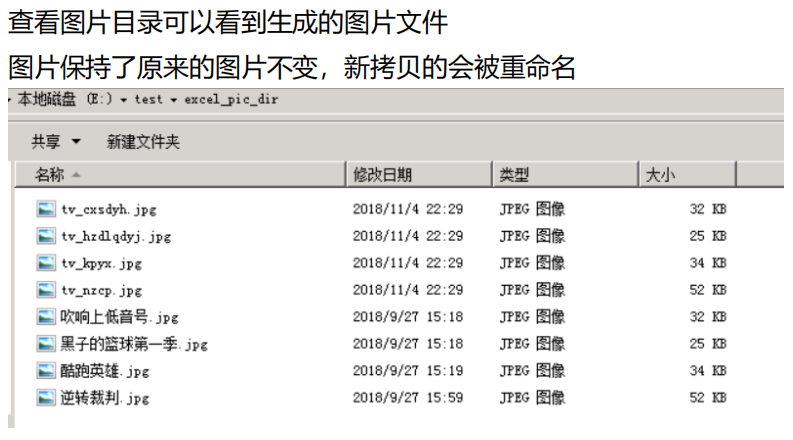
提取excel表数据成json格式的以及对图片重命名
开发那边的需求
1、功夫熊猫以及阿狸布塔故事集都是属于剧集的。意思就是有很多集,这里称他们为tv
最下面这几行第一列没名字的都是单集的,这里称它们为mv
需要统计所有工作表里面的数据把tv放一个大的json里面
把mv放一个大的json里面
2、需要检索图片名列。然后检测文件夹里面是否有对应的图片。
同时把图片提取首字母并生成新文件名
比如
功夫熊猫.jpg 会变成 tv_gfxm.jpg
必备古诗.jpg 会变成 mv_gfxm.jpg
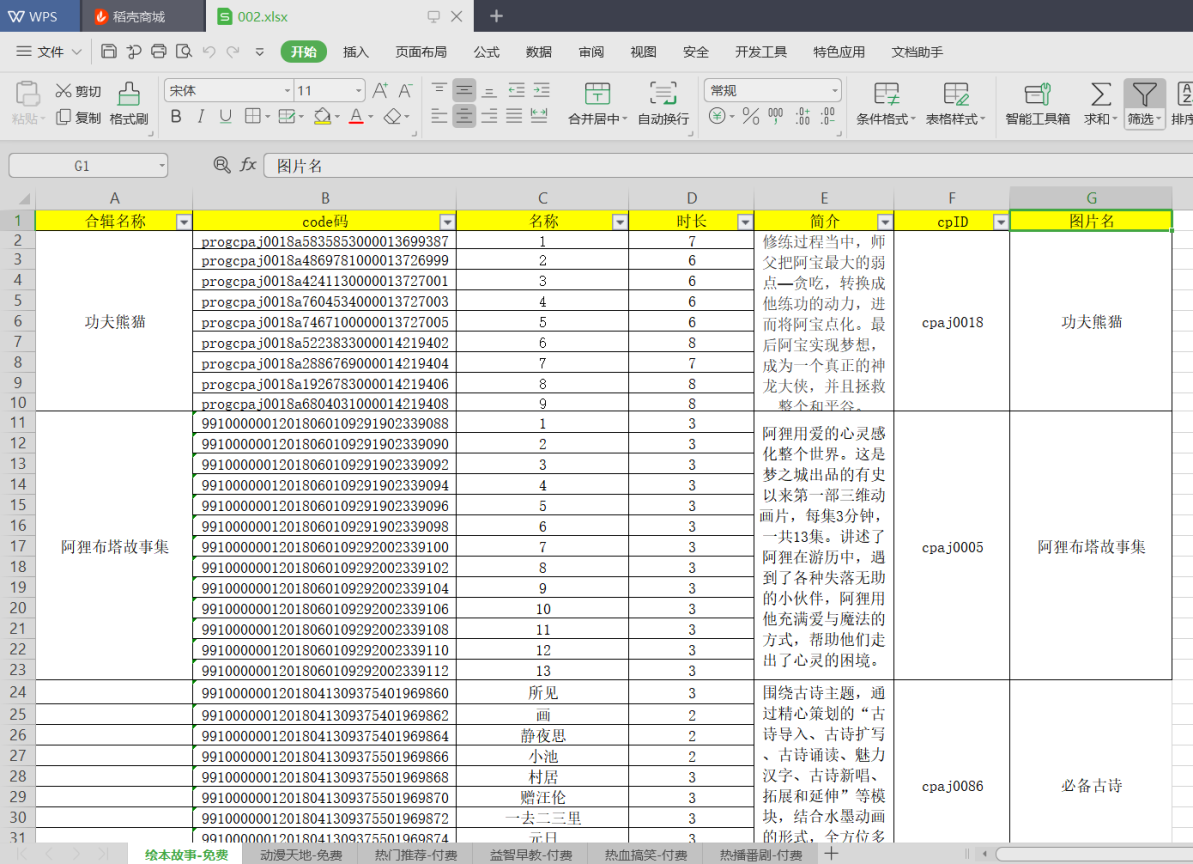
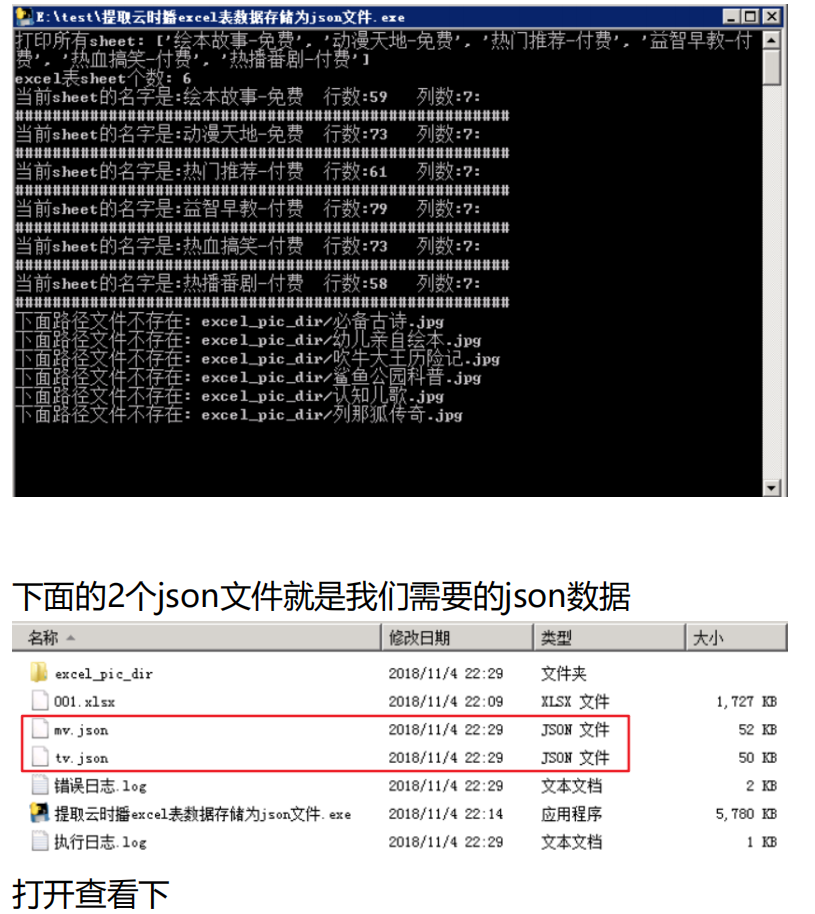
下面是最终效果图
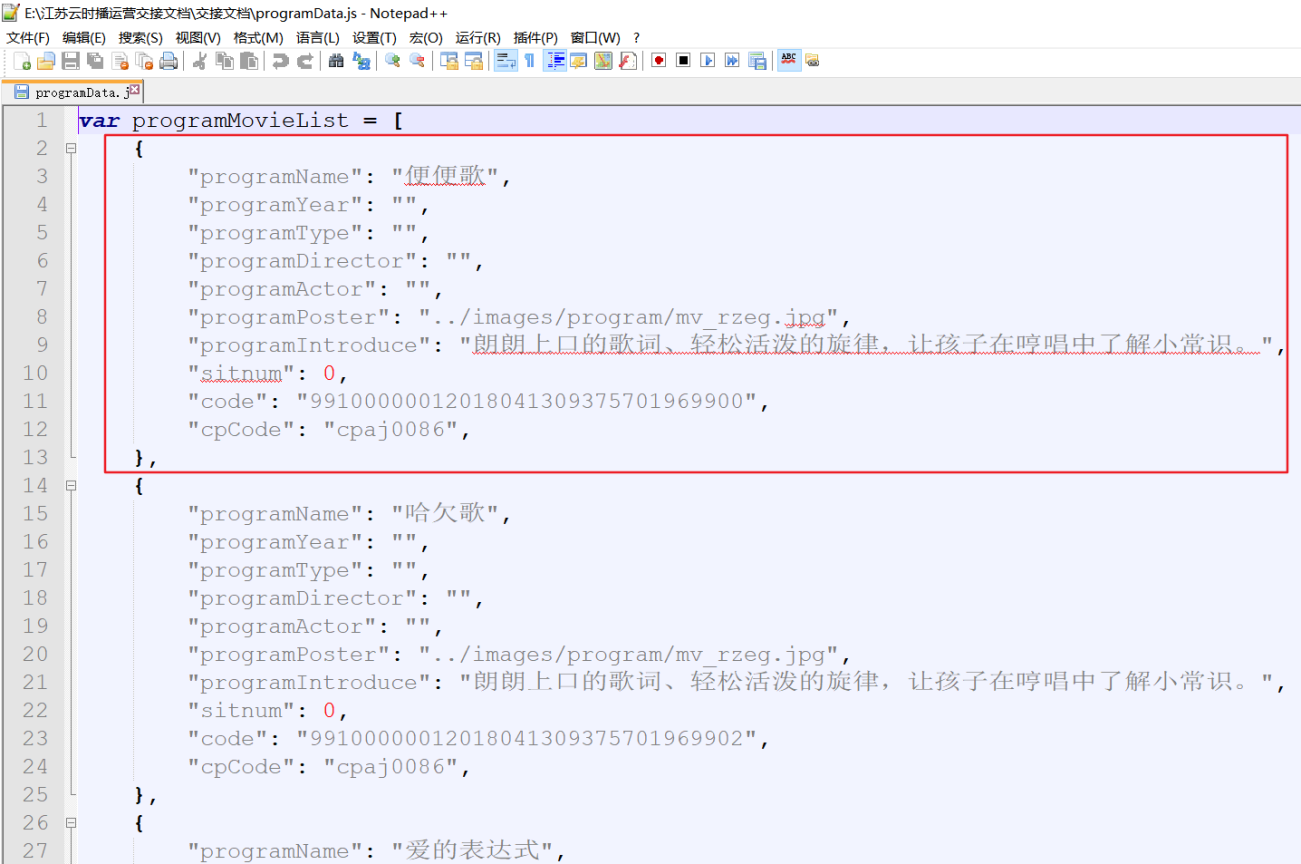
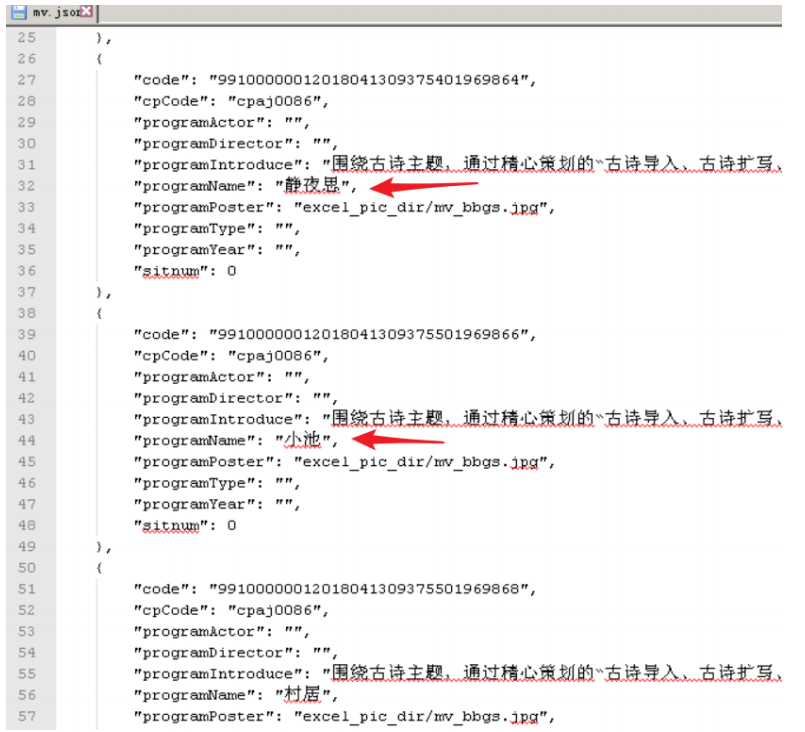
这是单个mv的数据和字段
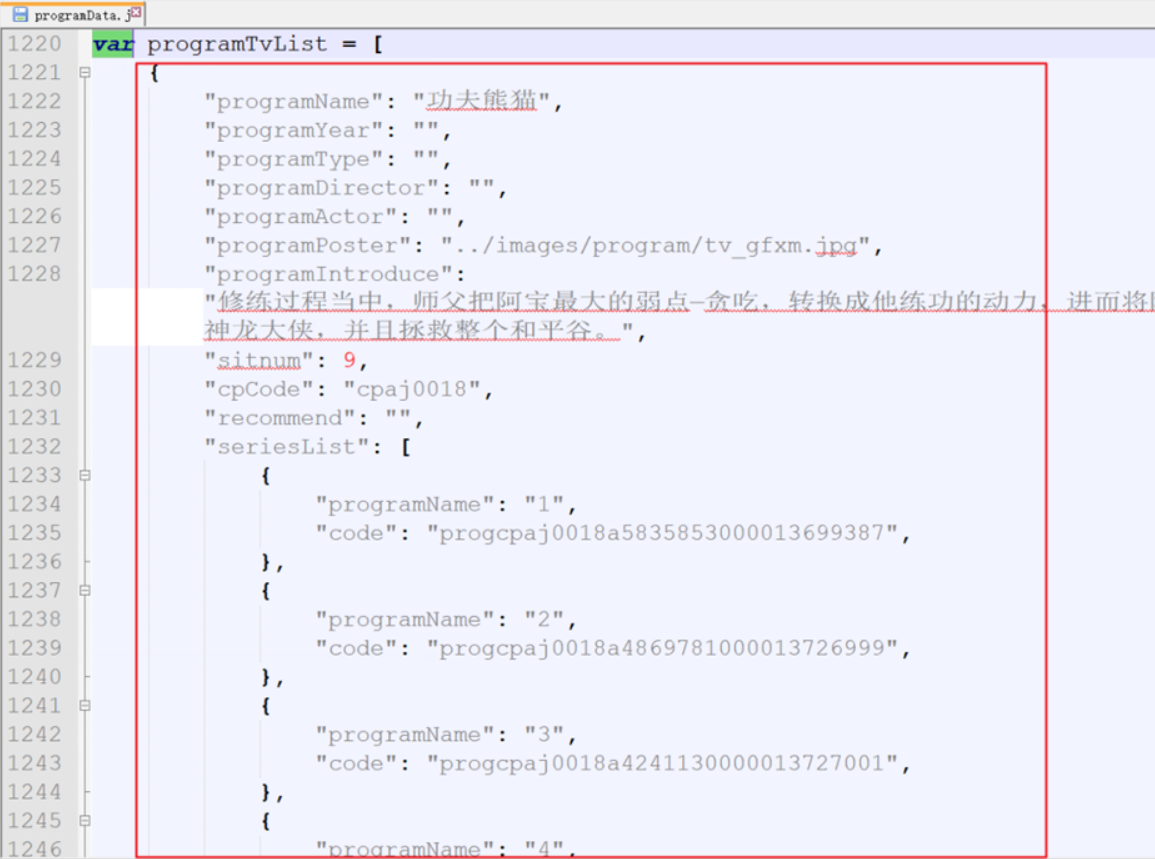
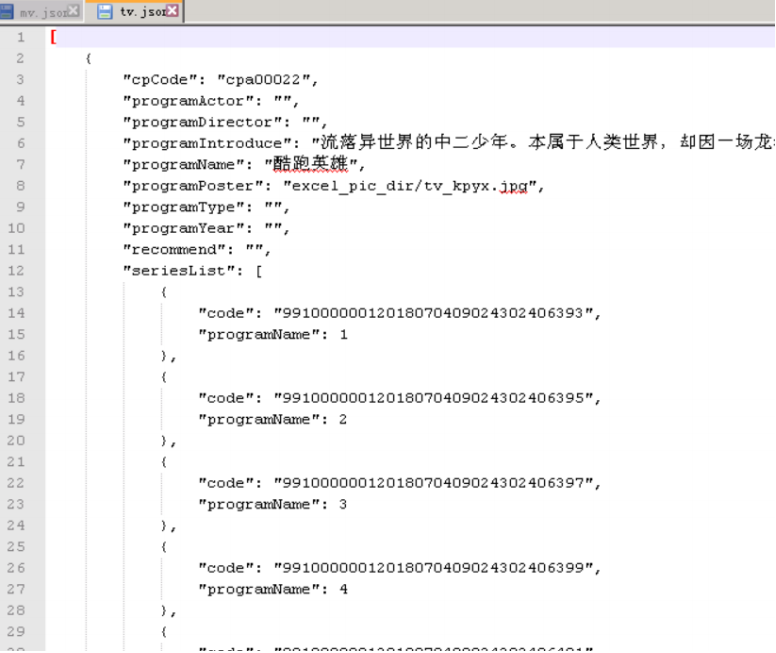
下面是一个tv
功能实现
这里没使用到uuid。本来想把它当做一个key的。后面发现不需要
# -*- coding: utf-8 -*-
import xlrd
import uuid
import re,time,json,shutil,os #临时存放所有单集
mv_list=[]
#临时存放剧集,后面调用format_tv方法存成tv_dict
tv_list=[] #tv_dict是所有剧集,key是首字母缩写,值是列表,列表每个元素是剧集的一行
tv_dict={} #图片集合,后期用来给图片重命名使用
pic_list=[] exec_log=open('执行日志.log','a',encoding='utf-8')# 追加模式
error_log=open('错误日志.log','a',encoding='utf-8')# 追加模式
#获取excel表中需要提取的视频文件名列表,返回值是个excel句柄
def OpenExcel(excel_file):
