MYSQL一次千万级连表查询优化
概述:
交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差,因此SQL优化任务交到了我手上。
这个SQL查询关联两个数据表,一个是攻击IP用户表主要是记录IP的信息,如第一次攻击时间,地址,IP等等,一个是IP攻击次数表主要是记录每天IP攻击次数。而需求是获取某天攻击IP信息和次数。(以下SQL语句测试均在测试服务器上上,正式服务器的性能好,查询时间快不少。)
准备:
查看表的行数:
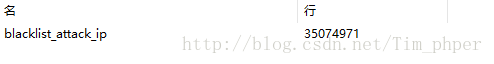

未优化前SQL语句为:
- SELECT
- attack_ip,
- country,
- province,
- city,
- line,
- info_update_time AS attack_time,
- sum( attack_count ) AS attack_times
- FROM
- `blacklist_attack_ip`
- INNER JOIN `blacklist_ip_count_date` ON `blacklist_attack_ip`.`attack_ip` = `blacklist_ip_count_date`.`ip`
- WHERE
- `attack_count` > 0
- AND `date` BETWEEN '2017-10-13 00:00:00'
- AND '2017-10-13 23:59:59'
- GROUP BY
- `ip`
- LIMIT 10 OFFSET 1000
先EXPLAIN分析一下:
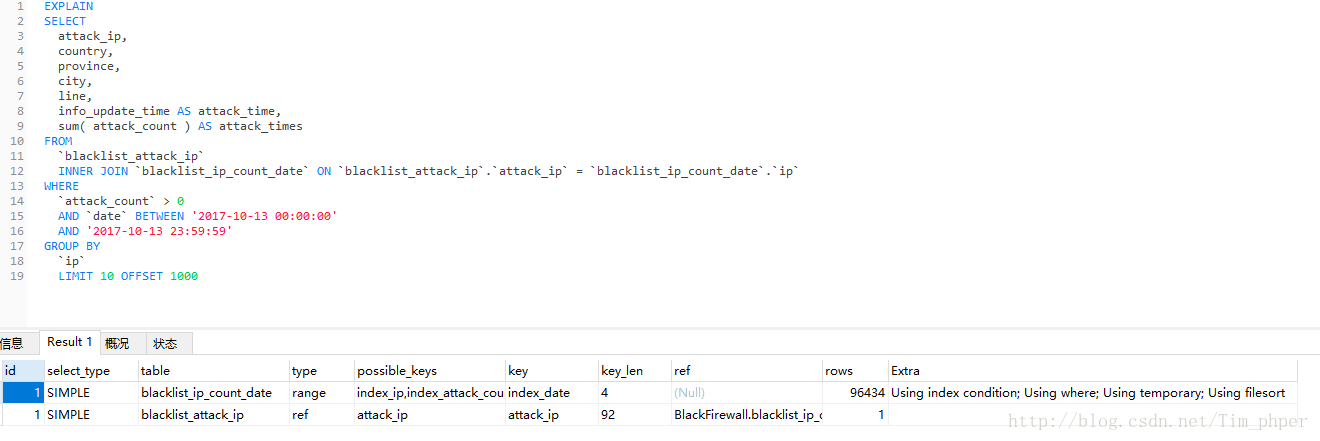
这里看到索引是有的,但是IP攻击次数表blacklist_ip_count_data也用上了临时表。那么这SQL不优化直接第一次执行需要多久(这里强调第一次是因为MYSQL带有缓存功能,执行过一次的同样SQL,第二次会快很多。)
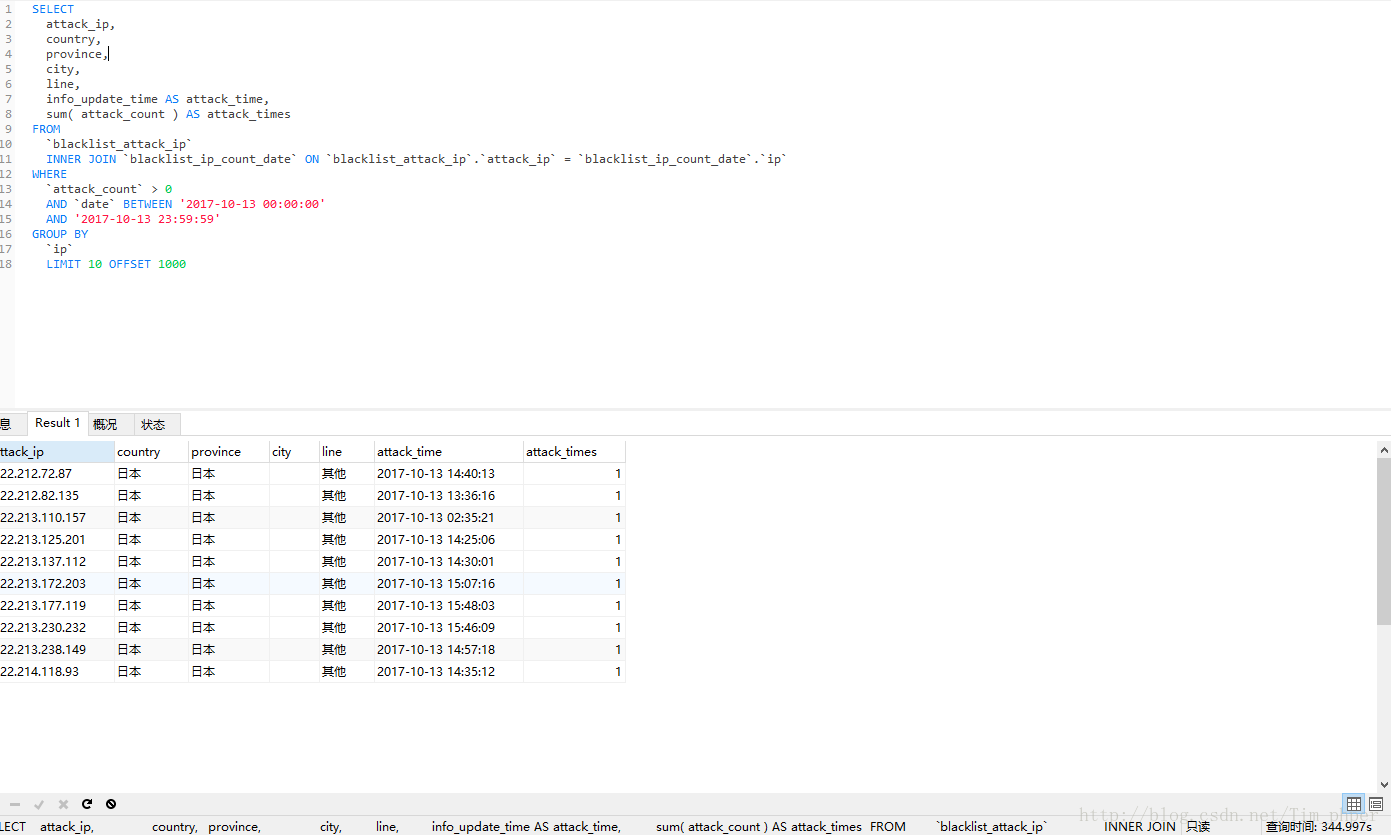
实际查询时间为300+秒,这完全不能接受呀,这还是没有其他搜索条件下的。
那么我们怎么优化呢,索引既然走了,我尝试一下避免临时表,这时我们先了解一下临时表跟group by的使联系:
查找了网上一些博客分析GROUP BY 与临时表的关系 :
- . 如果GROUP BY 的列没有索引,产生临时表.
- . 如果GROUP BY时,SELECT的列不止GROUP BY列一个,并且GROUP BY的列不是主键 ,产生临时表.
