HBase之Table.put客户端流程
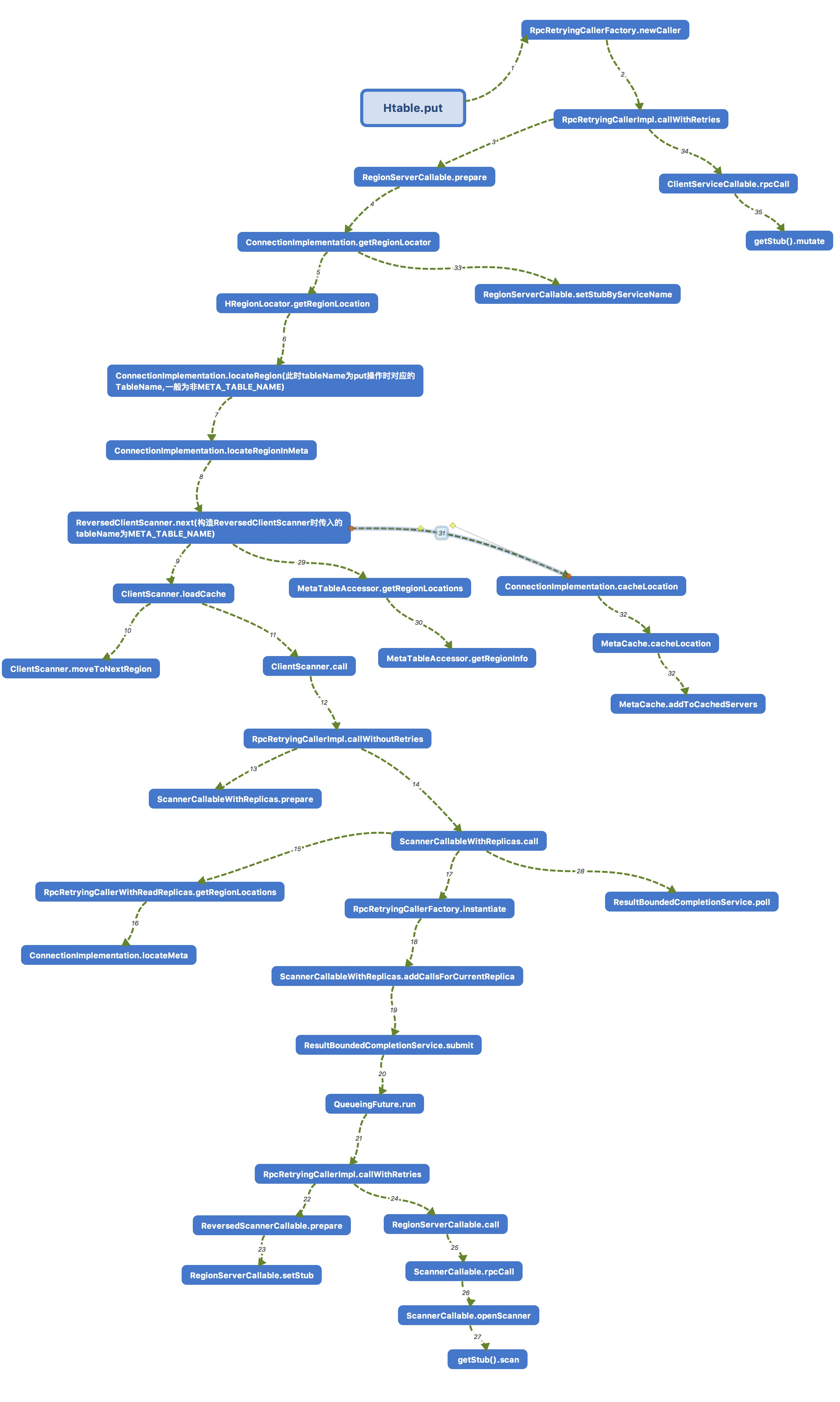
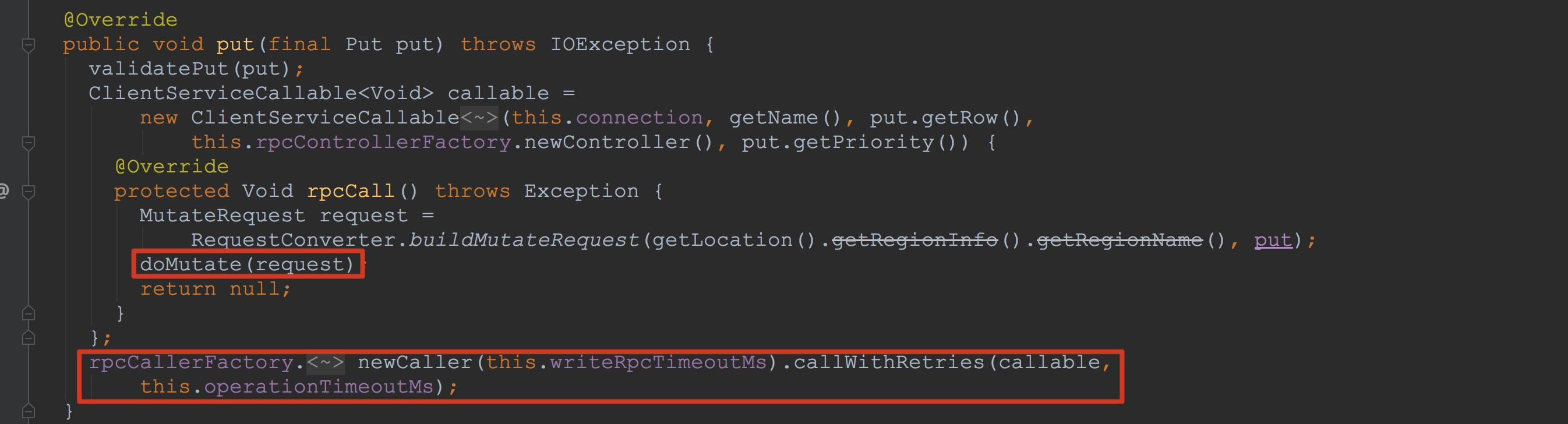 这里我先讲一下这一节的最后调用流程,也同时让大家明确一下在本节我着重要讲解的流程是哪块。在上图中我已经表示出来了,后面方法的调用最后调用到了上面新创建的ClientServiceCallable中覆写的rpcCall方法,也就是调用到了ClientServiceCallable.doMutate。关于这个方法中具体与服务端的交互流程在本节我就略过,但是,在后面的内容中,我会谈到类似的情况,如果大家感兴趣的话,可以继续后面的内容。
这里我先讲一下这一节的最后调用流程,也同时让大家明确一下在本节我着重要讲解的流程是哪块。在上图中我已经表示出来了,后面方法的调用最后调用到了上面新创建的ClientServiceCallable中覆写的rpcCall方法,也就是调用到了ClientServiceCallable.doMutate。关于这个方法中具体与服务端的交互流程在本节我就略过,但是,在后面的内容中,我会谈到类似的情况,如果大家感兴趣的话,可以继续后面的内容。 接下来让我们回到本节的重点。首先是RpcRetryingCallerFactory.newCaller方法的调用,该方法使用RpcRetryingCallerFactory的成员参数创建了RpcRetryingCaller,用于后面对于RetryingCallable的调用(该方法在后面也会多次调用,在后面我就不贴图了)。
接下来让我们回到本节的重点。首先是RpcRetryingCallerFactory.newCaller方法的调用,该方法使用RpcRetryingCallerFactory的成员参数创建了RpcRetryingCaller,用于后面对于RetryingCallable的调用(该方法在后面也会多次调用,在后面我就不贴图了)。 接下来让我们来到RpcRetryingCallerImpl.callWithRetries。这个方法是本节中最为重要的方法,在后面也会多次用到。方法虽然比较长,但大多是异常的情况的解决,在本节中我们就单单介绍callable.prepare与callable.call两个方法。至于interceptor.intercept,由于在构造RpcRetryingCallerFactory时默认的interceptor类型为RetryingCallerInterceptorFactory.NO_OP_INTERCEPTOR,在本节并不会有其它影响,所以我们暂时不需要关注。
接下来让我们来到RpcRetryingCallerImpl.callWithRetries。这个方法是本节中最为重要的方法,在后面也会多次用到。方法虽然比较长,但大多是异常的情况的解决,在本节中我们就单单介绍callable.prepare与callable.call两个方法。