WordCount改进 小组项目
GitHub地址:https://github.com/DM-Star/WordCount-opt
作业需求:http://www.cnblogs.com/ningjing-zhiyuan/p/8654132.html
1、WordCount项目PSP表格:
PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
5 | 5 |
|
· Estimate |
· 估计这个任务需要多少时间 |
5 | 5 |
|
Development |
开发 |
310 | 340 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
30 | 30 |
|
· Design Spec |
· 生成设计文档 |
20 | 20 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
10 | 10 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 | 60 |
|
· Design |
· 具体设计 |
60 | 60 |
|
· Coding |
· 具体编码 |
90 | 60 |
|
· Code Review |
· 代码复审 |
10 | 10 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 | 90 |
|
Reporting |
报告 |
52 | 52 |
|
· Test Report |
· 测试报告 |
30 | 30 |
|
· Size Measurement |
· 计算工作量 |
2 | 2 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
20 | 20 |
|
合计 |
367 | 397 |
2、项目接口实现:
在这个部分,我一开始接的任务是状态转移,创建哈希函数,以及添加单词功能,但根据模块化的需要,后来添加单词的这部分还是由Star亲自出马解决。在这个项目里,要提高性能的话,就肯定不能不考虑数据结构就开始做,比如说,要看一个单词是否已经存在,不可能去从头开始找,找到了就词频加1,没找到就在后面再添一个新单词,设置词频是1。因为这样的开销是巨大的,在一个有几千几万个单词的文件中,无法想象要过多久才能统计出他的次数,显然和性能要求不符。
我一开始的反应是可以像字典一样弄一个首字母索引序列,但在和Star同学的交流中,我发现这样其实是不合理的,比方说a开头的单词有很多,但是例如v,x这些字母开头的单词实际上不是那么多,虽然实际上要根据当时的文件来看,但这种做法确实是不合理的。于是就想到了将单词所有字母的ASCLL码相加,并且模除一个数字,得到ASCLL码的下标,就相当于找到字典中的部首那样,通过这个下标去找到所有具有这个特征的单词,再处理词频,这样的话效率会高很多,后来我们为了程序处理方便选择模除128,这样的话这个算法只需要和127做 按位与 运算即可得到下标。
int WordList::Hash(char* word){
int HashVal = ;
while (*word != '\0')
HashVal += *word++;
return HashVal & ;
}
另外是一个状态转移的函数,由于这个项目需求的描述很清楚,所以很容易就可以得出这样的一个流程图:

参考Star的流程图:http://www.cnblogs.com/DM-Star/p/8728684.html
一共有三个状态在单词中,在边界值,在单词外部,因此在WordState这个类型中进行宏定义:
#define INNERWORD 1 //状态一:单词内部
#define CRITICAL 2 //状态二:临界(收到一个连词符)
#define OUTERWORD 3 //状态三:单词外部
从外部到内部,再从内部到外部,就完成一个单词的提取,所以我们需要几个表示状态转移的量,根据虚线方向会出现11,12,13,21,23,31,33这些状况,因此继续增加宏定义,为了能简化有限状态机的运算
采用了16进制的数字:
#define PROCESS_11 0x11 //过程:状态一 到 状态一
#define PROCESS_12 0x12 //过程:状态一 到 状态二
#define PROCESS_13 0x13 //过程:状态一 到 状态三
#define PROCESS_21 0x21 //过程:状态二 到 状态一
