【数据结构】 顺序表查找(折半查找&&差值查找)
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAXSIZE 10
首先构造一个数组, 由随机数生成, 同时确保没有重复元素。(为了排序之后查找时候方便)
为了确保没有重复的元素使用了一个简单的查找函数:
用数组的0号元素来作为哨兵
化简了操作:
int search0(int *a,int length,int key)
{
int i;
a[] = key;
i = length;
while(a[i]!=key)
{
i--;
}
return i; //这样如果没有查找到元素,就会return 0;
}
int a[MAXSIZE] = {};
int i;
int find;
int rec;
srand((unsigned)time(NULL));
for(i=;i<MAXSIZE+;i++)
{
a[i] = rand()%+;
while(search0(a,i-,a[i])!=&&i!=&&i!=MAXSIZE+)
a[i]=rand()%+;
}
还需要一个函数 显示数组里所有元素:
void print_List(int *a,int length)
{
int i;
printf("List:");
for(i=;i<length+;i++)
{
printf(" %d ",a[i]);
}
printf("\n");
}
使用冒泡法进行排序:
void sort(int *a,int length)
{
int i,j;
int t;
for(i=;i<length+;i++)
{
for(j=i+;j<length+;j++)
{
if(a[i]>a[j])
{
t = a[i];
a[i] = a[j];
a[j] = t;
}
}
}
}
之后是折半查找的函数:
int search_half(int *a,int length,int key)
{
int low,high,mid;
low = ;
high = length;
int n = ;
while(low<=high)
{
//mid = (low + high)/2; //折半查找
mid = low+ (high - low)*(key-a[low])/(a[high]-a[low]); //差值查找
printf("%d: low = %d high = %d mid = %d\n",n,low,high,mid);
if(key<a[mid])
high= mid - ;
else if (key>a[mid])
low = mid + ;
else
return mid;
n++;
}
return ;
}
首先需要确保是一个有序的表,这样通过比较key 和 mid的大小
如果key小于mid则说明key可能在小于mid的区域 high 调整
如果key大于mid则说明key可能在大于mid的区域 low 调整
相等就找到了
效果如图: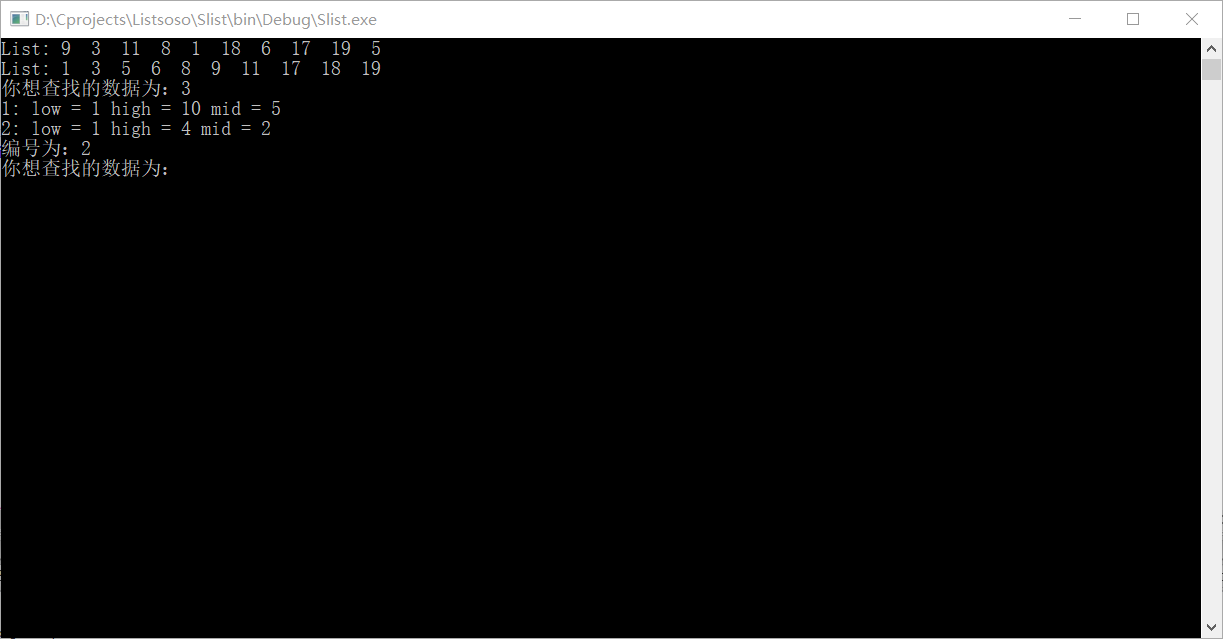
那么另一个问题出现了:为什么一定要折半呢?