至于interceptor.intercept,由于在构造RpcRetryingCallerFactory时默认的interceptor类型为RetryingCallerInterceptorFactory.NO_OP_INTERCEPTOR,在本节并不会有其它影响,所以我们暂时不需要关注。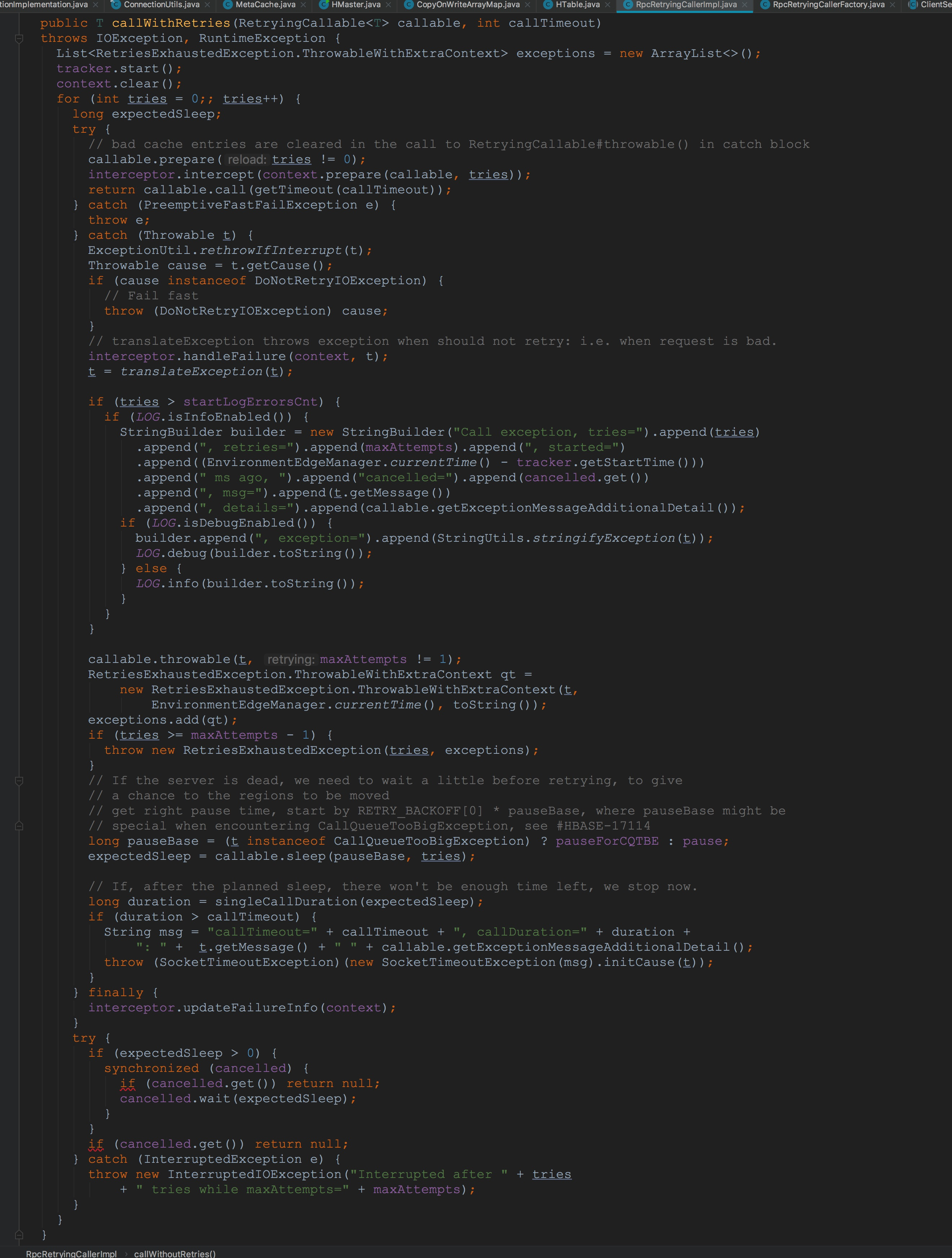 上面的方法调用的callable具体类型为覆写了rpcCall方法的ClientServiceCallable,下面让我们来到ClientServiceCallable类的内部。ClientServiceCallable继承自RegionServerCallable,因此,上面方法实际调用的是RegionServerCallable.prepare与RegionServerCallable.call。
上面的方法调用的callable具体类型为覆写了rpcCall方法的ClientServiceCallable,下面让我们来到ClientServiceCallable类的内部。ClientServiceCallable继承自RegionServerCallable,因此,上面方法实际调用的是RegionServerCallable.prepare与RegionServerCallable.call。 首先让我们来到RegionServerCallable.prepare方法。这里比较重要的方法我已经框选出来了。需要大家特别留意的是最后的setStubByServiceName,一是因为他比较重要,二是我在后面的内容才会介绍,大家到时候可能忘记了,所以在这里特别提醒一下大家。
首先让我们来到RegionServerCallable.prepare方法。这里比较重要的方法我已经框选出来了。需要大家特别留意的是最后的setStubByServiceName,一是因为他比较重要,二是我在后面的内容才会介绍,大家到时候可能忘记了,所以在这里特别提醒一下大家。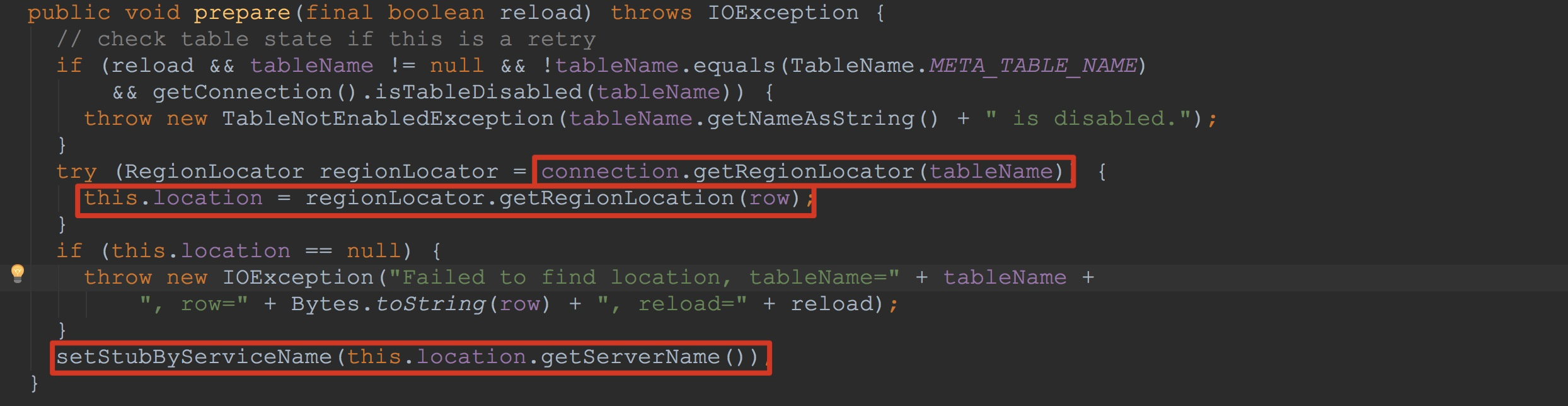 在调用HRegionLocator.getRegionLocation时,这里会有一系列简单方法的调用,由于在上面的导图中我并没有画出,在这里我就一一贴图描述。
在调用HRegionLocator.getRegionLocation时,这里会有一系列简单方法的调用,由于在上面的导图中我并没有画出,在这里我就一一贴图描述。



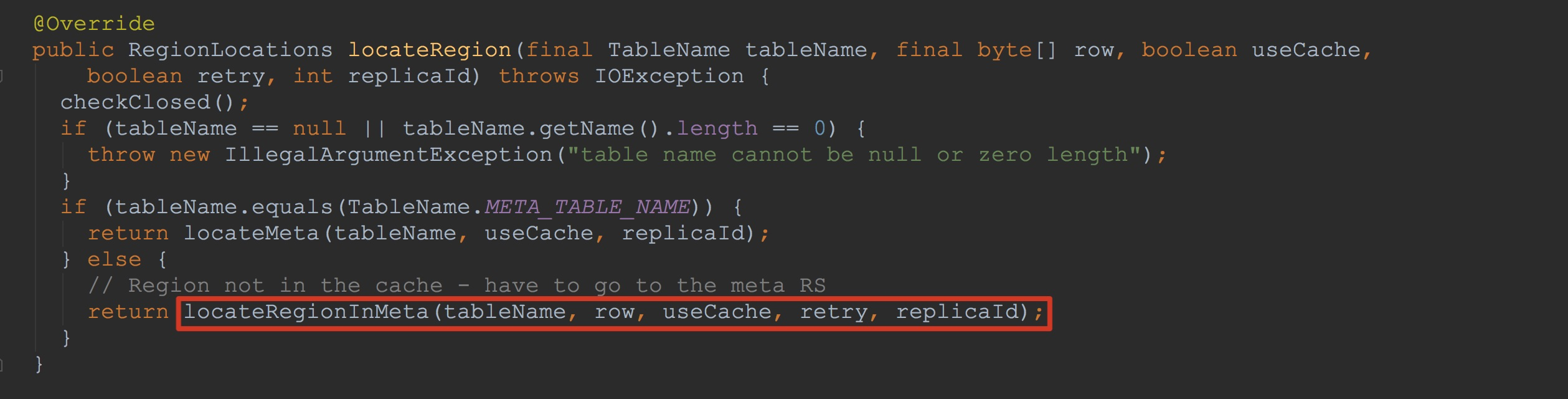 一系列方法走下来,到这里就到了比较重要的方法。由于这个是长图,没有办法框选除重点,我就在文字中一一介绍该方法中调用的比较好重要的方法。
一系列方法走下来,到这里就到了比较重要的方法。由于这个是长图,没有办法框选除重点,我就在文字中一一介绍该方法中调用的比较好重要的方法。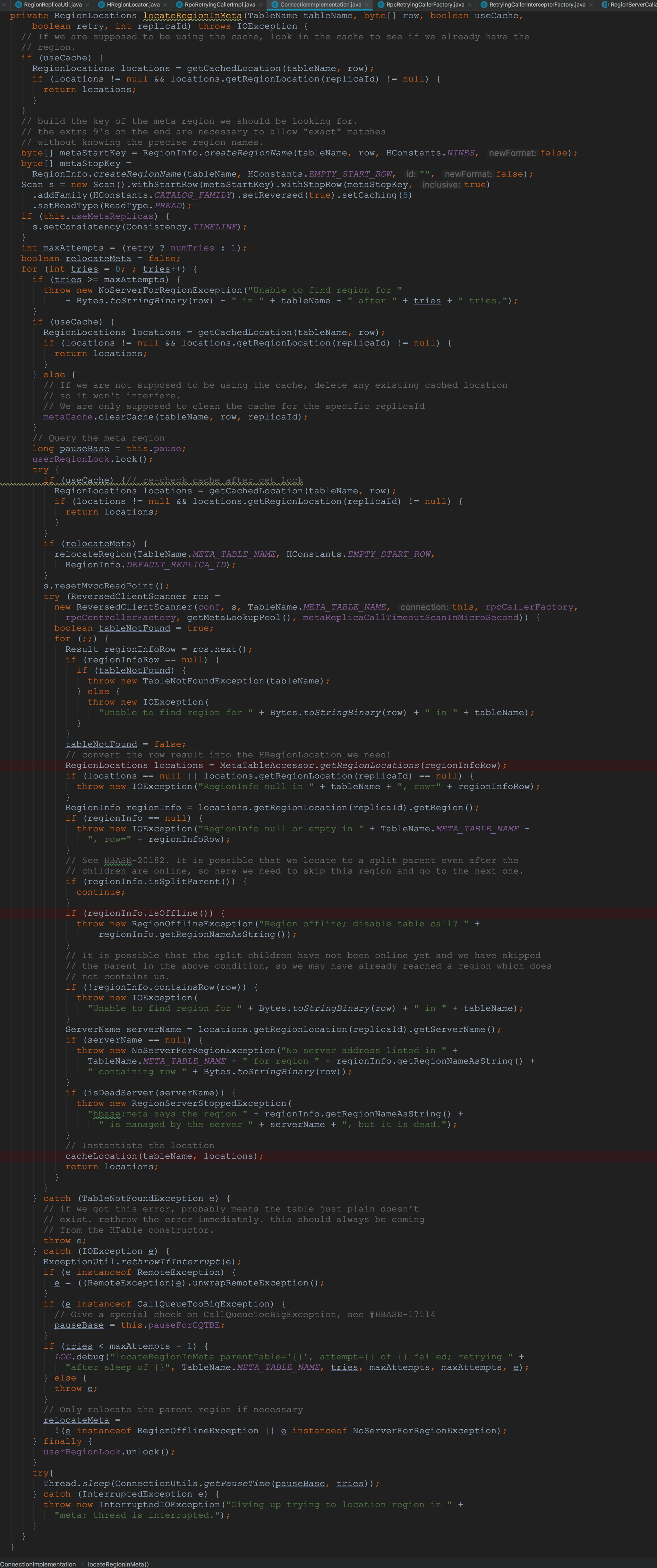 上面,我将ConnectionImplementation.locateRegionInMeta方法中调用的各个流程都简单介绍了一下,下面,我就选择其中比较重要的方法来详细描述。
