数据迁移之Sqoop
一 简介
Apache Sqoop(TM)是一种用于在Apache Hadoop和结构化数据存储(如关系数据库)之间高效传输批量数据的工具 。
官方下载地址:http://www.apache.org/dyn/closer.lua/sqoop/1.4.7
1. Sqoop是什么
Sqoop:SQL-to-Hadoop
连接 传统关系型数据库 和 Hadoop 的桥梁
把关系型数据库的数据导入到 Hadoop 系统 ( 如 HDFS HBase 和 Hive) 中;
把数据从 Hadoop 系统里抽取并导出到关系型数据库里。
利用MapReduce加快数据传输速度 : 将数据同步问题转化为MR作业
批处理方式进行数据传输:实时性不够好
2. Sqoop优势
高效、可控地利用资源
任务并行度,超时时间等
数据类型映射与转换
可自动进行,用户也可自定义
支持多种数据库
MySQL,Oracle,PostgreSQL
3. Sqoop import
将数据从关系型数据库导入Hadoop中
步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
步骤2:Sqoop启动一个Map-Only的MR作业,利用元数据信息并行将数据写入Hadoop。
特点:可以指定hdfs路径,指定关系数据库的表,字段,连接数(不压垮数据库),可以导入多个表,支持增量导入(手动指定起始id、事件,或自动记录上次结束位置,自动完成增量导入)
4. Sqoop Export
将数据从Hadoop导入关系型数据库导中
步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
步骤2:并行导入数据:
将Hadoop上文件划分成若干个split;
每个split由一个Map Task进行数据导入。
5. Sqoop与其他系统结合
Sqoop可以与Oozie、Hive、Hbase等系统结合;
二、sqoop的安装与使用
Sqoop是一个转换工具,用于在关系型数据库与HDFS之间进行数据转换。强大功能见下图
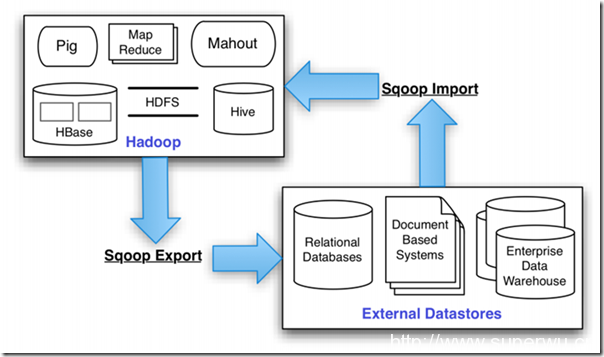
以下操作就是使用sqoop在mysql和hdfs之间转换数据。
1. 安装
首先就是解压缩,重命名为sqoop,然后在文件/etc/profile中设置环境变量SQOOP_HOME。
把mysql的jdbc驱动mysql-connector-java-5.1.10.jar复制到sqoop项目的lib目录下。
2. 重命名配置文件
在${SQOOP_HOME}/conf中执行命令
mv sqoop-env-template.sh sqoop-env.sh 生效即可,不用改内容
在conf目录下,有两个文件sqoop-site.xml和sqoop-site-template.xml内容是完全一样的,不必在意,我们只关心sqoop-site.xml即可。
3. 修改配置文件sqoop-env.sh
内容如下
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/local/hadoop/
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/local/hadoop
#set the path to where bin/hbase is available
export HBASE_HOME=/usr/local/hbase
#Set the path to where bin/hive is available
export HIVE_HOME=/usr/local/hive
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/usr/local/zk
好了,搞定了,下面就可以运行了。
安装通过查看版本 sqoop version
测试连接mysql
sqoop list-databases -connect jdbc:mysql://node001:3306/ -username root -password 123
4. 数据从mysql导入到hdfs中
在mysql中数据库test中有一张表是aa,表中的数据如下图所示

现在我们要做的是把aa中的数据导入到hdfs中,执行命令如下
格式: Import 连接数据库 (导入文件类型) 表名 列名 目标位置 作业数
sqoop ##sqoop命令
import ##表示导入
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password admin ##连接mysql的密码
--table aa ##从mysql导出的表名称
--fields-terminated-by '\t' ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
以上的命令中后面的##部分是注释,执行的时候需要删掉;另外,命令的所有内容不能换行,只能一行才能执行。以下操作类似。
该命令执行结束后,观察hdfs的目录/user/{USER_NAME},下面会有一个文件夹是aa,里面有个文件是part-m-00000。该文件的内容就是数据表aa的内容,字段之间是使用制表符分割的。
import
--connect
jdbc:mysql://node001:3306/test
--username
root
--password
123
--as-textfile
--columns
id,name,msg
--table
psn
--delete-target-dir
--target-dir
/sqoop/data
-m
1
命令:sqoop --options-file sqoop1
5. 数据从hdfs导出到mysql中
把上一步导入到hdfs的数据导出到mysql中。我们已知该文件有两个字段,使用制表符分隔的。那么,我们现在数据库test中创建一个数据表叫做bb,里面有两个字段。然后执行下面的命令
sqoop
export ##表示数据从hive复制到mysql中
--connect jdbc:mysql://192.168.1.113:3306/test
--username root
--password admin
--table bb ##mysql中的表,即将被导入的表名称
--export-dir '/user/root/aa/part-m-00000' ##hive中被导出的文件
--fields-terminated-by '\t' ##hive中被导出的文件字段的分隔符
命令执行完后,再去观察表bb中的数据,是不是已经存在了!
