Flink 核心技术浅析(整理版)
1. Flink简介
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink流执行引擎(streaming dataflow engine),提供支持流处理和批处理两种类型应用的功能。batch dataSet可以视作data Streaming的一种特例。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:
- DataSet API,对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
- DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
- Table API,对结构化数据进行查询操作,对结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
- Flink ML,Flink的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。
- Gelly,Flink的图计算库,提供了图计算的相关API以及多种图计算算法。
Flink的技术栈如图所示:
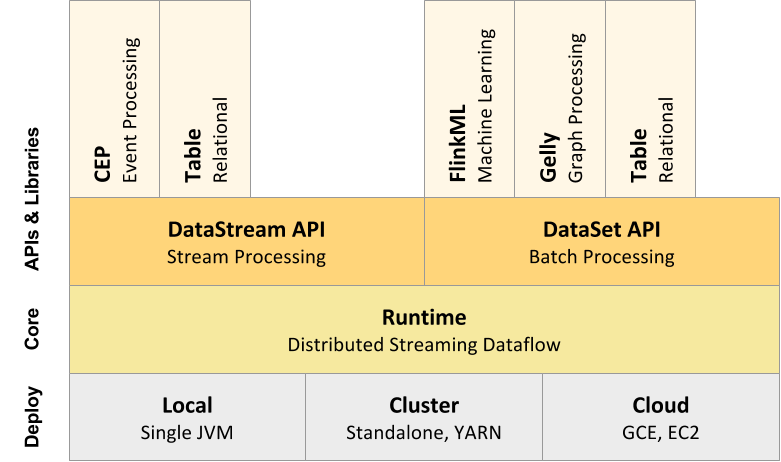
此外,Flink也可以方便和Hadoop生态圈中其他项目集成,例如Flink可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式的数据源,直接重用MapReduce或Store代码,或是通过YARN申请集群资源等。
2. Flink核心特点
2.1 统一的批处理和流处理系统
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式。对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。而对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。这两种数据传输模式是两个极端,对应的是流处理对低延迟的要求和批处理系统对高吞吐量的要求。
Flink的执行引擎采用了一种十分灵活的方式,同时支持了上述两种数据传输模型。Flink以固定的缓存块为单位进行网络数据传输,用户可以通过缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟。如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文所提到批处理系统标准模型,此时系统可以获得最高的吞吐量。同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阀值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阀值,用户可根据需求灵活地权衡系统延迟和吞吐量。
在统一的流式执行引擎基础上,Flink同时支持了流计算和批处理,并对性能(延迟、吞吐量等)有所保障。相对于其他原生的流处理与批处理系统,并没有因为统一执行引擎而受到影响,从而大幅度减轻了用户安装、部署、监控、维护等成本。
2.2 Flink流处理的容错机制
对于一个分布式系统来说,单个进程或是节点崩溃导致整个Job失败是经常发生的事情,在异常发生时不会丢失用户数据并能自动恢复才是分布式系统必须支持的特性之一。本节主要介绍Flink流处理系统任务级别的容错机制。
批处理系统比较容易实现容错机制,由于文件可以重复访问,当个某个任务失败后,重启该任务即可。但是到了流处理系统,由于数据源是无限的数据流,从而导致一个流处理任务执行几个月的情况,将所有数据缓存或是持久化,留待以后重复访问基本上是不可行的。Flink基于分布式快照与可部分重发的数据源实现了容错。用户可自定义对整个Job进行快照的时间间隔,当任务失败时,Flink会将整个Job恢复到最近一次快照,并从数据源重发快照之后的数据。
