JAVA复习笔记分布式篇:zookeeper
前言:终于到分布式篇,前面把JAVA的一些核心知识复习了一遍,也是一个JAVA程序员最基本要掌握的知识点,接下来分布式的知识点算是互联网行业的JAVA程序员必备的技能;
概念:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是谷歌的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等
关键词:分布式,一致性服务
讲得通俗一点,zookeeper的诞生就是为了解决分布式一致性的问题。
什么是分布式一致性?
分布式:分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
一致性:指对每个节点一个数据的更新,整个集群都知道更新,并且是一致的 ;
PS:通俗一点以前一台服务器支撑一个系统的模式升级为多台服务器(多个容器)去支撑一个系统,这样这个系统的并发、容灾等各方面的能力将得到大大提升(传统的ngix和集群也能做到),分布式和集群最大的一个区别是分布式的节点都是不同业务(比如账号 系统,订单系统,物流系统,商品系统各自部署在不同服务器上)这样做的好处是可以根据不同模块的特性合理地分配资源(比如账号系统访问量很大,需要部署3-5台机器,而物流系统的访问量较小,只需要部署1-2台服务器即可),一致性就是虽然账号系统部署 了3台服务器,对于client而言是透明的(订单系统调用账号系统的服务,不用知道调用的哪台服务器上的系统, 结果每次都能得到幂等),那么如何保证每次都能得到这个幂等结果?也就是zookeeper的要解决的问题
基本架构图
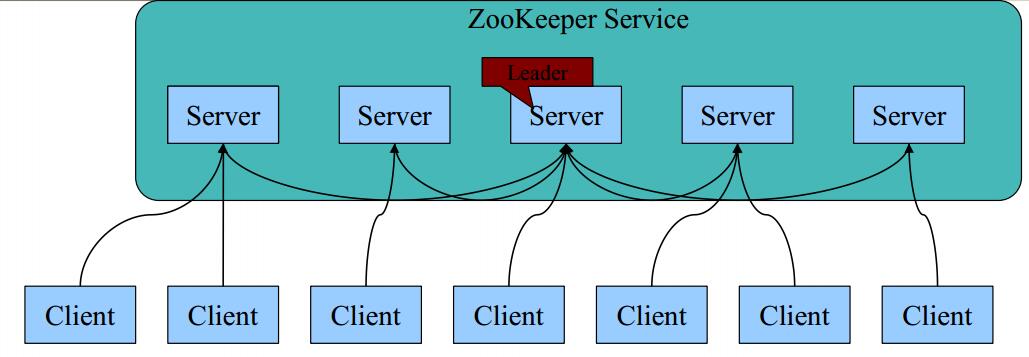
角色:
领导者(leader): Leader作为整个ZooKeeper集群的主节点,负责响应所有对ZooKeeper状态变更的请求;
追随者(follower):除了响应本服务器上的读请求外(exists,getData,getChildren等只读请求),follower还要处理leader的提议,并在leader提交该提议时在本地也进行提交
观察者(observer):Observer和Follower比较相似,只有一些小区别:首先observer不参加选举也不响应提议;其次是observer不需要将事务持久化到磁盘,一旦observer被重启,需要从leader重新同步整个名字空间。
整个zookeeper集群只有这3种角色,可以看到leader只有一个,所有对数据变更的请求都需要有leader去调度(leader会向所有节点发送原子广播,收到一半以上的节点都同意的消息后才真正提交这个事务),所以leader这个节点相当重要,那如何确立这个 learder 呢?