- . 如果GROUP BY的列有索引,ORDER BY的列没索引.产生临时表.
- . 如果GROUP BY的列和ORDER BY的列不一样,即使都有索引也会产生临时表.
- . 如果GROUP BY或ORDER BY的列不是来自JOIN语句第一个表.会产生临时表.
- . 如果DISTINCT 和 ORDER BY的列没有索引,产生临时表.
仔细按照上面分析一下,这SQL可能是因为第二条导致的,blacklist_ip_count_date这个表的确主键不是IP,SELECT是多列的,那么我们试试单独提出单表测试能不能避免临时表:
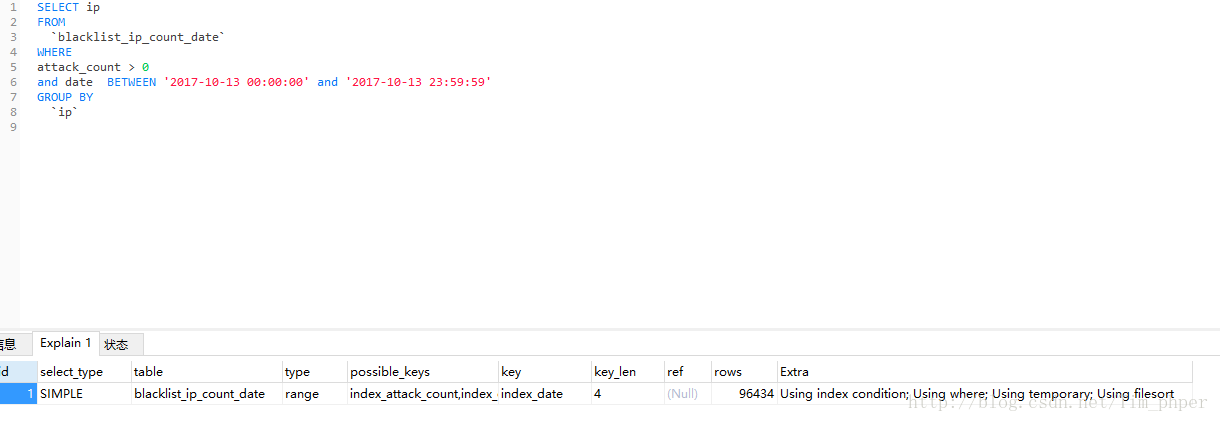
很遗憾,并不能避免,但是我们仔细看看这EXPLAIN 里面的KEY 分析,用的索引是date单字段的索引。这好像就是导致了第一条的问题了,相当于GROUP BY没有用索引。那么我们试试强制使用IP单字段的索引呢?
这里看来的确是索引的问题,导致了临时表啊,然而再看看ROWS的数量,原来的9W变成了1552W,这不是不是捡了芝麻掉了西瓜吗?
这里单列索引 避免了临时表可是联系的行数又增加了,那么我们再试试复合索引呢?