上面,我将ConnectionImplementation.locateRegionInMeta方法中调用的各个流程都简单介绍了一下,下面,我就选择其中比较重要的方法来详细描述。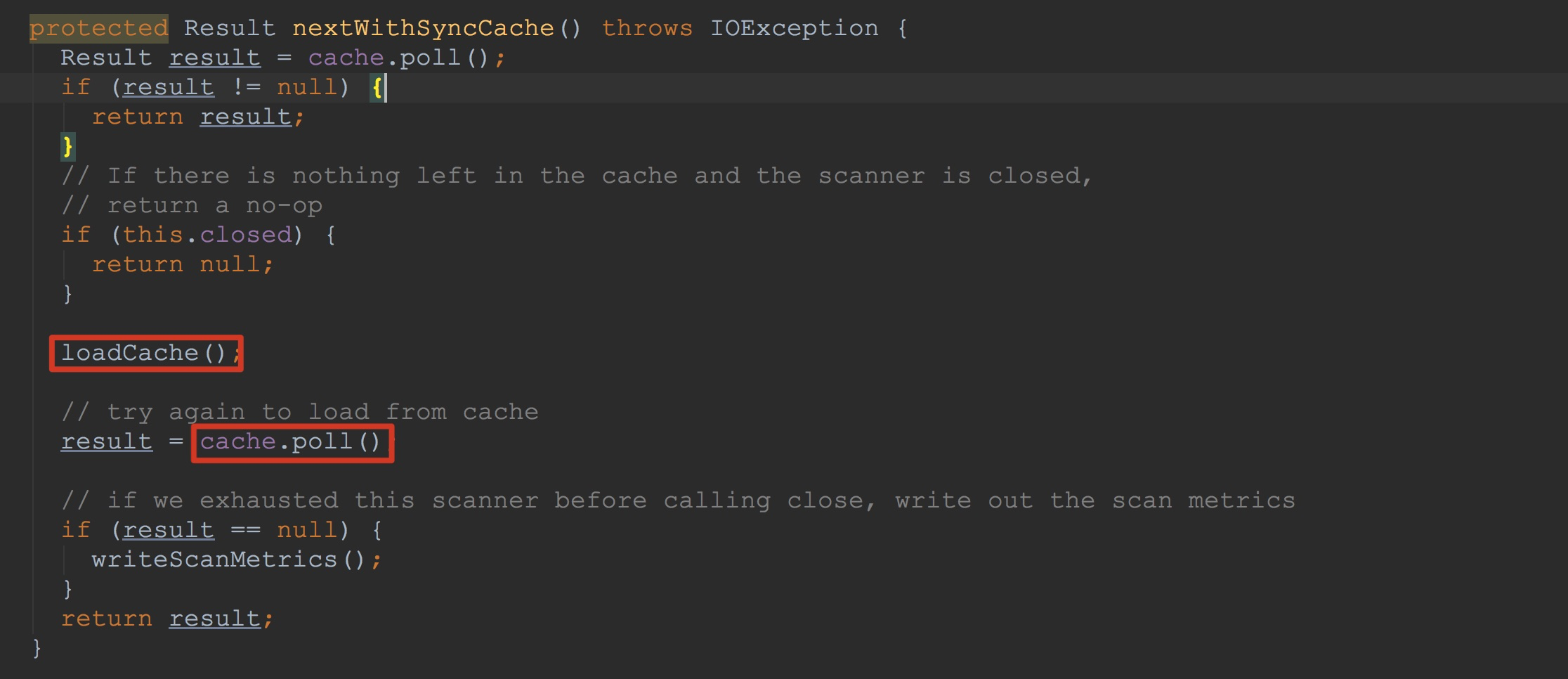 上图框选的两个方法都比较重要,让我们首先介绍比较复杂的loadCache,如下图所示。
上图框选的两个方法都比较重要,让我们首先介绍比较复杂的loadCache,如下图所示。 上面我提到过很多次ClientScanner.call方法,但是都没有详细描述,下面我就特意来讲解该方法。其实这个方法很简单,只是调用了方法RpcRetryingCaller.callWithoutRetries。这里的caller是在ReversedClientScanner方法构造时创建的(上面只是提到说构造ReversedClientScanner有需要注意的地方,也就是这里,其截图我在上面也已经贴出来了)。
上面我提到过很多次ClientScanner.call方法,但是都没有详细描述,下面我就特意来讲解该方法。其实这个方法很简单,只是调用了方法RpcRetryingCaller.callWithoutRetries。这里的caller是在ReversedClientScanner方法构造时创建的(上面只是提到说构造ReversedClientScanner有需要注意的地方,也就是这里,其截图我在上面也已经贴出来了)。 接下来让我们来到RpcRetryingCallerImpl.callWithoutRetries。这里的入参callable我在上面的方法loadCache已经介绍过了。其类型为ScannerCallableWithReplicas。由于ScannerCallableWithReplicas.prepare方法为空实现,我在这里就不贴图了,接下来将重点放在ScannerCallableWithReplicas.call。
接下来让我们来到RpcRetryingCallerImpl.callWithoutRetries。这里的入参callable我在上面的方法loadCache已经介绍过了。其类型为ScannerCallableWithReplicas。由于ScannerCallableWithReplicas.prepare方法为空实现,我在这里就不贴图了,接下来将重点放在ScannerCallableWithReplicas.call。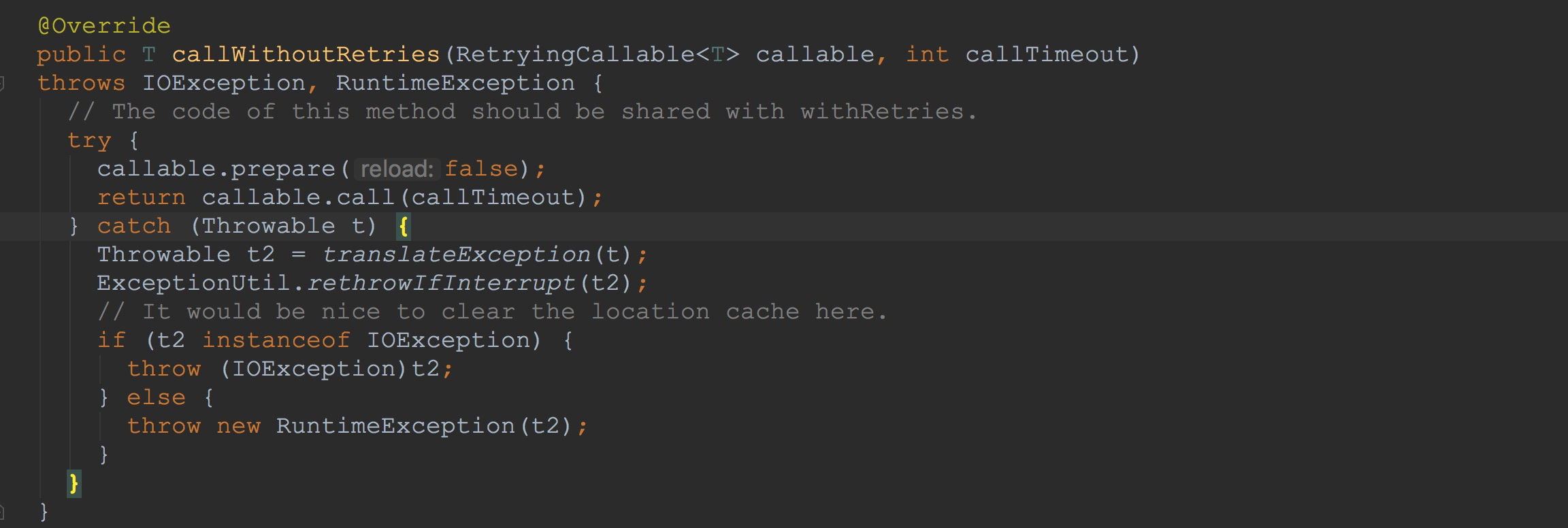 让我们来到ScannerCallableWithReplicas.call,如下图所示。
让我们来到ScannerCallableWithReplicas.call,如下图所示。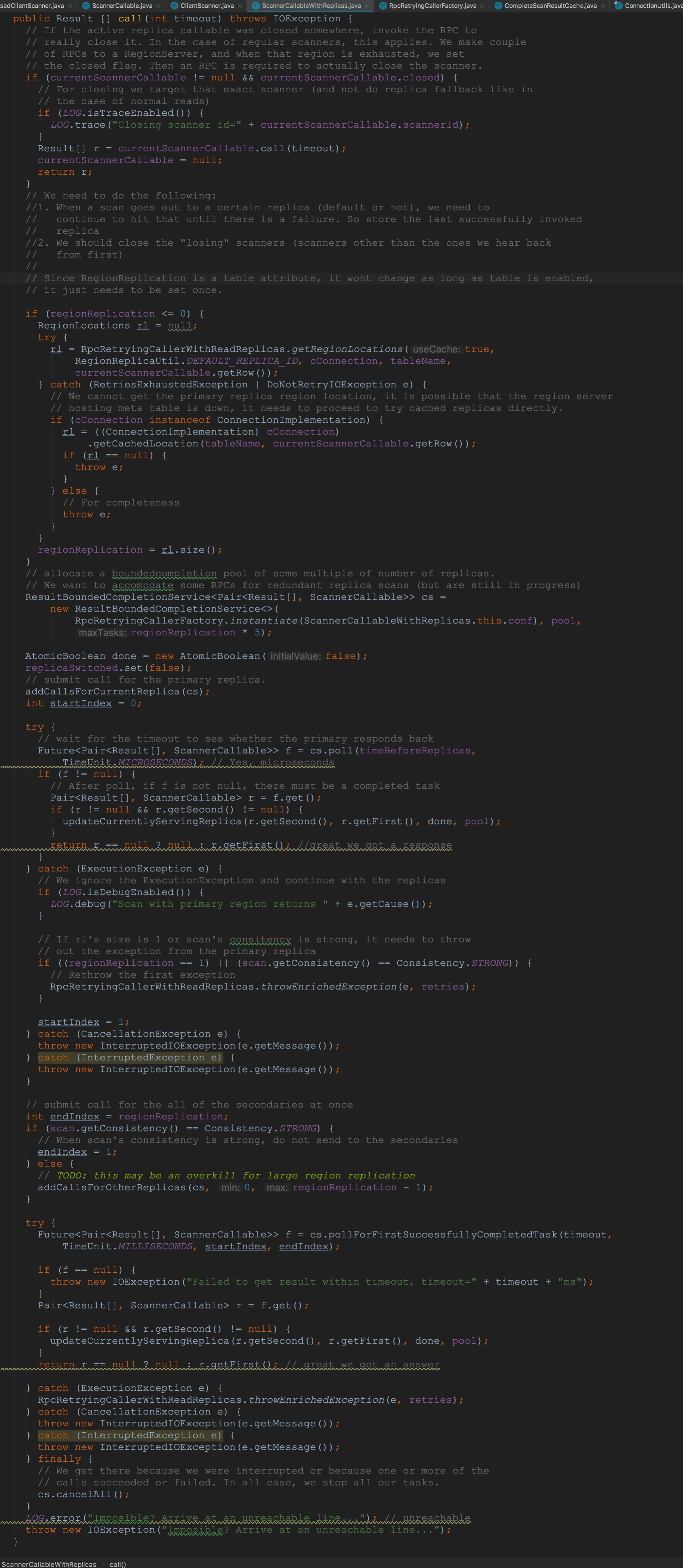 首先来到ScannerCallableWithReplicas.addCallsForCurrentReplica方法。容易看到,将成员变量currentScannerCallable封装到RetryingRPC中。然后调用了ResultBoundedCompletionService.submit。这里着重提醒一下大家,这里的currentScannerCallable类型为ReversedScannerCallable。
