Visualizing CNN Layer in Keras
How convolutional neural networks see the world
An exploration of convnet filters with Keras
Note: all code examples have been updated to the Keras 2.0 API on March 14, 2017. You will need Keras version 2.0.0 or higher to run them.
In this post, we take a look at what deep convolutional neural networks (convnets) really learn, and how they understand the images we feed them. We will use Keras to visualize inputs that maximize the activation of the filters in different layers of the VGG16 architecture, trained on ImageNet. All of the code used in this post can be found on Github.
VGG16 (also called OxfordNet) is a convolutional neural network architecture named after the Visual Geometry Group from Oxford, who developed it. It was used to win the ILSVR (ImageNet) competition in 2014. To this day is it still considered to be an excellent vision model, although it has been somewhat outperformed by more revent advances such as Inception and ResNet.
First of all, let's start by defining the VGG16 model in Keras:
from keras import applications # build the VGG16 network
model = applications.VGG16(include_top=False,
weights='imagenet') # get the symbolic outputs of each "key" layer (we gave them unique names).
layer_dict = dict([(layer.name, layer) for layer in model.layers])
Note that we only go up to the last convolutional layer --we don't include fully-connected layers. The reason is that adding the fully connected layers forces you to use a fixed input size for the model (224x224, the original ImageNet format). By only keeping the convolutional modules, our model can be adapted to arbitrary input sizes.
The model loads a set of weights pre-trained on ImageNet.
Now let's define a loss function that will seek to maximize the activation of a specific filter (filter_index) in a specific layer (layer_name). We do this via a Keras backend function, which allows our code to run both on top of TensorFlow and Theano.
from keras import backend as K layer_name = 'block5_conv3'
filter_index = 0 # can be any integer from 0 to 511, as there are 512 filters in that layer # build a loss function that maximizes the activation
# of the nth filter of the layer considered
layer_output = layer_dict[layer_name].output
loss = K.mean(layer_output[:, :, :, filter_index]) # compute the gradient of the input picture wrt this loss
grads = K.gradients(loss, input_img)[0] # normalization trick: we normalize the gradient
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5) # this function returns the loss and grads given the input picture
iterate = K.function([input_img], [loss, grads])
All very simple. The only trick here is to normalize the gradient of the pixels of the input image, which avoids very small and very large gradients and ensures a smooth gradient ascent process.
Now we can use the Keras function we defined to do gradient ascent in the input space, with regard to our filter activation loss:
import numpy as np # we start from a gray image with some noise
input_img_data = np.random.random((1, 3, img_width, img_height)) * 20 + 128.
# run gradient ascent for 20 steps
for i in range(20):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
This operation takes a few seconds on CPU with TensorFlow.
We can then extract and display the generated input:
from scipy.misc import imsave # util function to convert a tensor into a valid image
def deprocess_image(x):
# normalize tensor: center on 0., ensure std is 0.1
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1 # clip to [0, 1]
x += 0.5
x = np.clip(x, 0, 1) # convert to RGB array
x *= 255
x = x.transpose((1, 2, 0))
x = np.clip(x, 0, 255).astype('uint8')
return x img = input_img_data[0]
img = deprocess_image(img)
imsave('%s_filter_%d.png' % (layer_name, filter_index), img)
Result:

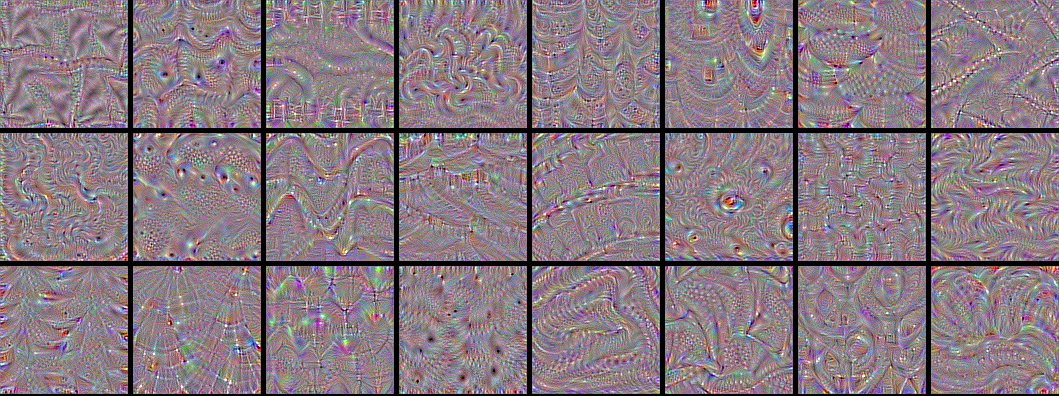
Visualize all the filters!
Now the fun part. We can use the same code to systematically display what sort of input (they're not unique) maximizes each filter in each layer, giving us a neat visualization of the convnet's modular-hierarchical decomposition of its visual space.