答案是选举,zookeeper采用选举的方式确立leader(触发选举的场景分为2种,一种是服务器初始化启动时候,还有一种是服务器运行期间无法和Leader保持连接)
讲解选举过程前先需要了解几个名词
electionEpoch(时钟):每执行一次leader选举,electionEpoch就会自增,用来标记leader选举的轮次
peerEpoch:每次leader选举完成之后,都会选举出一个新的peerEpoch,用来标记事务请求所属的轮次
zxid:事务请求的唯一标记,由leader服务器负责进行分配。由2部分构成,高32位是上述的peerEpoch,低32位是请求的计数,从0开始。所以由zxid我们就可以知道该请求是哪个轮次的,并且是该轮次的第几个请求。
lastProcessedZxid:最后一次commit的事务请求的zxid
选举过程:
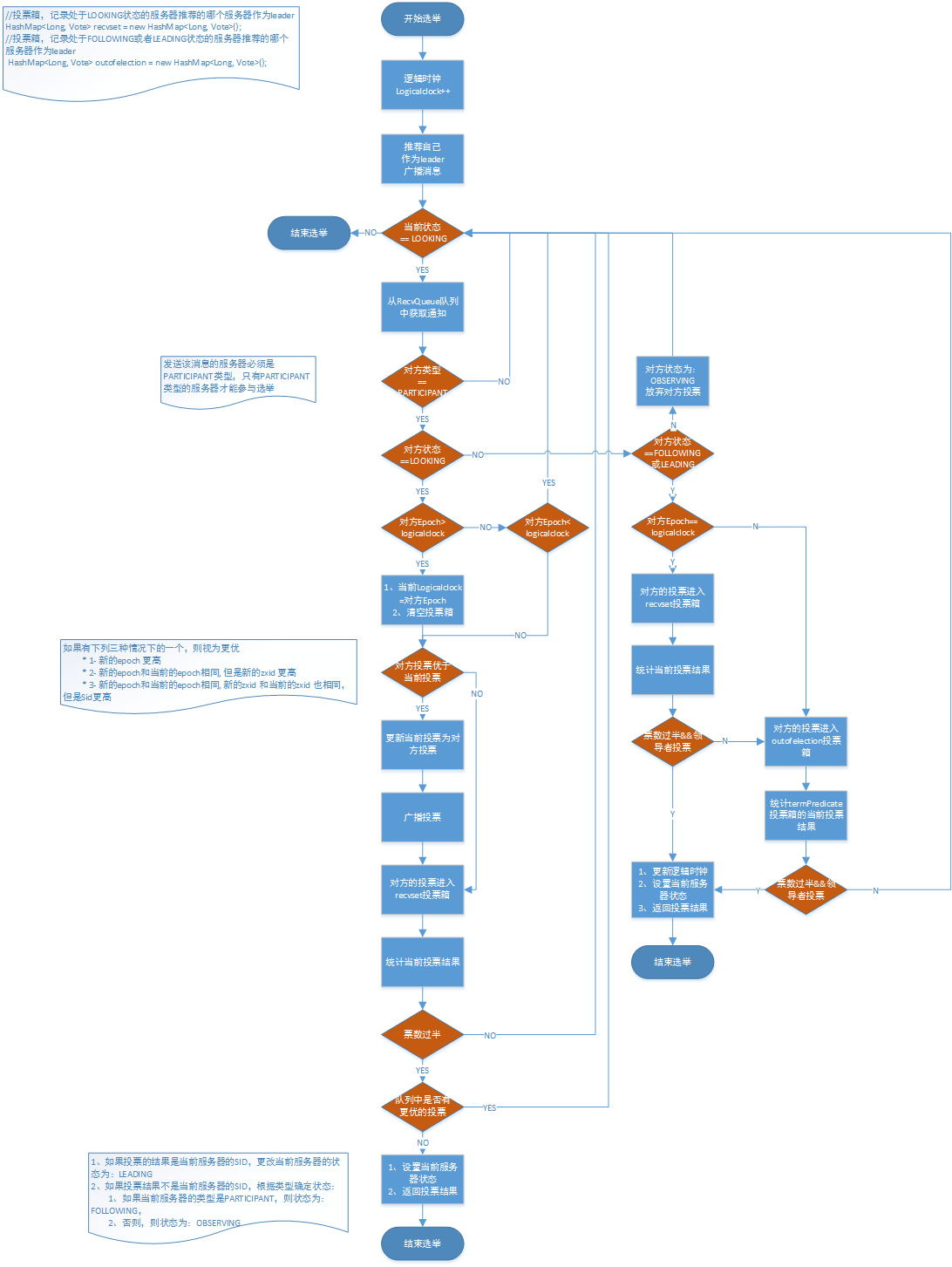
整个选举流程如上图
每个节点开始第一轮选举,逻辑时钟(当前投票轮数)+1,投票给自己节点(myid,zxid),广播给所有节点,并且开始接收其他节点发来的投票信息(第一轮的投票每个节点都会投给自己),每接收到一个其他节点的投票就先判断对方节点是否满足投票条件(只有PARTICIPANT类型的节点并且处于Looking才能参与选举),判断对方的Epoch和自己节点的逻辑时钟大小
1:如果对方的Epoch小与自己节点的逻辑时钟,那么就舍弃对方的这次投票(认为它是过期无效的),判断当前节点的状态节点是否满足投票条件,如果满足则继续接收其他节点的投票
2:如果对方的Epoch等于自己节点的逻辑时钟,则判断zxid大小
2.1如果自己节点所投票的zxid小于对方的zxid,则需要更新自己的投票为对方的投票,并广播所有节点,把对方的票放到自己的投票箱
