高性能JavaScript(字符串和正则表达式)
字符串连接
+/+=操作符连接
str += "one" + "two";
这是常用的连接字符串的方法,它运行的时候会经历下面四个步骤:
1、在内存中创建一个临时字符串;
2、连接后的”onetwo”被赋值给这个临时字符串;
3、临时字符串与str的当前值连接;
4、连接后的结果赋值给str。
下行代码可以避免产生临时字符串
str = str + "one" + "two";
赋值表达式由 str 开始作为基础,每次给它附加一个字符串,由左向右依次连接,因此避免了使用临时字符串。如果改变顺序 比如 把 str 放到中间 那就没有优化的效果了。这与浏览器合并字符串时分配内存的方法有关。
数组项合并
Array.prototype.join 方法将数组的所有元素合并成一个字符串,接收一个参数作为连接符。
var str = "i am people but i very shuai a",
Newstr = "",
Appends = 5000; while(Appends --){
Newstr += str
}
此代码连接了5000个长度为30的字符串,下图为IE7中完成所消耗的时间
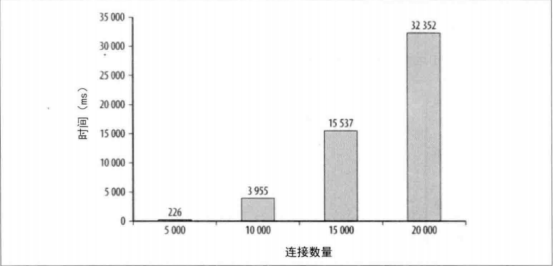
IE7 5000次合并用了226毫秒已经明显影响性能了,如何优化呢?
使用数组项合并生成通用的字符串
var str = "i am people but i very shuai a",
Strs = [],
Newstr = "",
Appends = 5000; while(Appends --){
Strs[Strs.length] = str;
}
Newstr = Strs.join("");
IE7测试结果
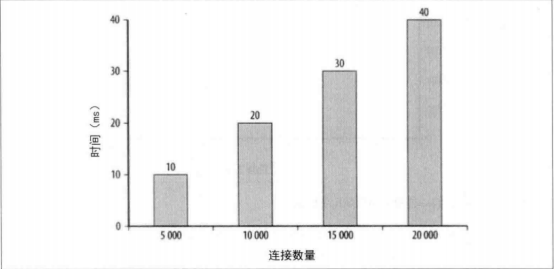
由于避免了重复分配内存和拷贝逐渐增大的字符串,于是性能提升很明显。
String.prototype.concat
Concat 可以接收任意数量的参数,并将每个参数附加到所调用的字符串上。
str = str.concat(s1);
str = str.concat(s1,s2,s3);
遗憾的是,使用concat 比使用简单的 + 和 += 稍慢,尤其是在IE opera 和 Chrome 慢的更明显。
正则表达式优化
正则表达式工作原理,了解原理有助于更好的解决各种影响正则性能的问题。
编译:浏览器验证正则表达式对象,之后把它转换成原生代码程序;把正则对象赋值给一个变量,可以避免重复编译。
设置起始位置:目标字符串的起始搜索位置,一般是字符串的起始字符、或者正则的lastIndex属性指定位置(限于带有/g的exec和test)、或者从第四步返回时的最后一次匹配的字符的下一个字符。
浏览器优化正则表达式引擎的办法是,在这一阶段中通过早期预测跳过一些不必要的工作。例如,如果一个正则表达式以^开头,IE 和Chrome通常判断在字符串起始位置上是否能够匹配,然后可避免愚蠢地搜索后续位置。另一个例子是匹配第三个字母是x的字符串,一个聪明的办法是先找到x,然后再将起始位置回溯两个字符。
匹配每个正则表达式字元:从字符串的起始位置开始,逐个检查文本和正则模式,当一个特定的字元匹配失败时,回溯到之前尝试匹配的位置,尝试其他可能的路径。
匹配成功或失败:如果在当前的字符串位置有一个完全匹配,则宣布匹配成功;如果当前位置没有所有可能的路径都没有成功匹配,会退回第二步,重新设置起始位置,开始另一轮匹配…直到以最后一个字符串为其实位置,仍未成功,则宣布匹配失败。
理解回溯(Backtracking)
回溯是匹配过程的基本组成部分,是正则如此强大的根源,也是正则的性能消耗所在,因此如何减少回溯是提高正则的关键所在。回溯一般在分支和重复的情况下出现:
分支与回溯
/h(ello|appy) hippo/.test("hello there, happy hippo");
正则开始的h与字符串起始位置的h匹配,接下来的分支,按从左到右的原则,(ello|appy)中的ello先尝试匹配,字符串h后面也是ello,匹配成功,于是继续匹配正则中(ello|appy)之后的空格,仍然匹配成功,继续匹配正则中空格之后的h,字符串空格之后是t,匹配失败。
回到正则的分支(ello|appy)(这就是回溯),尝试用appy对字符串第一位个字符h之后的字符进行匹配,失败,这里没有更多的选项,不再回溯。
第一个起始位置匹配失败,起始位置后延一位,重新匹配h…直到字符串起始位置为14时,匹配到h。
于是开启新一轮的字元匹配,进入分支(ello|appy)中的ello,匹配失败。
回到正则的分支(ello|appy)(再次回溯),appy匹配成功,退出分支,匹配后续的 hippo,匹配字符串happy hippo,匹配成功,结束匹配。
重复与回溯
var str = "<p>Para 1.</p><img src='smiley.jpg'><p>Para 2.</p><div>Div.</div>";
