自然语言处理--Word2vec(一)
一、自然语言处理与深度学习
自然语言处理应用

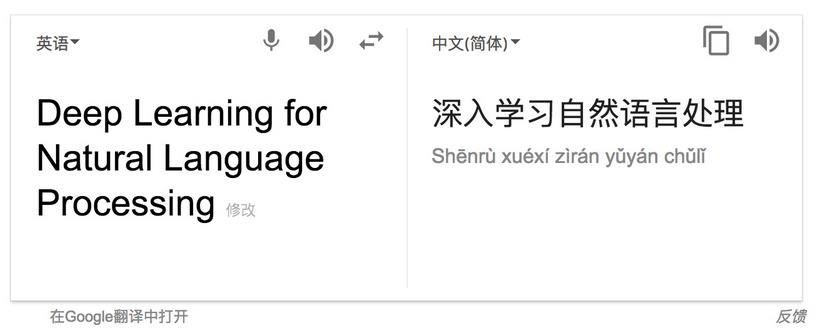
深度学习模型

为什么需要用深度学习来处理呢

二、语言模型
1、语言模型实例:
机器翻译

拼写纠错 智能问答


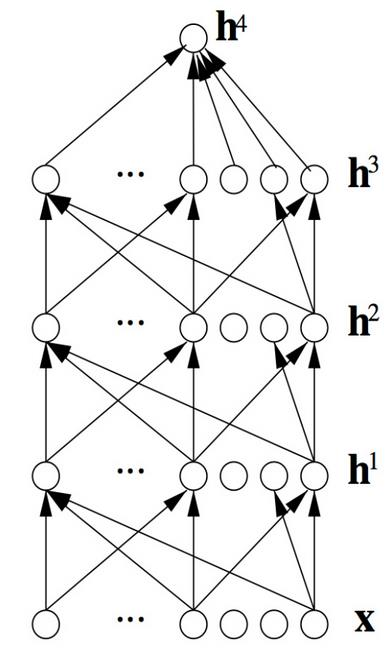
1)机器翻译,比如要翻译高价,可能 P(high price) > P(large price),然后得到的结果就是high price
2)拼写纠错,比如 fifteen minutes,P(about fifteen minutes from) > P(about fifteenminuets from),一般时分开写的,如果合在一起则会纠正为分开书写
3)语言模型举例
我 今天 下午 打 篮球
p(S) = p(w1,w2,w3,w4,w5,...,wn)
= p(w1)p(w2|w1)p(w3|w1,w2) ... p(wn|w1,w2,...,wn-1)
上式中wi表示每个词
p(S)被称为语言模型,即用来计算一个句子概率的模型
2、语言模型存在哪些问题呢?
p(wi|w1,w2,...,wi-1) = p(w1,w2,...,wi-1,wi) / p(w1,w2,...,wi-1)
1)数据过于稀疏
2)参数空间太大
三、N-gram模型
假设下一个词的出现依赖它前面的一个词:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1)
假设下一个词的出现依赖它前面的两个词:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|wn-1,wn-2)
举例:
I want english food
p( I want chinese food ) = P( want|I ) × P( chinese|want ) × P( food|chinese )


