Pandas Learning
Panda Introduction
- Pandas 是基于 NumPy 的一个很方便的库,不论是对数据的读取、处理都非常方便。常用于对csv,json,xml等格式数据的读取和处理。
- Pandas定义了两种自己独有的数据结构,Series 和 DataFrame。
Series
Series可以理解为竖着的列表。
(Ps:Series中元素可以是任意类型)index | data
---|---
0 | XiaoWang
1 | XiaoLin
Series比较常用的定义方式有如下几种
传入列表定义Series
s = Series([66,'score','scout','fbricate'])
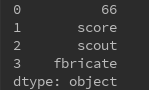
传入字典定义Series
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'})
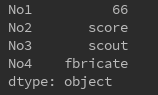
比较常用的属性和方法
S.values 可以显示Series对象的数据值
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'})
print(s.values)

S.index 可以显示Series对象的索引
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'})
print(s.index)

判断是否为空
- pd.isnull(series对象)
- pd.notnull(series对象)
- Series 对象.isnull()
- Series 对象.index = []
可以重新定义索引的名字s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'})
s.index=['no1','no2','no3','no4']
print(s)

Series自定义索引机制(索引不仅可以是数字)
实际实现:数据值和自定义索引分别对应于两个列表,新索引自动指向于相应旧索引指向的数据值实现“自动对齐”。
利用已经生成的Series创建新的Series,并且尝试传入原本不存在的索引
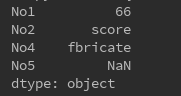
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'})
s1 = Series(s,index= ['No1','No2','No3','No4','No5'])
print(s1)

Ps:数据不存在用NaN表示。
当旧的索引不在新定义的索引中,则该数据项自动剔除,不进入新的Series中,索引对应可以看成是新的对旧的数据的一种筛选或者添加。
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'})
s1 = Series(s,index= ['No1','No2','No4','No5'])
print(s1)
Series相关运算
筛选符合条件的数据,返回一个新的Series
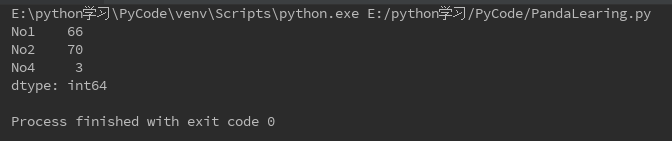
s = Series({'No1':66,'No2':70,'No3':-2,'No4':3})
s1 = s[s > 0]
print(s1)
对Series进行普通加减乘除以及平方等任何运算都是针对Series里所有数据的
s = Series({'No1':66,'No2':70,'No3':-2,'No4':3})
s1 = s**2
print(s1)
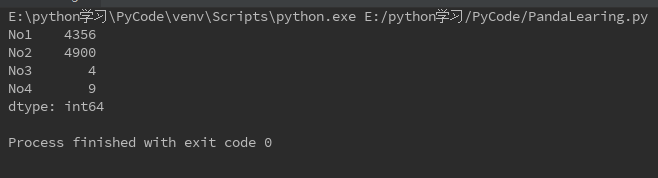
用in判断某索引或者数据值是否在Series中
判断索引(直接查询对象默认是查询键值)
s = Series({'No1':66,'No2':70,'No3':-2,'No4':3})
print(66 in s)
print('No1' in s)

判断键值(应在s.values中查找)
s = Series({'No1':66,'No2':70,'No3':-2,'No4':3})
print(66 in s.values)

两个Series之间的运算(只把具有相同索引的值进行运算,而不是共有的索引都赋值为NaN)
s1 = Series({'No1':66,'No2':70,'No3':-2,'No4':3})
s2 = Series({'No1':4,'No2':0,'No5':-2,'No4':67})
print(s1 + s2)

DataFrame
DataFrame 是一种二维的数据结构,与电子表格非常像,竖行为columns,横行为index。每一列可以理解为由一个Series构成。如下:
None column0 column1 index0 index1 定义方式
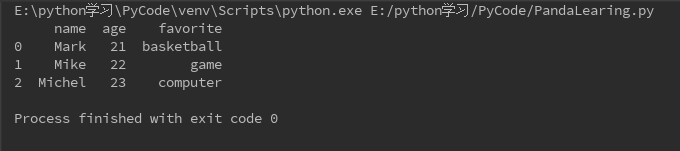
传入字典定义DataFrame
data = {"name":["Mark","Mike","Michel"],"age":[21,22,23],"favorite":["basketball","game","computer"]}
df = DataFrame(data)
# df = DataFrame(data,columns=['age','name','favorite']) 可以规定显示键(columns)的顺序
print(df)
自定义索引(默认为0,1,2等整数)
df = DataFrame(data,index=["No1","No2","No3"])