/<p>.*<\/p>/i.test(str);
正则开始的<p>与字符串起始位置的<p>匹配,接下来是.*(.匹配换行以外任意字符,*是贪婪量词,表示重复0次或多次,匹配尽可能多的次数),.*匹配后续一直到字符串尾部的所有字符。
尝试匹配正则中.*后面的<,在字符串最后匹配失败,然后每次向前回溯一个字符尝试匹配…,直到</div>的第一个字符匹配成功,接下来正则中的\/也与字符串中的/匹配成功,继续匹配正则中的p,匹配失败,返回</div>,继续向前回溯,直到第二段的</p>,匹配成功,返回<p>Para 1.</p><img src=’smiley.jpg’><p>Para 2.</p>,里面有2个段落和一张图片,结束匹配。
回溯失控
回溯失控的时候,可能导致浏览器假死数秒、数分钟或更长时间,以下面这个正则为例(用来匹配整个HTML字符串):
/<html>[\s\S]*?<head>[\s\S]*?<\/head>[\s\S]*?<body>[\s\S]*?<\/body>[\s\S]*?<\/html>/
匹配结构完整的html文件时,一切正常,但是有些标签缺失时问题就出现了,假如html文件最后的</html>缺失,最后一个[\s\S]*?重复会扩展到字符串末尾,匹配</html>失败,正则会依次向前搜索并记住回溯位置以便后续使用,当正则表达式扩展到倒数第二个[\s\S]*?——用它匹配由正则表达式的<\/body>匹配到的那个<body>,——然后继续查找</body>标签,直到字符串末尾。当所有步骤都失败时,倒数第三个[\s\S]*?将被扩展至字符串末尾,以此类推。
回溯失控终极方案:模拟原子组(向前查看+反向引用):(?=([\s\S]*?<head>))\1
/<html>(?=([\s\S]*?<head>))\1(?=([\s\S]*?<\/head>))\2(?=([\s\S]*?<body>))\3(?=([\s\S]*?<\/body>))\4[\s\S]*?<\/html>/
原子组(向前查看)的任何回溯位置都会被丢弃,从根源上避免了回溯失控,但是向前查看不会消耗任何字符作为全局匹配的一部分,捕获组+反向引用在这里可以用来解决这个问题,需要注意的是这的反向引用次数,即上面的\1、\2、\3、\4对应的位置。
其它不做赘述(因为我理解不了了)。
何时不使用正则表达式
如果仅仅是搜索字符串,而且事先知道字符串的哪部分需要被测试时,正则并不是最佳的解决方案。比如,检查一个字符串是否以分号结尾:
/;$/.test(str);正则会从第一个字符开始,逐个测试整个字符串,看她是否是分号,在判断是否在字符串的最后,当字符串很长时,需要的时间越多。
str.charAt(str.length – 1) == “;”;这个直接跳到最后一个字符,检查是否为分号,字符串很小是可能只是快一点点,但是对于长字符串,长度不会影响所需的时间。
字符串的原生方法都是很快的,比如slice、substr、substring、indexOf、lastIndexOf等,他们可以避免正则带来的性能开销。
去除字符串首尾空白
String.prototype.trim = function() {
var str = this.replace(/^\s+/, ""),
end = str.length - 1,
ws = /\s/;
while (ws.test(str.charAt(end))) {
end--;
}
return str.slice(0, end + 1);
}
这个解决方案用正则来去除头部的空白,位置锚^,会很快,主要是尾部的空白处理,像上面何时不使用正则表达式里说的,用正则并不是最佳的,这里用字符串原生方法结合正则来解决,可以避免性能受到字符串长度和空白的长度的影响。
小结:
当连接数量巨大或尺寸巨大的字符串时,数组项合并是唯一在IE7及更早版本中性能合理的方法。
不考虑IE7的话,数组项合并是最慢的连接字符串方法之一。推荐使用+和+=操作符代替。
回溯既是正则表达式匹配功能的基本组成部分,也是正则的低效原因。
回溯失控发生在正则本应快速匹配的地方,但因某些特殊的字符串匹配动作导致运行缓慢甚至浏览器崩溃。避免这个问题的方法是:使相邻的资源互斥,避免嵌套量词对同一字符串的相同部分多次匹配,通过重复利用预查的原子组去除不必要的回溯。
正则表达式并不总是完成工作的最佳工具,尤其当你只搜索字面字符串的时候。
去除字符串收尾空白有很多方法,但是用两个简单的正则表达式(一个去除头部一个去除尾部)来处理大量字符串内容能提供一个简洁而跨浏览器的方法。
高性能JavaScript(字符串和正则表达式)的更多相关文章
- 《高性能javascript》一书要点和延伸(上)
前些天收到了HTML5中国送来的<高性能javascript>一书,便打算将其做为假期消遣,顺便也写篇文章记录下书中一些要点. 个人觉得本书很值得中低级别的前端朋友阅读,会有很多意想不到的 ...