假设词典的大小是N,则模型参数的量级是 
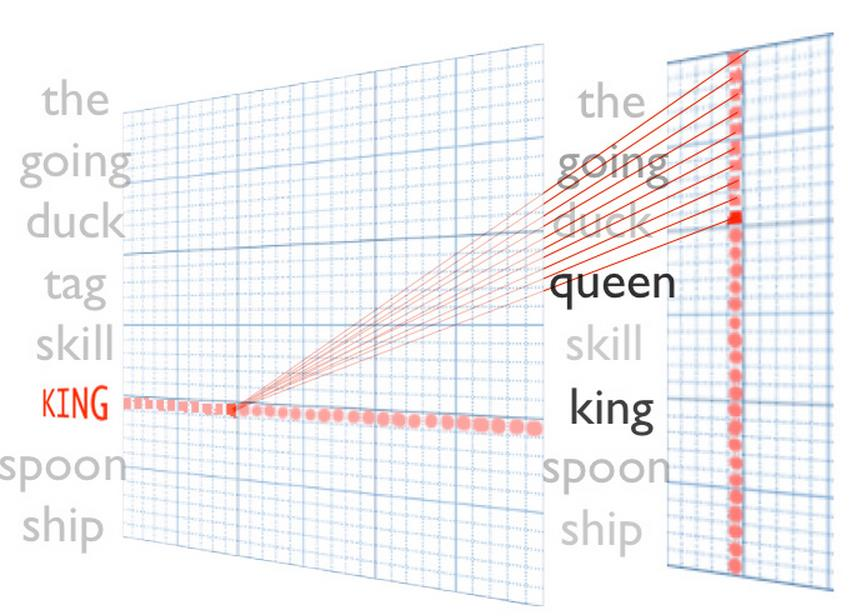
四、词向量



五、神经网络模型
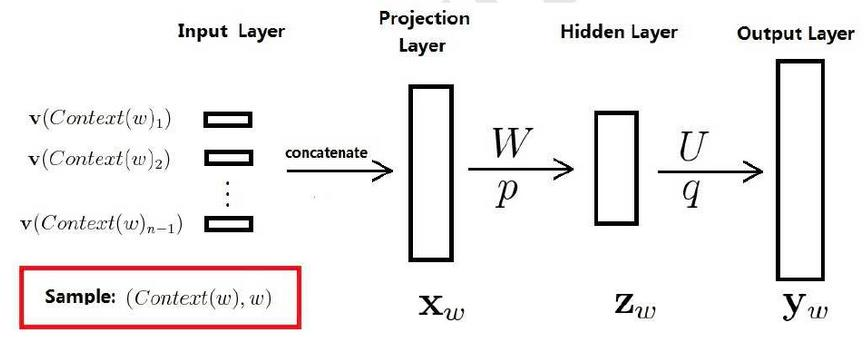
训练样本:  ,包括前n-1个词分别的向量,假定每个词向量大小m
,包括前n-1个词分别的向量,假定每个词向量大小m
投影层:(n-1)*m 首尾拼接起来的大向量
输出: 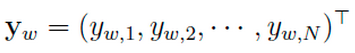
表示上下文为  时,下一个词恰好为词典中第i个词的概率
时,下一个词恰好为词典中第i个词的概率
归一化: 
神经网络模型的优势
S1 = ‘’我 今天 去 网咖’’ 出现了1000次
S2 = ‘’我 今天 去 网吧’’ 出现了10次
对于S1和S2两句话其实表达的意思差不多的,但
对于N-gram模型: P(S1) >> P(S2),一般会表述为S1
而神经网络模型计算的 P(S1) ≈ P(S2)
对于如下:

在神经网络中,只要语料库中出现其中一个,其他句子的概率也会相应的增大
六、Hierarchical Softmax
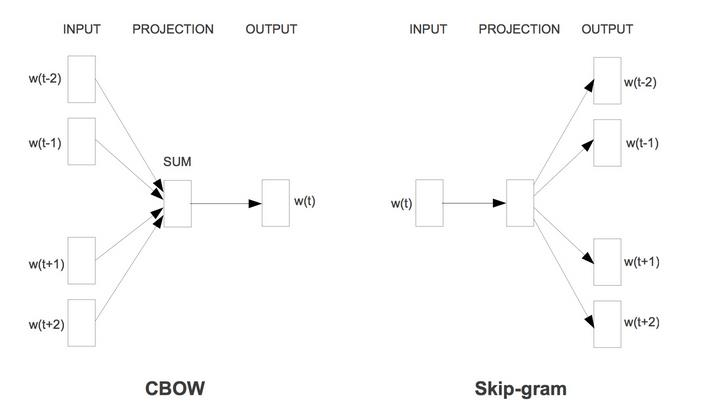
Hierarchical Softmax有两种模型,CBOW,Skip-gram
1、CBOW
CBOW 是 Continuous Bag-of-Words Model 的缩写,是一种根据上下文的词语预测当前词语的出现概率的模型