比如说在0~1000内查找5 折半就很不明智了吧。
最初的公式可以理解为:
mid = (low+high)/2 = low+1/2*(high - low)
即 在low这个基础数值上附加了一个数值 (这里是选择区间数值的一半), 如果我们想改进这个公式, 显然应该改进那个附加值 改为与key 相关
mid = low+(key-a[low])/(a[high]-a[low])*(highj - low)
比如说还是在 0~1000个内寻找5
第一次的mid 修改为 mid = 0+(5-0)/(1000-0)*1000 = 5 显然能看出 当插值明显很小(或者很大) mid 的取值取决于key在整体的大小趋势, 这样mid也会明显变小(或者很大)
测试, 将MAXSIZE 增大为20
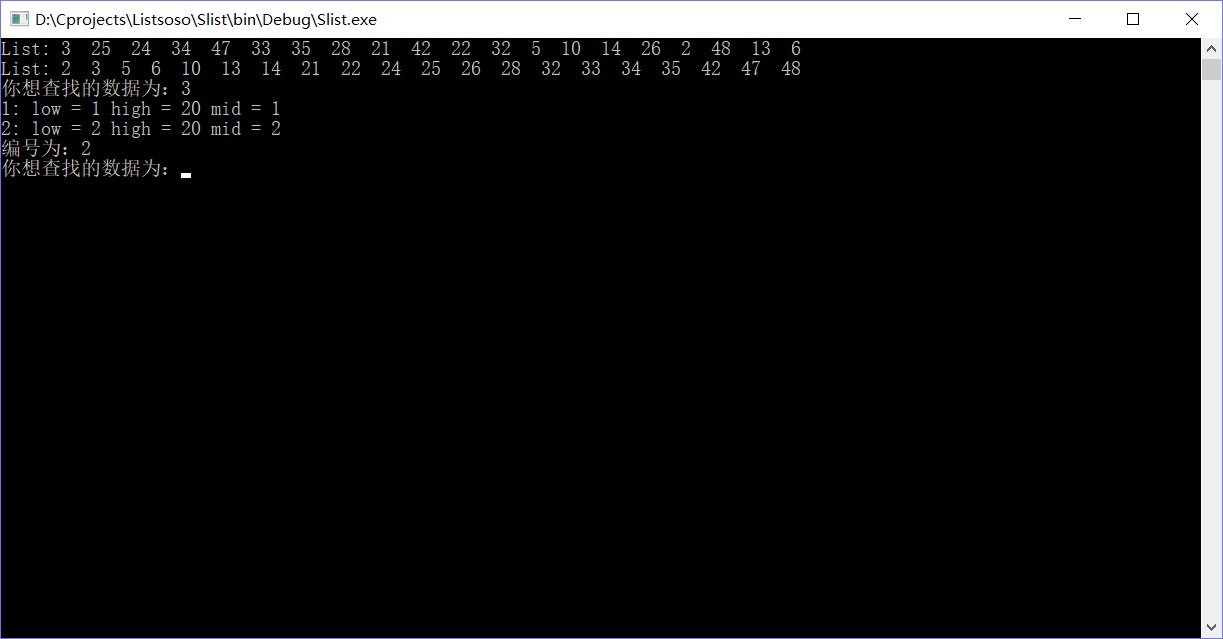
比常规的折半相比, 速度更快了。
完整程序:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAXSIZE 20
void print_List(int *a,int length)
{
int i;
printf("List:");
for(i=;i<length+;i++)
{
printf(" %d ",a[i]);
}
printf("\n");
} void sort(int *a,int length)
{
int i,j;
int t;
for(i=;i<length+;i++)
{
for(j=i+;j<length+;j++)
{
if(a[i]>a[j])
{
t = a[i];
a[i] = a[j];
a[j] = t;
}
}
}
}
int search0(int *a,int length,int key)
{
int i;
a[] = key;
i = length;
while(a[i]!=key)
{
i--;
}
return i;
}
int search_half(int *a,int length,int key)
{
int low,high,mid;
low = ;
high = length;
int n = ;
while(low<=high)
{
//mid = (low + high)/2; //折半查找
mid = low+ (high - low)*(key-a[low])/(a[high]-a[low]); //差值查找
printf("%d: low = %d high = %d mid = %d\n",n,low,high,mid);
if(key<a[mid])
high= mid - ;
else if (key>a[mid])
low = mid + ;
else
return mid;
n++;
}
return ;
}
int main()
{
int a[MAXSIZE] = {};
int i;
int find;
int rec;
srand((unsigned)time(NULL));
for(i=;i<MAXSIZE+;i++)
{
a[i] = rand()%+;
while(search0(a,i-,a[i])!=&&i!=&&i!=MAXSIZE+)
a[i]=rand()%+;
}
print_List(a,MAXSIZE);
sort(a,MAXSIZE);
print_List(a,MAXSIZE);
while()
{
printf("你想查找的数据为:");
scanf("%d",&find);
rec=search_half(a,MAXSIZE,find);
if(rec != )
printf("编号为:%d\n",rec);
else
printf("没找到\n");
}
return ;
}
【数据结构】 顺序表查找(折半查找&&差值查找)的更多相关文章
- hrbustoj 1545:基础数据结构——顺序表(2)(数据结构,顺序表的实现及基本操作,入门题)
基础数据结构——顺序表(2) Time Limit: 1000 MS Memory Limit: 10240 K Total Submit: 355(143 users) Total Accep ...