Flink的分布式快照实现借鉴了Chandy和Lamport在1985年发表的一篇关于分布式快照的论文,其实现的主要思想如下:按照用户自定义的分布式快照间隔时间,Flink会定时在所有数据源中插入一种特殊的快照标记消息,这些快照标记消息和其他消息一样在DAG中流动,但是不会被用户定义的业务逻辑所处理,每一个快照标记消息都将其所在的数据流分成两部分:本次快照数据和下次快照数据。
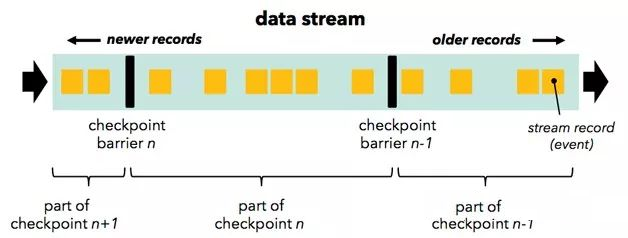
图3中Flink包含快照标记消息的消息流
快照标记消息沿着DAG流经各个操作符,当操作符处理到快照标记消息时,会对自己的状态进行快照,并存储起来。当一个操作符有多个输入的时候,Flink会将先抵达的快照标记消息及其之后的消息缓存起来,当所有的输入中对应该快照的快照标记消息全部抵达后,操作符对自己的状态快照并存储,之后处理所有快照标记消息之后的已缓存消息。操作符对自己的状态快照并存储可以是异步与增量的操作,并不需要阻塞消息的处理。分布式快照的流程如图4所示:
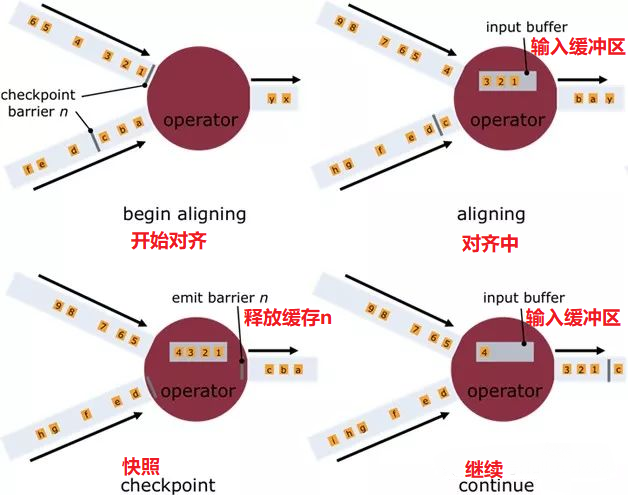
图4 Flink分布式快照流程图
当所有的Data Sink(终点操作符)都收到快照标记信息并对自己的状态快照和存储后,整个分布式快照就完成了,同时通知数据源释放该快照标记消息之前的所有消息。若之后发生节点崩溃等异常情况时,只需要恢复之前存储的分布式快照状态,并从数据源重发该快照以后的消息就可以了。
Exactly-Once是流处理系统需要支持的一个非常重要的特性,它保证每一条消息只被流处理系统一次,许多流处理任务的业务逻辑都依赖于Exactly-Once特性。相对于At-Least-Once或是At-Most-Once,Exactly-Once特性对流处理系统的要求更为严格,实现也更加困难。Flink基于分布式快照实现了Exactly-Once特性。
相对于其他流处理系统的容错方案,Flink基于分布式快照的方案在功能和性能方面都具有很多优点,包括:
- 低延迟。由于操作符状态的存储可以异步,所以进行快照的过程基本上不会阻塞消息的处理,因此不会对消息延迟产生负面影响。
- 高吞吐量。当操作符状态较少时,对吞吐量基本没有影响。当操作符状态较多时,相对于其他的容错机制,分布式快照的时间间隔是用户自定义的,所以用户可以权衡错误恢复时间和吞吐量要求来调整分布式快照的时间间隔。
与业务逻辑的隔离。Flink的分布式快照机制与用户的业务逻辑是完全隔离的,用户的业务逻辑不会依赖或是对分布式快照产生任何影响。
错误恢复代价。分布式快照的时间间隔越短,错误恢复的时间越少,与吞吐量负相关。
2.3 Flink流处理的时间窗口
对于流处理系统来说,流入的消息不存在上限,所以对于聚合或是连接等操作,流处理系统需要对流入的消息进行分段,然后基于每一段数据进行聚合或是连接。消息的分段即称为窗口,流处理系统支持的窗口有很多类型,最常见的就是时间窗口,基于时间间隔对消息进行分段处理。本节主要介绍Flink流处理系统支持的各种时间窗口。
对于目前大部分流处理系统来说,时间窗口一般是根据Task所在节点的本地时钟进行切分,这种方式实现起来比较容易,不会产生阻塞。但是可能无法满足某些应用需求,比如:①消息本身带有时间戳,用户希望按照消息本身的时间特性进行分段处理;②由于不同节点的时钟可能不同,以及消息在流经各个节点的延迟不同,在某个节点属于同一个时间窗口处理的消息,流到下一个节点时可能被切分到不同的时间窗口中,从而产生不符合预期的结果。
Flink支持3种类型的时间窗口,分别适用于用户对时间窗口不同类型的要求:
- Operator Time。根据Task所在节点的本地时钟来切分的时间窗口。
- Event Time。消息自带时间戳,根据消息的时间戳进行处理,确保时间戳在同一个时间窗口的所有消息一定会被正确处理。由于消息可能乱序流入Task,所以Task需要缓存当前时间窗口消息处理的状态,直到确认属于该时间窗口的所有消息都被处理,才可以释放,如果乱序的消息延迟很高会影响分布式系统的吞吐量和延迟。