try:
dataHandle = xlrd.open_workbook(excel_file)
return dataHandle
except Exception as ex:
print(str(ex))
error_log.write('打开excel表失败,可能---'+excel_file+'---并不存在\n')
error_log.close()
exit(1) #读取excel数据
def ReadExcel(excel_file):
workbook=OpenExcel(excel_file)
exec_log.write("正在读取excel表内容")
print('打印所有sheet:', workbook.sheet_names())
#工作表个数
sheet_name_list=workbook.sheet_names()
sheet_count=len(workbook.sheet_names())
print("excel表sheet个数:",sheet_count)
exec_log.write("准备循环excel每个工作表..\n")
for i in range(sheet_count):
current_sheet = workbook.sheet_by_index(i) # sheet索引从0开始
rows_num = current_sheet.nrows
cols_num = current_sheet.ncols
print("当前sheet的名字是:%s 行数:%s 列数:%s:"%(sheet_name_list[i],rows_num,cols_num))
print("#####################################################")
for r in range(1,rows_num):
# 一行数据的实体
entity_dict = {}
for c in range(0,cols_num):
cell_value=get_value_and_get_int(current_sheet,r,c)
#这里如果单元格内容为空或者是None的话,再次判断是是否属于合并单元格
if (cell_value is None or cell_value == ''):
