HBase原理和安装
HBase的基本概念和安装:
Hbase简介
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
2006年Google发表BigTable白皮书
2006年开始开发HBase
2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目
2010年HBase成为Apache顶级项目
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
Hbase特点
海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。Hbase的单表可以有百亿行,百万列,对于关系型数据库单表记录在亿级别时,查询和写入的性能都会出现级数下降,对于传统数据库来说这种庞大的数据量时一种灾难,Hbase限定某个列的情况下对于单表存储百亿或者更多数据没有性能问题,它采用了LSM树为内部数据的存储结构,这种数据结构会周期性地合并成大文件以减少对磁盘地访问,但是牺牲了部分读的性能。
列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。每个列都是单独存储的,且持支基于列的独立检索。列存储下表按照列分开保存,数据查询操作时,列存储只需要读取相关列,可以降低系统的I/O。
极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
RegionServer的作用是管理region、承接业务的访问,通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
高可靠
Hbase运行在HDFS上,HDFS的多副本存储可以让它在出现故障的时候自动恢复,同时Hbase内部也提供WAL和Replication机制WAL(Write-Ahead-Log)预写日志在Hbase服务器处理数据插入和删除的过程中用来记录操作内容的日志,保证了数据写入时不会因为集群异常而导致写入数据的丢失,而Replication机制是基于数据操作来数据同步的。当集群中单个节点出现故障时,ZooKeeper通知集群的主节点,将故障节点的Hlog中的日志信息发送到从节点进行数据恢复。
稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,Hbase的数据都是以字符串进行存储的,在列数据为空的情况下,是不会占用存储空间的。最大程度上节省了存储开销,所以Hbase通常可以设计成系数的矩阵,这种方式比较接近实际的应用场景。
HBase架构
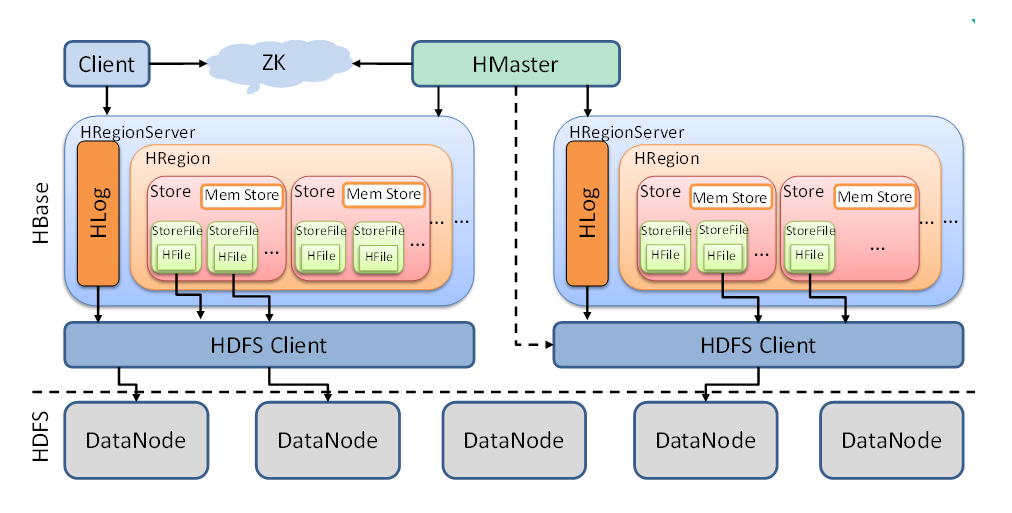
Client
Client包含了访问Hbase的接口,是整个HBase系统的入口,使用者可以通过客户端操作Hbase客户端使用HBase的RPC机制和HMaster和RegionServer进行通信,一般情况下,客户端与HMaster进行管理类的操作通信,在获取RegionServer的信息后,直接与RegionServer进行数据的读写类操作,另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息。客户端可以使用Java语言来实现、也可以是Thtift、Rest等客户端模式,甚至是MapReduce也可以算作是一种客户端。
ZooKeeper
ZooKeeper是一个高性能、集中化、分布式应用程序协调服务,主要用了解决分布式应用中常遇到的数据管理问题,比如数据发布/订阅、命名服务、分布式协调通知、集群管理、Master选举、分布式锁、分布式队列等。其中Master选举是Zookeeper中最经典的应用场景,在Hadoop中,Zookeeper主要实现HA高可用,包括NameNode和YARN的ResourceManager的HA。
Master选举
同HDFS的HA机制一样,Hbase集群中有多个HMaster并存,通过竞争选举保证同一时刻只有一个HMaster处于活跃状态,一旦这个HMaster无法使用,则从备用节点选举一个顶上,保证集群的高扩展性。
系统容错
在HBase启动时,每个RegioServer在加入集群时都需要到ZooKeeper中进行注册,创建一个状态节点,ZooKeeper会实时监控每个RegionServer的状态同时,HMaster会对这些注册的RegionServer进行监听,当某个RegionServer挂掉之后,ZooKeeper会因为一段时间内接收不到它的心跳信息而删除该RegionServer对于的状态节点,把并且给HMaster发送节点删除的通知,这时,HMaster获知集群中某节点断开,会立即调度其他节点开启容错机制。
Region元数据管理
在Hbase集群中,region元数据被存储在.META.表中 每次客户端发起新的请求时,需要查询.META.表来获取region的位置。.META.表是存在ZooKeeper中的。当RegionServer发生变化时,比如region的手工移动、进行负载均衡移动或者region所在的RegionServer出现故障等,就通过ZooKeeper来感知这一变化,保证客户端能够获得正确的region元数据信息。
Region状态管理
HBase集群中region会经常发生变更,变更的原因可能是系统故障,或者是配置修改,还有region的分裂和合并。只要region发生变化,就需要集群的所有节点知晓,否则就会出现某些事务性的异常。对于Hbase集群,region发生变化,就需要集群的所有节点知晓,否则会出现某些事务性的异常,对于HBase集群,region的数量会达到10万级别,甚至更多,如果这样规模的region状态管理直接由HMaster来实现,可想而知HMaster负担会很重,因此只有通过ZooKeeper系统来完成。
