隐马尔科夫模型(HMM)与词性标注问题
一、马尔科夫过程:
在已知目前状态(现在)的条件下,它未来的演变(将来)不依赖于它以往的演变 (过去 )。例如森林中动物头数的变化构成——马尔可夫过程。在现实世界中,有很多过程都是马尔可夫过程,如液体中微粒所作的布朗运动、传染病受感染的人数、车站的候车人数等,都可视为马尔可夫过程。
二、马尔科夫链:
时间和状态都是离散的马尔可夫过程称为马尔可夫链,简记为Xn=X(n),n=0,1,2…
三、马尔可夫模型(Markov Model):
是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。
一个马尔科夫过程包括一个初始向量和一个状态转移矩阵。关于这个假设需要注意的一点是状态转移概率不随时间变化。
四、隐马尔科夫模型:
(1)概述
在某些情况下马尔科夫过程不足以描述我们希望发现的模式。譬如,一个隐居的人可能不能直观的观察到天气的情况,但是有一些海藻。民间的传说告诉我们海藻的状态在某种概率上是和天气的情况相关的。在这种情况下我们有两个状态集合,一个可以观察到的状态集合(海藻的状态)和一个隐藏的状态(天气的状况)。我们希望能找到一个算法可以根据海藻的状况和马尔科夫假设来预测天气的状况。
其中,隐藏状态的数目和可以观察到的状态的数目可能是不一样的。在语音识别中,一个简单的发言也许只需要80个语素来描述,但是一个内部的发音机制可以产生不到80或者超过80种不同的声音。同理,在一个有三种状态的天气系统(sunny、cloudy、rainy)中,也许可以观察到四种潮湿程度的海藻(dry、dryish、damp、soggy)。在此情况下,可以观察到的状态序列和隐藏的状态序列是概率相关的。于是我们可以将这种类型的过程建模为一个隐藏的马尔科夫过程和一个和这个马尔科夫过程概率相关的并且可以观察到的状态集合。
(2)HMM的模型表示
HMM由隐含状态S、可观测状态O、初始状态概率矩阵pi、隐含状态概率转移矩阵A、可观测值转移矩阵B(混淆矩阵)组成。
pi和A决定了状态序列,B决定了观测序列,因此,HMM可以由三元符号表示:
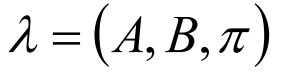
HMM的两个性质:
1. 齐次假设:
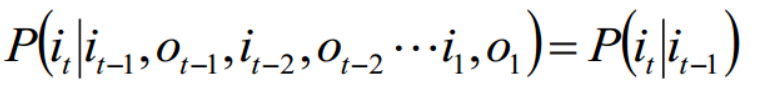
2.观测独立性假设:

齐次假设:本质就是时刻t的状态为qi,原本是要给定t时刻之前的所有状态和观测才可以确定,但是其实我们给出前一个时刻t-1的状态就可将t时刻与之前隔断,也就是说我们假设t时刻与t-1之前的所有状态和观测是独立的。
观测独立性假设:本质就是t时刻的观测为ot,原本是要给定包括t时刻和t时刻之前所有的观测和状态才能确定,现在我们给定t时刻状态qi就将ot与前边隔断,也就是说我们假设t时刻的观测ot与t时刻之前的所有状态和观测是独立的
(3)HMM的三个问题
概率计算问题:前向-后向算法----动态规划
给定模型 λ = (A, B, π)和观测序列O={o1, o2, o3 ...},计算模型λ下观测O出现的概率P(O | λ)
学习问题:Baum-Welch算法----EM算法
已知观测序列O={o1, o2, o3 ...},估计模型λ = (A, B, π)的参数,使得在该参数下该模型的观测序列P(O | λ)最大
预测问题:Viterbi算法----动态规划
解码问题:已知模型λ = (A, B, π)和观测序列O={o1, o2, o3 ...},求给定观测序列条件概率P(I | O,λ)最大的状态序列I
a)概率计算问题
对于概率计算问题,可以采用暴力计算法、前向算法和后向算法
暴力法:
问题:已知HMM的参数 λ,和观测序列O = {o1, o2, ...,oT},求P(O|λ)
思路:--------------------------------------------------------------------------
- 列举所有可能的长度为T的状态序列I = {i1, i2, ..., iT};每个i都有N个可能的取值。
- 求各个状态序列I与观测序列 的联合概率P(O,I|λ);
- 所有可能的状态序列求和∑_I P(O,I|λ)得到P(O|λ)。
步骤:
1,最终目标是求O和I同时出现的联合概率,即:
P(O,I|λ)= P(O|I, λ)P(I|λ)
那就需要求出P(O|I, λ) 和 P(I|λ)。
2,求P(I|λ) ,即状态序列I = {i1,i2, ..., iT} 的概率:
2.1,P(I|λ) = P(i1,i2, ..., iT |λ)
=P(i1 |λ)P(i2, i3, ..., iT |λ)
=P(i1 |λ)P(i2 | i1, λ)P(i3, i4, ..., iT |λ)
=......
=P(i1 |λ)P(i2 | i1, λ)P(i3 | i2, λ)...P(iT | iT-1, λ)
而上面的P(i1 |λ) 是初始为状态i1的概率,P(i2 | i1, λ) 是从状态i1转移到i2的概率,其他同理,于是分别使用初始概率分布π 和状态转移矩阵A,就得到结果:

PS:上面的ai1i2代表A的第i1行第i2列。
3,P(O|I, λ),即对固定的状态序列I,观测序列O的概率是:

4,代入第一步求出P(O,I|λ)。

5,对所有可能的状态序列I求和得到观测序列O的概率P(O|λ):

时间复杂度:
每个时刻有n个状态,一共有t个时刻,而根据上面的第5步可以知道每个时刻状态ai相乘的复杂度为nT,然后乘以各个对应的b,所以时间复杂度大概为:O(TnT)阶
概率消失:
可以通过取对数,防止P的值过小。
前向概率:
前向概率的定义:当第t个时刻的状态为i时,前面的时刻分别观测到q1,q2, ..., qt的概率。
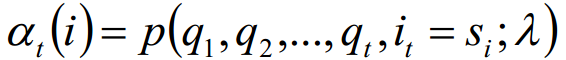
初值:
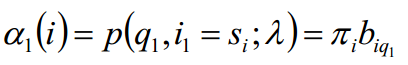
递推:
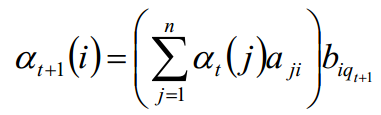
最终值:
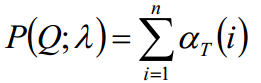
时间复杂度:
由公式可见,括号里面的时间复杂度为N^2,迭代过程中,又乘上T个时刻的b,因此,时间复杂度为O(TN^2)阶的。
对于暴力法和前向算法时间复杂度的理解:
对于两种算法,其实本质上都是通过状态 x 观测概率获得的概率值,只不过区别在于,前向算法将每一个时刻的状态概率先进行相加然后乘以观测概率,获得最终值。
可以理解为:a1*a2*a3... 如果ai有n种取值,其复杂度为 O(n^T)
对于另一种表达方式: α*a1 同理 α有n种取值,ai有n种取值,那么复杂度为 O(n^2)
时间复杂度计算:

后向概率和前向概率类似,此处不赘述。
b)学习问题
学习问题分两种:
- 观测序列和隐状态序列都给出,求HMM。这种学习是监督学习。
- 给出观测序列,但没给出隐状态序列,求HMM。这种学习是非监督学习,利用Baum-Welch(鲍姆-韦尔奇)算法。
对于监督学习,利用大数定律“频率的极限是概率”即可求解:
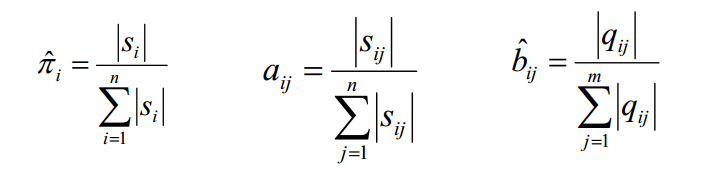
对于非监督学习,一般采用Baum-Welch算法。
对于观测数据Q、隐藏状态I、概率P(Q, I ;λ)即为暴力法的表达式,其对数似然函数为:ln(P(Q, I ;λ)),然后用EM算法求解即可。
求 π:利用约束条件:所有πi的和为1。
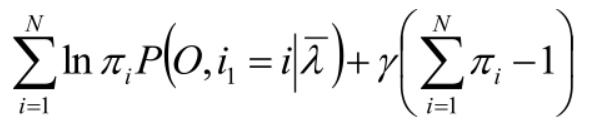
拉格朗日函数求解:


同理:
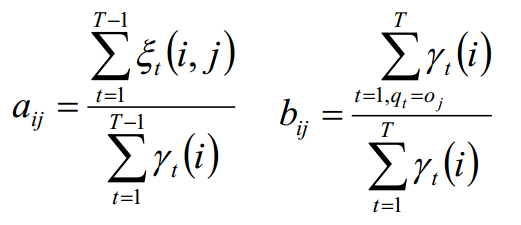
c)预测问题:
对于预测问题,本文主要讲Viterbi算法。Viterbi算法实际是用动态规划的思路求解HMM预测问题。求出概率最大的路径,每个路径对应一个状态序列。
盒子和球模型λ= (A, B,π),状态集合Q={1, 2, 3},观测集合V={白,黑},已知观测序列“白黑白白黑”,求最优的隐藏状态

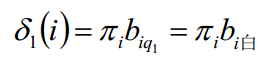
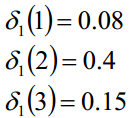
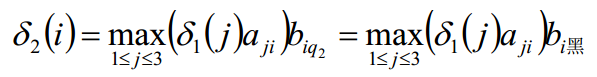