cell_value = (get_merged_cells_value(current_sheet, r, c))
the_key = 'colnum' + str(c + 1)
entity_dict[the_key] = cell_value
#第7列判断是否有空格
if entity_dict["colnum7"] is None or entity_dict['colnum7'] == '':
error_log.write("遇到图片所在列为空值的情况,无法对空值处理,格式异常位置为,3秒后退出\n")
exec_log.write("当前sheet的名字是:%s 行数:%s "%(sheet_name_list[i],r))
exec_log.close()
print("遇到图片所在列为空值的情况,无法对空值处理,格式异常位置为,3秒后退出")
print("当前sheet的名字是:%s 行数:%s "%(sheet_name_list[i],r))
time.sleep(3)
exit(1)
#第7列去掉空格,因为要把图片转成首字母
entity_dict["colnum7"].replace(' ','')
if entity_dict['colnum1'] is None or entity_dict['colnum1'] == '':
mv_list.append(entity_dict)
else:
tv_list.append(entity_dict)
exec_log.write("循环所有工作表完毕,已经追加到单集列表和剧集列表..暂未生成图片列\n") #处理单元格值中的int类型,因为xlrd模块会把int自动转成了float,再改回去
def get_value_and_get_int(sheet,r,c):
cell_value = sheet.row_values(r)[c]
# 这由于xlrd会把int类型自动转存float,这里做一个处理,把它再转回int类型
cell_type = sheet.cell(r,c).ctype # 表格的数据类型
if cell_type == 2 and cell_value % 1 == 0.0: # ctype为2且为浮点
cell_value = int(cell_value) # 浮点转成整型
