快速制作规则及获取规则提取器API
1. 引言
前面文章的测试案例都用到了集搜客Gooseeker提供的规则提取器,在网页抓取工作中,调试正则表达式或者XPath都是特别繁琐的,耗时耗力,工作枯燥,如果有一个工具可以快速生成规则,而且可以可视化的即时验证,就能把程序员解放出来,投入到创造性工作中。
之前文章所用的例子中的规则都是固定的,如何自定义规则再结合提取器提取我们想要的网页内容呢?对于程序员来说,理想的目标是掌握一个通用的爬虫框架,每增加一个新目标网站就要跟着改代码,这显然不是好工作模式。这就是本篇文章的主要内容了,本文使用一个案例说明怎样将新定义的采集规则融入到爬虫框架中。也就是用可视化的集搜客GooSeeker爬虫软件针对亚马逊图书商品页做一个采集规则,并结合规则提取器抓取网页内容。
2. 安装集搜客GooSeeker爬虫软件
2.1. 前期准备
进入集搜客官网产品页面,下载对应版本。我的电脑上已经安装了Firefox 38,所以这里只需下载爬虫。
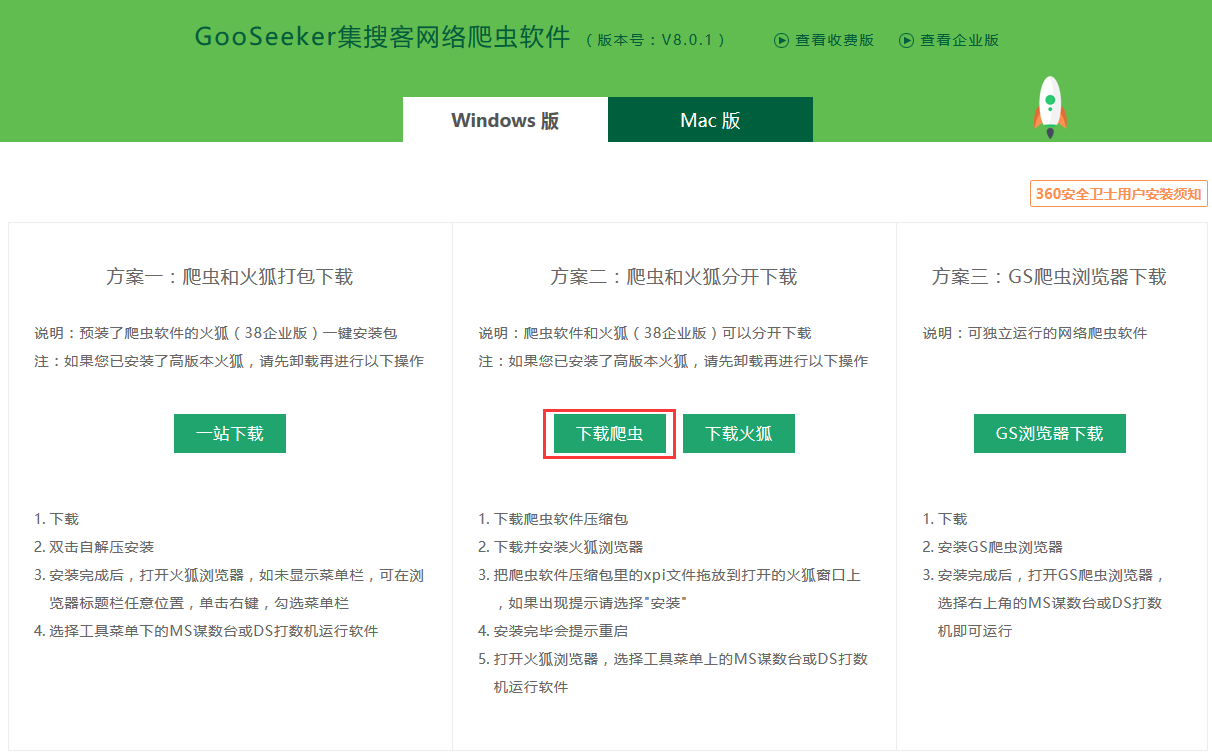
2.2 安装爬虫
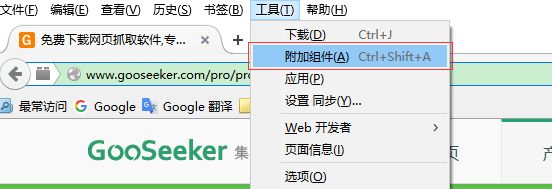
打开Firefox –> 点击菜单工具 –> 附加组件 –> 点击右上角附加组件的工具 –> 选择从文件安装附加组件 -> 选中下载好的爬虫xpi文件 –> 立即安装
下一步

下一步

3. 开始制作抓取规则
3.1 运行规则定义软件
点击浏览器菜单:工具-> MS谋数台 弹出MS谋数台窗口。
3.2 做规则
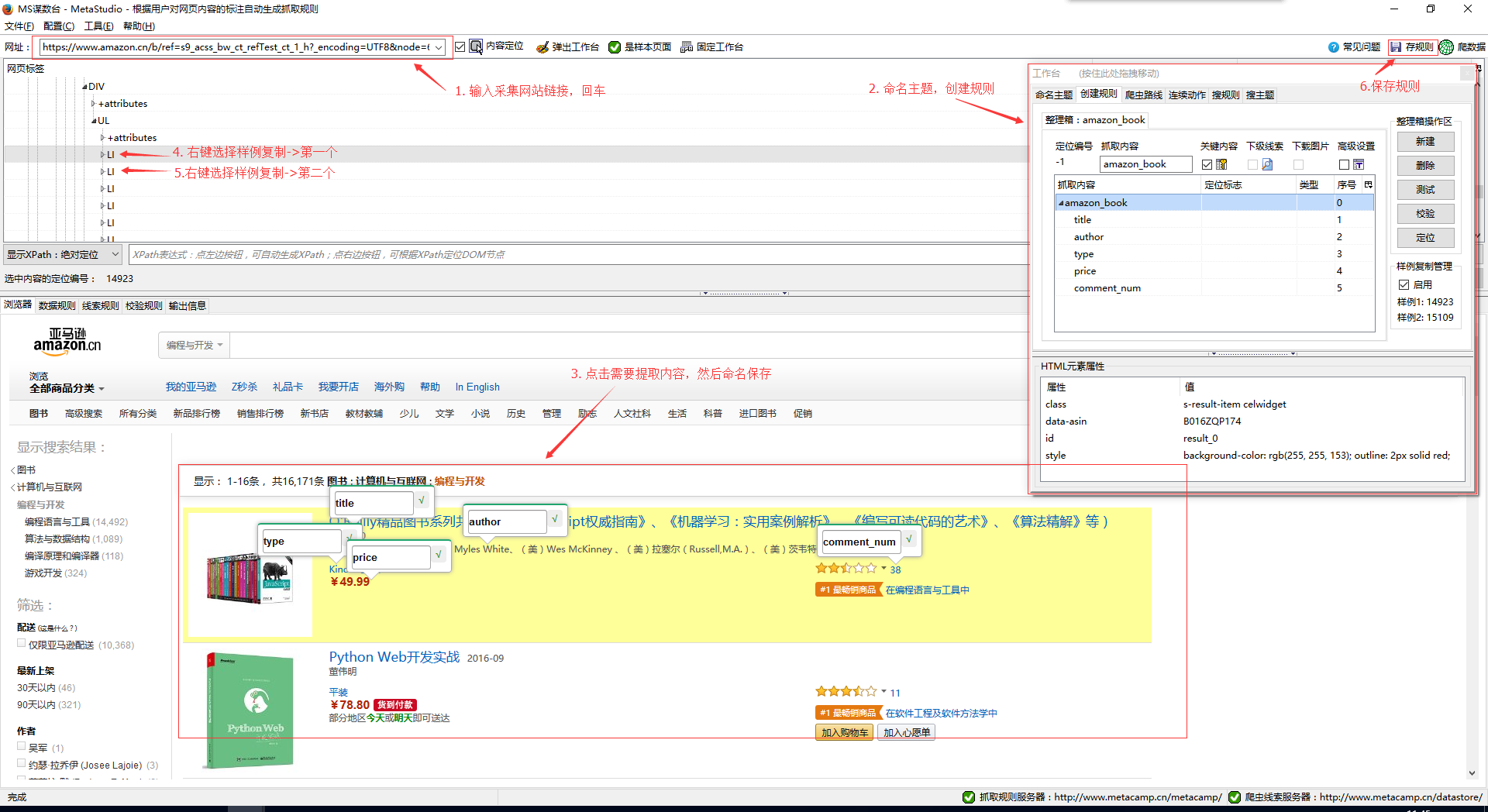
在网址栏输入我们要采集的网站链接,然后回车。当页面加载完成后,在工作台页面依次操作:命名主题名 -> 创建规则 -> 新建整理箱 -> 在浏览器菜单选择抓取内容,命名后保存。
