SQLServer之视图篇
1 视图介绍
视图是从一个或者多个表导出的,它的行为与表非常相似,但视图是一个虚拟表,在视图中可以使用SELECT语句查询数据,以及使用insert、update和delete语句修改记录,对于视图的操作最终转化为对基本数据表的操作。视图不仅可以方便操作,而且可以保障数据库系统的安全性。
视图一经定义便存储在数据库中,与其相对应的数据并没有像表数据那样在数据库中在存储一份,通过视图看到的数据只是存放在基本表中的数据。可以对其进行增删该查,通过视图对数据修改,基本表数据也对应变化,反之亦然。
1.2 使用视图的目的与好处
1.聚焦特定数据:使用户只能看到和操作与他们有关的数据,提高了数据的安全性。
2.简化数据操作:使用户不必写复杂的查询语句就可对数据进行操作。
3.定制用户数据:使不同水平的用户能以不同的方式看到不同的数据。
4.合并分离数据:视图可以从水平和垂直方向上分割数据,但原数据库的结构保持不变。
2 创建视图
语法:
| [ with check option ] --强制所有通过是同修改的数据,都要满足select语句中指定的条件
select查询语句
as
[ with encryption ] --用于加密视图的定义,用户只能查看不能修改。
[ (列名表) ]
create view 视图
|
先创建一个学生表
|
use marvel_db;
--创建一个学生表
create table stuTable(
id int identity(1,1)primary key,--id 主键,自增
name varchar(20),
gender char(2),
age int,
)
--往表中插入数据
insert into stuTable (name,gender,age)
values
('刘邦','男',23),
('项羽','男',22),
('韩信','男',21);
insert into stuTable(name,gender,age) values('萧何','男',24) |
创建视图
|
--创建视图
if (exists (select * from sys.objects where name = 'stu_view'))
drop view stu_view
go
--stu_view()不实用参数,默认为基础表中的列名称
--注意 create view 必须是批处理里面的语句
create view stu_view
as
select name,age from stuTable where age>20;
go
--执行视图
select * from stu_view; |
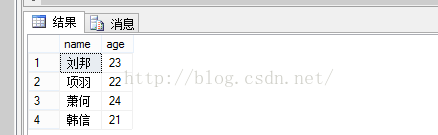
查询结果:
3 修改视图
|
go
alter view stu_view
as
select * from stuTable where age>22;
go
select * from stu_view |
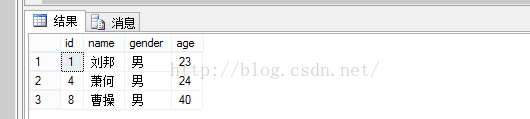
显示结果:
4 删除视图
|
go
--语法
drop view view_name1,view_name2,......,view_nameN;
--该语句可以同时删除多个视图,只要在删除各视图名称之间用逗号分隔即可。
|
例如:删除视图 stu_view
|
--语法
drop view stu_view;
--该语句可以同时删除多个视图,只要在删除各视图名称之间用逗号分隔即可。 |
5 通过视图管理表中的数据
注意:
1.可通过视图向基表中插入数据,但插入的数据实际上存放在基表中,而不是存放在视图中。
2.如果视图引用了多个表,使用insert语句插入的列必须属于同一个表。
3.若创建视图时定义了“with check option”选项,则使用视图向基表中插入数据时,必须保证插入后的数据满足定义视图的限制条件。
|
--(1).通过视图向基本表中插入数据
go
create view stu_insert_view(编号,姓名,性别,年龄)
as
select id,name,gender,age from stuTable;
go
select * from stuTable;
---插入一条数据
insert into stu_insert_view values('孙权','男',34);
----查看插入记录之后表中的内容。
select * from stuTable; |
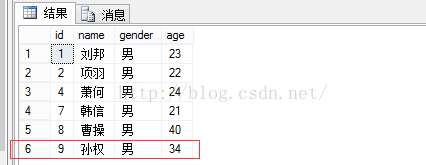
显示结果:
(2).通过视图修改基本表的数据
| --查看修改之前的数据 select * from stuTable; |
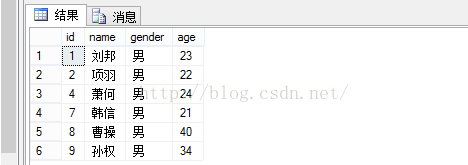
显示结果:
|
--修改数据
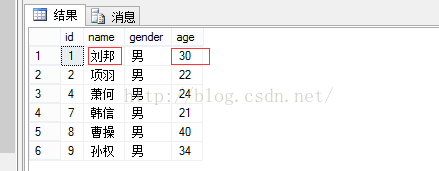
update stu_insert_view set 年龄=30 where 姓名='刘邦';
--查看修改后的数据
select * from stuTable; |
结果显示:
(3).通过视图删除基本表的数据
注意:
1.要删除的数据必须包含在视图的结果集中。
2.如果视图引用了多个表时,无法用delete命令删除数据。
语法
| --语法 delete stu_insert_view where condition; |
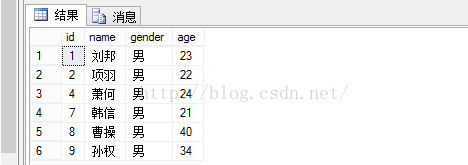
删除之前:
删除:
|
--例子
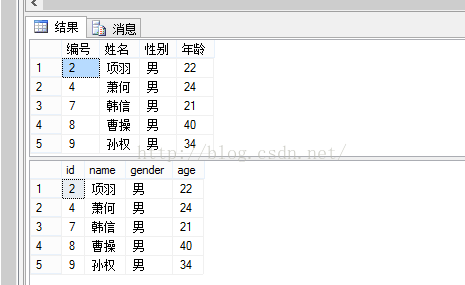
delete stu_insert_view where 姓名 ='刘邦';
select * from stu_insert_view;
select * from stuTable; |
显示结果:
6总结
2.涉及到权限管理方面,比如某表中的部分字段含有机密信息,不应当让低权限的用户访问到的情况,这时候给这些用户提供一个适合他们权限的视图,供他们阅读自己的数据就行了。
2.视图与表的区别:
1.视图是已经编译好的SQL语句,是基于SQL语句的结果集的可视化表,而表不是;
2.视图(除过索引视图)没有实际的物理记录,而基本表有;
3.表示内容,视图是窗口;
4.表占物理空间,而视图不占物理空间,视图只是逻辑概念的存在;
5.视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全角度说,视图可以防止用户接触数据表,从而不知表结构;
6.表属于全局模式的表,是实表;视图数据局部模式的表,是虚表;
7.视图的建立和删除只影响视图本身,不影响对应的基本表。
转载自:https://blog.csdn.net/marvel_java/article/details/53353475
SQLServer之视图篇的更多相关文章
- 解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译)
解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译) http://improve.dk/the-anatomy-of-row-amp-page-compre ...