#define PROCESS_23 0x23 //过程:状态二 到 状态三
#define PROCESS_31 0x31 //过程:状态三 到 状态一
#define PROCESS_33 0x33 //过程:状态三 到 状态三
用一个类WordState来存储关于状态的信息:
class WordState {
private:
public:
WordState();
processType stateTransfer(char c);
stateType state;
}
接下来是函数的实现:利用位运算,先将现存的state左移4位,并且与现在的状态做按位与,则可以得到对应的过程process,他看起来像是这样:
processType WordState::stateTransfer(char c) {
//传进一个字符,根据这个字符和当前状态计算下一个状态,并返回一个process,指明状态是如何迁移的。
processType process = state << ;
if( (c >= 'a') && (c <= 'z'))
state = INNERWORD;
else if (c == '-')
{
if (state == INNERWORD)
state = CRITICAL;
else
state = OUTERWORD;
}
else
state = OUTERWORD;
process = process | state;
return process;
}
3、单元测试
现在对我的hash()和stateTransfer()进行单元测试,hash( )这个函数虽然只是一种规则,为了做出一个映射,其实他的值多精确对程序来说并没有什么影响,但是为了达到我们要的效果,我们还是要对他进行必要的单元测试:
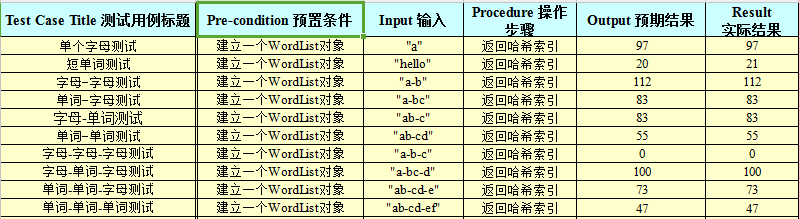
这个函数由于只有一条路,所以并不会出现什么错误,但是为了保证正确,我就从单个字母开始测试,后来慢慢变成单词,加上连字符,再到多个连字符,并且用Python编写一个检验的程序来确保程序运行的正确:
s = "hello"
l = list(s)
print l
a = 0
for i in l:
a += ord(i)
print a%128
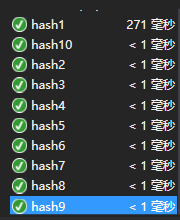
测试全部通过
另外一个状态迁移的函数的重要性相比之下高了很多,并且有很多种不同的情况,传出的参数会有当前的状态,以及迁移到这个状态的过程,对这两个部分分别进行测试:
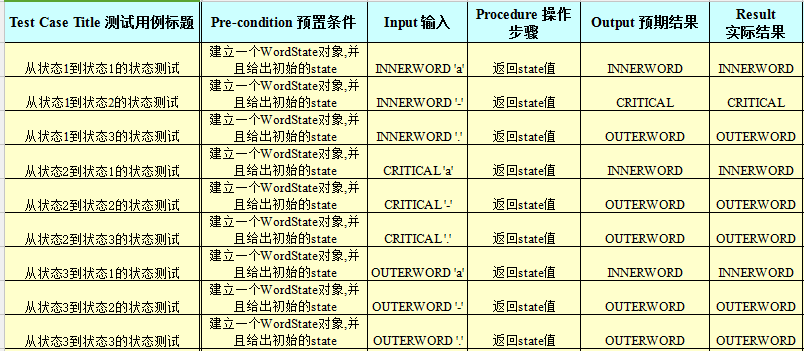
这里给出初始状态,然后给出下一个字符,就可以根据返回这个状态的值,值得一提的是,我虽然在这个测试里面写了状态二到状态二,状态三到状态二,但实际上我要验证的是他的状态会变成OUTERWORD,通过这个方式来证明连续的--会跳出word,在其他字符中给出-也不会让状态进入CRITICAL,状态与预想中的完全一致,在实际使用时候,会将state存储在类中,作为下一个调用的初始值,所以对state不需要重新赋值让他们能一直运行到读文件结束。
另外要测试的是process,这个函数关系到什么时候一个单词结束,结束之后哪一部分算单词。
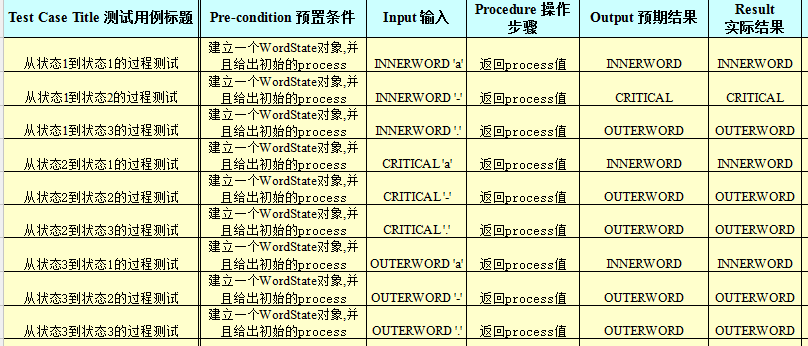
原理基本和state相同
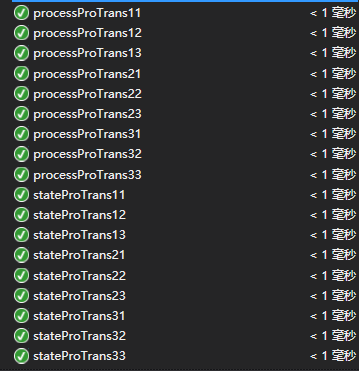
这些测试用例也完美的通过了,这也就意味着对单词逻辑的判断完全结束,并且只要是符合要求的文档放上来,那得出的结论一定是正确的。
4、总结
相比之前一次作业,我觉得这次作业让我对单元测试有了一些了解,这是一种从无到有的改变,以前我总是在想,一个工程要全部编完,然后再开始排查哪里的代码有问题,会很不方便,但是现在,有了单元测试,我可以保证编码和测试同步进行,当一个模块完全通过检验了之后,再进行下一个模块的编写,让之后的编码再也没有后顾之忧,单元测试的方法确实是非常实用。另外的静态测试涉及到编写代码的风格,我觉得这对以后的编程确实有着非常重要作用,我也确实应该培养一下良好的编程习惯了,我会尽量找一种适合我的代码风格,并且坚持使用下去。
WordCount改进 小组项目的更多相关文章
- 对小组项目alpha发布的评价
第一组:新蜂小组 项目:俄罗斯方块 评论:看见同学玩的时候,感到加速下落时不是很灵敏,没有及成绩的功能,用户的界面仍在修正. 第二组:天天向上 项目:连连看 评论:这个游戏增加了很多好玩的功能,比如更 ...