2.2如果自己节点所投票的xid等于对方的zxid,则需要判断节点id大小(对方节点id较大,执行2.1的逻辑,反之执行2.3)
2.3如果自己节点所投票的zxid大于对方的zxid,把对方的票放到自己的投票箱
3:如果对方的Epoch大于自己节点的逻辑时钟,更新自己的逻辑时钟为对方的Epoch, 清空自己的投票箱(认为之前的投票都是无效的)执行上面这一步(比较zxid大小)
4:每次投完票都会统计自己投票箱的情况,如果超过一半的票数投了相同的节点,就可以认为那个节点是leader节点。不过还需要再确认一遍(那么当前线程将被阻塞等待一段时间(这个时间在finalizeWait定义))从队列中继续接收,如果没有更优选票,投票就能结束(判断投票的节点id和当前服务器的Id一致,则认为是leader节点,如果节点类型是PARTICIPANT节点Following节点,反之Observing节点)
如果接收到的节点状不是Looking(Following,Observing,leading):
Observing:放弃该投票(Observer不参与投票)
Following或leading:对比当前的逻辑时钟与对方的逻辑时钟大小
a) 如果逻辑时钟相同,将该数据保存到recvset,如果所接收服务器宣称自己是leader,那么将判断是不是有半数以上的服务器选举它,如果是则设置选举状态退出选举过程
b) 否则这是一条与当前逻辑时钟不符合的消息,那么说明在另一个选举过程中已经有了选举结果,于是将该选举结果加入到outofelection集合中,再根据outofelection来判断是否可以结束选举,如果可以也是保存逻辑时钟,设置选举状态,退出选举过程.