- 解剖SQLSERVER 第十七篇 使用 OrcaMDF Corruptor 故意损坏数据库(译)
解剖SQLSERVER 第十七篇 使用 OrcaMDF Corruptor 故意损坏数据库(译) http://improve.dk/corrupting-databases-purpose-usin ...
- 解剖SQLSERVER 第七篇 OrcaMDF 特性概述(译)
解剖SQLSERVER 第七篇 OrcaMDF 特性概述(译) http://improve.dk/orcamdf-feature-recap/ 时间过得真快,这已经过了大概四个月了自从我最初介绍我 ...
- 解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)
解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译) http://improve.dk/orcamdf-now-supports-databases-with-mult ...
- 解剖SQLSERVER 第十篇 OrcaMDF Studio 发布+ 特性重温(译)
解剖SQLSERVER 第十篇 OrcaMDF Studio 发布+ 特性重温(译) http://improve.dk/orcamdf-studio-release-feature-recap/ ...
- 解剖SQLSERVER 第十一篇 对SQLSERVER的多个版本进行自动化测试(译)
解剖SQLSERVER 第十一篇 对SQLSERVER的多个版本进行自动化测试(译) http://improve.dk/automated-testing-of-orcamdf-against ...
- 解剖SQLSERVER 第三篇 数据类型的实现(译)
解剖SQLSERVER 第三篇 数据类型的实现(译) http://improve.dk/implementing-data-types-in-orcamdf/ 实现对SQLSERVER数据类型的解 ...
- 解剖SQLSERVER 第四篇 OrcaMDF里对dates类型数据的解析(译)
解剖SQLSERVER 第四篇 OrcaMDF里对dates类型数据的解析(译) http://improve.dk/parsing-dates-in-orcamdf/ 在SQLSERVER里面有几 ...
- 解剖SQLSERVER 第五篇 OrcaMDF里读取Bits类型数据(译)
解剖SQLSERVER 第五篇 OrcaMDF里读取Bits类型数据(译) http://improve.dk/reading-bits-in-orcamdf/ Bits类型的存储跟SQLSERVE ...
随机推荐
- YOLO end-to-end
1.YOLO: You Only Look Once:Unified, Real-Time Object Detection YOLO是一个可以一次性预测多个Box位置和类别的卷积神经网络,能够实现端 ...
- 安装使用Entity Framework Power Tool Bate4 (Code First)从已建好的数据自动生成项目中的对应Model(新手贴,望各位大侠给予指点)
从开始学习使用MVC以后,同时也开始接触EF,很多原理都不是太懂,只知道安装了EF以后,点击哪里可以生成数据库对应的Model,不用再自己手写Model.这里记录的就是如何从已建立好的数据库生成项目代 ...
- Winform解决界面重绘闪烁的问题
在窗体或用户控件中重写CreateParams protected override CreateParams CreateParams { get { CreateParams cp = base. ...
- ASP.NET CORE之上传文件夹
最近闲余时间在做一个仿百度网盘的项目,其中就有一个上传文件夹的功能.查了下网上好像对这个问题的描述比较少,所以在此记录一下. 1.网上找来找去发现webkitdirectory这个东西,H5的一个新的 ...
- Python-实现图表绘制总结
Numpy是Python开源的数值计算扩展,可用来存储和处理大型矩阵,比Python自身数据结构要高效: matplotlib是一个Python的图像框架,使用其绘制出来的图形效果和MATLAB下绘制 ...
- Spark踩坑——java.lang.AbstractMethodError
今天新开发的Structured streaming部署到集群时,总是报这个错: SLF4J: Class path contains multiple SLF4J bindings. SLF4J: ...
- vue.js 的起步
vue.js 的起步 转载 作者:伯乐在线专栏作者 - 1000copy 点击 → 了解如何加入专栏作者 如需转载,发送「转载」二字查看说明 介绍 vue.js 是一个客户端js库,可以用来开发单页应 ...
- 人工智能-机器学习之Selenium(chrome驱动,火狐驱动)
selenium是一个用于web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE.Mozilla Firefox.Mozilla Suite等 ...
- NPM(Node Package Manager,Node包管理器)
简介 每个Node应用都有一个包含该应用元数据的文件-package.json,包含应用名.版本号以及依赖等信息. 我们使用NPM从NPM库下载并安装第三方包. 所有下载的包以及其依赖都保存在node ...
- git merge 的过程及冲突处理演示
master分支上有一个1.txt文件,进行修改后提交 $ cat 1.txt 1 11 12 $ echo 13 >> 1.txt $ git commit -a -m "mo ...