export
--connect
jdbc:mysql://node001/test
--username
root
--password
123
-m
1
--table
h_psn
--columns
id,name,msg
--export-dir
/sqoop/data
l Hadoop启动时,出现 Warning:$HADOOP_HOME is deprecated 的原因
我们在执行脚本start-all.sh,启动hadoop时,有时会出现如下图的警告信息
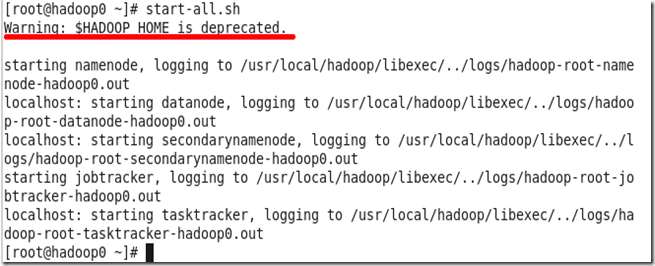
虽然不影响程序运行,但是看到这样的警告信息总是觉得自己做得不够好,怎么去掉哪?
我们一步步分享,先看一下启动脚本start-all.sh的源码,如下图
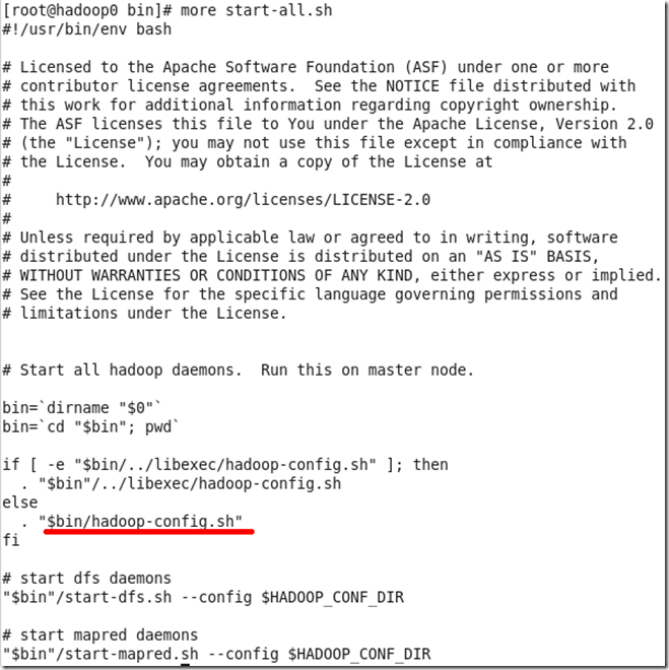
虽然我们看不懂shell脚本的语法,但是可以猜到可能和文件hadoop-config.sh有关,我们再看一下这个文件的源码。该文件特大,我们只截取最后一部分,见下图
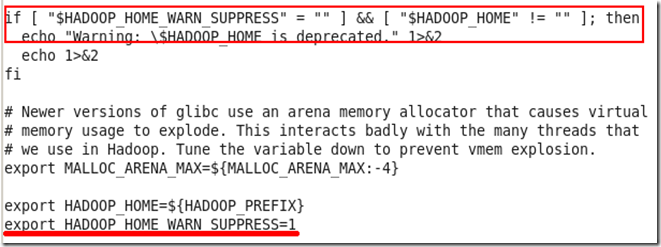
从图中的红色框框中可以看到,脚本判断变量HADOOP_HOME_WARN_SUPPRESS和HADOOP_HOME的值,如果前者为空,后者不为空,则显示警告信息“Warning……”。
我们在安装hadoop是,设置了环境变量HADOOP_HOME造成的。
网上有的说新的hadoop版本使用HADOOP_INSTALL作为环境变量,我还没有看到源代码,并且担心其他框架与hadoop的兼容性,所以暂时不修改,那么只好设置HADOOP_HOME_WARN_SUPPRESS的值了。
修改配置文件/etc/profile(我原来一直在这里设置环境变量,操作系统是rhel6.3),增加环境变量HADOOP_HOME_WARN_SUPPRESS,如下图
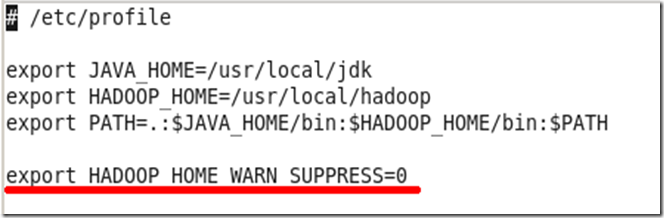
保存退出,再次启动hadoop,就不会出现警告信息了,如下图

1、列出mysql数据库中的所有数据库
sqoop list-databases --connect jdbc:mysql://localhost:3306/ -username dyh -password 000000
2、连接mysql并列出数据库中的表
sqoop list-tables --connect jdbc:mysql://localhost:3306/test --username dyh --password 000000
3、将关系型数据的表结构复制到hive中
sqoop create-hive-table --connect jdbc:mysql://localhost:3306/test --table users --username dyh
--password 000000 --hive-table users --fields-terminated-by "\0001" --lines-terminated-by "\n";
参数说明:
--fields-terminated-by "\0001" 是设置每列之间的分隔符,"\0001"是ASCII码中的1,它也是hive的默认行内分隔符, 而sqoop的默认行内分隔符为","
--lines-terminated-by "\n" 设置的是每行之间的分隔符,此处为换行符,也是默认的分隔符;
注意:只是复制表的结构,表中的内容没有复制
4、将数据从关系数据库导入文件到hive表中
sqoop import --connect jdbc:mysql://localhost:3306/test --username dyh --password 000000
--table users --hive-import --hive-table users -m 2 --fields-terminated-by "\0001";
参数说明:
-m 2 表示由两个map作业执行;
--fields-terminated-by "\0001" 需同创建hive表时保持一致;
5、将hive中的表数据导入到mysql数据库表中
sqoop export --connect jdbc:mysql://192.168.20.118:3306/test --username dyh --password 000000