于是创建attack_count、date、ip的复合索引index_Acount_date_ip
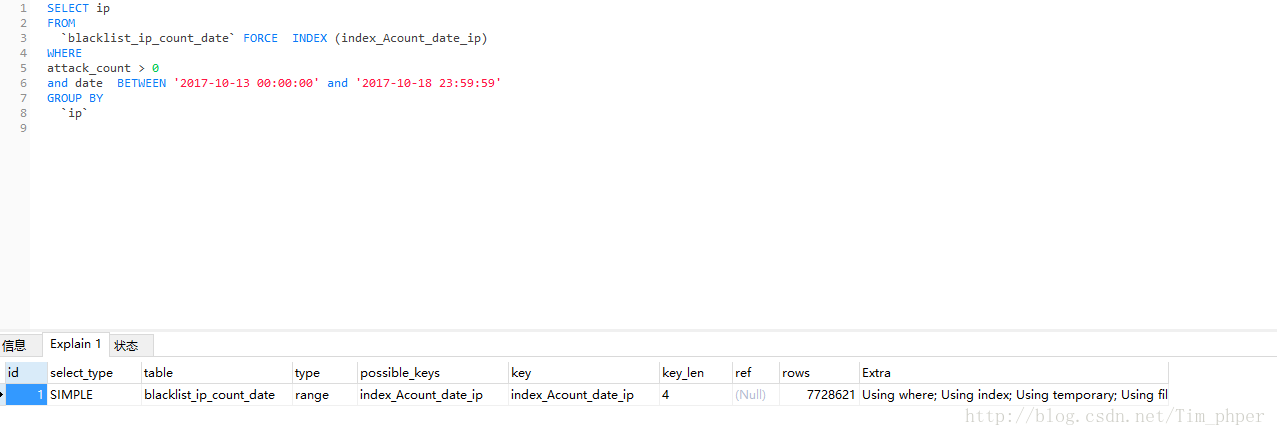
ROWS的行数770W而且还是有临时表,看来这复合索引也是不可取。
到此,避免临时表方法失败了,我们得从其他角度想想如何优化。
其实,9W的临时表并不算多,那么为什么导致会这么久的查询呢?我们想想这没优化的SQL的执行过程是怎么样的呢?
网上搜索得知内联表查询一般的执行过程是:
- 、执行FROM语句
- 、执行ON过滤
- 、添加外部行
- 、执行where条件过滤
- 、执行group by分组语句
- 、执行having
- 、select列表
- 、执行distinct去重复数据
- 、执行order by字句
- 、执行limit字句
这里得知,Mysql 是先执行内联表然后再进行条件查询的最后再分组,那么想想这SQL的条件查询和分组都只是一个表的,内联后数据就变得臃肿了,这时候再进行条件查询和分组是否太吃亏了,我们可以尝试一下提前进行分组和条件查询,实现方法就是子查询联合内联查询。
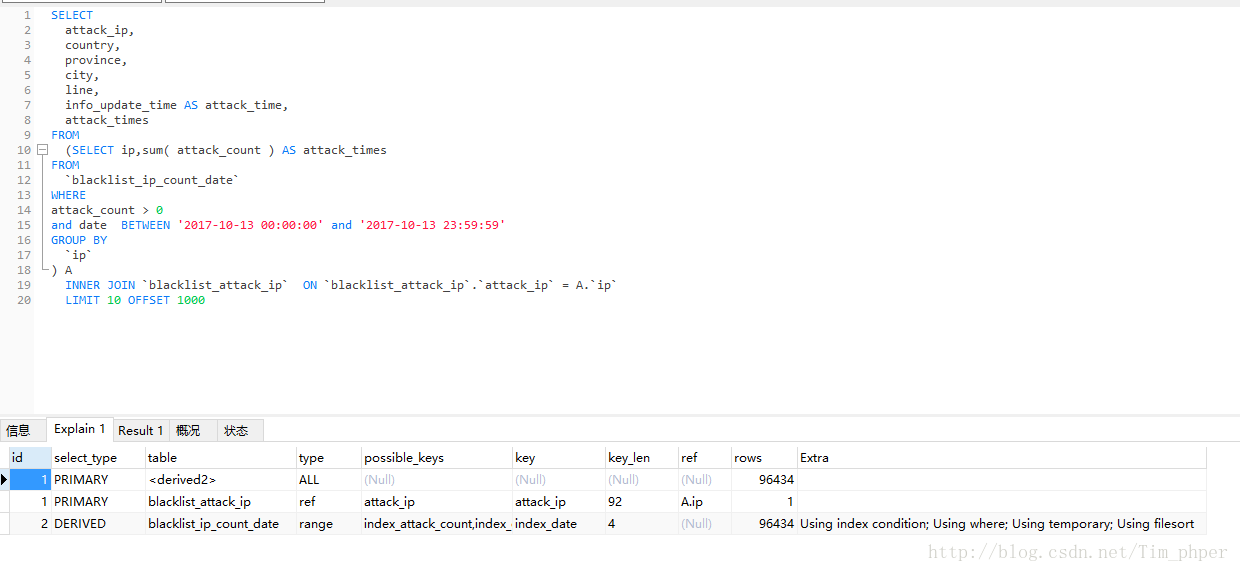
这里EXPLAIN看来,只是多了子查询,ROWS和临时表都没有变化。那么我们看看实际的效果呢?