- Ingress Time。有时消息本身并不带时间戳信息,但用户依然希望按照消息而不是节点时钟划分时间窗口,例如避免上面提到的第二个问题,此时可以在消息源流入Flink流处理系统时自动生成增量的时间戳赋予消息,之后处理的流程与Event Time相同。Ingress Time可以看成是Event Time的一个特例,由于其在消息源处时间戳一定是有序的,所以在流处理系统中,相对于Event Time,其乱序的消息延迟不会很高,因此对Flink分布式系统的吞吐量和延迟的影响也会更小。
2.4 定制的内存管理
Flink项目基于Java及Scala等JVM语言,JVM本身作为一个各种类型应用的执行平台,其对Java对象的管理也是基于通用的处理策略,其垃圾回收器通过估算Java对象的生命周期对Java对象进行有效率的管理。
JVM存在的问题
Java对象开销
相对于C/C++等更加接近底层的语言,Java对象的存储密度相对偏低,例如[1],"abcd"这样简单的字符串在UTF-8编码中需要4个字节存储,但采用了UTF-16编码存储字符串的Java需要8个字节,同时Java对象还有header等其他额外信息,一个4字节字符串对象在Java中需要48字节的空间来存储。对于大部分的大数据应用,内存都是稀缺资源,更有效率的内存存储,意味着CPU数据访问吐吞量更高,以及更少磁盘落地的存在。
对象存储结构引发的cache miss
为了缓解CPU处理速度与内存访问速度的差距,现代CPU数据访问一般都会有多级缓存。当从内存加载数据到缓存时,一般是以cache line为单位加载数据,所以当CPU访问的数据如果是在内存中连续存储的话,访问的效率会非常高。如果CPU要访问的数据不在当前缓存所有的cache line中,则需要从内存中加载对应的数据,这被称为一次cache miss。当cache miss非常高的时候,CPU大部分的时间都在等待数据加载,而不是真正的处理数据。Java对象并不是连续的存储在内存上,同时很多的Java数据结构的数据聚集性也不好。
大数据的垃圾回收
Java的垃圾回收机制一直让Java开发者又爱又恨,一方面它免去了开发者自己回收资源的步骤,提高了开发效率,减少了内存泄漏的可能,另一方面垃圾回收也是Java应用的不定时炸弹,有时秒级甚至是分钟级的垃圾回收极大影响了Java应用的性能和可用性。在时下数据中心,大容量内存得到了广泛的应用,甚至出现了单台机器配置TB内存的情况,同时,大数据分析通常会遍历整个源数据集,对数据进行转换、清洗、处理等步骤。在这个过程中,会产生海量的Java对象,JVM的垃圾回收执行效率对性能有很大影响。通过JVM参数调优提高垃圾回收效率需要用户对应用和分布式计算框架以及JVM的各参数有深入了解,而且有时候这也远远不够。
OOM问题
OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会出现OutOfMemoryError错误,JVM崩溃,分布式框架的健壮性和性能都会受到影响。通过JVM管理内存,同时试图解决OOM问题的应用,通常都需要检查Java对象的大小,并在某些存储Java对象特别多的数据结构中设置阈值进行控制。但是JVM并没有提供官方检查Java对象大小的工具,第三方的工具类库可能无法准确通用地确定Java对象大小[6]。侵入式的阈值检查也会为分布式计算框架的实现增加很多额外与业务逻辑无关的代码。
Flink的处理策略
为了解决以上提到的问题,高性能分布式计算框架通常需要以下技术:
定制的序列化工具
显式内存管理的前提步骤就是序列化,将Java对象序列化成二进制数据存储在内存上(on heap或是off-heap)。通用的序列化框架,如Java默认使用java.io.Serializable将Java对象及其成员变量的所有元信息作为其序列化数据的一部分,序列化后的数据包含了所有反序列化所需的信息。这在某些场景中十分必要,但是对于Flink这样的分布式计算框架来说,这些元数据信息可能是冗余数据。
