python摸爬滚打之day33----线程
1、线程
能够独立运行的基本单位.
进程: 进程是资源分配的最小单位; 每一个进程中至少有一个线程.
线程: 线程是cpu调度的最小单位.
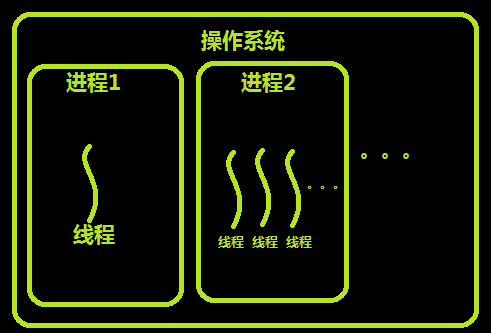
2、创建线程(类似于创建进程)
import time
from threading import Thread def func1(m):
time.sleep(1)
print(">>>>>>")
print(m) t = Thread(target=func1, args=(25,))
t.start()
print("主线程结束")
创建线程1
import time
from threading import Thread class MyThread(Thread):
def __init__(self,numb):
super(MyThread, self).__init__()
self.numb = numb def run(self):
print("")
print(self.numb) if __name__ == '__main__': t = MyThread(500)
t.start()
print("主线程结束")
创建线程方式2
3、join()
import time
from threading import Thread def func1(m):
print(m)
time.sleep(5)
print("子线程啦啦啦") t = Thread(target=func1, args=(25,))
t.start()
t.join() # 等子线程结束后再执行主线程 print("主线程啦啦啦啦啦啦")
join()
4、线程提供的几个方法
current_thread().getName() # 获取当前线程的名字
current_thread().is_alive() # 判断该线程是否还存活
current_thread().isAlive() # 判断该线程是否还存活 threading.enumerate() # 当前存活的线程列表
threading.activeCount() # 当前存活的所有线程数量
threading.active_count() # 当前存活着的线程的所有数量
import time,threading
from threading import Thread,current_thread def func1():
time.sleep(1)
print(current_thread().is_alive()) # 判断该线程是否还存活
print(current_thread().isAlive())
print(f"子线程名字:{current_thread().getName()}") if __name__ == '__main__': for i in range(10):
t = Thread(target=func1,name=f"子线程{i}号")
t.start()
print(threading.enumerate()) # 当前存活的线程列表
print(threading.activeCount()) # 当前存活的所有线程数量
print(f"主线程名字:{current_thread().getName()}" ) # 当前主线程的名字
time.sleep(3)
print(threading.active_count()) # 当前存活的线程的所有数量
5、进程和线程的效率对比
线程省去了系统给进程分配资源, 销毁进程等时间, 效率上明显提高.
import time
from multiprocessing import Process
from threading import Thread def func():
print("XXXXXXXXXX") if __name__ == '__main__': t_lst = []
t_s_tm = time.time()
for i in range(100):
t = Thread(target=func,)
t_lst.append(t)
t.start()
[tt.join() for tt in t_lst]
t_e_tm = time.time()
t_dis_tm = t_e_tm - t_s_tm
print(f"多线程时间: {t_dis_tm}") # 多线程时间: 0.01200723648071289 p_lst = []
p_s_tm = time.time()
for i in range(100):
p = Process(target=func, )
p_lst.append(p)
p.start()
[pp.join() for pp in p_lst]
p_e_tm = time.time()
p_dis_tm = p_e_tm - p_s_tm
print(f"多进程时间: {p_dis_tm}") # 多进程时间: 1.9823119640350342
进程线程效率对比
6、线程间数据安全
线程间的数据是共享的, 当大量线程去访问数据时也会造成数据混乱不安全的现象.
