Python之聚类(KMeans,KMeans++)
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 17 16:41:46 2018 @author: zhen
""" import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import matplotlib.colors
from sklearn.cluster import KMeans
from sklearn.cluster import MiniBatchKMeans def expand(a, b):
d = (b - a) * 0.1
return a-b, b+d if __name__ == "__main__":
N = 400
centers = 4
data, y = ds.make_blobs(N, n_features=2, centers=centers, random_state=2)
data2, y2 = ds.make_blobs(N, n_features=2, centers=centers, cluster_std=(1, 2.5, 0.5, 2), random_state=2)
# 按行拼接numpy数组
data3 = np.vstack((data[y == 0][:], data[y == 1][:50], data[y == 2][:20], data[y == 3][:5]))
y3 = np.array([0] * 100 + [1] * 50 + [2] * 20 + [3] * 5)
cls = KMeans(n_clusters=4, init='k-means++')
y_hat = cls.fit_predict(data)
y2_hat = cls.fit_predict(data2)
y3_hat = cls.fit_predict(data3) m = np.array(((1, 1),(1, 3)))
data_r = data.dot(m)
y_r_hat = cls.fit_predict(data_r) matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
cm = matplotlib.colors.ListedColormap(list('rgbm'))
plt.figure(figsize=(9, 10), facecolor='w')
plt.subplot(421)
plt.title(u'原始数据')
plt.scatter(data[:, 0], data[:, 1], c=y, s=30, cmap=cm, edgecolors='none')
x1_min, x2_min = np.min(data, axis=0)
x1_max, x2_max = np.max(data, axis=0)
x1_min, x1_max = expand(x1_min, x1_max)
x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True) plt.subplot(422)
plt.title(u'KMeans++聚类')
plt.scatter(data[:, 0], data[:, 1], c=y_hat, s=30, cmap=cm, edgecolors='none')
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True) plt.subplot(423)
plt.title(u'旋转后数据')
plt.scatter(data[:, 0], data[:, 1], c=y, s=30, cmap=cm, edgecolors='none')
#x1_min, x2_min = np.min(data_r, axis=0)
#x1_max, x2_max = np.max(data_r, axis=0)
#x1_min, x1_max = expand(x1_min, x1_max)
#x2_min, x2_max = expand(x2_min, x2_max)
plt.ylim((x1_min, x1_max))
plt.xlim((x2_min, x2_max))
plt.grid(True) plt.subplot(424)
plt.title(u'旋转后KMeans++聚类')
plt.scatter(data[:, 0], data[:, 1], c=y_hat, s=30, cmap=cm, edgecolors='none')
plt.ylim((x1_min, x1_max))
plt.xlim((x2_min, x2_max))
plt.grid(True) plt.subplot(425)
plt.title(u'方差不相等数据')
plt.scatter(data2[:, 0], data2[:, 1], c=y2, s=30, cmap=cm, edgecolors='none')
#x1_min, x2_min = np.min(data2, axis=0)
#x1_max, x2_max = np.max(data2, axis=0)
#x1_min, x1_max = expand(x1_min, x1_max)
#x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True) plt.subplot(426)
plt.title(u'方差不相等KMeans++聚类')
plt.scatter(data2[:, 0], data2[:, 1], c=y2_hat, s=30, cmap=cm, edgecolors='none')
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True) plt.subplot(427)
plt.title(u'数量不相等数据')
plt.scatter(data3[:, 0], data3[:, 1], c=y3, s=30, cmap=cm, edgecolors='none')
#x1_min, x2_min = np.min(data3, axis=0)
#x1_max, x2_max = np.max(data3, axis=0)
#x1_min, x1_max = expand(x1_min, x1_max)
#x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True) plt.subplot(428)
plt.title(u'数量不相等KMeans++聚类')
plt.scatter(data3[:, 0], data3[:, 1], c=y3_hat, s=30, cmap=cm, edgecolors='none')
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True) plt.tight_layout(2, rect=(0, 0, 1, 0.97))
plt.suptitle(u'数据分布对KMeans聚类的影响', fontsize=18)
plt.show()
结果:
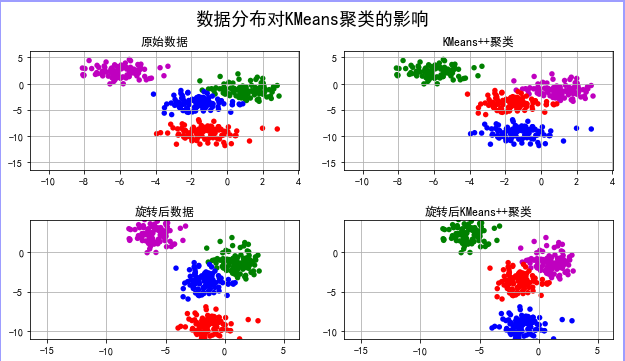

总结:可知不同的超参数对聚类的效果影响很大,因此在聚类之前采样的数据要尽量保持均匀,各类的方差最好先进行预研,以便达到较好的聚类效果!