首先来到ScannerCallableWithReplicas.addCallsForCurrentReplica方法。容易看到,将成员变量currentScannerCallable封装到RetryingRPC中。然后调用了ResultBoundedCompletionService.submit。这里着重提醒一下大家,这里的currentScannerCallable类型为ReversedScannerCallable。 接着让我们来到ResultBoundedCompletionService.submit,如下图所示。
接着让我们来到ResultBoundedCompletionService.submit,如下图所示。 接下来让我们来到QueueingFuture。在下图中,我框选出了其中比较重要的方法。
接下来让我们来到QueueingFuture。在下图中,我框选出了其中比较重要的方法。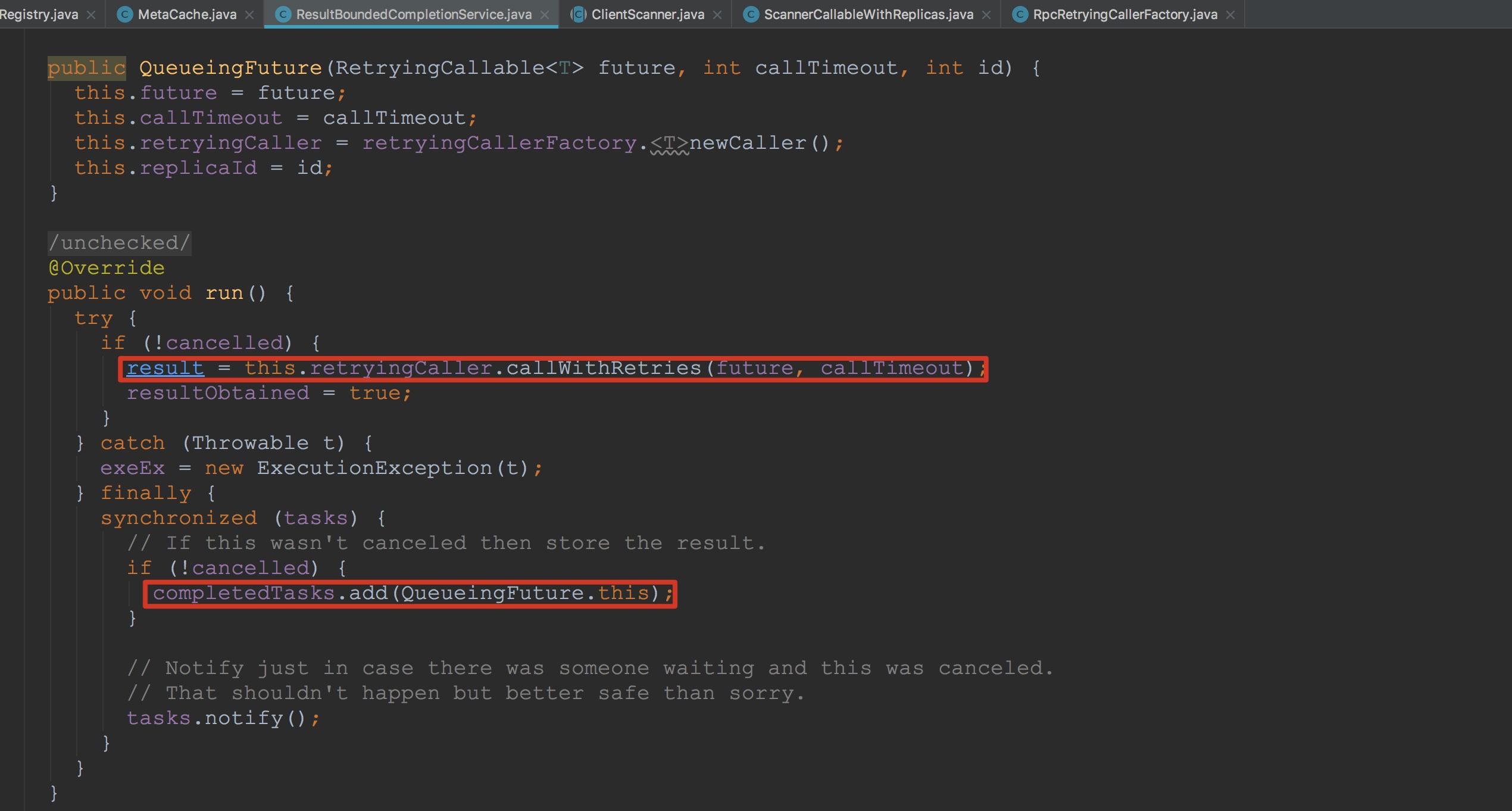 让我们来到ScannerCallableWithReplicas.RetryingRPC.prepare方法。如下图所示。大家可能对这里的成员变量callable比较模糊了,大家可以往上翻到方法addCallsForCurrentReplica的描述,没错这里的callable就是ScannerCallableWithReplicas的成员变量currentScannerCallable。而ScannerCallableWithReplicas.currentScannerCallable正是在构造ScannerCallableWithReplicas时传入的ReversedScannerCallable。
让我们来到ScannerCallableWithReplicas.RetryingRPC.prepare方法。如下图所示。大家可能对这里的成员变量callable比较模糊了,大家可以往上翻到方法addCallsForCurrentReplica的描述,没错这里的callable就是ScannerCallableWithReplicas的成员变量currentScannerCallable。而ScannerCallableWithReplicas.currentScannerCallable正是在构造ScannerCallableWithReplicas时传入的ReversedScannerCallable。 接下来让我们来到ReversedScannerCallable.prepare。由于这是第一次调用prepare方法,因此其成员变量instantiated为false。这里简单提一下,这里的getRow方法获取的是我们调用put时的行键,也就是我们对于目标表的rowKey。由于这里的tableName为TableName.META_TABLE_NAME,其rowKey在后面并没有用到。