import time
from threading import Thread numb = 100
def func(): global numb
mid = numb
time.sleep(0.000001)
numb = mid - 1 if __name__ == '__main__': t_lst = []
for i in range(100):
t = Thread(target=func,)
t_lst.append(t)
t.start()
[tt.join() for tt in t_lst]
print(f"拿到的numb为: {numb}") # 93 或者其他
线程共享数据造成数据混乱
7、同步锁(类似进程)
import time
from threading import Thread,Lock numb = 100
def func(lok): global numb
lok.acquire()
mid = numb
time.sleep(0.000001)
numb = mid - 1
lok.release() if __name__ == '__main__': lok = Lock()
t_lst = []
for i in range(100):
t = Thread(target=func,args=(lok,))
t_lst.append(t)
t.start()
[tt.join() for tt in t_lst]
print(f"拿到的numb为: {numb}") #
同步锁
8、死锁
import time
from threading import Thread,RLock,Lock def func1(lock_a, lock_b):
lock_a.acquire()
time.sleep(0.5)
print("线程1拿到了A锁")
lock_b.acquire()
print("线程1拿到了B锁")
lock_b.release()
lock_a.release() def func2(lock_a, lock_b):
lock_b.acquire()
print("线程2拿到了B锁")
lock_a.acquire()
print("线程2拿到了A锁")
lock_a.release()
lock_b.release() if __name__ == '__main__': lock_a = Lock()
lock_b = Lock()
t1 = Thread(target=func1,args=(lock_a, lock_b))
t2 = Thread(target=func2,args=(lock_a, lock_b))
t1.start()
t2.start() # 结果
# func2拿到了B锁
# func1拿到了A锁
# 阻塞...... (因为线程2拿到B锁的同时, 线程1也拿到了A锁, 然后线程2要拿A锁, 但是线程1没有释放A锁,
# 同理线程2没有释放B锁, 两个线程就互相等, 一直阻塞着......)
死锁
9、递归锁
解决死锁的方法: ----> 递归锁
递归锁内部维持着一个计数器, 当计数器 == 0 时, 各线程开始抢夺递归锁, 当线程每抢着一个锁, 递归锁内部的计数器就 +1, 释放一个就 -1.
import time
from threading import Thread,RLock,Lock def func1(lock_a, lock_b):
lock_a.acquire()
time.sleep(0.5)
print("线程1拿到了A锁")
lock_b.acquire()
print("线程1拿到了B锁")
lock_b.release()
lock_a.release() def func2(lock_a, lock_b):
lock_b.acquire()
print("线程2拿到了B锁")
lock_a.acquire()
print("线程2拿到了A锁")
lock_a.release()
lock_b.release() if __name__ == '__main__': lock_a = lock_b = Lock()
t1 = Thread(target=func1,args=(lock_a, lock_b))
t2 = Thread(target=func2,args=(lock_a, lock_b))
t1.start()
t2.start() """
注意: lock_a, lock_b = RLock() 表示lock_a, lock_b使用的是同一把递归锁
lock_a = RLock(), loca_b = Rlock() 表示lock_a使用一把递归锁,lock_b使用另一把递归锁,两个递归锁不一样, 相当于死锁
lock_a, lock_b = Lock() 表示lock_a, lock_b 使用同一把普通锁, 锁本身还没有释放, 肯定获取不到的 """
递归锁
10、守护线程
守护线程随主线程的结束而结束. 主线程要等所有非守护线程代码统统运行完毕后, 主线程才运行完毕.
什么叫运行完毕? (结束和运行完毕是两码事)
进程: 对于进程来说, 运行完毕指的是主进程代码运行完毕;
线程: 对于线程来说, 运行完毕指得是主线程等待该进程内所有非守护线程代码统统运行完毕后, 主线程才运行完毕.
守护进程: 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束.
守护线程: 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
import time
from threading import Thread def func1():
time.sleep(3)
print("子线程1结束了") def func2():
time.sleep(2)
print("子线程2结束了") if __name__ == '__main__':
t1 = Thread(target=func1,)
t2 = Thread(target=func2,) t1.daemon = True
t2.daemon = True t1.start()
t2.start() print("主线程代码结束了")
守护线程
import time
from multiprocessing import Process def func1():
time.sleep(3)
print("子进程1结束了") def func2():
time.sleep(2)
print("子进程2结束了") if __name__ == '__main__':
p1 = Process(target=func1,)
p2 = Process(target=func2,) p1.daemon = True
p2.daemon = True p1.start()
p2.start() print("主进程代码结束了")
守护进程
11, 信号量, 事件
参考进程.
12、线程队列
和进程的方法一样, 不过种类有3种.
Queue: 先进先出;
LifoQueue: 先进后出, 后进先出;
PriorityQueue: 可以指定优先级的队列.
import queue """"""
# 先进先出
q = queue.Queue(3)
q.put(111)
q.put(222)
q.put(333)
print("当前队列里的元素数量>>>>>>",q.qsize())
try:
q.put_nowait(444) # queue.Full
except Exception:
print("队列满了") print(q.get())
print(q.get())
print(q.get())
try:
q.get_nowait() # _queue.Empty
except:
print("队列空了") # 先进后出
q = queue.LifoQueue(3)
q.put(111)
q.put(222)
q.put_nowait(444)
print(q.get())
print(q.get())
print(q.get())
# 方法和先进先出的队列一样 # 指定优先级顺序的队列
# put()里面放元组, 第一个参数是优先级顺序, 越小优先级越高(包括负数在内), get()越靠前. q = queue.PriorityQueue(5)
q.put((-2, -222))
q.put((0, 101))
q.put((1, 111))
q.put((2, 222))
q.put((3, 333)) print(q.get()) # (-2, -222)
print(q.get()) # (0, 101)
print(q.get()) # (1, 111)
print(q.get()) # (2, 222)
print(q.get()) # (3, 333)
线程3种队列
13、线程池
虽然说线程的开支要比进程小得多, 但总归还是要消耗资源的, 所有就有了线程池.
