数据库索引、B树、B+树
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
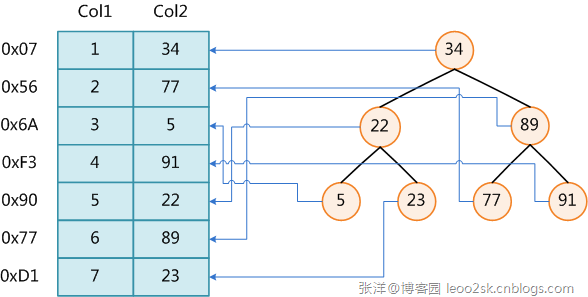
上图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:在经常需要搜索的列上,可以加快搜索的速度;在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。
唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。
主键索引
数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。
在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚集索引
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。
如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
B-/+Tree索引的性能分析
到这里终于可以分析B-/+Tree索引的性能了。
上文说过一般使用磁盘I/O次数评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
综上所述,用B-Tree作为索引结构效率是非常高的。
应该花时间学习B-树和B+树数据结构
=============================================================================================================
1)B树
B树中每个节点包含了键值和键值对于的数据对象存放地址指针,所以成功搜索一个对象可以不用到达树的叶节点。
成功搜索包括节点内搜索和沿某一路径的搜索,成功搜索时间取决于关键码所在的层次以及节点内关键码的数量。
在B树中查找给定关键字的方法是:首先把根结点取来,在根结点所包含的关键字K1,…,kj查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查的关键字在某个Ki或Ki+1之间,于是取Pi所指的下一层索引节点块继续查找,直到找到,或指针Pi为空时查找失败。
2)B+树
B+树非叶节点中存放的关键码并不指示数据对象的地址指针,非也节点只是索引部分。所有的叶节点在同一层上,包含了全部关键码和相应数据对象的存放地址指针,且叶节点按关键码从小到大顺序链接。如果实际数据对象按加入的顺序存储而不是按关键码次数存储的话,叶节点的索引必须是稠密索引,若实际数据存储按关键码次序存放的话,叶节点索引时稀疏索引。
B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
所以 B+树有两种搜索方法:
一种是按叶节点自己拉起的链表顺序搜索。
一种是从根节点开始搜索,和B树类似,不过如果非叶节点的关键码等于给定值,搜索并不停止,而是继续沿右指针,一直查到叶节点上的关键码。所以无论搜索是否成功,都将走完树的所有层。
B+ 树中,数据对象的插入和删除仅在叶节点上进行。
这两种处理索引的数据结构的不同之处:
a,B树中同一键值不会出现多次,并且它有可能出现在叶结点,也有可能出现在非叶结点中。而B+树的键一定会出现在叶结点中,并且有可能在非叶结点中也有可能重复出现,以维持B+树的平衡。
b,因为B树键位置不定,且在整个树结构中只出现一次,虽然可以节省存储空间,但使得在插入、删除操作复杂度明显增加。B+树相比来说是一种较好的折中。
c,B树的查询效率与键在树中的位置有关,最大时间复杂度与B+树相同(在叶结点的时候),最小时间复杂度为1(在根结点的时候)。而B+树的时候复杂度对某建成的树是固定的。
数据库索引、B树、B+树的更多相关文章
- 为什么MySQL数据库索引选择使用B+树?
在进一步分析为什么MySQL数据库索引选择使用B+树之前,我相信很多小伙伴对数据结构中的树还是有些许模糊的,因此我们由浅入深一步步探讨树的演进过程,在一步步引出B树以及为什么MySQL数据库索引选择使 ...
- 数据库索引数据结构总结——ART树就是前缀树
数据库索引数据结构总结 from:https://zhewuzhou.github.io/2018/10/18/Database-Indexes/ 摘要 数据库索引是数据库中最重要的组成部分,而索引的 ...
- B树和B+树对比,为什么MySQL数据库索引选择使用B+树?
一 基础知识 二叉树 根节点,第一层的节点 叶子节点,没有子节点的节点. 非叶子节点,有子节点的节点,根节点也是非叶子节点. B树 B树的节点为关键字和相应的数据(索引等) B+树 B+树是B树的一个 ...