4. 申请规则提取器API KEY
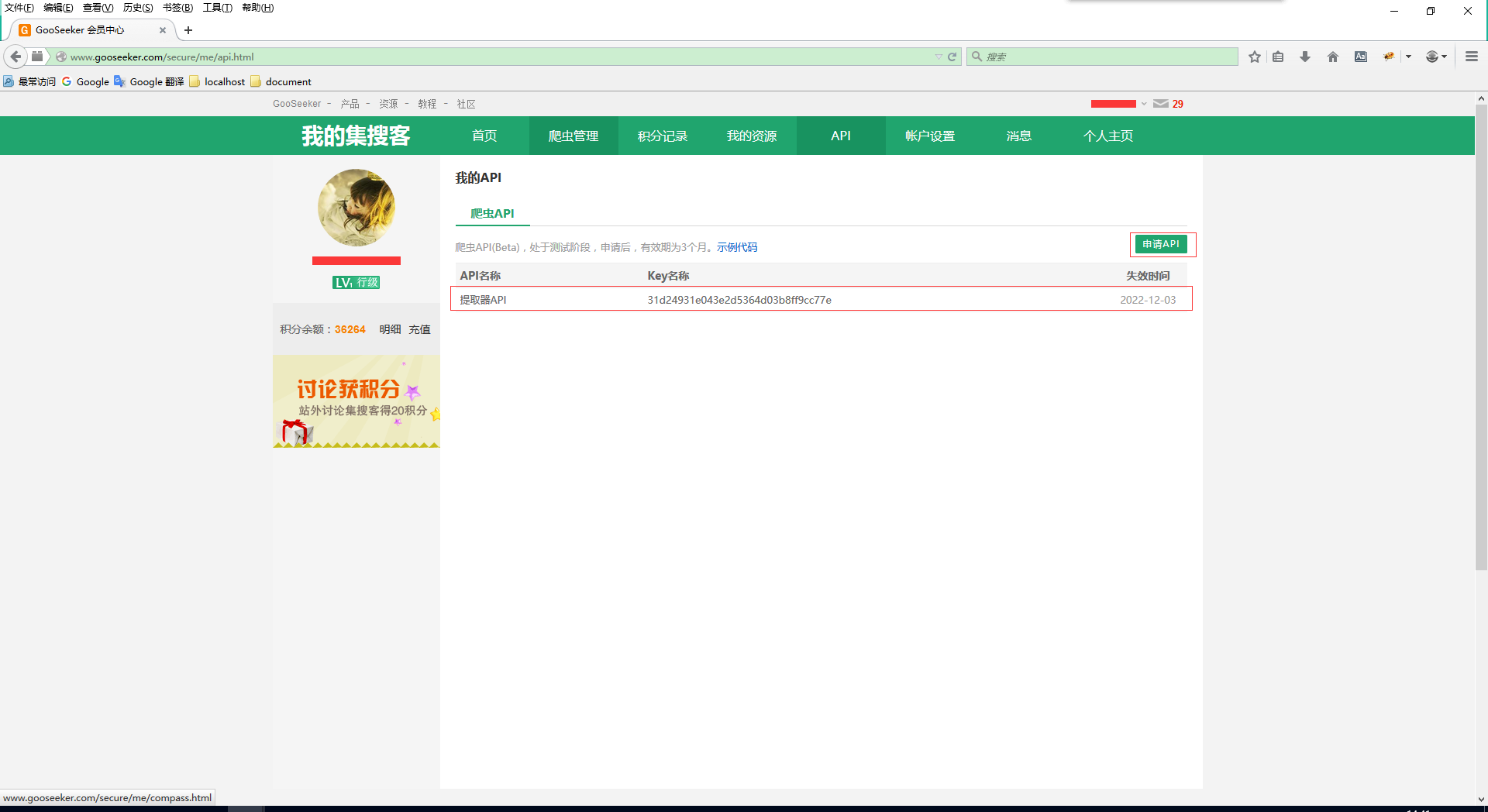
打开集搜客Gooseeke官网,注册登陆后进入会员中心 -> API -> 申请API
5. 结合提取器API敲一个爬虫程序
5.1 引入Gooseeker规则提取器模块gooseeker.py
(下载地址: https://github.com/FullerHua/gooseeker/tree/master/core), 选择一个存放目录,这里为E:\demo\gooseeker.py
5.2 与gooseeker.py同级创建一个.py后缀文件
如这里为E:\Demo\third.py,再以记事本打开,敲入代码: 注释:代码中的31d24931e043e2d5364d03b8ff9cc77e 就是API KEY,用你申请的代替;amazon_book_pc 是规则的主题名,也用你的主题名代替
# -*- coding: utf-8 -*-
# 使用GsExtractor类的示例程序
# 以webdriver驱动Firefox采集亚马逊商品列表
# xslt保存在xslt_bbs.xml中
# 采集结果保存在third文件夹中
import os
import time
from lxml import etree
from selenium import webdriver
from gooseeker import GsExtractor # 引用提取器
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "amazon_book_pc") # 设置xslt抓取规则 # 创建存储结果的目录