线程池和进程池提供异步调用, 减少资源的开支.
(在 from current.futures import ThreadPoolExecutor, ProcessPoolExecutor的模块中, 线程池和进程池中的 map() 方法是没有 close() 和 join() 方法的, 而且map机制中不自带 shutdown() 方法, 得自己手写 shutdown() 方法, 而且在该模块下的进程池中是没有 apply() 和 apply_async()方法的)
import time
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor """submit() 和 shutdown() 是进程池和线程池所共有的方法""" def func(i):
time.sleep(0.5)
return i ** 2 if __name__ == '__main__': """
# 线程池
t_p_lst = []
t_p = ThreadPoolExecutor(4)
for i in range(10):
ret = t_p.submit(func,i) # 提交一个执行函数, 并返回一个结果对象, 参数i 可以是任意的
# print(ret.result()) # 和进程的 .get()方法一样,拿任务的执行结果, 取不到就一直阻塞着,一个一个取的话就是串行状态
t_p_lst.append(ret) t_p.shutdown() # 作用效果和 .close()阻止新任务进来 + .join(), 等待所有的线程运行完毕.
for t_p in t_p_lst:
print(t_p.result()) # map()
ret = t_p.map(func,range(10)) # 线程池的map是没有close()和join()方法的
# print(ret) # <generator object Executor.map.......是一个生成器对象
for i in ret:
print(i)
""" """
# 进程池
p_p_lst = []
p_p = ProcessPoolExecutor(4)
for i in range(10):
ret = p_p.submit(func,i)
# print(ret.result())
p_p_lst.append(ret)
p_p.shutdown()
for p_p in p_p_lst:
print(p_p.result())
"""
线程池
14、线程池的回调函数
import time
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor def func(i):
time.sleep(1)
return i ** 2 def call_back_func(ret):
print(ret.result()) if __name__ == '__main__': p_p = ProcessPoolExecutor(max_workers=4)
for i in range(10):
p_p.submit(func, i).add_done_callback(call_back_func) # add_done_callback() 进程池的回调函数.
回调函数
15、GIL全局解释器线程锁
在CPython中由于GIL全局解释器线程锁, 同一进程下开启的多线程, 同一时刻只能有一个线程运行.
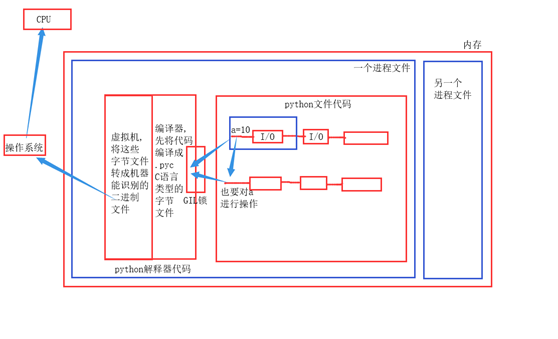
执行过程:
1, cPython解释器由两部分组成, 虚拟机和编译器;
2, cPython解释器代码先被加载到内存中, 然后.py文件这个进程中开启的多个线程, 同一时间只能有一个线程通过GIL锁,被编译器编译成.pyc文件(C语言能识别的字节码);
3, cpython中的虚拟机再将这些字节码转成机器能识别的二进制文件;
4, 操作系统将这些二进制文件调给CPU去计算.
有了GIL锁, 还要自定义的同步锁干嘛?
当第一个线程在运行时遇到 I/O 操作, 第二个线程就会通过GIL锁被执行, 如果两个线程操作的是同一个文件或数据, 就会造成数据混乱的现象, 用自定义的同步锁来保护数据安全.
有了GIL锁, 没有自定义的同步锁, 无法保证数据安全; 没有GIL锁, 只有同步锁也可以保证数据安全, 只不过后来cpython解释器的发展是建立在GIL锁的基础上的.
python摸爬滚打之day33----线程的更多相关文章
- python之进程与线程
什么是操作系统 可能很多人都会说,我们平时装的windows7 windows10都是操作系统,没错,他们都是操作系统.还有没有其他的? 想想我们使用的手机,Google公司的Androi ...