Python之聚类(KMeans,KMeans++)的更多相关文章
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- Python笔记11------一个K-means聚类的小例子
#导入scipy库,库中已经有实现的kmeans模块,直接使用, #根据六个人的分数分为学霸或者学渣两类 import numpy as np from scipy.cluster.vq import ...
- [聚类算法] K-means 算法
聚类 和 k-means简单概括. 聚类是一种 无监督学习 问题,它的目标就是基于 相似度 将相似的子集聚合在一起. k-means算法是聚类分析中使用最广泛的算法之一.它把n个对象根据它们的属性分为 ...
- 机器学习(二)——K-均值聚类(K-means)算法
最近在看<机器学习实战>这本书,因为自己本身很想深入的了解机器学习算法,加之想学python,就在朋友的推荐之下选择了这本书进行学习,在写这篇文章之前对FCM有过一定的了解,所以对K均值算 ...
- K-均值聚类(K-means)算法
https://www.cnblogs.com/ybjourney/p/4714870.html 最近在看<机器学习实战>这本书,因为自己本身很想深入的了解机器学习算法,加之想学pytho ...
- 【数据挖掘】聚类之k-means(转载)
[数据挖掘]聚类之k-means 1.算法简述 分类是指分类器(classifier)根据已标注类别的训练集,通过训练可以对未知类别的样本进行分类.分类被称为监督学习(supervised learn ...
- 【机器学习】机器学习入门08 - 聚类与聚类算法K-Means
时间过得很快,这篇文章已经是机器学习入门系列的最后一篇了.短短八周的时间里,虽然对机器学习并没有太多应用和熟悉的机会,但对于机器学习一些基本概念已经差不多有了一个提纲挈领的了解,如分类和回归,损失函数 ...
- 机器学习——详解经典聚类算法Kmeans
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第12篇文章,我们一起来看下Kmeans聚类算法. 在上一篇文章当中我们讨论了KNN算法,KNN算法非常形象,通过距离公 ...
- R与数据分析旧笔记(十四) 动态聚类:K-means
动态聚类:K-means方法 动态聚类:K-means方法 算法 选择K个点作为初始质心 将每个点指派到最近的质心,形成K个簇(聚类) 重新计算每个簇的质心 重复2-3直至质心不发生变化 kmeans ...
随机推荐
- CentOS 6.7 下 MYSQL 5.7 的安装与配置
安装 #yum源 http://dev.mysql.com/downloads/repo/yum/ #安装 rpm -Uvh http://dev.mysql.com/get/mysql57-comm ...
- C++ string中的几个小陷阱,你掉进过吗?
C++开发的项目难免会用到STL的string,使用管理都比char数组(指针)方便的多,但在得心应手的使用过程中也要警惕几个小陷阱,避免我们项目出bug却迟迟找不到原因. 1. 结构体中的stri ...
- centos7 安装配置postgresql
考:https://www.linuxidc.com/Linux/2017-10/147536.htm http://blog.51cto.com/12482328/2090844 https://w ...
- dig命令详解
dig命令是常用的域名查询工具,可以用来测试域名系统工作是否正常 语法 dig(选项)(参数) 选项 @<服务器地址>:指定进行域名解析的域名服务器: -b<ip地址>:当主机 ...
- BeanDefinition到Bean
转自:http://songzi0206.iteye.com/blog/1430239 当 BeanDefinition 注册完毕以后, Spring Bean 工厂就可以随时根据需要进行实例化了.对 ...
- java RMI原理详解
java本身提供了一种RPC框架——RMI(即Remote Method Invoke 远程方法调用),在编写一个接口需要作为远程调用时,都需要继承了Remote,Remote 接口用于标识其方法可以 ...
- 从PHP5.0到PHP7.1的性能全评测
本文是最初是来自国外的这篇:PHP Performance Evolution 2016, 感谢高可用架构公众号翻译成了中文版, 此处是转载的高可用架构翻译后的文章从PHP 5到PHP 7性能全评测( ...
- 部署---阿里云服务器,linux, ubuntu ,部署django用到的一些命令
部署项目<下课说>APP时,总结出的一些命令和方法细节 Linux.ubuntu.django.uwsgi.nginx.mysql 里面有些是查找的资料,我也不大懂[手动笑哭],这还是部署 ...
- 音频播放时出现 Uncaught (in promise) DOMException: play() failed because the user didn't interact with the document first. https://goo.gl/xX8pDD
<audio id="play" controls="controls" loop="loop"> <source src ...
- <!--[if IE]><script type="text/javascript" src="matrix/js/html5.js"></script><![endif]-->代码解释
块注释例子 1. <!--[if !IE]><!--> 除IE外都可识别 <!--<![endif]-->2. <!--[if IE]> 所有的I ...