current_path = os.getcwd()
res_path = current_path + "/third-result"
if os.path.exists(res_path):
pass
else:
os.mkdir(res_path) # 驱动火狐
driver = webdriver.Firefox()
url = "https://www.amazon.cn/s/ref=sr_pg_1?rh=n%3A658390051%2Cn%3A!658391051%2Cn%3A658414051%2Cn%3A658810051&page=1&ie=UTF8&qid=1476258544"
driver.get(url)
time.sleep(2) # 获取总页码
total_page = driver.find_element_by_xpath("//*[@class='pagnDisabled']").text
total_page = int(total_page) + 1 # 用简单循环加载下一页链接(也可以定位到下一页按钮,循环点击)
for page in range(1,total_page):
# 获取网页内容
content = driver.page_source.encode('utf-8') # 获取docment
doc = etree.HTML(content)
# 调用extract方法提取所需内容
result = bbsExtra.extract(doc) # 保存结果
file_path = res_path + "/page-" + str(page) + ".xml"
open(file_path,"wb").write(result)
print('第' + str(page) + '页采集完毕,文件:' + file_path) # 加载下一页
if page < total_page - 1:
url = "https://www.amazon.cn/s/ref=sr_pg_" + str(page + 1) + "?rh=n%3A658390051%2Cn%3A!658391051%2Cn%3A658414051%2Cn%3A658810051&page=" + str(page + 1) + "&ie=UTF8&qid=1476258544"
driver.get(url)
time.sleep(2)
print("~~~采集完成~~~")
driver.quit()
5.3 执行third.py
打开命令提示窗口,进入third.py文件所在目录,输入命令 :python third.py 回车

5.4 查看结果文件
进入third.py文件所在目录,找到名称为result-2的文件夹然后打开
6. 总结
制作规则时,由于定位选择的是偏好id,而采集网址的第二页对应页面元素的id属性有变化,所以第二页内容提取出现了问题,然后对照了一下网页元素发现class是一样的,果断将定位改为了偏好class,这下提取就正常了。下一篇《在Python3.5下安装和测试Scrapy爬网站》简单介绍Scrapy的使用方法。
7. 集搜客GooSeeker开源代码下载源
快速制作规则及获取规则提取器API的更多相关文章
- 爬虫Scrapy框架-Crawlspider链接提取器与规则解析器
Crawlspider 一:Crawlspider简介 CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著 ...