采用“字典套字典”的方式定义DataFrame
data = {"name":{"No1":"Mark","No2":"Mike","No3":"Michel"},"age":{"No1":21,"No2":22,"No3":23},"favorite":{"No1":"basketball","No2":"game","No3":"computer"}}
df = DataFrame(data)
print(df)

属性方法和常用操作
DataFrame.columns,能够显示素有的 columns 名称。
print(df.columns)

DataFrame.index,获得行索引信息
DataFrame.shape,获得df的size
DataFrame.shape[0],获得df的行数
DataFrame.shape[1],获得df的列数
DataFrame.values,获得df中的值
得到某竖列(可以理解为一个Series)的全部内容。
print(df['name'])

索引某几行
#索引前3行
df[:3]
可利用loc/iloc/ix索引函数进行索引
del df[0] 删除第0列
df.drop(0) 删除第0行
给某一列统一赋值
# 添加某一新列并且赋初始值:
df1['NewColumn'] = 0
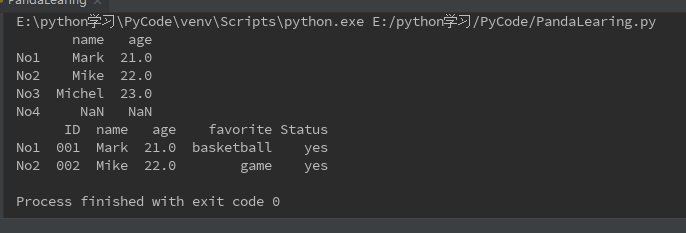
data = {"name":{"No1":"Mark","No2":"Mike","No3":"Michel"},"age":{"No1":21,"No2":22,"No3":23},"favorite":{"No1":"basketball","No2":"game","No3":"computer"}}
df = DataFrame(data)
# 新增一行No4,一列 ID 和 Status。
df1 = DataFrame(df,columns=["ID","name","age","favorite","Status"],index=["No1","No2","No3","No4"])
# 为Status统一赋值yes。
df1["Status"]="yes"
print(df1)