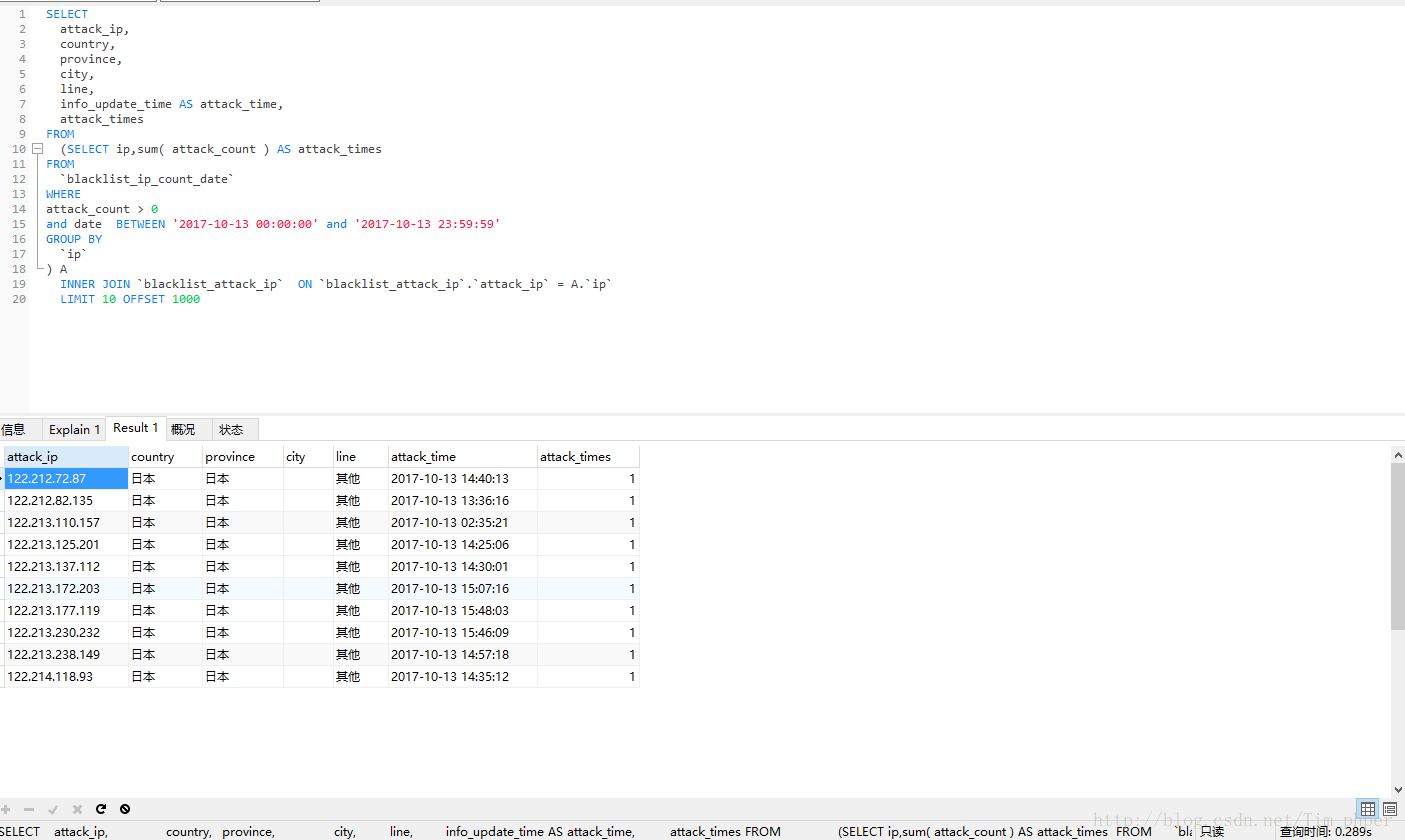
可见,取出来的数据完全一模一样,可是优化后效率从原来的330秒变成了0.28秒,这里足足提升了1000多倍的速度。这也基本满足了我们的优化需求。
总结:
整个过程中我们得知,其实EXPLAIN有时候并不能指出你的SQL的所有问题,有一些隐藏问题必须要你自己思考,正如我们这个例子,看起来临时表是最大效率低的源头,但是实际上9W的临时表对MYSQL来说不足以挂齿的。我们进行内联查询前,最好能限制连的表大小的条件都先用上了,同时尽量让条件查询和分组执行的表尽量小。感谢您们的阅读,如果有更好的方案,欢迎留言交流!!!
估计到这里,你猜这里就是全部的优化方案?不不不,整个优化过程怎么可能只是发现一个优化方案。还有其他方案
那么我们怎么优化呢,这里用的是内联表查询,大家都是知道子查询完全是可以代替内联表查询的,只不过SQL语句复杂了不少,那么我们分析一下这SQL,两个表分表提供了什么?
1、IP攻击次数表blacklist_ip_count_data主要提供的指定时间条件查询,攻击次数条件查询后的IP和每个IP符合条件下的具体攻击次数。