接下来让我们来到ReversedScannerCallable.prepare。由于这是第一次调用prepare方法,因此其成员变量instantiated为false。这里简单提一下,这里的getRow方法获取的是我们调用put时的行键,也就是我们对于目标表的rowKey。由于这里的tableName为TableName.META_TABLE_NAME,其rowKey在后面并没有用到。 让我们来到ConnectionImplementation.getClient方法。看过我博文《HBase之HRegionServer启动(含与HMaster交互)》的同学看到这里可能就比较熟悉。 没错,这里正是通过ClientProtos.ClientService.newBlockingStub构造了协议ClientProtos.ClientService的客户端stub。关于与服务端交互的流程,我在《HBase之HRegionServer启动(含与HMaster交互)》中已经具体介绍了,大家感兴趣的可以去看一下,我们这里来描述比较重要一个点。
让我们来到ConnectionImplementation.getClient方法。看过我博文《HBase之HRegionServer启动(含与HMaster交互)》的同学看到这里可能就比较熟悉。 没错,这里正是通过ClientProtos.ClientService.newBlockingStub构造了协议ClientProtos.ClientService的客户端stub。关于与服务端交互的流程,我在《HBase之HRegionServer启动(含与HMaster交互)》中已经具体介绍了,大家感兴趣的可以去看一下,我们这里来描述比较重要一个点。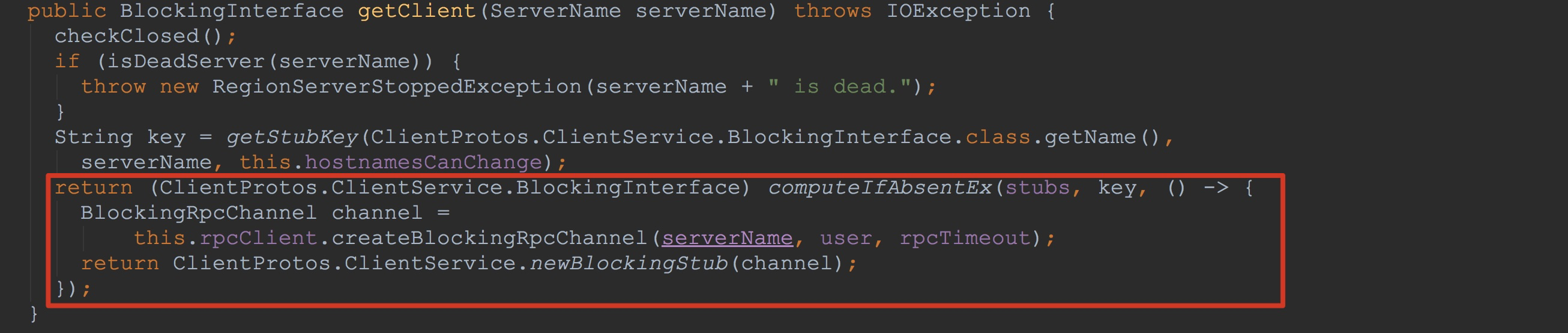 在第一次调用时,我们的stubs中并没有到该serverName的客户端stub,因此调用了入参supplier的get方法。也就是我们上面看到的lambda表达式方法内容被调用。
在第一次调用时,我们的stubs中并没有到该serverName的客户端stub,因此调用了入参supplier的get方法。也就是我们上面看到的lambda表达式方法内容被调用。 到这里,ReversedScannerCallable.prepare方法就调用完成了。这个还有一个需要注意的点就是ReversedScannerCallable.prepare方法的最后将其成员变量instantiated置为true。
到这里,ReversedScannerCallable.prepare方法就调用完成了。这个还有一个需要注意的点就是ReversedScannerCallable.prepare方法的最后将其成员变量instantiated置为true。 也就是说,接下来应该调用的是ReversedScannerCallable.call。由于其并没有call方法,因此,会一直调用到其父类RegionServerCallable.call。如下图所示。这里的rpcController类型为HBaseRpcControllerImpl。接下来调用了rpcCall方法。由于ReversedScannerCallable中并没有rpcCall方法的实现,而在其父类ScannerCallable有实现rpcCall。