- python学习笔记12 ----线程、进程
进程和线程的概念 进程和线程是操作系统中两个很重要的概念,对于一般的程序,可能有若干个进程,每一个进程有若干个同时执行的线程.进程是资源管理的最小单位,线程是程序执行的最小单位(线程可共享同一进程里的 ...
- python之路: 线程、进程和协程
进程和线程 既然看到这一章,那么你肯定知道现在的系统都是支持“多任务”的操作,比如: Mac OS X,UNIX,Linux,Windows等. 多任务:简单地说就是同时运行多个任务.譬如:你可以一边 ...
- Python的进程与线程--思维导图
Python的进程与线程--思维导图
- 004_浅析Python的GIL和线程安全
在这里我们将介绍Python的GIL和线程安全,希望大家能从中理解Python里的GIL,以及GIL的前世今生. 对于Python的GIL和线程安全很多人不是很了解,通过本文,希望能让大家对Pytho ...
- Python 9 进程,线程
本节内容 python GIL全局解释器锁 线程 进程 Python GIL(Global Interpreter Lock) In CPython, the global interpreter l ...
- python网络编程基础(线程与进程、并行与并发、同步与异步、阻塞与非阻塞、CPU密集型与IO密集型)
python网络编程基础(线程与进程.并行与并发.同步与异步.阻塞与非阻塞.CPU密集型与IO密集型) 目录 线程与进程 并行与并发 同步与异步 阻塞与非阻塞 CPU密集型与IO密集型 线程与进程 进 ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- Python基础-进程和线程
一.进程和线程的概念 首先,引出“多任务”的概念:多任务处理是指用户可以在同一时间内运行多个应用程序,每个应用程序被称作一个任务.Linux.windows就是支持多任务的操作系统,比起单任务系统它的 ...
- python基础===进程,线程,协程的区别(转)
本文转自:http://blog.csdn.net/hairetz/article/details/16119911 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度. 线程拥有自 ...
随机推荐
- liblensfun 在 mingw 上编译时遇到的奇怪问题
ffmpeg 2018.07.15 增加 lensfun 滤镜; 这个滤镜需要 liblensfun 库; Website: http://lensfun.sourceforge.net/ Sourc ...
- angularjs异步处理 $q.defer()
看别人的项目中有用到 var def = $q.defer()返回一个deferred异步对象def 当代码逻辑遇到 def.resolve(rtns); deferred状态为执行成功,返回rtns ...
- Windows Internals 笔记——进程
1.一般将进程定义成一个正在运行的程序的一个实例,由以下两部分构成: 一个内核对象,操作系统用它来管理进程,内核对象也是系统保存进程统计信息的地方. 一个地址空间,其中包含所有可执行文件或DLL模块的 ...
- python 列表 元组 字符串
列表添加: list.append() list.extend() list.insert() 列表删除: list.remove() #删除某一个元素 list.pop() #删除某一个返回删 ...
- python之使用 wkhtmltopdf 和 pdfkit 批量加载html生成pdf,适用于博客备份和官网文档打包
0. 1.参考 Python 爬虫:把廖雪峰教程转换成 PDF 电子书 https://github.com/lzjun567/crawler_html2pdf wkhtmltopdf 就是一个非常好 ...
- pandas处理丢失数据-【老鱼学pandas】
假设我们的数据集中有缺失值,该如何进行处理呢? 丢弃缺失值的行或列 首先我们定义了数据集的缺失值: import pandas as pd import numpy as np dates = pd. ...
- Expression Trees 参数简化查询
ASP.NET MVC 引入了 ModelBinder 技术,让我们可以在 Action 中以强类型参数的形式接收 Request 中的数据,极大的方便了我们的编程,提高了生产力.在查询 Action ...
- Python学习(三十三)—— Django之ORM
Object Relational Mapping(ORM) 一.ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系 ...
- 2018-2019-1 20189201 《LInux内核原理与分析》第五周作业
甜死人的图片 一.书本第四章知识总结[系统调用的三层机制(上)] 无参数系统调用 依次通过c语言和内嵌汇编的c语言实现time()函数中封装的系统调用. 用户态.内核态和中断 用户态:在低的执行级别下 ...
- WebLogic使用总结(一)——WebLogic安装
一.下载WebLogic 到Oracle官网http://www.oracle.com/ 下载WebLogic(根据自己的情况选择),本文档下载的是Generic WebLogic Server an ...