分布式计算框架可以使用定制序列化工具的前提是要待处理数据流通常是同一类型,由于数据集对象的类型固定,从而可以只保存一份对象Schema信息,节省大量的存储空间。同时,对于固定大小的类型,也可通过固定的偏移位置存取。在需要访问某个对象成员变量时,通过定制的序列化工具,并不需要反序列化整个Java对象,而是直接通过偏移量,从而只需要反序列化特定的对象成员变量。如果对象的成员变量较多时,能够大大减少Java对象的创建开销,以及内存数据的拷贝大小。Flink数据集都支持任意Java或是Scala类型,通过自动生成定制序列化工具,既保证了API接口对用户友好(不用像Hadoop那样数据类型需要继承实现org.apache.hadoop.io.Writable接口),也达到了和Hadoop类似的序列化效率。
Flink对数据集的类型信息进行分析,然后自动生成定制的序列化工具类。Flink支持任意的Java或是Scala类型,通过Java Reflection框架分析基于Java的Flink程序UDF(User Define Function)的返回类型的类型信息,通过Scala Compiler分析基于Scala的Flink程序UDF的返回类型的类型信息。类型信息由TypeInformation类表示,这个类有诸多具体实现类,例如:
- BasicTypeInfo任意Java基本类型(装包或未装包)和String类型。
- BasicArrayTypeInfo任意Java基本类型数组(装包或未装包)和String数组。
- WritableTypeInfo任意Hadoop的Writable接口的实现类。
- TupleTypeInfo任意的Flink tuple类型(支持Tuple1 to Tuple25)。 Flink tuples是固定长度固定类型的Java Tuple实现。
- CaseClassTypeInfo任意的 Scala CaseClass(包括 Scala tuples)。
- PojoTypeInfo任意的POJO (Java or Scala),例如Java对象的所有成员变量,要么是public修饰符定义,要么有getter/setter方法。
- GenericTypeInfo任意无法匹配之前几种类型的类。
前6种类型数据集几乎覆盖了绝大部分的Flink程序,针对前6种类型数据集,Flink皆可以自动生成对应的TypeSerializer定制序列化工具,非常有效率地对数据集进行序列化和反序列化。对于第7种类型,Flink使用Kryo进行序列化和反序列化。此外,对于可被用作Key的类型,Flink还同时自动生成TypeComparator,用来辅助直接对序列化后的二进制数据直接进行compare、hash等操作。对于Tuple、CaseClass、Pojo等组合类型,Flink自动生成的TypeSerializer、TypeComparator同样是组合的,并把其成员的序列化/反序列化代理给其成员对应的TypeSerializer、TypeComparator,如图6所示:

图6组合类型序列化
此外如有需要,用户可通过集成TypeInformation接口定制实现自己的序列化工具。
显式的内存管理
一般通用的做法是批量申请和释放内存,每个JVM实例有一个统一的内存管理器,所有内存的申请和释放都通过该内存管理器进行。这可以避免常见的内存碎片问题,同时由于数据以二进制的方式存储,可以大大减轻垃圾回收压力。
垃圾回收是JVM内存管理回避不了的问题,JDK8的G1算法改善了JVM垃圾回收的效率和可用范围,但对于大数据处理实际环境还远远不够。这也和现在分布式框架的发展趋势有所冲突,越来越多的分布式计算框架希望尽可能多地将待处理数据集放入内存,而对于JVM垃圾回收来说,内存中Java对象越少、存活时间越短,其效率越高。通过JVM进行内存管理的话,OutOfMemoryError也是一个很难解决的问题。同时,在JVM内存管理中,Java对象有潜在的碎片化存储问题(Java对象所有信息可能在内存中连续存储),也有可能在所有Java对象大小没有超过JVM分配内存时,出现OutOfMemoryError问题。Flink将内存分为3个部分,每个部分都有不同用途:
- Network buffers: 一些以32KB Byte数组为单位的buffer,主要被网络模块用于数据的网络传输。
- Memory Manager pool大量以32KB Byte数组为单位的内存池,所有的运行时算法(例如Sort/Shuffle/Join)都从这个内存池申请内存,并将序列化后的数据存储其中,结束后释放回内存池。