也就是说,接下来应该调用的是ReversedScannerCallable.call。由于其并没有call方法,因此,会一直调用到其父类RegionServerCallable.call。如下图所示。这里的rpcController类型为HBaseRpcControllerImpl。接下来调用了rpcCall方法。由于ReversedScannerCallable中并没有rpcCall方法的实现,而在其父类ScannerCallable有实现rpcCall。 接下来,让我们来到ScannerCallable.rpcCall。由于默认的成员变量scannerId为-1,因此,会调用openScanner。由于openScanner方法仅仅是通过Client协议发送到服务端。关于rpc流程我在博客《hbase之RPC调用流程简介》中已经介绍过了,感兴趣的同学可以去看一下,那篇博文讲的比较浅显,我会在春节期间将那篇内容更新,大家可以关注我,到时候有更新大家也就收到通知了。
接下来,让我们来到ScannerCallable.rpcCall。由于默认的成员变量scannerId为-1,因此,会调用openScanner。由于openScanner方法仅仅是通过Client协议发送到服务端。关于rpc流程我在博客《hbase之RPC调用流程简介》中已经介绍过了,感兴趣的同学可以去看一下,那篇博文讲的比较浅显,我会在春节期间将那篇内容更新,大家可以关注我,到时候有更新大家也就收到通知了。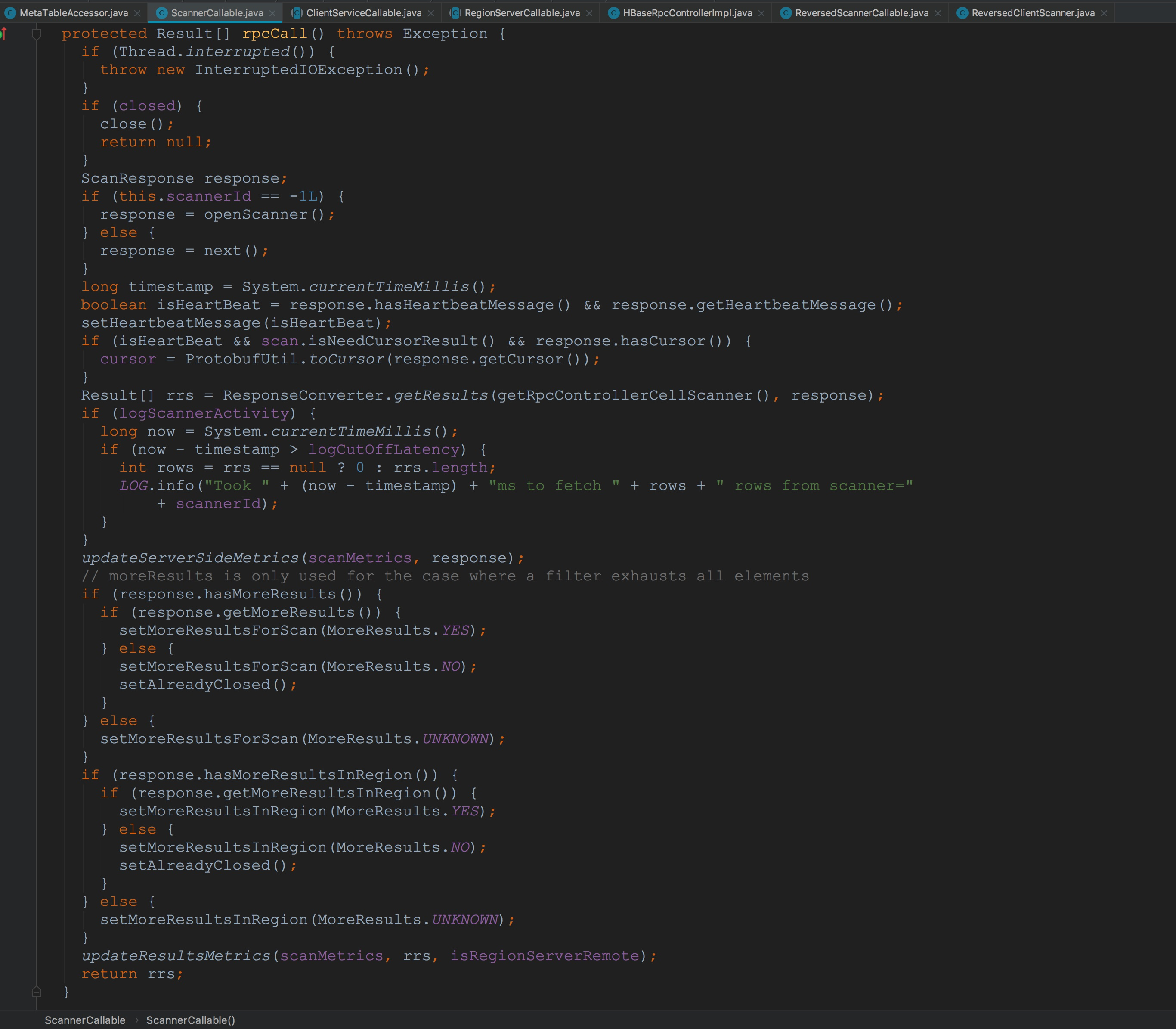 让我们来到ResponseConverter.getResults。这个方法的主要作用是将CellScanner中Cell的或ScanResponse中的PB类型的results转换为java类型的Result。至于该方法的详细描述我要放到后面开设的第二章节,也就是HBase中客户端协议各个操作中来讲解,因为这里流程是比较复杂的,要结合上服务端的流程才能讲述清楚。所以这里暂时略过。
让我们来到ResponseConverter.getResults。这个方法的主要作用是将CellScanner中Cell的或ScanResponse中的PB类型的results转换为java类型的Result。至于该方法的详细描述我要放到后面开设的第二章节,也就是HBase中客户端协议各个操作中来讲解,因为这里流程是比较复杂的,要结合上服务端的流程才能讲述清楚。所以这里暂时略过。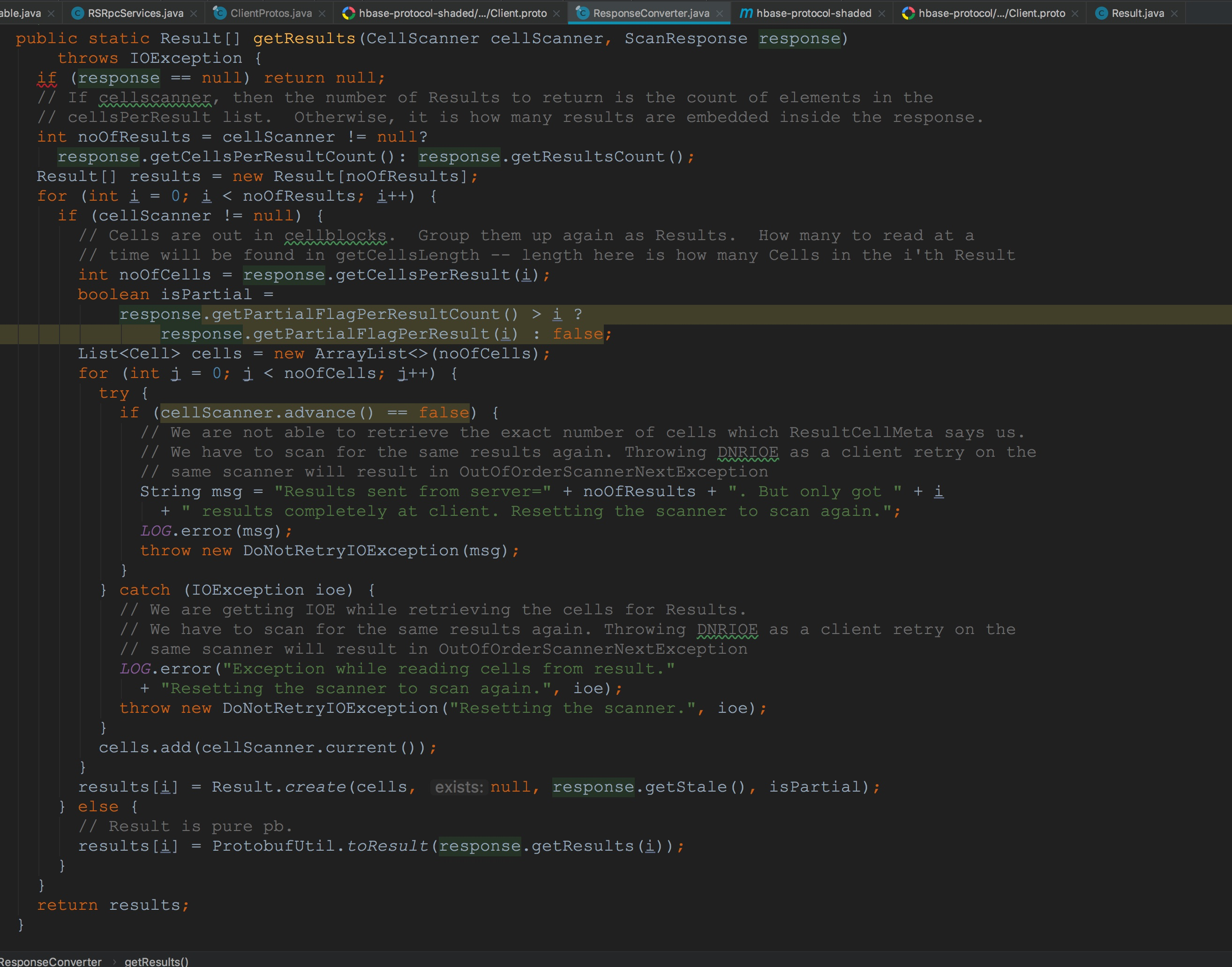 到这里,一个完整的RpcRetryingCallerImpl.callWithRetries方法调用流程可以说是完结了。然后在ResultBoundedCompletionService.QueueingFuture.run方法的后面,将当前QueueingFuture添加到ResultBoundedCompletionService成员变量completedTasks中(虽然我在上面提到过,但这里还是重述一下,以便我们后面的理解)。