- 高性能JavaScript(您值得一看)
众所周知浏览器是使用单进程处理UI更新和JavaScript运行等多个任务的,而同一时间只能有一个任务被执行,如此说来,JavaScript运行了多长时间就意味着用户得等待浏览器响应需要花多久时间. ...
- 【读书笔记】读《高性能JavaScript》
这本<高性能JavaScript>讲述了有关JavaScript性能优化的方方面面,主要围绕以下几个方面: 1> 加载顺序 2> 数据访问(如怎样的数据类型访问最快,怎样的作用 ...
- 《高性能javascript》学习总结
本文是学习<高性能javascript>(Nichols C. Zakes著)的一些总结,虽然书比较过时,里面的知识点也有很多用不上了,但是毕竟是前人一步步探索过来的,记录着javascr ...
- 高性能javascript笔记
----------------------------------------------------------- 第一章 加载和执行 ------------------------------ ...
- 高性能JavaScript读书笔记
零.组织结构 根据引言,作者将全书划分为四个部分: 一.页面加载js的最佳方式(开发前准备) 二.改善js代码的编程技巧(开发中) 三.构建与部署(发布) 四.发布后性能检测与问题追踪(线上问题优化) ...
- 《高性能JavaScript》--读书笔记
第一章 加载和运行 延迟脚本 defer 该属性表明脚本在执行期间不会影响到页面的构造,脚本会先下载但被延迟到整个页面都解析完毕后再运行.只适用于外部脚本 <script src="j ...
- 高性能javascript学习总结(3)--数据访问
在 JavaScript 中,数据存储位置可以对代码整体性能产生重要影响.有四种数据访问类型:直接量,变量,数组项,对象成员. 直接量仅仅代表自己,而不存储于特定位置. JavaScr ...
- 《高性能Javascript》 Summary(二)
第四章.算法和流程控制 Algorithms And Flow Control 原因:代码整体结构是执行速度的决定因素之一.代码量少不一定运行速度快,代码量多不一定运行速度慢.性能损失与组织代码和具体 ...
- 《高性能JavaScript》 实用指南
By XFE-堪玉 阅读<高性能javascript>后,对其内容的一个整理和精简 加载与执行 将script标签放在body结尾标签上面 控制script标签数量(每一次script解析 ...
随机推荐
- TypeScript设计模式之装饰、代理
看看用TypeScript怎样实现常见的设计模式,顺便复习一下. 学模式最重要的不是记UML,而是知道什么模式可以解决什么样的问题,在做项目时碰到问题可以想到用哪个模式可以解决,UML忘了可以查,思想 ...
- 课程一(Neural Networks and Deep Learning),第二周(Basics of Neural Network programming)—— 0、学习目标
1. Build a logistic regression model, structured as a shallow neural network2. Implement the main st ...
- C++中:默认构造函数、析构函数、拷贝构造函数和赋值函数——转
对于一个空类,编译器默认产生4个成员函数:默认构造函数.析构函数.拷贝构造函数和赋值函数.1.构造函数:构造函数是一种特殊的类成员,是当创建一个类的时候,它被调用来对类的数据成员进行初始化和分配内存. ...
- 客户端禁用cookie
如果客户端禁用cookie的话不影响session使用 的设置方法: <sessionState cookieless="AutoDetect"
- java字节码文件
查看字节码文件: javap -verbose HellloWorld.class
- 详解C#泛型(一)
一.C#中的泛型引入了类型参数的概念,类似于C++中的模板,类型参数可以使类型或方法中的一个或多个类型的指定推迟到实例化或调用时,使用泛型可以更大程度的重用代码.保护类型安全性并提高性能:可以创建自定 ...
- The case for learned index structures
17年的旧文,最近因为SageDB论文而重读. 文章主要思路是通过学习key的顺序.结构等来预测record在位置.存在与否等.效果方面,据称部分场景下,相对b-tree可以优化70%的内存占用. 最 ...
- 软件架构设计学习总结(4):大数据架构hadoop
摘要:Admaster数据挖掘总监 随着互联网.移动互联网和物联网的发展,谁也无法否认,我们已经切实地迎来了一个海量数据的时代,数据调查公司IDC预计2011年的数据总量将达到1.8万亿GB,对这些海 ...
- Ansible工作流程详解
1:Ansible的使用者 ------>Ansible的使用者来源于多种维度,(1):CMDB(Configuration Management Database,配置管理数据库),CMDB存 ...
- VS2012 编译报错:找不到编译动态表达式所需的一个或多个类型。是否缺少引用?
今天编译公司项目,原本项目是3.5,由于现在要用到dynamic ,把target 改为4.0 ,编译时 报错误 “找不到编译动态表达式所需的一个或多个类型.是否缺少引用?”,然后根据另一个提示排错 ...