- JMeter学习-011-JMeter 后置处理器实例之 - 正则表达式提取器(三)多参数获取进阶引用篇
前两篇文章分表讲述了 后置处理器 - 正则表达式提取器概述及简单实例.多参数获取,相应博文敬请参阅 简单实例.多参数获取. 此文主要讲述如何引用正则表达式提取器获取的数据信息.其实,正则表达式提取器获 ...
- JMeter学习-009-JMeter 后置处理器实例之 - 正则表达式提取器(二)多参数获取
前文简述了通过后置处理器 - 正则表达式提取器 获取 HTTP请求 响应结果中的特定数据,未看过的亲,敬请参阅 JMeter学习-008-JMeter 后置处理器实例之 - 正则表达式提取器(一). ...
- Jmeter-正则表达式提取器获取token-小实例
步骤一:在需要获取token的接口上,添加正则表达式提取器 说明: (1) Apply to:应用范围 Main sample and sub-samples:匹配范围包括当前父取样器并覆盖至子取样器 ...
- Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作 ...
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
- JMeter 后置处理器之正则表达式提取器详解
后置处理器之正则表达式提取器详解 by:授客 QQ:1033553122 1. 添加正则表达式提取器 右键线程组->添加->后置处理器->正则表达式提取器 2. 提取器配置介绍 ...
- Jmeter正则表达式提取器(转载)
转载自 http://blog.csdn.net/qq_35885203 使用jmeter来测试时,经常会碰到需要上下文传输数据的情况,如登录后生成的token,在其他页面的操作,都需传入这个toke ...
- Jmeter--正则表达式提取器
正则提取器的一般使用场景是, 在我第二个请求参数中需要加入第一个请求的返回值, 此时通过正则提取器可以提取第一个请求返回值中指定的字段信息并赋值, 在第二个请求参数中直接引用该变量即可 jmeter的 ...
随机推荐
- JSON C# Class Generator是一个从JSON文本中生成C#内的应用程序
JSON C# Class Generator是一个从JSON文本中生成C#内的应用程序 .NET平台开源项目速览(18)C#平台JSON实体类生成器JSON C# Class Generator ...
- [HDU] 1698 Just a Hook [线段树区间替换]
Just a Hook Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- [OpenJudge] 百练2754 八皇后
八皇后 Description 会下国际象棋的人都很清楚:皇后可以在横.竖.斜线上不限步数地吃掉其他棋子.如何将8个皇后放在棋盘上(有8 * 8个方格),使它们谁也不能被吃掉!这就是著名的八皇后问题. ...
- C语言开发CGI程序的简单例子
这年头用C语言开发cgi的已经不多,大多数的web程序都使用java.php.python等这些语言了. 但是本文将做一些简单的cgi实例. 首先配置环境 #这里是使用的apache AddHandl ...
- 2013第49周三IE9文档模式
今天完善了原有模块的代码和注释,然后继续之前新模块的开发,并写了两边的service接口,除了因为邮件中有部分问题让我分心外,专心下来写代码的感觉真好,今天基本上没遇到多少让我新感悟的技术问题,就总结 ...
- c++ 友元类
一.友元类相关概念 要将私有成员数据或函数暴露给另一个类,必须将后者声明为友元类. 注意三点: (1)友元关系不能传递 (2)友元关系不能继承 (3)友元关系不能互通
- OpenMeetings(3)----启动顺序解析
OpenMeetings系统较大,代码量也不小,如果对前端的OpenLaszlo开发不熟悉的话,刚研究代码时,确实有种丈二和尚摸不着头脑的感觉.一番研究之后,终于初步理清了系统的初步动作流程,具体执行 ...
- paip.提升性能--- mysql 建立索引 删除索引 很慢的解决.
paip.提升性能--- mysql 建立索引 删除索引 很慢的解决. 作者Attilax , EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blo ...
- Hive 12、Hive优化
要点:优化时,把hive sql当做map reduce程序来读,会有意想不到的惊喜. 理解hadoop的核心能力,是hive优化的根本. 长期观察hadoop处理数据的过程,有几个显著的特征: 1. ...
- javascript 继承机制设计思想
作者: 阮一峰 原文链接:http://www.ruanyifeng.com/blog/2011/06/designing_ideas_of_inheritance_mechanism_in_java ...