到这里,一个完整的RpcRetryingCallerImpl.callWithRetries方法调用流程可以说是完结了。然后在ResultBoundedCompletionService.QueueingFuture.run方法的后面,将当前QueueingFuture添加到ResultBoundedCompletionService成员变量completedTasks中(虽然我在上面提到过,但这里还是重述一下,以便我们后面的理解)。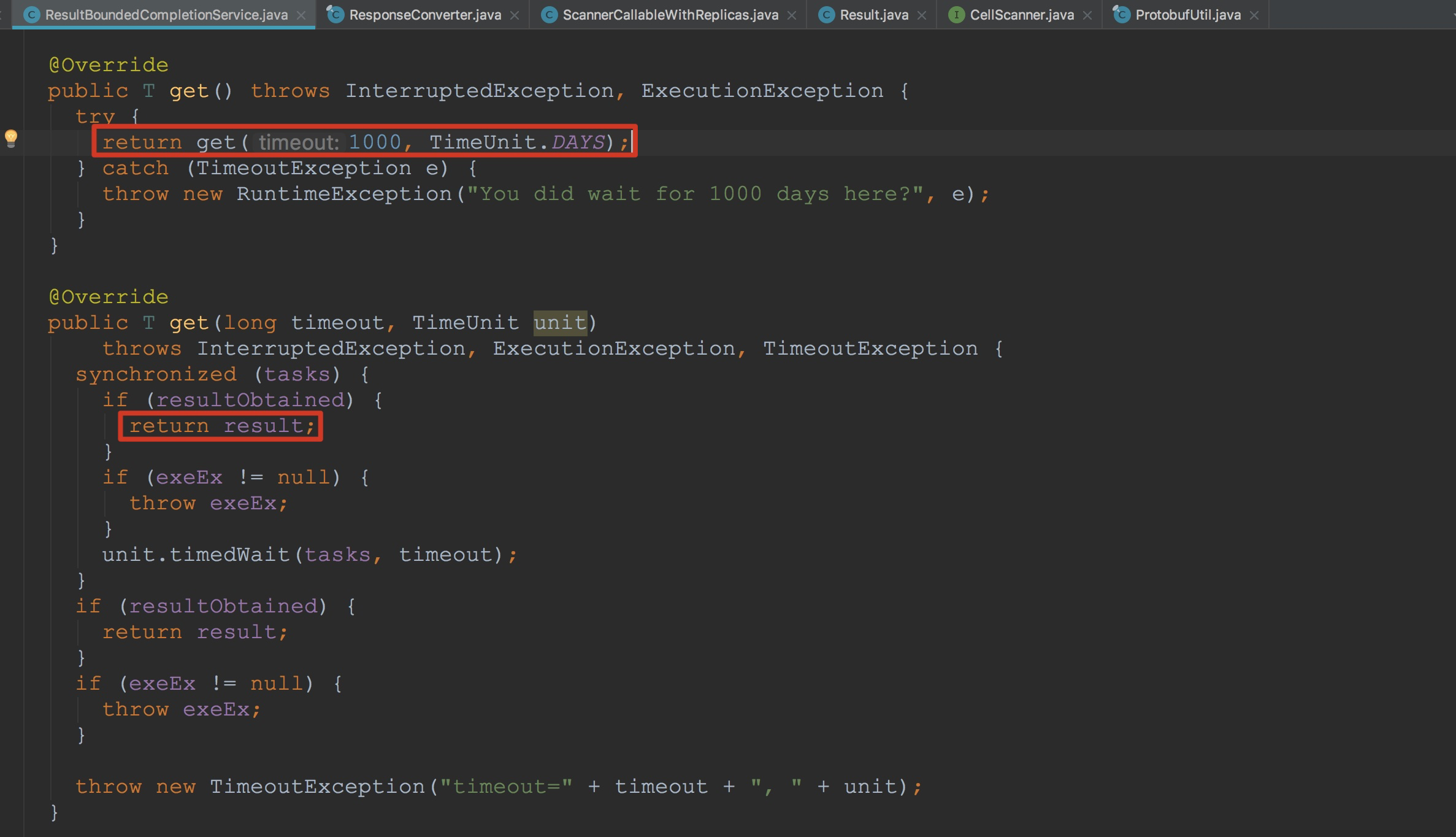
HBase之Table.put客户端流程的更多相关文章
- HBase之Table.put客户端流程(续)
上篇博文中已经谈到,有两个流程没有讲到.一个是MetaTableAccessor.getRegionLocations,另外一个是ConnectionImplementation.cacheLocat ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- paip.提升效率--数据绑定到table原理和流程Angular js jquery实现
paip.提升效率--数据绑定到table原理和流程Angular js jquery实现 html #--keyword 1 #---原理和流程 1 #----jq实现的代码 1 #-----An ...
- hbase删除table时,显示table不存在
hbase删除table时,显示table不存在,但是创建table时,显示table存在. 解决方案: 清空zookeeper数据.(重新安装zookeeper)
- Netty 源码学习——客户端流程分析
Netty 源码学习--客户端流程分析 友情提醒: 需要观看者具备一些 NIO 的知识,否则看起来有的地方可能会不明白. 使用版本依赖 <dependency> <groupId&g ...
- HBase介绍(3)---框架结构及流程
HBASE依托于Hadoop的HDFS作为存储基础,因此结构也很类似于Hadoop的Master-Slave模式,Hbase Master Server 负责管理所有的HRegion Server,但 ...
- 一条数据的HBase之旅,简明HBase入门教程-Write全流程
如果将上篇内容理解为一个冗长的"铺垫",那么,从本文开始,剧情才开始正式展开.本文基于提供的样例数据,介绍了写数据的接口,RowKey定义,数据在客户端的组装,数据路由,打包分发, ...
- Hbase 基础 - shell 与 客户端
版权说明: 本文章版权归本人及博客园共同所有,转载请标明原文出处(http://www.cnblogs.com/mikevictor07/),以下内容为个人理解,仅供参考. 一.简介 Hbase是在 ...
- HBase读写数据的详细流程及ROOT表/META表介绍