The first layers basically just encode direction and color. These direction and color filters then get combined into basic grid and spot textures. These textures gradually get combined into increasingly complex patterns.
You can think of the filters in each layer as a basis of vectors, typically overcomplete, that can be used to encode the layer's input in a compact way. The filters become more intricate as they start incorporating information from an increasingly larger spatial extent.

A remarkable observation: a lot of these filters are identical, but rotated by some non-random factor (typically 90 degrees). This means that we could potentially compress the number of filters used in a convnet by a large factor by finding a way to make the convolution filters rotation-invariant. I can see a few ways this could be achieved --it's an interesting research direction.
Shockingly, the rotation observation holds true even for relatively high-level filters, such as those in block4_conv1.
In the highest layers (block5_conv2, block5_conv3) we start to recognize textures similar to that found in the objects that network was trained to classify, such as feathers, eyes, etc.
Convnet dreams
Another fun thing to do is to apply these filters to photos (rather than to noisy all-gray inputs). This is the principle of Deep Dreams, popularized by Google last year. By picking specific combinations of filters rather than single filters, you can achieve quite pretty results. If you are interested in this, you could also check out the Deep Dream example in Keras, and the Google blog post that introduced the technique.

Finding an input that maximizes a specific class
Now for something else --what if you included the fully connected layers at the end of the network, and tried to maximize the activation of a specific output of the network? Would you get an image that looked anything like the class encoded by that output? Let's try it.
We can just define this very simple loss function:
model = applications.VGG16(include_top=True,
weights='imagenet')
loss = K.mean(model.output[:, output_index])
Let's apply it to output_index = 65 (which is the sea snake class in ImageNet). We quickly reach a loss of 0.999, which means that the convnet is 99.9% confident that the generated input is a sea snake. Let's take a look at the generated input.
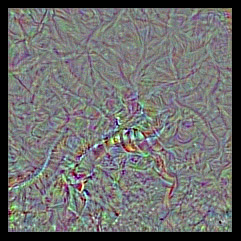
Oh well. Doesn't look like a sea snake. Surely that's a fluke, so let's try again with output_index = 18 (the magpie class).

Ok then. So our convnet's notion of a magpie looks nothing like a magpie --at best, the only resemblance is at the level of local textures (feathers, maybe a beak or two). Does it mean that convnets are bad tools? Of course not, they serve their purpose just fine. What it means is that we should refrain from our natural tendency to anthropomorphize them and believe that they "understand", say, the concept of dog, or the appearance of a magpie, just because they are able to classify these objects with high accuracy. They don't, at least not to any any extent that would make sense to us humans.
So what do they really "understand"? Two things: first, they understand a decomposition of their visual input space as a hierarchical-modular network of convolution filters, and second, they understand a probabilitistic mapping between certain combinations of these filters and a set of arbitrary labels. Naturally, this does not qualify as "seeing" in any human sense, and from a scientific perspective it certainly doesn't mean that we somehow solved computer vision at this point. Don't believe the hype; we are merely standing on the first step of a very tall ladder.
Some say that the hierarchical-modular decomposition of visual space learned by a convnet is analogous to what the human visual cortex does. It may or may not be true, but there is no strong evidence to believe so. Of course, one would expect the visual cortex to learn something similar, to the extent that this constitutes a "natural" decomposition of our visual world (in much the same way that the Fourier decomposition would be a "natural" decomposition of a periodic audio signal). But the exact nature of the filters and hierarchy, and the process through which they are learned, has most likely little in common with our puny convnets. The visual cortex is not convolutional to begin with, and while it is structured in layers, the layers are themselves structured into cortical columns whose exact purpose is still not well understood --a feature not found in our artificial networks (although Geoff Hinton is working on it). Besides, there is so much more to visual perception than the classification of static pictures --human perception is fundamentally sequential and active, not static and passive, and is tightly intricated with motor control (e.g. eye saccades).
Think about this next time your hear some VC or big-name CEO appear in the news to warn you against the existential threat posed by our recent advances in deep learning. Today we have better tools to map complex information spaces than we ever did before, which is awesome, but at the end of the day they are tools, not creatures, and none of what they do could reasonably qualify as "thinking". Drawing a smiley face on a rock doesn't make it "happy", even if your primate neocortex tells you so.
That said, visualizing what convnets learn is quite fascinating --who would have guessed that simple gradient descent with a reasonable loss function over a sufficiently large dataset would be enough to learn this beautiful hierarchical-modular network of patterns that manages to explain a complex visual space surprisingly well. Deep learning may not be intelligence is any real sense, but it's still working considerably better than anybody could have anticipated just a few years ago. Now, if only we understood why... ;-)
@fchollet, January 2016
Visualizing CNN Layer in Keras的更多相关文章
- Visualizing LSTM Layer with t-sne in Neural Networks
LSTM 可视化 Visualizing Layer Representations in Neural Networks Visualizing and interpreting represent ...