--table users --export-dir /user/hive/warehouse/users/part-m-00000
--input-fields-terminated-by '\0001'
注意:
1、在进行导入之前,mysql中的表userst必须已经提起创建好了。
2、jdbc:mysql://192.168.20.118:3306/test中的IP地址改成localhost会报异常,具体见本人上一篇帖子
6、将数据从关系数据库导入文件到hive表中,--query 语句使用
sqoop import --append --connect jdbc:mysql://192.168.20.118:3306/test --username dyh --password 000000 --query "select id,age,name from userinfos where \$CONDITIONS" -m 1 --target-dir /user/hive/warehouse/userinfos2 --fields-terminated-by ",";
7、将数据从关系数据库导入文件到hive表中,--columns --where 语句使用
sqoop import --append --connect jdbc:mysql://192.168.20.118:3306/test --username dyh --password 000000 --table userinfos --columns "id,age,name" --where "id > 3 and (age = 88 or age = 80)" -m 1 --target-dir /user/hive/warehouse/userinfos2 --fields-terminated-by ",";
注意:--target-dir /user/hive/warehouse/userinfos2 可以用 --hive-import --hive-table userinfos2 进行替换
三、Sqoop选项含义说明
|
选项 |
含义说明 |
|
--connect <jdbc-uri> |
指定JDBC连接字符串 |
|
--connection-manager <class-name> |
指定要使用的连接管理器类 |
|
--driver <class-name> |
指定要使用的JDBC驱动类 |
|
--hadoop-mapred-home <dir> |
指定$HADOOP_MAPRED_HOME路径 |
|
--help |
万能帮助 |
|
--password-file |
设置用于存放认证的密码信息文件的路径 |
|
-P |
从控制台读取输入的密码 |
|
--password <password> |
设置认证密码 |
|
--username <username> |
设置认证用户名 |
|
--verbose |
打印详细的运行信息 |
|
--connection-param-file <filename> |
可选,指定存储数据库连接参数的属性文件 |
|
选选项项 |
含义说明含义说明 |
|
--append |
将数据追加到HDFS上一个已存在的数据集上 |
|
--as-avrodatafile |
将数据导入到Avro数据文件 |
|
--as-sequencefile |
将数据导入到SequenceFile |
|
--as-textfile |
将数据导入到普通文本文件(默认) |
|
--boundary-query <statement> |
边界查询,用于创建分片(InputSplit) |
|
--columns <col,col,col…> |
从表中导出指定的一组列的数据 |
|
--delete-target-dir |
如果指定目录存在,则先删除掉 |
|
--direct |
使用直接导入模式(优化导入速度) |
|
--direct-split-size <n> |
分割输入stream的字节大小(在直接导入模式下) |
|
--fetch-size <n> |
从数据库中批量读取记录数 |
|
--inline-lob-limit <n> |
设置内联的LOB对象的大小 |
|
-m,--num-mappers <n> |
使用n个map任务并行导入数据 |
|
-e,--query <statement> |
导入的查询语句 |
|