一.HBase读数据流程 1.Client访问Zookeeper,从ZK获取-ROOT-表的位置信息,通过访问-ROOT-表获取.META.表的位置,然后确定数据所在的HRegion位置: 2.Cli ...
随机推荐
- Java类的继承与方法调用的一个小问题
public class Father { protected void server(int i){ switch (i){ case 1: methodone(); break; case 2: ...
- Motrix for Mac(百度网盘加速/全能下载软件) v1.3.7最新版!
Motrix for Mac最新版第一时间在本站上线!Mac上最强大实用百度网盘加速器Motrix for Mac分享给您!Motrix for Mac是一款非常优秀的下载工具,采用Aria 2作为核 ...
- pygame学习之绘制圆
import pygame from pygame.locals import * pygame.init() screen = pygame.display.set_mode((600, 500)) ...
- MyBatis sqlsession 简化 使用工具类创建
2019-04-09 @Test public void Test() throws Exception { // 1.读取配置文件 String resource = "mybatis-c ...
- Picnic Planning POJ - 1639(最小k度生成树)
The Contortion Brothers are a famous set of circus clowns, known worldwide for their incredible abil ...
- Web 性能优化:21 种优化 CSS 和加快网站速度的方法
这是 Web 性能优化的第 4 篇,上一篇在下面看点击查看: Web 性能优化:使用 Webpack 分离数据的正确方法 Web 性能优化:图片优化让网站大小减少 62% Web 性能优化:缓存 Re ...
- Java链表基本操作和Java.util.ArrayList
Java链表基本操作和Java.util.ArrayList 今天做了一道<剑指offer>上的一道编程题“从尾到头打印链表”,具体要求如下:输入一个链表,按链表值从尾到头的顺序返回一个A ...
- [POJ3630]Phone List (Tire)
题意 trie字典树模板 LOJ有中文翻译https://loj.ac/problem/10049 思路 TIRE 代码 之前在LOJ上做过 直接交了 #include<cstdio> # ...
- css实现文本超出两行隐藏
当文字显示超出两行时,多余部分文字隐藏,用到的css属性如下代码 display: -webkit-box; text-overflow: ellipsis; overflow: hidden; -w ...
- vue 使用瞬间
vue 使用瞬间 一, 图片类 <img :src="data.deptLogo | imgUrl" onerror="this.src='../img/headD ...