- 数据库索引B-树和B+树
一开始学习数据结构的时候,主要学习的是数组,队列,链表,队列,栈,树这些数据结构,其中树主要学习二叉树,平衡二叉树,二叉搜索树等这些子节点最多只有两个的树结构.但是,当我们接触数据库的时候,你会发现数 ...
- 数据库索引的数据结构b+树
b+树的查找过程:如上图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针, ...
- 数据库索引的基石----B树
数据结构相对来说比较枯燥, 我尽量用最易懂的话,来把B树讲清楚.学过数据结构的人都接触过一个概念二叉树,简单来说,就是每个父节点最多有两个子节点.为了在二叉树上更快的进行元素的查找,人们通过不断的改进 ...
- 为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
B树: B+树 1) B+-tree的磁盘读写代价更低 B+-tree的内部结点并没有指向关键字具体信息的指针.因此其内部结点相对B 树更小.如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所 ...
- MySQL数据库索引之B+树
一.B+树是什么 B+ 树是一种树型数据结构,通常用于数据库和操作系统的文件系统中.B+ 树的特点是能够保持数据稳定有序,其插入与修改操作拥有较稳定的对数时间复杂度.B+ 树元素自底向上插入,这与二叉 ...
- 深入理解数据库索引采用B树和B+树的原因
前面几篇关于数据库底层磁盘文件读取,数据库索引实现细节进行了深入的研究,但是没有串联起来的讲解为什么数据库索引会采用B树和B+树而不是其他的数据结构,例如平衡二叉树.链表等,因此,本文打算从数据库文件 ...
- 数据库索引 B+树
问题1.数据库为什么要设计索引?索引类似书本目录,用于提升数据库查找速度.问题2.哈希(hash)比树(tree)更快,索引结构为什么要设计成树型?加快查找速度的数据结构,常见的有两类:(1)哈希,例 ...
随机推荐
- 【UI测试】--易用性
- Mac OS X下安装Python的MySQLdb模块【终结版】
1.下载源文件: https://pypi.org/project/MySQL-python/ 2.cd 到源文件所在目录: 3.在目录下使用 python setup.py install 命令安装 ...
- json(原生态)
什么是 JSON ? JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation) JSON 是轻量级的文本数据交换格式 JSON 独立于语言 * JSO ...
- 日志分析工具、日志管理系统、syslog分析
日志分析工具.日志管理系统.syslog分析 系统日志(Syslog)管理是几乎所有企业的重要需求.系统管理员将syslog看作是解决网络上系统日志支持的系统和设备性能问题的关键资源.人们往往低估了对 ...
- 2019.01.08 bzoj4543: [POI2014]Hotel加强版(长链剖分+dp)
传送门 代码: 长链剖分好题. 题意:给你一棵树,问树上选三个互不相同的节点,使得这个三个点两两之间距离相等的方案数. 思路: 先考虑dpdpdp. fi,jf_{i,j}fi,j表示iii子树中离 ...
- CString成员函数详解[转]
1.构造函数(常用) CString( const unsigned char* psz ); 例:char s[]="abcdef"; cha ...
- BZOJ 2440 [中山市选2011]完全平方数 (二分 + 莫比乌斯函数)
2440: [中山市选2011]完全平方数 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 4805 Solved: 2325[Submit][Sta ...
- Node简单的控制台读取和文件操作
const fs = require('fs'); const readline = require('readline'); const rl = readline.createInterface( ...
- vip导致的serverConnection closed by foreign host问题
问题描述: 应应用需求,设计搭建了一套带tokudb存储引擎的percona数据库,使用的是常见的双主架构.具体的架构如下图所示: 在172.20.32.x1上进行验证的时候出现了下面的问题: FHo ...
- DEM数据及其他数据下载
GLCF大家都知道吧?http://glcf.umiacs.umd.edu/data/ +++++++++++++++去年12月份听遥感所一老师说TM08初将上网8万景,可是最近一直都没看到相关的网页 ...