--split-by <column-name> |
指定按照哪个列去分割数据 |
|
--table <table-name> |
导入的源表表名 |
|
--where <where clause> |
指定导出时所使用的查询条件 |
|
-z,--compress |
启用压缩 |
|
--compression-codec <c> |
指定Hadoop的codec方式(默认gzip) |
|
--null-string <null-string> |
如果指定列为字符串类型,使用指定字符串替换值为null的该类列的值 |
|
--null-non-string <null-string> |
如果指定列为非字符串类型,使用指定字符串替换值为null的该类列的值 |
|
选项 |
含义说明 |
|
--validate <class-name> |
启用数据副本验证功能,仅支持单表拷贝,可以指定验证使用的实现类 |
|
--validation-threshold <class-name> |
指定验证门限所使用的类 |
|
--direct |
使用直接导出模式(优化速度) |
|
--export-dir <dir> |
导出过程中HDFS源路径 |
|
--m,--num-mappers <n> |
使用n个map任务并行导出 |
|
--table <table-name> |
导出的目的表名称 |
|
--call <stored-proc-name> |
导出数据调用的指定存储过程名 |
|
--update-key <col-name> |
更新参考的列名称,多个列名使用逗号分隔 |
|
--update-mode <mode> |
指定更新策略,包括:updateonly(默认)、allowinsert |
|
--input-null-string <null-string> |
使用指定字符串,替换字符串类型值为null的列 |
|
--input-null-non-string <null-string> |
使用指定字符串,替换非字符串类型值为null的列 |
|
--staging-table <staging-table-name> |
在数据导出到数据库之前,数据临时存放的表名称 |
|
--clear-staging-table |
清除工作区中临时存放的数据 |
|
--batch |
使用批量模式导出 |
四、Hive月HBase的整合
1. hive和hbase同步官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration
2. jar包拷贝
把hbase中的所有的jar,cp到hive/lib中,
同时把hive-hbase-handler-1.2.1.jar cp到hbase/lib 下
3. hive的配置文件增加属性:
伪分布式 完全分布式zookeeper管理
<property>
<name>hbase.zookeeper.quorum</name>
<value>node002,node003,node004</value>
</property>
4. 在hive中创建临时表
外部表创建需要hbase数据库有与之对应的表已存在,否则创建失败
CREATE EXTERNAL TABLE tmp_order
(key string, id string, user_id string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,order:order_id,order:user_id")
TBLPROPERTIES ("hbase.table.name" = "t_order");
内部表创建,hbase上自动创建
CREATE TABLE hbasetbl(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
TBLPROPERTIES ("hbase.table.name" = "xyz", "hbase.mapred.output.outputtable" = "xyz");
数据迁移之Sqoop的更多相关文章
- 跨库数据迁移利器 —— Sqoop
一.Sqoop 基本命令 1. 查看所有命令 # sqoop help 2. 查看某条命令的具体使用方法 # sqoop help 命令名 二.Sqoop 与 MySQL 1. 查询MySQL所有数据 ...