- Remaining (Free) Heap主要留给UDF中用户自己创建的Java对象,由JVM管理。
Network buffers在Flink中主要基于Netty的网络传输,无需多讲。Remaining Heap用于UDF中用户自己创建的Java对象,在UDF中,用户通常是流式的处理数据,并不需要很多内存,同时Flink也不鼓励用户在UDF中缓存很多数据,因为这会引起前面提到的诸多问题。Memory Manager pool(以后以内存池代指)通常会配置为最大的一块内存,接下来会详细介绍。
在Flink中,内存池由多个MemorySegment组成,每个MemorySegment代表一块连续的内存,底层存储是byte[],默认32KB大小。MemorySegment提供了根据偏移量访问数据的各种方法,如get/put int、long、float、double等,MemorySegment之间数据拷贝等方法和java.nio.ByteBuffer类似。对于Flink的数据结构,通常包括多个向内存池申请的MemeorySegment,所有要存入的对象通过TypeSerializer序列化之后,将二进制数据存储在MemorySegment中,在取出时通过TypeSerializer反序列化。数据结构通过MemorySegment提供的set/get方法访问具体的二进制数据。Flink这种看起来比较复杂的内存管理方式带来的好处主要有:
- 二进制的数据存储大大提高了数据存储密度,节省了存储空间。
- 所有的运行时数据结构和算法只能通过内存池申请内存,保证了其使用的内存大小是固定的,不会因为运行时数据结构和算法而发生OOM。对于大部分的分布式计算框架来说,这部分由于要缓存大量数据最有可能导致OOM。
- 内存池虽然占据了大部分内存,但其中的MemorySegment容量较大(默认32KB),所以内存池中的Java对象其实很少,而且一直被内存池引用,所有在垃圾回收时很快进入持久代,大大减轻了JVM垃圾回收的压力。
- Remaining Heap的内存虽然由JVM管理,但是由于其主要用来存储用户处理的流式数据,生命周期非常短,速度很快的Minor GC就会全部回收掉,一般不会触发Full GC。
Flink当前的内存管理在最底层是基于byte[],所以数据最终还是on-heap,最近Flink增加了off-heap的内存管理支持。Flink off-heap的内存管理相对于on-heap的优点主要在于:
- 启动分配了大内存(例如100G)的JVM很耗费时间,垃圾回收也很慢。如果采用off-heap,剩下的Network buffer和Remaining heap都会很小,垃圾回收也不用考虑MemorySegment中的Java对象了。
- 更有效率的IO操作。在off-heap下,将MemorySegment写到磁盘或是网络可以支持zeor-copy技术,而on-heap的话则至少需要一次内存拷贝。
- off-heap可用于错误恢复,比如JVM崩溃,在on-heap时数据也随之丢失,但在off-heap下,off-heap的数据可能还在。此外,off-heap上的数据还可以和其他程序共享。
缓存友好的计算
对于计算密集的数据结构和算法,直接操作序列化后的二进制数据,而不是将对象反序列化后再进行操作。同时,只将操作相关的数据连续存储,可以最大化的利用L1/L2/L3缓存,减少Cache miss的概率,提升CPU计算的吞吐量。以排序为例,由于排序的主要操作是对Key进行对比,如果将所有排序数据的Key与Value分开并对Key连续存储,那么访问Key时的Cache命中率会大大提高。
磁盘IO和网络IO之前一直被认为是Hadoop系统的瓶颈,但是随着Spark、Flink等新一代分布式计算框架的发展,越来越多的趋势使得CPU/Memory逐渐成为瓶颈,这些趋势包括:
- 更先进的IO硬件逐渐普及。10GB网络和SSD硬盘等已经被越来越多的数据中心使用。
- 更高效的存储格式。Parquet,ORC等列式存储被越来越多的Hadoop项目支持,其非常高效的压缩性能大大减少了落地存储的数据量。