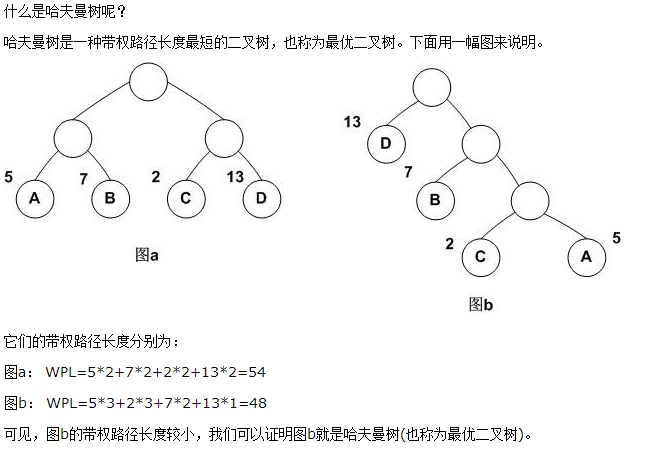
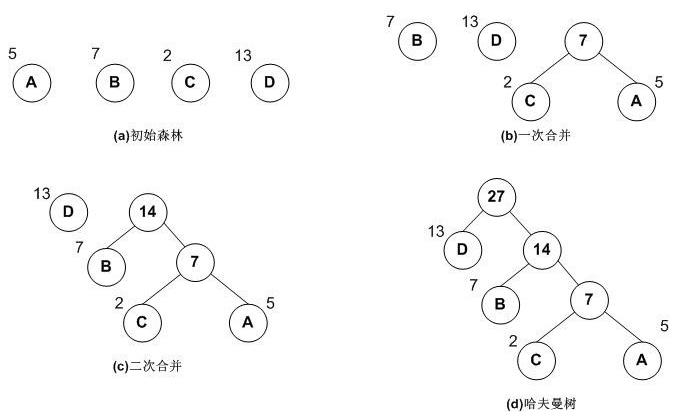
2、哈夫曼树
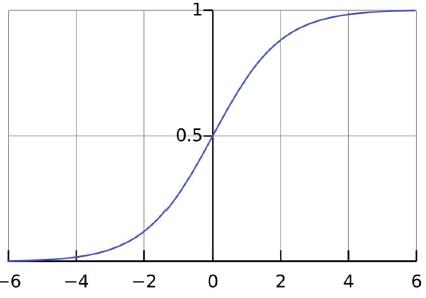
3、Logistic回归
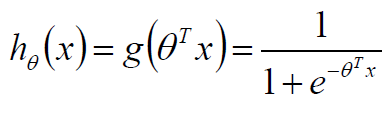
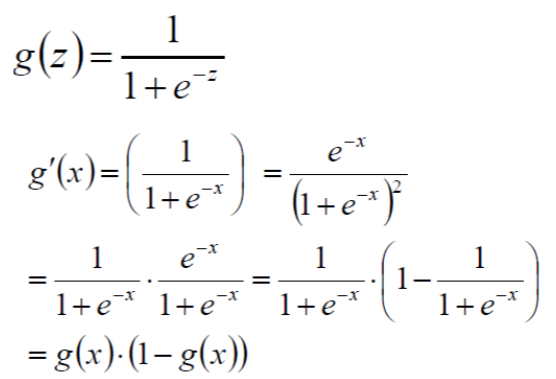
4、CBOW模型推导
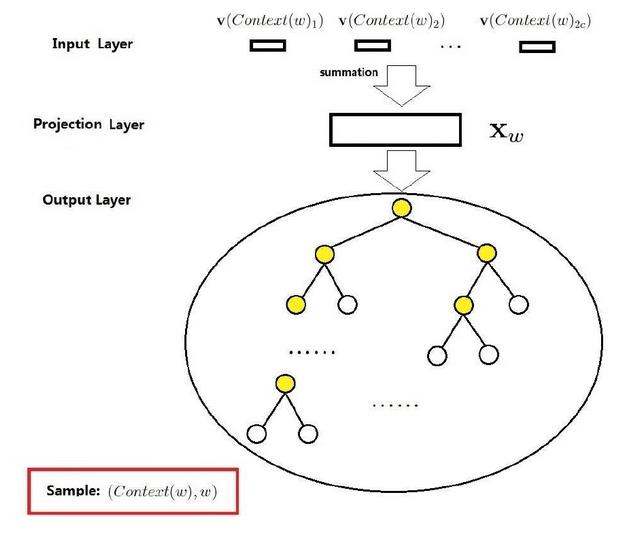
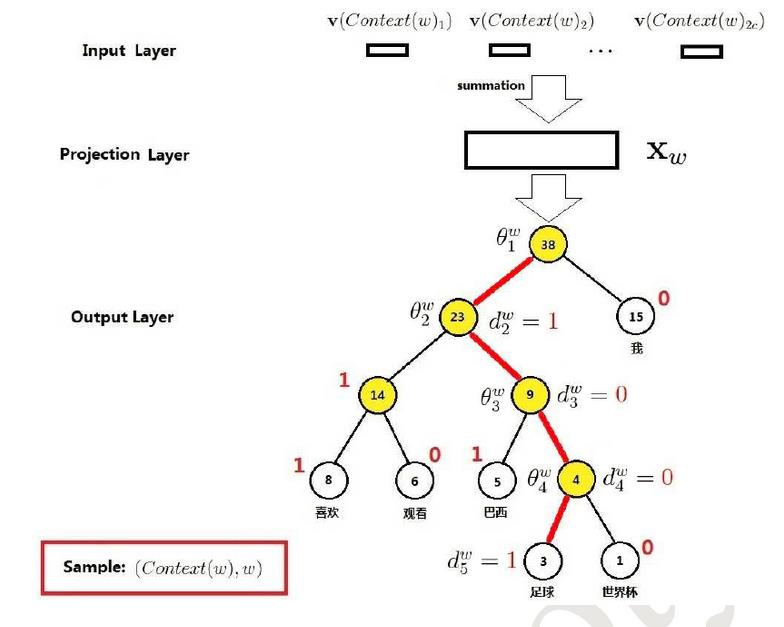
输入层是上下文的词语的词向量,在训练CBOW模型,词向量只是个副产品,确切来说,是CBOW模型的一个参数。训练开始的时候,词向量是个随机值,随着训练的进行不断被更新)。
投影层对其求和,所谓求和,就是简单的向量加法。
输出层输出最可能的w。由于语料库中词汇量是固定的|C|个,所以上述过程其实可以看做一个多分类问题。给定特征,从|C|个分类中挑一个。