- 深度学习Trick——用权重约束减轻深层网络过拟合|附(Keras)实现代码
在深度学习中,批量归一化(batch normalization)以及对损失函数加一些正则项这两类方法,一般可以提升模型的性能.这两类方法基本上都属于权重约束,用于减少深度学习神经网络模型对训练数据的 ...
- keras入门(三)搭建CNN模型破解网站验证码
项目介绍 在文章CNN大战验证码中,我们利用TensorFlow搭建了简单的CNN模型来破解某个网站的验证码.验证码如下: 在本文中,我们将会用Keras来搭建一个稍微复杂的CNN模型来破解以上的 ...
- keras和tensorflow搭建DNN、CNN、RNN手写数字识别
MNIST手写数字集 MNIST是一个由美国由美国邮政系统开发的手写数字识别数据集.手写内容是0~9,一共有60000个图片样本,我们可以到MNIST官网免费下载,总共4个.gz后缀的压缩文件,该文件 ...
- Keras入门——(2)卷积神经网络CNN
前期准备工作参考:https://www.cnblogs.com/ratels/p/11144881.html 基于CNN算法利用Keras框架编写代码实现对Minst数据分类识别: from ker ...
- Keras教程
In this step-by-step Keras tutorial, you’ll learn how to build a convolutional neural network in Pyt ...
- 利用CNN进行多分类的文档分类
# coding: utf-8 import tensorflow as tf class TCNNConfig(object): """CNN配置参数"&qu ...
- CNN卷积神经网络的改进(15年最新paper)
回归正题,今天要跟大家分享的是一些 Convolutional Neural Networks(CNN)的工作. 大家都知道,CNN 最早提出时,是以一定的人眼生理结构为基础,然后逐渐定下来了一些经典 ...
- AI:IPPR的数学表示-CNN可视化语义分析
前言: ANN是个语义黑箱的意思是没有通用明确的函数表示,参数化的模型并不能给出函数的形式,更进而不能表示函数的实际意义. 而CNN在图像处理方面具有天然的理论优势,而Conv层和Polling层,整 ...
随机推荐
- 【mNOIP模拟赛Day 1】 T2 数颜色
题目传送门:https://www.luogu.org/problemnew/show/P3939 题外话:写完这题后本地跑了下极限数据,用时1.5s,于是马上用fread+fwrite优化至0.3s ...
- HBase Cli相关操作
修改HBase表结构之前首先需要disable表,然后进行更改相关表结构信息,最后enable表,如下 1. 动态添加一个或多个列簇 hbase(main):034:0> describe 'H ...
- C++运算符重载三种形式(成员函数,友元函数,普通函数)详解
首先,介绍三种重载方式: //作为成员函数重载(常见) class Person{ Private: string name; int age; public: Person(const char* ...
- VS2015 未能正确加载 JavascriptWebExtensionsPackage
解决方法: Close Visual Studio Open the %UserProfile%\AppData\Local\Microsoft\VisualStudio\<version> ...
- 【优化】bigpipe技术
一.什么是bigpipe Bigpipe是Facebook工程师提出了一种新的页面加载技术. BigPipe是一个重新设计的基础动态网页服务体系.大体思路是,分解网页成叫做Pagelets的小块,然后 ...
- 四则运算2及psp0设计
随机生成运算式,要求: 1.题目避免重复. 2.可定制(数量/打印方式). 3.可以控制一下参数. 要求:是否有乘除法,是否有括号,数值范围,加减有无负数,除法有无余数. 刚开始看到这样一个题目感觉还 ...
- 关于Spring的一点东西
Spring IoC 容器 容器将创建对象,把它们连接在一起,配置它们,并管理他们的整个生命周期从创建到销毁.Spring 容器使用依赖注入(DI)来管理组成一个应用程序的组件.这些对象被称为 Spr ...
- android的几种“通知”方式简单实现(Notification&NotificationManager)
关于通知Notification相信大家都不陌生了,平时上QQ的时候有消息来了或者有收到了短信,手机顶部就会显示有新消息什么的,就类似这种.今天就稍微记录下几种Notification的用法.3.0以 ...
- IDEA里点击Build,再Build Artifacts没反应,灰色的?解决办法(图文详解)
不多说,直接上干货! 问题详情 如下:点击Build ,再 Build -> Build Artifacts,没反应??? 解决办法 1.File,再Project Structure 2.然后 ...
- 可视化的Redis数据库管理工具redis-desktop-manager的初步使用(图文详解)
不多说,直接上干货! 无论是Linux 还是 Windows里安装Redis, Windows里如何正确安装Redis以服务运行(博主推荐)(图文详解) Windows下如何正确下载并安装可视化的Re ...