return cell_value #找到所有合并单元格的坐标(上下左右)
def get_merged_cells(sheet):
"""
获取所有的合并单元格,格式如下:
[(4, 5, 2, 4), (5, 6, 2, 4), (1, 4, 3, 4)]
(4, 5, 2, 4) 的含义为:行 从下标4开始,到下标5(不包含) 列 从下标2开始,到下标4(不包含),为合并单元格
:param sheet:
:return:
"""
return sheet.merged_cells # 获取单元格的值
def get_merged_cells_value(sheet, row_index, col_index):
"""
先判断给定的单元格,是否属于合并单元格;
如果是合并单元格,就返回合并单元格的内容
:return:
"""
merged = get_merged_cells(sheet)
for (rlow, rhigh, clow, chigh) in merged:
if (row_index >= rlow and row_index < rhigh) and (col_index >= clow and col_index < chigh) :
cell_value = sheet.cell_value(rlow, clow)
# print('该单元格[%d,%d]属于合并单元格,值为[%s]' % (row_index, col_index, cell_value))
return cell_value
# print(cell_value)
# return None def getUUID():
return uuid.uuid1().hex #去除标点符号
def remove_punctuation(str):
new_str=re.sub('[^\w\u4e00-\u9fff]+', '',str)
return new_str #获取单个汉字的首字母
def single_get_first(unicode1):
str1 = unicode1.encode('gbk')
try:
ord(str1)
return str1
except:
asc = str1[0] * 256 + str1[1] - 65536