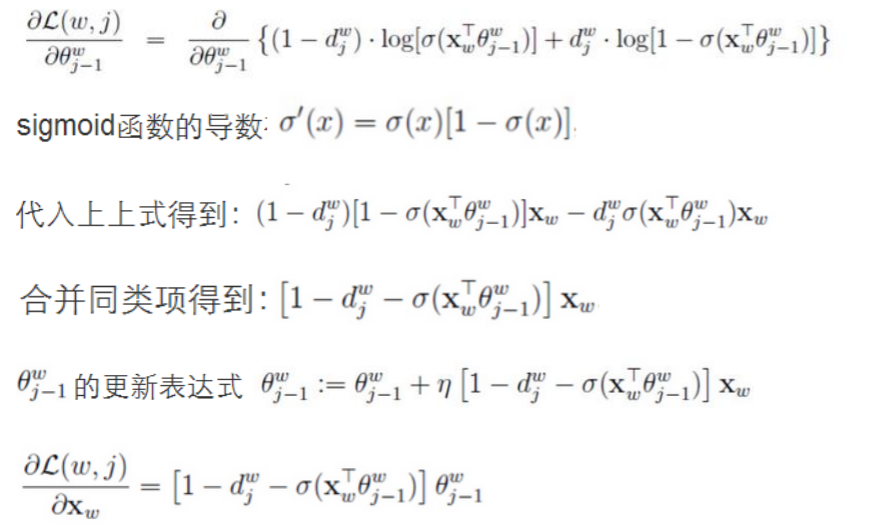

5、Skip-gram模型
1)输入层不再是多个词向量,而是一个词向量
2)投影层其实什么事都没干,直接将输入层的词向量传递给输出层
七、负采样模型(Negative Sampling)
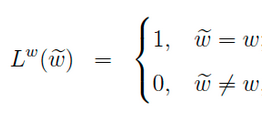
负样本那么多该如何选择呢?
对于一个给定的正样本(Context(w), w),我们希望最大化
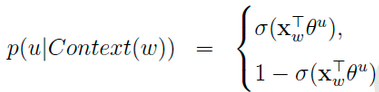
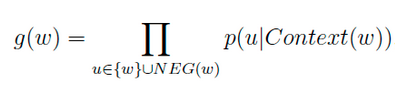


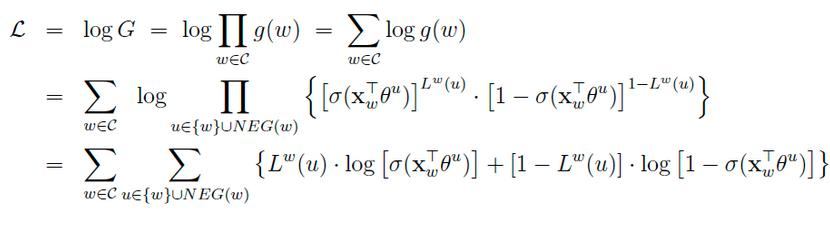
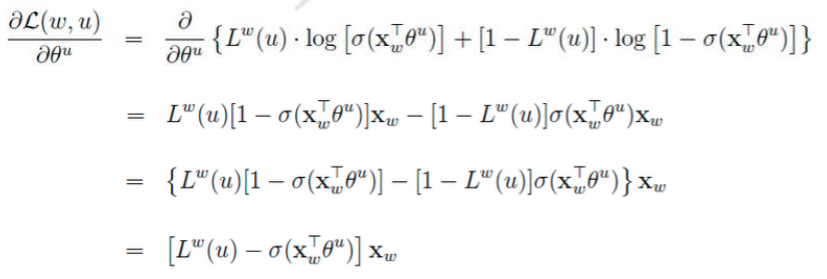