- 小组项目alpha发布的评价
新蜂团队一直都特别努力,这节课我也看到了他们努力的结果--项目可以顺利运行,在两个同学试玩期间没有出现BUG,不知道玩游戏的同学的心情,反正我们在台下看得很开心的. 飞天小女警组的礼物挑选系统,是一个 ...
- 1st 四人小组项目
小组名称:好好学习 项目组长:林莉 组员:王东涵.宫丽君.胡丽娜 项目选题:基于jsp的车库管理系统 项目期限:十周内<暂定> 需求分析:有待进一步思考
- 【week3】四人小组项目—东师论坛
项目选题:东北师范大学论坛 小组名称:nice! 项目组长:李权 组员:于淼 刘芳芳 杨柳. 本周任务: 1.发布申请 功能列表: 1.注册,登录 2.校内信息公告推送 3.十大热点 (根据搜索量.评 ...
- 【week2】四人小组项目(WBS、NABCD)
项目选题:东北师范大学论坛 小组名称:nice! 项目组长:李权 组员:于淼 刘芳芳 杨柳 本周任务:要求给出需求概述.功能列表.痛点或亮点.NABCD及WBS模型在此项目中的应用. 作为东北师范大学 ...
- week1 四人小组项目
小组名称:nice! 项目组长:李权 组员:于淼 刘芳芳 杨柳 项目选题:东北师范大学论坛 作为东北师范大学同学间的信息交流平台,要满足的需求如下: 1.校内信息及公告 2.毕业生招聘信息 3.课程查 ...
- 小组项目beta发布的评价
这次最看好飞天小女警组,相比上次他们的界面漂亮了很多,功能也相对完善,他们的礼物挑选系统非常有创意.如果去网上爬更多的数据,这个项目会更完美. 新蜂团队的俄罗斯方块游戏新增加了显示下一个方块以及游戏积 ...
- 连连看的设计与实现——四人小组项目(GUI)
项目GUI界面经过简单设计,整理如下:(图片截取致宠物连连看3.1) 点开游戏后界面显示: 点击菜单游戏—>初级 后显示 -------------------------- > 当游戏时 ...
- 连连看的设计与实现——四人小组项目(NABCD)
小组名称:天天向上 成员:王森.张政,张金生,栾骄阳 题目:连连看游戏 NABCD N(需求) 游戏最大的乐趣在于玩法,我们要想在众多的连连看游戏当中脱颖而出,就需要增加更多富有乐趣.吸引用户的玩法. ...
随机推荐
- 用PLSQL Developer 查看Oracle的存储过程
1 2.输入 3.具体存储过程
- centos 7.3+nginx+jira(.bin)+mysql
JIRA 安装参考资料 http://www.cnblogs.com/ilanni/p/6200875.html 注意服务启动与关闭 service jira stop service jira st ...
- 今天清理C盘空间,发现Unity的一个问题
C:\Users\Acer\AppData\LocalLow\Unity\Caches\GiCache AppData目录下,Unity占用了大量C盘空间,大概有5,6个G
- 截图原理(一)——Android自动化测试学习历程
把两节的内容汇总起来,第一节讲的是如何在apk中直接进行截屏,用到了Robotium的Solo类的takeScreenShot方法,有一个小的demo,以及从方法一直往里钻,知道它具体是怎么进行截屏的 ...
- DES对称加密
DES是对称性加密里面常见一种,全称为Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法.密钥长度是64位(bit),超过位数密钥被忽略.所谓对称性加密,加密 ...
- c++实现中的一些注意 事项
1,尽可能延后对象中的变量定义式的出现,这样可以增加程序的清晰度,尽量少的调用构造,如果有定义变量最好在末尾定义并给予初值,这样就避免了默认构造函数的调用. 2 尽量少做转型操作. const_cas ...
- lendinghome oa 准备
hardcode版本 估计只能过一个吧 import java.util.*; public class NextServer { Map<Integer, Integer> server ...
- TableView下拉刷新崩溃解决办法
return cell;上边加判断 if(self.dataArray.count<1){ return cell; }
- springmvc+logback项目的日志搭建
一.重写HTMLLayout 两个自定义类:LzhHTMLLayoutBase和LzhHTMLLayout LzhHTMLLayoutBase代码如下: package top.liaozhengha ...
- 获取URL某个参数
/* 获取URL某个参数(可以是中文) * 返回:字符串 */ function getUrlParam(key) { // 获取参数 var url = window.location.search ...