同理:
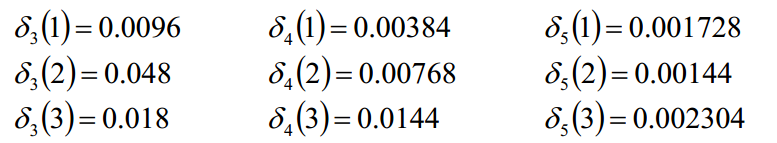
可以看到结果如图:
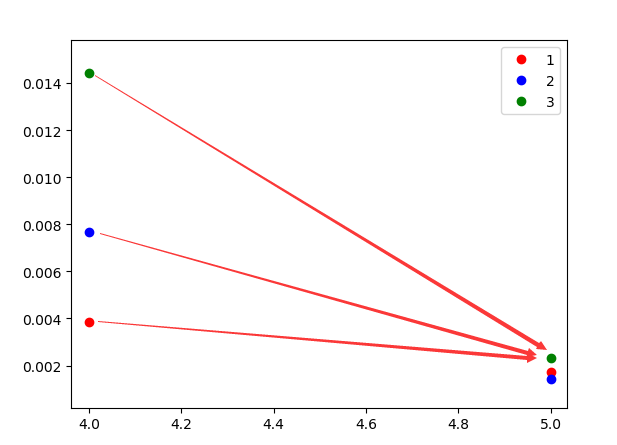
我们从后往前查询,第5时刻最大概率的状态为3,然后往前推导,究竟第5个状态是从哪一个状态的来的呢?
max{ 0.00384*0.1 0.00768*0.6 0.0144*0.3 } 可以看到,应该取状态2 -> 3才是最大的,故第4个时刻的状态为2。
最终求得最优状态为:2 3 2 2 3
五、viterbi用于词性标注
词性标注问题映射到隐马模型可以表述为:模型中状态(词性)的数目为词性符号的个数N;从每个状态可能输出的不同符号(单词)的数目为词汇的个数M。假设在统计意义上每个词性的概率分布只与上一个词的词性有关(即词性的二元语法),而每个单词的概率分布只与其词性相关。那么,我们就可以通过对已分词并做了词性标注的训练语料进行统计,统计出HMM的参数 λ,当然这就是上述学习问题。
然后可以根据已知的词语,通过viterbi算法,求出每个词语对应的词性,即完成词性标注。
隐马尔科夫模型(HMM)与词性标注问题的更多相关文章
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 猪猪的机器学习笔记(十七)隐马尔科夫模型HMM
隐马尔科夫模型HMM 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十七次课在线笔记.隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来 ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(一)HMM模型
隐马尔科夫模型HMM(一)HMM模型基础 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比 ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态 ...
- 用hmmlearn学习隐马尔科夫模型HMM
在之前的HMM系列中,我们对隐马尔科夫模型HMM的原理以及三个问题的求解方法做了总结.本文我们就从实践的角度用Python的hmmlearn库来学习HMM的使用.关于hmmlearn的更多资料在官方文 ...
- 机器学习之隐马尔科夫模型HMM(六)
摘要 隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔科夫过程.其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步 ...
- 隐马尔科夫模型HMM
崔晓源 翻译 我们通常都习惯寻找一个事物在一段时间里的变化规律.在很多领域我们都希望找到这个规律,比如计算机中的指令顺序,句子中的词顺序和语音中的词顺序等等.一个最适用的例子就是天气的预测. 首先,本 ...
- 隐马尔科夫模型HMM介绍
马尔科夫链是描述状态转换的随机过程,该过程具备“无记忆”的性质:即当前时刻$t$的状态$s_t$的概率分布只由前一时刻$t-1$的状态$s_{t-1}$决定,与时间序列中$t-1$时刻之前的状态无关. ...
随机推荐
- java学习路线-从入门到入土
以下是个人学习路线,资源等我找到了 share,如果没找到请自行百度: 1.javase 观看 毕向东的 javase ,主要是老毕口才略屌,听着不容易打瞌睡,冷不丁吓你一大跳 老毕的年代久远,我已经 ...
- Spring Cloud (十五)Stream 入门、主要概念与自定义消息发送与接收
前言 不写随笔的日子仿佛就是什么都没有产出一般--上节说到要学Spring Cloud Bus,这里发现按照官方文档的顺序反而会更好些,因为不必去后边的章节去为当前章节去打基础,所以我们先学习Spri ...
- HDU 1501 Zipper 字符串
题目大意:输入有一个T,表示有T组测试数据,然后输入三个字符串,问第三个字符串能否由第一个和第二个字符串拼接而来,拼接的规则是第一个和第二个字符串在新的字符串中的前后的相对的顺序不能改变,问第三个字符 ...
- spring如何管理mybatis(一) ----- 动态代理接口
问题来源 最近在集成spring和mybatis时遇到了很多问题,从网上查了也解决了,但是就是心里有点别扭,想看看到底怎么回事,所以跟了下源码,终于发现了其中的奥妙. 问题分析 首先我们来看看基本的配 ...
- 以python代码解释fork系统调用
import os print('Process (%s) start...' % os.getpid()) # Only works on Unix/Linux/Mac: pid = os.fork ...
- 【API】NetUserEnum-获取系统所有账户名称
1 说明 该NetUserEnum函数检索服务器上所有用户帐户的信息. 函数原型: NET_API_STATUS NetUserEnum( _In_ LPCWSTR servername, _In_ ...
- 使用InstallShield打包windriver驱动-转
转自:http://blog.csdn.net/weixin_29796711/article/details/72822052 用户在使用我们用windriver开发的硬件驱动时,需要先安装wind ...
- linux批量关闭进程
ps aux | grep gunicorn_api | awk '{print $2}' | xargs kill -9 gunicorn 换成你的关键字即可.
- cefSharp获取百度搜索结果页面的源码
using CefSharp; using CefSharp.WinForms; using System; using System.Collections.Generic; using Syste ...
- elasticsearch分别在windows和linux系统安装
WINDOWS系统安装1.安装JDKElastic Search要求使用较高版本JDK,本文使用D:\DevTools\jdk1.8.0_131,并配置环境变量 2.安装Elastic Search官 ...