2、攻击IP用户表blacklist_attack_ip主要是具体IP的信息,如第一次攻击时间,地址,IP等等。
那么我们一步步来:
1、IP攻击次数表blacklist_ip_count_data获取符合时间条件和攻击次数的IP并且以IP分组:
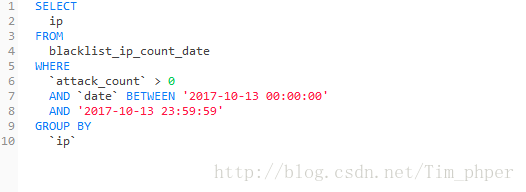
2、攻击IP用户表blacklist_attack_ip指定具体的IP获取信息:

然后结合在一起:
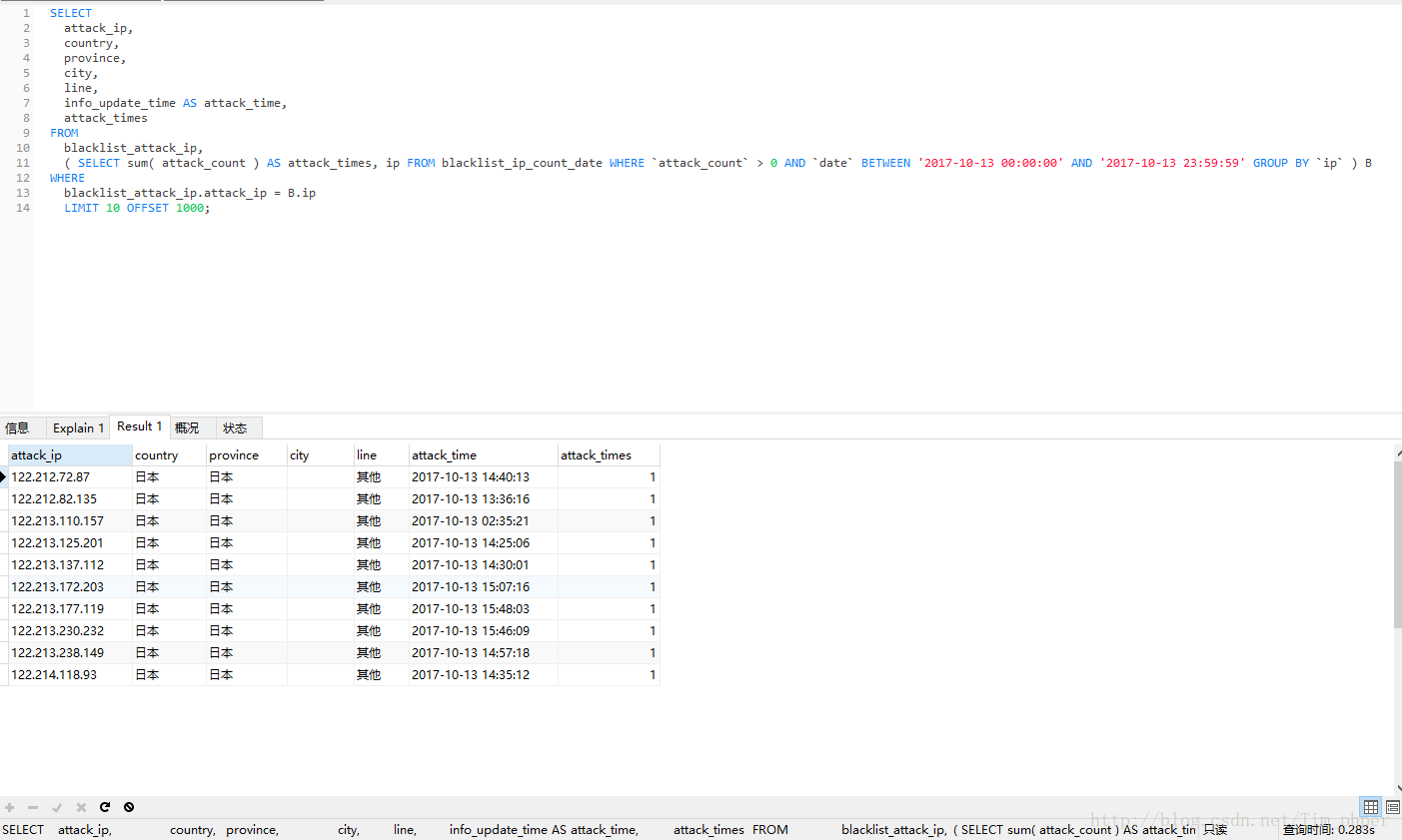
可见,取出来的数据完全一模一样,可是优化后效率从原来的330秒变成了0.28秒,这里足足提升了1000多倍的速度。这也基本满足了我们的优化需求。
我们EXPLAIN了解一下情况:

总结:
其实这个优化方案跟我上一篇文章MYSQL一次千万级连表查询优化(一)解决原理一样,都是解决了内联表后数据就变得臃肿了,这时候再进行条件查询和分组就太吃亏了,于是我们可以先对单表进行条件处理,再进行连表查询,只不过这个方案只是用了子查询而没有内联查询了,而两者效率对比之下,有内联的方案带其他查询条件的效率更高。感谢您们的阅读,如果有更好的方案,欢迎留言交流!!!
MYSQL一次千万级连表查询优化的更多相关文章
- MYSQL一次千万级连表查询优化(二) 作为一的讲解思路
这里摘自网上,仅供自己学习之用,再次鸣谢 概述: 交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别 ...
- MYSQL一次千万级连表查询优化(一)
摘自网上学习之用 https://blog.csdn.net/Tim_phper/article/details/78344444 概述: 交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的 ...
- ( 转 ) 优化 Group By -- MYSQL一次千万级连表查询优化
概述: 交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差,因此SQL优化任务交到了我手上. 这个 ...
- 在mysql数据库中制作千万级测试表
在mysql数据库中制作千万级测试表 前言: 最近准备深入的学一下mysql,包括各种引擎的特性.性能优化.分表分库等.为了方便测试性能.分表等工作,就需要先建立一张比较大的数据表.我这里准备先建一张 ...