元数据信息
ZooKeeper存储HBase中有哪些表,每个表包含那些列族信息,存储元数据的统一入口地址。
HMaster
HMaster是HBase集群中的主服务器,负责监控集群中的所有RegionServer,并且是所有元数据更改的接口,分布式环境中HMaster服务通常运行在HDFS的NameNode上,HMaster通过ZooKeeper来避免单点故障,在集群当中可以启动多个HMaster,但ZooKeeper的选举机制能够保证同时只有一个HMaster处于Active状态,其他的HMaster处于热备状态。HMaster主要负责表和region的管理作业。
- 管理用户对于表的增删改查
| 相关的 | 功能 |
|---|---|
| HBase表 | 创建表、删除表、启用/失效表、修改表 |
| HBase列族 | 添加列、修改列、删除列 |
| HBase表region | 移动region、region的分配和合并 |
管理RegionServer的负载均衡,调整region的分布。
Region的分配和移除
处理RegionServer的故障转移
当某台RegionServer挂掉时,总有一部分新写入的数据还没有持久化到磁盘上,因此在迁移RegionServer服务是,需要从修改记录中恢复这部分还在内存中的数据,HMaster需要遍历该RegionServer的修改记录,并按region切分成小块移动到新的地址下。当HMaster节点发生故障时,由于客户端时进行与RegionServer交互的,且.META.表也时存在ZooKeeper当中,整个集群的工作会继续正常运行,所以HMaster发生故障时,集群仍然可以稳定运行。但是HMaster还会执行一些重要的工作,比如region的切片,RegionServer的故障冠以等,如果HMaster发生故障而没有及时处理,这些功能都会受到影响,所以HMaster要尽快恢复工作。ZooKeeper组件就提供了这种多HMaster的机制提高HBase的可用性和鲁棒性。
RegionServer
RegionServer主要负责用户的请求,向HDFS中读写数据。一般在分布式集群中,RegionServer运行在DataNode服务器上,实现数据的本地性,每个RegionServer包含多个region,它负责的功能有:
- 处理给它的region
- 处理客户端读写请求
- 刷新缓存到HDFS中
- 处理region分配
- 执行压缩
RegionServer时HBase中最核心的部分,其内部管理了一系列的region对象,每个region由多个HStore组成,每个HStore对应列表中一个列族的存储。这可以看到HBase时按照列进行存储的,将列族作为一个集中的存储单元,并且HBase将具备同I/O特性的列放到一个列族中,这样可以保证写的高效性。RegionServer最终将region数据存在HDFS上,采用HDFS作为底层存储。HBase自身并不具备数据和维护数据副本的功能,而依赖HDFS可以为HBase提供可靠和稳定的存储。当然HBase也可以不采用HDFS,比如它可以使用本地文件系统或云计算环境中的Amzon
S3。
其他组件
WAL
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead
logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
Store
HFile存储在Store中,一个Store对应HBase表中的一个列族。
MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile是以Hfile的形式存储在HDFS的。
安装
前置条件:
Zookeeper正常部署 Hadoop正常部署
解压文件
- tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/module
配置文件
hbase-env.sh
- export JAVA_HOME=/opt/module/jdk1.8.0_144
- export HBASE_MANAGES_ZK=false
hbase-site.xml
- <configuration>
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://datanode1:9000/hbase</value>
- </property>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
- <!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
- <property>
- <name>hbase.master.port</name>
- <value>16000</value>
- </property>
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>datanode1:2181,datanode2:2181,datanode3:2181</value>
- </property>
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/opt/module/zookeeper-3.4.10/data/zkData</value>
- </property>
- </configuration>
regionservers
- datanode1
- datanode2
- datanode3
软连接