可以查看部分核心源码
- public Vote lookForLeader() throws InterruptedException {
- try {
- this.self.jmxLeaderElectionBean = new LeaderElectionBean();
- MBeanRegistry.getInstance().register(this.self.jmxLeaderElectionBean, this.self.jmxLocalPeerBean);
- } catch (Exception var23) {
- LOG.warn("Failed to register with JMX", var23);
- this.self.jmxLeaderElectionBean = null;
- }
- if(this.self.start_fle == 0L) {
- this.self.start_fle = System.currentTimeMillis();
- }
- FastLeaderElection.Notification n;
- try {
- HashMap<Long, Vote> recvset = new HashMap();
- HashMap<Long, Vote> outofelection = new HashMap();
- int notTimeout = 200;
- synchronized(this) {
- ++this.logicalclock;
- this.updateProposal(this.getInitId(), this.getInitLastLoggedZxid(), this.getPeerEpoch());
- }
- LOG.info("New election. My id = " + this.self.getId() + ", proposed zxid=0x" + Long.toHexString(this.proposedZxid));
- this.sendNotifications();
- while(this.self.getPeerState() == ServerState.LOOKING && !this.stop) {
- n = (FastLeaderElection.Notification)this.recvqueue.poll((long)notTimeout, TimeUnit.MILLISECONDS);
- if(n == null) {
- if(this.manager.haveDelivered()) {
- this.sendNotifications();
- } else {
- this.manager.connectAll();
- }
- int tmpTimeOut = notTimeout * 2;
- notTimeout = tmpTimeOut < '\uea60'?tmpTimeOut:'\uea60';
- LOG.info("Notification time out: " + notTimeout);
- } else if(!this.self.getVotingView().containsKey(Long.valueOf(n.sid))) {
- LOG.warn("Ignoring notification from non-cluster member " + n.sid);
- } else {
- Vote endVote;
- Vote var6;
- switch(FastLeaderElection.SyntheticClass_1.$SwitchMap$org$apache$zookeeper$server$quorum$QuorumPeer$ServerState[n.state.ordinal()]) {
- case 1:
- if(n.electionEpoch > this.logicalclock) {
- this.logicalclock = n.electionEpoch;
- recvset.clear();
- if(this.totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, this.getInitId(), this.getInitLastLoggedZxid(), this.getPeerEpoch())) {
- this.updateProposal(n.leader, n.zxid, n.peerEpoch);
- } else {
- this.updateProposal(this.getInitId(), this.getInitLastLoggedZxid(), this.getPeerEpoch());
- }
- this.sendNotifications();
- } else {
- if(n.electionEpoch < this.logicalclock) {
- if(LOG.isDebugEnabled()) {
- LOG.debug("Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x" + Long.toHexString(n.electionEpoch) + ", logicalclock=0x" + Long.toHexString(this.logicalclock));
- }
- break;
- }
- if(this.totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, this.proposedLeader, this.proposedZxid, this.proposedEpoch)) {
- this.updateProposal(n.leader, n.zxid, n.peerEpoch);
- this.sendNotifications();
- }
- }
- if(LOG.isDebugEnabled()) {
- LOG.debug("Adding vote: from=" + n.sid + ", proposed leader=" + n.leader + ", proposed zxid=0x" + Long.toHexString(n.zxid) + ", proposed election epoch=0x" + Long.toHexString(n.electionEpoch));
- }
- recvset.put(Long.valueOf(n.sid), new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
- if(!this.termPredicate(recvset, new Vote(this.proposedLeader, this.proposedZxid, this.logicalclock, this.proposedEpoch))) {
- break;
- }
- while((n = (FastLeaderElection.Notification)this.recvqueue.poll(200L, TimeUnit.MILLISECONDS)) != null) {
- if(this.totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, this.proposedLeader, this.proposedZxid, this.proposedEpoch)) {
- this.recvqueue.put(n);
- break;
- }
- }
- if(n == null) {
- this.self.setPeerState(this.proposedLeader == this.self.getId()?ServerState.LEADING:this.learningState());
- endVote = new Vote(this.proposedLeader, this.proposedZxid, this.logicalclock, this.proposedEpoch);
- this.leaveInstance(endVote);
- var6 = endVote;
- return var6;
- }
- break;
Leader与Follower同步数据(ZAB 原子广播)
Fast Leader选举算法中提到的同步数据时使用的逻辑时钟,它的初始值是0,每次选举过程都会递增的,在leader正式上任之后做的第一件事情,就是根据当前保存的数据id值,设置最新的逻辑时钟值。
随后,leader构建NEWLEADER封包,该封包的数据是当前最大数据的id,广播给所有的follower,也就是告知follower leader保存的数据id是多少,大家看看是不是需要同步。然后,leader根据follower数量给每个follower创建一个线程LearnerHandler,专门负责接收它们的同步数据请求.leader主线程开始阻塞在这里,等待其他follower的回应(也就是LearnerHandler线程的处理结果),同样的,只有在超过半数的follower已经同步数据完毕,这个过程才能结束,leader才能正式成为leader.