利用Series点对点添加数据(DataFrame每一列是一个Series)
# 创建ID列并且赋值
IDSeries = Series(['001','002','004'],index=["No1","No2","No4"])
df1['ID'] = IDSeries
Ps:Series的索引会与DataFrame的索引自动对齐,以此为依据定向添加数据。
DataFrame也可以单点精确的修改数据(仿照字典dict操作),比如:
df1['name']['No3'] = 'MICHEL'
print(df1)
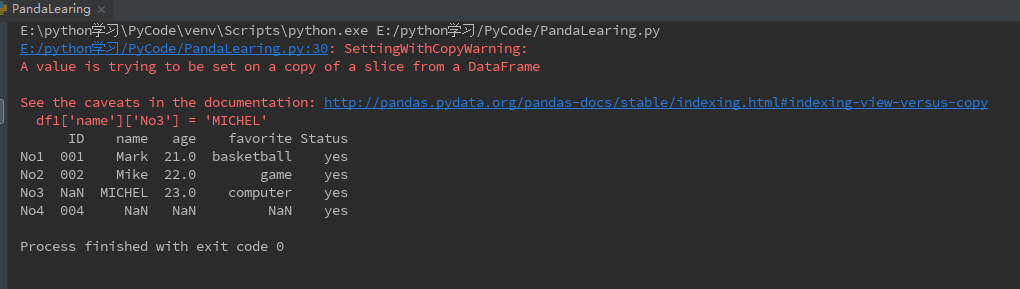
可见数据虽然是成功修改过来了,但是却报了一个SettingWithCopyWarning,其中原因是说“在DataFrame的一个切片上进行赋值操作”,虽然我也不理解在切片上进行数据处理有什么不妥,而且使用给定的索引工具loc创建新的df并进行相同操作也会报如上警告。最后看了网上找了一个比较好的解决方案是:先生成正确的Series再将整个Series插入DataFrame会更加有效。
DataFrame选择某些列或者行进行输出,生成新的DataFrame。
# 筛选 name列和age列
df2 = DataFrame(df1,columns=["name","age"])
print(df2)
# 筛选No1,No2行
df3 = DataFrame(df1,index=["No1","No2"])
print(df3)
根据某列sort排序
# 按照age递减排序
print(data.sort_values(["age"],ascending=False))
map(function)运算 传入一个函数,应用在dataframe的每一个元素上,返回一个dataframe。
apply(function,axis)运算 对dataframe的每一列或行进行运算,返回一个Series索引为原先的columns,数据值为函数值(ps:不指定axis对列操作,指定axis=1,对行操作)。
Group by操作
可以将dataframe导出到csv文件,to_csv方法。
df.to_csv(file_path, encoding='utf-8', index=False)
# index为False表示不导出dataframe的index数据
Summary
- 这篇博客是根据自己学习pandas库的使用过程中使用过的操作记录下来的,可能不够全面,排序也有点乱,但是后面进一步学习之后会进行补充和修改并且如果文章中有错误希望指出。
Pandas Learning的更多相关文章
- [Machine Learning with Python] Data Preparation by Pandas and Scikit-Learn
In this article, we dicuss some main steps in data preparation. Drop Labels Firstly, we drop labels ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- 数据分析(7):pandas介绍和数据导入和导出
前言 Numpy Numpy是科学计算的基础包,对数组级的运算支持较好 pandas pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数.pandas兼具Numpy高性能的数组计 ...
- [Machine Learning & Algorithm] 随机森林(Random Forest)
1 什么是随机森林? 作为新兴起的.高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来 ...
- [Machine Learning] 国外程序员整理的机器学习资源大全
本文汇编了一些机器学习领域的框架.库以及软件(按编程语言排序). 1. C++ 1.1 计算机视觉 CCV —基于C语言/提供缓存/核心的机器视觉库,新颖的机器视觉库 OpenCV—它提供C++, C ...
- do some projects in macine learning using python
i want to do some projects in macine learning using python help me in this context I don't know if y ...
- Python (1) - 7 Steps to Mastering Machine Learning With Python
Step 1: Basic Python Skills install Anacondaincluding numpy, scikit-learn, and matplotlib Step 2: Fo ...
- Machine Learning : Pre-processing features
from:http://analyticsbot.ml/2016/10/machine-learning-pre-processing-features/ Machine Learning : Pre ...
- Advice for applying Machine Learning
https://jmetzen.github.io/2015-01-29/ml_advice.html Advice for applying Machine Learning This post i ...
随机推荐
- CPU简单科普
CPU简单科普 本文仅限于对小白科普. 误解一:CPU使用率和硬盘使用率一样. 误解二:一台电脑只有一个CPU. 误解三:CPU的核数,就是CPU的数量. 误解三:CPU主频越高越厉害:CPU核数越多 ...
- apache 隐藏 index.php
在根目录下添加文件 .htaccess <IfModule mod_rewrite.c> Options +FollowSymlinks RewriteEngine On RewriteC ...
- PCA算法学习(Matlab实现)
PCA(主成分分析)算法,主要用于数据降维,保留了数据集中对方差贡献最大的若干个特征来达到简化数据集的目的. 实现数据降维的步骤: 1.将原始数据中的每一个样本用向量表示,把所有样本组合起来构成一个矩 ...
- Java代码优化笔记
指定类.方法的final修饰符 为类指定final修饰符可以让类不可以被继承,为方法指定final修饰符可以让方法不可以被重写.如果指定了一个类为final,则该类所有的方法都是final的.Java ...
- Proud Merchants(01背包变形)hdu3466
I - Proud Merchants Time Limit:1000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u ...
- linux7 安装SVN
1.安装Linux虚拟机-- 安装后配置a.停止防火墙# systemctl stop firewalld.service# systemctl disable firewalld.service# ...
- Linux常用基本命令(head)
head命令 作用:显示文件的头部内容,默认显示前面10行 格式: head [option] [file] -n <行数> -c <字节> ghostwu@dev:~/lin ...
- CSS图标文字不对齐
页面排版经常遇到‘图标+文字’的需求,正常样式写下来是这样 , 但产品要的应该是长这样 ,怎么办呢?其实很简单,加个样式看看 vertical-align: top/middle/bottom; ...
- Angular Npm Package.Json文件详解
Angular7 Npm Package.Json文件详解 近期时间比较充裕,正好想了解下Angular Project相关内容.于是将Npm官网上关于Package.json的官方说明文档进行了 ...
- Codeforces Round #545 (Div. 1) 简要题解
这里没有翻译 Codeforces Round #545 (Div. 1) T1 对于每行每列分别离散化,求出大于这个位置的数字的个数即可. # include <bits/stdc++.h&g ...