if asc >= -20319 and asc <= -20284:
return 'a'
if asc >= -20283 and asc <= -19776:
return 'b'
if asc >= -19775 and asc <= -19219:
return 'c'
if asc >= -19218 and asc <= -18711:
return 'd'
if asc >= -18710 and asc <= -18527:
return 'e'
if asc >= -18526 and asc <= -18240:
return 'f'
if asc >= -18239 and asc <= -17923:
return 'g'
if asc >= -17922 and asc <= -17418:
return 'h'
if asc >= -17417 and asc <= -16475:
return 'j'
if asc >= -16474 and asc <= -16213:
return 'k'
if asc >= -16212 and asc <= -15641:
return 'l'
if asc >= -15640 and asc <= -15166:
return 'm'
if asc >= -15165 and asc <= -14923:
return 'n'
if asc >= -14922 and asc <= -14915:
return 'o'
if asc >= -14914 and asc <= -14631:
return 'p'
if asc >= -14630 and asc <= -14150:
return 'q'
if asc >= -14149 and asc <= -14091:
return 'r'
if asc >= -14090 and asc <= -13119:
return 's'
if asc >= -13118 and asc <= -12839:
return 't'
if asc >= -12838 and asc <= -12557:
return 'w'
if asc >= -12556 and asc <= -11848:
return 'x'