- 更高效的执行计划。例如很多SQL系统执行计划优化器的Fliter-Push-Down优化会将过滤条件尽可能的提前,甚至提前到Parquet的数据访问层,使得在很多实际的工作负载中并不需要很多的磁盘IO。
3. Flink vs Spark
通过比较spark,了解flink的作用和优缺点,主要从设计抽象、内存管理、语言实现,以及API和SQL等方面来描述。
3.1 设计抽象
接触过 Spark 的同学,应该比较熟悉,在处理批处理任务,可以使用 RDD,而对于流处理,可以使用 Streaming,然其实际还是 RDD,所以本质上还是 RDD 抽象而来。但是,在 Flink 中,批处理用 DataSet,对于流处理,有 DataStreams。思想类似,但却有所不同:其一,DataSet 在运行时表现为 Runtime Plans,而在 Spark 中,RDD 在运行时表现为 Java Objects。在 Flink 中有 Logical Plan ,这和 Spark 中的 DataFrames 类似。因而,在 Flink 中,若是使用这类 API ,会被优先来优化(即:自动优化迭代)。然而,在 Spark 中,RDD 就没有这块的相关优化。
另外,DataSet 和 DataStream 是相对独立的 API,在 Spark 中,所有不同的 API,比如 Streaming,DataFrame 都是基于 RDD 抽象的。然而在 Flink 中,DataSet 和 DataStream 是同一个公用引擎之上的两个独立的抽象。所以,不能把这两者的行为合并在一起操作,目前官方正在处理这种问题。
3.2 内存
在之前的版本(1.5以前),Spark 延用 Java 的内存管理来做数据缓存,这样很容易导致 OOM 或者 GC。之后,Spark 开始转向另外更加友好和精准的控制内存,即:Tungsten 项目。然而,对于 Flink 来说,从一开始就坚持使用自己控制内存。Flink 除把数据存在自己管理的内存之外,还直接操作二进制数据。在 Spark 1.5之后的版本开始,所有的 DataFrame 操作都是直接作用于 Tungsten 的二进制数据上。
PS:Tungsten 项目将是 Spark 自诞生以来内核级别的最大改动,以大幅度提升 Spark 应用程序的内存和 CPU 利用率为目标,旨在最大程度上利用硬件性能。该项目包括了三个方面的改进:
- 内存管理和二进制处理:更加明确的管理内存,消除 JVM 对象模型和垃圾回收开销。
- 缓存友好计算:使用算法和数据结构来实现内存分级结构。
- 代码生成:使用代码生成来利用新型编译器和 CPU。
3.2 编程语言
Spark 使用 Scala 来实现的,它提供了 Java,Python 以及 R 语言的编程接口。而对于 Flink 来说,它是使用 Java 实现的,提供 Scala 编程 API。从编程语言的角度来看,Spark 略显丰富一些。Spark 和 Flink 两者都倾向于使用 Scala 来实现对应的业务。
3.2 SQL
目前,Spark SQL 是其组件中较为活跃的一部分,它提供了类似于 Hive SQL 来查询结构化数据,API 依然很成熟。对于 Flink 来说,支持 Flink Table API。
总结
参考资料:
https://www.cnblogs.com/smartloli/p/5580757.html
https://www.cnblogs.com/feiyudemeng/p/8998772.html
https://yq.aliyun.com/articles/600173
Flink 核心技术浅析(整理版)的更多相关文章
- 【转帖】Flink 核心技术浅析(整理版)
Flink 核心技术浅析(整理版) https://www.cnblogs.com/swordfall/p/10612404.html 分类: Flink undefined 1. Flink简介 A ...
- 一个项目涉及到的50个Sql语句(整理版)
/* 标题:一个项目涉及到的50个Sql语句(整理版) 说明:以下五十个语句都按照测试数据进行过测试,最好每次只单独运行一个语句. */ --1.学生表Student(S,Sname,Sage,Sse ...