- hrbust-1545-基础数据结构——顺序表(2)
http://acm.hrbust.edu.cn/index.php?m=ProblemSet&a=showProblem&problem_id=1545 基础数据结构——顺序表(2) ...
- 数据结构---顺序表(C++)
顺序表 是用一段地址连续的存储单元依次存储线性表的数据元素. 通常用一维数组来实现 基本操作: 初始化 销毁 求长 按位查找 按值查找 插入元素 删除位置i的元素 判空操作 遍历操作 示例代码: // ...
- 数据结构——顺序表(sequence list)
/* sequenceList.c */ /* 顺序表 */ /* 线性表的顺序存储是指在内存中用地址连续的一块存储空间顺序存放线性表中的各项数据元素,用这种存储形式的线性表称为顺序表. */ #in ...
- 数据结构 - 顺序表 C++ 实现
顺序表 此处实现的顺序表为**第一个位置为 data[0] **的顺序表 顺序表的定义为 const int MAX = 50; typedef int ElemType; typedef struc ...
- python算法与数据结构-顺序表(37)
1.顺序表介绍 顺序表是最简单的一种线性结构,逻辑上相邻的数据在计算机内的存储位置也是相邻的,可以快速定位第几个元素,中间不允许有空,所以插入.删除时需要移动大量元素.顺序表可以分配一段连续的存储空间 ...
- 数据结构顺序表中Sqlist *L,&L,Sqlist *&L
//定义顺序表L的结构体 typedef struct { Elemtype data[MaxSize]: int length; }SqList; //建立顺序表 void CreateList(S ...
- c数据结构 顺序表和链表 相关操作
编译器:vs2013 内容: #include "stdafx.h"#include<stdio.h>#include<malloc.h>#include& ...
- 数据结构顺序表删除所有特定元素x
顺序表类定义: template<class T> class SeqList : { public: SeqList(int mSize); ~SeqList() { delete[] ...
随机推荐
- 数组操作方法中的splice()和concat() 以及slice()
1.splice()方法是修改Array的'全能方法',它可以从指定的索引开始删除若干元素,然后再从该位置添加若干元素,其中有三个参数(x,y,z) x:从索引x开始操作数组; y:0或不为0,当为0 ...
- 二维码ZBar之ZBarReaderView
参考:http://www.chinatarena.com/Html/iospeixun/201301/3985.html http://blog.csdn.net/chenyong05314/a ...
- [转]Using Browser Link in Visual Studio 2013
本文转自:https://docs.microsoft.com/en-us/aspnet/visual-studio/overview/2013/using-browser-link Browser ...
- .NET创建WebService服务简单的例子
Web service是一个基于可编程的web的应用程序,用于开发分布式的互操作的应用程序,也是一种web服务 WebService的特性有以下几点: 1.使用XML(标准通用标记语言)来作为数据交互 ...
- ASP.NET 预编译笔记
本来下写篇总结,但感觉自己语言不知道怎么组织.就算了. aspnet_compiler的问题: 一开始 aspnet_compiler -v \ -p F: E: -fixednames e ...
- MyBatis源码解析之数据源(含数据库连接池简析)
一.概述: 常见的数据源组件都实现了javax.sql.DataSource接口: MyBatis不但要能集成第三方的数据源组件,自身也提供了数据源的实现: 一般情况下,数据源的初始化过程参数较多,比 ...
- 地址解析协议ARP,网络层协议IP、ICMP协议
分析所用软件下载:Wireshark-win32-1.10.2.exe 阅读导览 1. 分析并且应用ARP协议 2.分析IP协议 3.分析ICMP协议 1.分析arp报文的格式与内容 (1)ping ...
- 中小型研发团队架构实践七:集中式日志ELK
一.集中式日志 日志可分为系统日志.应用日志以及业务日志,系统日志给运维人员使用,应用日志给研发人员使用,业务日志给业务操作人员使用.我们这里主要讲解应用日志,通过应用日志来了解应用的信息和状态,以及 ...
- node.js(http协议)
七层网络协议 应用层:浏览器(http,FTP,DNS,SMTP,TeInet)(邓哥)表示层:加密,格式转换(怕别人偷看,加密摩斯电码)会话层:解除或者建立和其他节点的联系(邓哥在想追这个女孩,不再 ...
- Vue双向绑定原理详解
前言:Vue最核心的功能之一就是响应式的数据绑定模式,即view与model任意一方改变都会同步到另一方,而不需要手动进行DOM操作,本文主要探究此功能背后的原理. 思路分析 以下是一个最简单的双向绑 ...