leader所做的工作:
所以其实leader与follower同步数据的大部分操作都在LearnerHandler线程中处理的,接着看这一块.
leader接收到的来自某个follower封包一定是FOLLOWERINFO,该封包告知了该服务器保存的数据id.之后根据这个数据id与本机保存的数据进行比较:
1) 如果数据完全一致,则发送DIFF封包告知follower当前数据就是最新的了.
2) 判断这一阶段之内有没有已经被提交的提议值,如果有,那么:
a) 如果有部分数据没有同步,那么会发送DIFF封包将有差异的数据同步过去.同时将follower没有的数据逐个发送COMMIT封包给follower要求记录下来.
b) 如果follower数据id更大,那么会发送TRUNC封包告知截除多余数据.(一台leader数据没同步就宕掉了,选举之后恢复了,数据比现在leader更新)
3) 如果这一阶段内没有提交的提议值,直接发送SNAP封包将快照同步发送给follower.
4)消息完毕之后,发送UPTODATE封包告知follower当前数据就是最新的了,再次发送NEWLEADER封包宣称自己是leader,等待follower的响应.
follower做的工作:
(1)会尝试与leader建立连接,这里有一个机制,如果一定时间内没有连接上,就报错退出,重新回到选举状态.
(2)其次在发送FOLLOWERINFO封包,该封包中带上自己的最大数据id,也就是会告知leader本机保存的最大数据id.
(3)根据前面对LeaderHandler的分析,leader会根据不同的情况发送DIFF,UPTODATE,TRUNC,SNAP,依次进行处理就是了,此时follower跟leader的数据也就同步上了.
(4)由于leader端发送的最后一个封包是UPTODATE,因此在接收到这个封包之后follower结束同步数据过程,发送ACK封包回复leader.
以上过程中,任何情况出现的错误,服务器将自动将选举状态切换到LOOKING状态,重新开始进行选举.
zookeeper的机制
分布式锁:
用zookeeper实现分布式锁有2种
方式一:根据zookeeper命名的唯一性,每个想要竞争资源的节点,创建一个相同名字的临时节点(相同路径),只能有一个节点创建成功,创建成功的节点就获得了锁
方式二:根据zk的“临时顺序”节点 , 每个想要竞争资源的节点,在同一个节点下注册一个临时顺序节点,然后将所有临时节点按小从到大排序,如果自己注册的临时节点正好是最小的,表示获得了锁(zk能保证临时节点序号始终递增,所以如果后面有其它应用也注册了临时节点,序号肯定比获取锁的应用更大),其余节点watch排在前面的节点,只要监测到节点被删除了(锁释放之后就删除=该节点),马上重新竞争锁
JAVA复习笔记分布式篇:zookeeper的更多相关文章
- JAVA复习笔记分布式篇:kafka
前言:第一次使用消息队列是在实在前年的时候,那时候还不了解kafka,用的是阿里的rocket_mq,当时觉得挺好用的,后来听原阿里的同事说rocket_mq是他们看来kafka的源码后自己开发了一套 ...
- Java 学习笔记提高篇
Java笔记(提高篇)整理 主要内容: 面向对象 异常 数组 常用类 集合 IO流 线程 反射 Socket编程 1. 面向对象 1.1包 用来管理Java中的类, 类似文件夹管理文件一样. 因 ...
- java复习笔记
本笔记(无异常处理与网络编程部分)整理自<java程序设计>-黄岚 王岩 王康平 编著 java数据 UI I/O java线程 数据库操作 Java数 ...
- SQL 复习笔记 MSSQL篇
苦逼得很,一下就失业了,只有好好复习,迎接下一份工作 MSSQL篇: 1.数据库表分为临时表和永久表.临时表又分为全局临时表和局部临时表 全局临时表:表名以##开头.对系统当前 ...