- 深入理解Apache Flink核心技术
深入理解Apache Flink核心技术 2016年02月18日 17:04:03 阅读数:1936 标签: Apache-Flink数据流程序员JVM 版权声明:本文为博主原创文章,未经博主允许 ...
- 任正非讲话稿 PDF整理版
任正非讲话稿 PDF整理版 任正非思想之路 这里收录了任正非讲话稿400余篇,从1994年到2018年,从深圳.中国到东南亚.非洲.欧洲.美洲,从研发.市场.服务到财经.人力资源.战略.内控与公共关系 ...
- 深入理解Flink核心技术及原理
前言 Apache Flink(下简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的关注.本文将深入分析Flink的一些关键技术与特性,希望 ...
- 菜农群课笔记之ICP与ISP----20110412(整理版)
耗时一上午时间对HOT大叔昨晚的群课内容进行温故并整理,现将其上传,若想看直播可到下面链接处下载:http://bbs.21ic.com/icview-229746-1-1.html 成 ...
- Java并发编程面试题 Top 50 整理版
本文在 Java线程面试题 Top 50的基础上,对部分答案进行进行了整理和补充,问题答案主要来自<Java编程思想(第四版)>,<Java并发编程实战>和一些优秀的博客,当然 ...
- Java虚拟机—垃圾收集器(整理版)
1.概述 如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现.Java虚拟机规范中对垃圾收集器应该如何实现并没有规定,因此不同的厂商.不同版本的虚拟机所提供的垃圾收集器都可能会有很 ...
- Java虚拟机—垃圾回收算法(整理版)
1.概述 由于垃圾收集算法的实现涉及大量的程序细节.因此本节不打算过多地讨论算法的实现,只是介绍几种算法的思想及其发展过程.主要涉及的算法有标记-清除算法.复制算法.标记-整理算法.分代收集算法. 2 ...
随机推荐
- 彻底卸载注册表、流氓软件的工具Uninstall Tool
Your Uninstaller 和Uninstall Tool都可以卸载Windows系统卸载不干净的软件和注册表驱动等 Uninstall Tool下载
- mssql server for docker on MacOs
1. install 1.下载镜像 docker pull microsoft/mssql-server-linux 使用该命令就可以把数据库的docker镜像下载下来. 2.创建并运行容器 dock ...
- mysql export mysqldump version mismatch upgrade or downgrade your local MySQL client programs
I use MySQL Community Edition and I solved this problem today. goto https://dev.mysql.com/downloads/ ...
- 360 随身 WiFi3 在 Ubuntu 14.04 下的使用
由于 360 随身 WiFi3 采用 Mediaek 代号 0e8d:760c 的芯片,目前没有官方或第三方 Linux 驱动,所以造成 Linux 用户的诸多困扰. 本文给出一个迂回的解决方案:在 ...
- VUE 安装及项目创建
Vue.js 安装cnpm npm install -g 镜像 cnpm --registry=https://registry.npm.taobao.org 安装 vue.js cnpm insta ...
- 随心测试_数据库_001<论数据的重要性>
测试工作中,数据的重要性 软测工程师:作为综合运用多学科知识,保障软件质量的重要岗位.需要我们学以致用,在工作中不断学习提升.以下:软测人员必备_数据库核心技能学习点,供大家学习参考. Q1:什么是: ...
- Neutron vxlan network
OpenStack 还支持 vxlan 和 gre 这两种 overlay network. overlay network 是指建立在其他网络上的网络. 该网络中的节点可以看作通过虚拟(或逻辑) ...
- jdbc连接字符串
MySQL:String Driver="com.mysql.jdbc.Driver"; //驱动程序String URL="jdbc:mysql://localhost ...
- Selenium WebDriver原理(一):Selenium WebDriver 是怎么工作的?
首先我们来看一个经典的例子: 搭出租车 在出租车驾驶中,通常有3个角色: 乘客 : 他告诉出租车司机他想去哪里以及如何到达那里 对出租车司机说: 1.去阳光棕榈园东门 2.从这里转左 3.然后直行 2 ...
- win 解压安装mysql步骤
5 安装成功之后,启动mysql时报错: 系统错误2,找不到指定的文件.原因:有的系统安装过MySQL没有卸载干净,或者系统自带精简版的MySQL导致注册表关于MySQL的配置与实际安装路径不一致. ...