- Mysql千万级大表优化
Mysql的单张表的最大数据存储量尚没有定论,一般情况下mysql单表记录超过千万以后性能会变得很差.因此,总结一些相关的Mysql千万级大表的优化策略. 1.优化sql以及索引 1.1优化sql 1 ...
- MySQL千万级大表优化解决方案
MySQL千万级大表优化解决方案 非原创,纯属记录一下. 背景 无意间看到了这篇文章,作者写的很棒,于是乎,本人自私一把,把干货保存下来.:-) 问题概述 使用阿里云rds for MySQL数据库( ...
- 如何优化MySQL千万级大表
很好的一篇博客,转载 如何优化MySQL千万级大表 原文链接::https://blog.csdn.net/yangjianrong1985/article/details/102675334 千万级 ...
- Oracle中创建千万级大表归纳
从一月至今,我总共归纳了三种创建千万级大表的方案,它们是: 下面是这三种方案的对比表格: # 名称 地址 主要机制 速度 1 在Oracle中十分钟内创建一张千万级别的表 https://www.cn ...
- Mysql学习总结(22)——Mysql数据库中制作千万级测试表
前言: 为了方便测试性能.分表等工作,就需要先建立一张比较大的数据表.我这里准备先建一张千万记录用户表. 步骤: 1 创建数据表(MYISAM方式存储插入速度比innodb方式快很多) 数据表描述 数 ...
随机推荐
- 关于WordCount的作业
一.开发者:201631062418 二.代码地址:https://gitee.com/YsuLIyan/WordCount 三.作业地址:https://edu.cnblogs.com/campus ...
- 使用json-server模拟REST API
https://segmentfault.com/a/1190000005793257 在开发过程中,前后端不论是否分离,接口多半是滞后于页面开发的.所以建立一个REST风格的API接口,给前端页面提 ...
- 检查iOS项目中是否使用了IDFA
(1)什么是IDFA 关于IDFA,在提交应用到App Store时,iTunes Connect有如下说明: 这里说到检查项目中是否包含IDFA,那如何来对iOS项目(包括第三方SDK)检查是否 ...
- javascript数据结构与算法---检索算法(二分查找法、计算重复次数)
javascript数据结构与算法---检索算法(二分查找法.计算重复次数) /*只需要查找元素是否存在数组,可以先将数组排序,再使用二分查找法*/ function qSort(arr){ if ( ...
- JVM中OutOFMemory和StackOverflowError异常代码
1.Out of Memory 异常 右键Run As --->Run Configuration 设置JVM参数 -Xms20m -Xmx20m 上代码: /** * VM Args:-Xms ...
- (转)Python3之requests模块
原文:https://www.cnblogs.com/wang-yc/p/5623711.html Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了.它是为另 ...
- Notepad++中代码格式化插件NppAStyle
本文以图片和说明,手把手教大家怎么让Notepad++中的代码风格看起来更美观. 工具/原料 Windows7 Notepad++ NppAStyle(Notepad++的一个插件) 方法/步骤 直 ...
- JAVA与DOM解析器基础 学习笔记
要求 必备知识 JAVA基础知识.XML基础知识. 开发环境 MyEclipse10 资料下载 源码下载 文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的 ...
- linux-centos使用 wget命令获取jdk
1, 首先去官网看下地址是否变化了 2, 然后输入以下命令即可 wget --no-check-certificate --no-cookies --header "Cookie: orac ...
- 编译centos6.5:glibc 升级2.14问题
第一种:不需要 ln 创建软连接,缺点嘛,就是直接安装到系统文件夹/lib64下,想换回来就比较麻烦.(我选择的第二种,因为公司需要fpm打包,写到脚本里面,第一种之间安装在/usr目录下,打包的包安 ...