一般大多采用负采样模型来求解,因为Hierarchical softmax模型太过于复杂。
自然语言处理--Word2vec(一)的更多相关文章
- 自然语言处理--Word2vec(二)
前一篇,word2vec(一)主要讲了word2vec一些表层概念,以及主要介绍CBOW方法来求解词向量模型,这里主要讲论文 Distributed Representations of Words ...
- word2vec:主要概念和流程
1.单词的向量化表示 一般来讲,词向量主要有两种形式,分别是稀疏向量和密集向量. 所谓稀疏向量,又称为one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的 ...
- Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树
Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 目录 Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 0x00 摘要 0x01 背景概念 1.1 词向量基础 ...
- python就业班-淘宝-目录.txt
卷 TOSHIBA EXT 的文件夹 PATH 列表卷序列号为 AE86-8E8DF:.│ python就业班-淘宝-目录.txt│ ├─01 网络编程│ ├─01-基本概念│ │ 01-网络通信概述 ...
- 自然语言处理高手_相关资源_开源项目(比如:分词,word2vec等)
(1) 中科院自动化所的博士,用神经网络做自然语言处理:http://licstar.net (2) 分词项目:https://github.com/fxsjy/jieba(3) 清华大学搞的中文分词 ...
- word2vec 在 非 自然语言处理 (NLP) 领域的应用
word2vec 本来就是用来解决自然语言处理问题的,它在 NLP 中的应用是显然的. 比如,你可以直接用它来寻找相关词.发现新词.命名实体识别.信息索引.情感分析等:你也可以将词向量作为其他模型的输 ...
- 自然语言处理之word2vec
在word2vec出现之前,自然语言处理经常把字词转为one-hot编码类型的词向量,这种方式虽然非常简单易懂,但是数据稀疏性非常高,维度很多,很容易造成维度灾难,尤其是在深度学习中:其次这种词向量中 ...
- 利用Tensorflow进行自然语言处理(NLP)系列之一Word2Vec
同步笔者CSDN博客(https://blog.csdn.net/qq_37608890/article/details/81513882). 一.概述 本文将要讨论NLP的一个重要话题:Word2V ...
- 自然语言处理工具:中文 word2vec 开源项目,教程,数据集
word2vec word2vec/glove/swivel binary file on chinese corpus word2vec: https://code.google.com/p/wor ...
随机推荐
- android周期性任务
一般任务调度机制的实现方式主要有: Thread sleep.Timer.ScheduledExecutor.Handler和其他第三方开源库.android的AlarmManager 1. Time ...
- Fig 7.2.4 & Fig 7.3.2
Fig 7.2.4 \documentclass[varwidth=true, border=2pt]{standalone} \usepackage{tkz-euclide} \begin{docu ...
- Python学习-21.Python的代码注释
在Python中有两种注释,一种是普通注释,另一种是文档注释. 普通注释是使用#开头 print('output something') # here is comment 而Python中多行注释也 ...
- Change Jenkins time zone
修改Jenkins时区 Debian: vim /etc/defalut/jenkins JAVA_ARGS="-Dorg.apache.commons.jelly.tags.fmt.tim ...
- 8086汇编语言(1)虚拟机安装ms-dos 7.1
8086汇编语言(1)虚拟机安装ms-dos 7.1 文/玄魂 前言 在开始这一系列文章之前,我想先说下,对于古董级的8086汇编到底还以有没有学习的必要.这里我说下我要从8086开始学习,而不是从w ...
- 将GridView的数据导出Excel
HttpContext.Current.Response.AppendHeader("Content-Disposition", "attachment;filename ...
- c#与c++类型
C/C++ C# HANDLE, LPDWORD, LPVOID, void* IntPtr LPCTSTR, LPCTSTR, LPSTR, char*, const char*, Wchar_t* ...
- OSLab课堂作业1
日期:2019/3/16 作业:实现命令cat, cp, echo. myecho命令 #include <stdio.h> int main(int argc, char *ar ...
- Android 为库(library)创建不同编译环境
项目中需要导入库,一般有两种情况,一种是直接路径导入,一种是导入库的 aar 文件. 1. 设置库项目 1. 在库项目的 src 目录下设置 debug 目录,里面可以添加代码或者 res 文件夹. ...
- Python对excel表格的操作.
参考博客: https://blog.csdn.net/lmj19851117/article/details/78814721 ####一.excel的读取操作xlrd#### import xlr ...