- ln -s /opt/module/hadoop/etc/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml
- ln -s /opt/module/hadoop/etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml
同步
- xsync hbase/
启动
- start-hbase.sh
查看 web界面
使用场景
- 数据模式时动态的或者可变的,且支持半结构化和非结构化的数据。
- 数据库中很多列都包含了很多空字段,在HBase中空字段不会像关系型数据库占用空间。
- 需要很高的吞吐量,瞬间写入量大。
- 数据很多版本需要维护,HBase利用时间戳来区分不同版本的数据。
- 具有高可拓展性,能动态拓展整个系统。
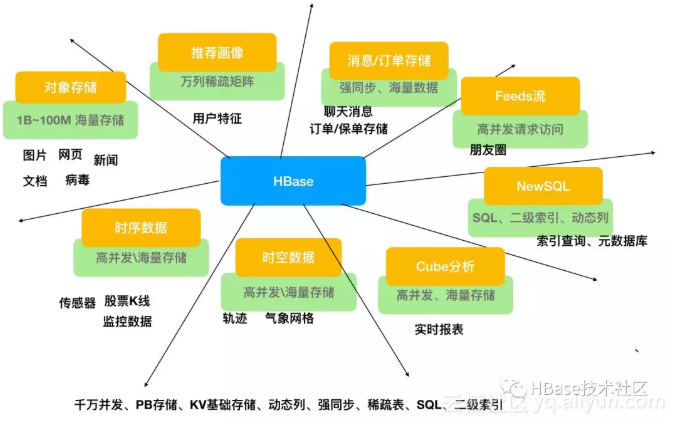
业务场景
对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求
推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上
时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
Feeds流:典型的应用就是xx朋友圈类似的应用
NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
HBase原理和安装的更多相关文章
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- hbase概述和安装
前言 前几天刚学了Hadoop的安装,几乎把Hadoop的雷都踩了一个遍,虽然Hadoop的相关的配置文件以及原理还没有完全完成,但是现在先总结分享一下笔者因为需要所整理的一些关于Hbase的东西. ...
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Hbase原理
Hbase原理 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop ...
- DNS服务器:主要介绍DNS的服务原理以及安装及其主从配置
DNS服务器:主要介绍DNS的服务原理以及安装及其主从配置 一.DNS简介 1.DNS DNS是域名系统(Domain Name System)的简称,它是一个将域名和IP相互映射的分布式数据库 ...
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- hbase伪分布式安装(单节点安装)
hbase伪分布式安装(单节点安装) http://hbase.apache.org/book.html#quickstart 1. 前提配置好java,环境java变量 上传jdk ...
- hbase完全分布式安装
hbase完全分布式安装 http://hbase.apache.org/book.html#standalone_dist master ...
随机推荐
- mysql创建部分索引
mysql中,字符串如何建立索引的(本文中截取一部分) 只对字符串的前几个字符进行索引.通过字符串的前几个字符我们已经能大概排序字符串了,剩下不能排序的可以通过遍历进行查找啊,这样只在B+树中存储字符 ...
- zabbix--3.0--3
使用JMX监控jvm vim /usr/local/tomcat/bin/catalina.sh 添加如下内容 CATALINA_OPTS="$CATALINA_OPTS -Dcom ...
- 【转】Vue生命周期
Vue所有的生命周期钩子自动绑定在this上下文到实例中,因此你可以访问数据,对属性和方法进行运算.这意味着你不能使用箭头函数来定义一个生命周期方法.这是因为箭头函数绑定了父上下文,因此this与你期 ...
- tp5服务器验证案例
1.验证器代码 <?php namespace app\user\validate; use think\Validate; use Potting\IDCard; /** * 山区治理报名验证 ...
- CSS 仿 iOS 系统通知数字样式
/** 仿 iOS 系统通知数字样式 **/ .num_span{ background-color: #f00; background-image: -webkit-linear-gradient( ...
- java实现文件的上传和下载
1. servlet 如何实现文件的上传和下载? 1.1上传文件 参考自:http://blog.csdn.net/hzc543806053/article/details/7524491 通过前台选 ...
- Device Identifier and Device DNA初识
Device Identifier and Device DNA初识 信息来源 怎么样去用这个DNA:
- golang 字符串统计
golang内建只认utf8 如果传递的字符串里含有汉字什么的,最好使用 utf8.RuneCountInString() 统计 字符串统计几种方法: - 使用 bytes.Count() 统计- 使 ...
- Windows右键菜单中新建项目添加与删除
一种是如 txt 类型: HKEY_CLASSES_ROOT\.txt\ShellNew 项下空字符串值:NullFile 另一种如MsOffice类型: HKEY_CLASSES_ROOT\.xl ...
- 在MacOSX系统上的一些工具和问题汇总
Android 模拟器 1. 安装模拟器 点击链接:https://cloud.genymotion.com/page/launchpad/download 需要先注册登录一下. 2.安装Virtua ...