- sqoop 数据迁移
sqoop 数据迁移 1 概述 sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具. 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIVE.H ...
- sqoop数据迁移(基于Hadoop和关系数据库服务器之间传送数据)
1:sqoop的概述: (1):sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具.(2):导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIV ...
- 【Hadoop离线基础总结】Sqoop数据迁移
目录 Sqoop介绍 概述 版本 Sqoop安装及使用 Sqoop安装 Sqoop数据导入 导入关系表到Hive已有表中 导入关系表到Hive(自动创建Hive表) 将关系表子集导入到HDFS中 sq ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
- Oracle数据迁移至HBase操作记录
Oracle数据迁移至HBase操作记录 @(HBase) 近期需要把Oracle数据库中的十几张表T级别的数据迁移至HBase中,过程中遇到了许多苦难和疑惑,在此记录一下希望能帮到一些有同样需求的兄 ...
- 从MySQL到Hive,数据迁移就这么简单
使用Sqoop能够极大简化MySQL数据迁移至Hive之流程,并降低Hadoop处理分析任务时的难度. 先决条件:安装并运行有Sqoop与Hive的Hadoop环境.为了加快处理速度,我们还将使用Cl ...
- 13_sqoop数据迁移概述
3. sqoop数据迁移 3.1 概述 sqoop是apache旗下一款“Hadoop体系和关系数据库服务器之间传送数据”的工具. 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS. ...
- 2.1 关系型数据的收集--Sqoop
Sqoop应用场景: 1.数据迁移,将关系型数据库中的数据导入Hadoop存储系统 2.可视化分析结果,将Hadoop处理之后产生的结果导入关系型数据库,以便进行可视化展示 3.数据增量导入:减少ha ...
随机推荐
- Linux运维一:生产环境CentOS6.6系统的安装
CentOS 6.6 x86_64官方正式版系统(64位)下载地址 系统之家:http://www.xitongzhijia.net/linux/201412/33603.html 百度网盘:http ...
- 百度定位api 定位不准修正
https://www.zhihu.com/question/38313555 在安卓开发中需要设置 setCoorType("bd09lsetCoorType("bd09ll ...
- Windows 2012 R2 安装net4.6.1
下载并安装Net4.6.1 根据提示下载如下,并安装 https://support.microsoft.com/zh-cn/help/2919355/windows-rt-8-1--windows- ...
- np.isin判断数组元素在另一数组中是否存在
np.isin用法 觉得有用的话,欢迎一起讨论相互学习~Follow Me np.isin(a,b) 用于判定a中的元素在b中是否出现过,如果出现过返回True,否则返回False,最终结果为一个形状 ...
- MAC下 Apache服务器配置
今天做了一个注册登录提交的页面,后续操作需要用到后端的知识 php+Mysql,之前只是有些了解,现在开始具体操作了,首先从配置环境开始.查了好几篇文档与博客,了解了挺多知识. Mac下Apache服 ...
- React - 环境准备
1. 下载 node.js,在 https://nodejs.org/en/download/ 选择合适的版本. 2. 检查 node.js 是否安装成功. hueyMB:~ zhisenzheng$ ...
- HDU 2087 剪花布条 (KMP 不允许重叠的匹配)
题目链接 Problem Description 一块花布条,里面有些图案,另有一块直接可用的小饰条,里面也有一些图案.对于给定的花布条和小饰条,计算一下能从花布条中尽可能剪出几块小饰条来呢? Inp ...
- log4net记录系统错误日志到文本文件用法详解
log4net是一个完全免费开源的插件,可以去官网下载源码. 一般系统操作日志不会用log4net,自己写代码存入数据库更方便合理,但是系统部署后运行在客户环境,难免会发生系统bug.崩溃.断网等无法 ...
- VS2010 项目属性的默认包含路径设置方法
VS2010 项目属性的默认包含路径设置方法 分类: c++小技巧2014-01-10 10:16 1358人阅读 评论(0) 收藏 举报 c++ 有两种方法可以设置vs2010的默认包含路径 方法一 ...
- Vagrant 无法校验手动下载的 Homestead Box 版本
起因 4年前电脑,配置不太好了,现有的 Homestead 运行起来太吃内存.在修改了 Homestead.yaml 文件里 memory 选项的内存配置为 1024 后,应用最新配置重启失败. 索性 ...