- java学习笔记-JavaWeb篇二
JavaWEB篇二 45 HttpSession概述46 HttpSession的生命周期 47 HttpSession常用方法示例48 HttpSessionURL重写 49 HttpSession ...
- java学习笔记-JavaWeb篇一
JavaWEB篇一 1 Tomcat的安装和配置 2 JavaWeb开发的目录结构 3 使用Eclipse开发JavaWeb项目 4 第一个Servlet程序 5 Servlet 的配置及生命周期方法 ...
- java学习笔记-基础篇
Java基础篇 1—12 常识 13 this关键字 14参数传递 16 继承 17 访问权限 28—31异常 1—12 常识 1.文件夹以列表展示,显示扩展名,在地址栏显示全路径 2.javac编译 ...
- 【私人向】Java复习笔记
此笔记学习于慕课网:Java入门第一季-第三季,想学的可以点击链接进行学习,笔记仅为私人收藏 建议学习时间:2-3天(极速版) 数据类型 基本数据类型存的是数据本身 引用类型变量(class.inte ...
- Java学习笔记——基础篇
Tips1:eclipse中会经常用到System.out.println方法,可以先输入syso,然后eclipse就会自动联想出这个语句了!! 学习笔记: *包.权限控制 1.包(package) ...
随机推荐
- MySQL 第六篇:数据备份、pymysql模块
一 IDE工具介绍 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具 下载链接:https://pan.baidu.com/s/1O8hXkdRK5_EVHZwNPwjCB ...
- linux中awk工具的使用
awk是一个非常好用的数据处理工具.相较于sed常常一整行处理,awk则比较倾向于一行当中分成数个“字段”处理,awk处理方式如下: $ awk '条件类型1{动作1} 条件类型2{动作2} ...' ...
- SIFT算法学习
几个关于SIFT算法的blog,写的很好,链接学习一下 小北的家谈谈SIFT.PCA-SIFT.SURF及我的一点思考http://blog.csdn.net/ijuliet/article/deta ...
- UnityShader 序列帧动画效果
实现原理:主要思想是设置显示uv纹理的大小,并逐帧修改图片的uv坐标. 实现步骤 1.我们首先用_Time.y和速度属性_Speed相乘得到模拟的时间. 2.然后我们用time除以_Horizonta ...
- C陷阱与缺陷的个人知识点摘录
编译过程的一点心得体会: .h文件其实只在预处理的过程用到,用来将类似#include <stdio.h>这样的行展开为具体内容. 那些标准库或者其他库中的函数,是在链接的过程中连接器把相 ...
- Java入门:修改IDE主题颜色
1.去 http://eclipsecolorthemes.org/?view=theme&id=1下载你需要的颜色,根据id不同,配色方案不一样. 2.下载页面右侧的“Eclipse Pre ...
- python基础之02列表/元组/字典/set集合
python中内置的数据类型有列表(list)元组(tuple)字典(directory). 1 list list是一种可变的有序的集合.来看一个list实例: #第一种方法: >>&g ...
- Jenkins+Maven+SVN
准备环境: CentOS7 JDK1.7.9.0_79 Maven3.3.9 Jenkins2.5.0 1.配置jdk环境变量 2.安装maven(否则在创建job时没有maven选项) unzip ...
- [大数据]-Fscrawler导入文件(txt,html,pdf,worf...)到Elasticsearch5.3.1并配置同义词过滤
fscrawler是ES的一个文件导入插件,只需要简单的配置就可以实现将本地文件系统的文件导入到ES中进行检索,同时支持丰富的文件格式(txt.pdf,html,word...)等等.下面详细介绍下f ...
- Hadoop生态圈-使用MapReduce处理HBase数据
Hadoop生态圈-使用MapReduce处理HBase数据 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.对HBase表中数据进行单词统计(TableInputFormat) ...