if asc >= -11847 and asc <= -11056:
return 'y'
if asc >= -11055 and asc <= -10247:
return 'z'
return '' #获取每个汉字每个首字母并返回英文首字母字符串
def getPinyin(str):
if str==None:
return None
str_list = list(str)
charLst = []
for item in str_list:
charLst.append(single_get_first(item))
return ''.join(charLst) #拷贝文件
def copy_file(source_file,target_file):
if os.path.exists(source_file) and not os.path.exists(target_file):
shutil.copy(source_file,target_file)
else:
error_log.write("下面路径文件不存在: %s\n"%(source_file))
print("下面路径文件不存在: %s"%(source_file))
time.sleep(0.1) #处理图片列表[[pic1,tar1],[pic2,tar2],去重并且调用拷贝文件方式拷贝为新文件
def copy_file_from_list(pic_list):
#对列表去重,这里无法使用set,因为set无法对子元素为列表的元素做hash
new_pic_list=[]
for item in pic_list:
if item not in new_pic_list:
new_pic_list.append(item)
for item in new_pic_list:
copy_file(item[0],item[1]) #给单集新增加一列key,值是图片列的英文首字母加上路径名拼接字符串,比如"excel_pic_dir/mv_hj.jpg" 这种格式
def add_pic_col_for_mv(mv_list):
exec_log.write("给单集列表生成图片路径列excel_pic_dir/mv_hj.jpg 这种格式\n")
for item in mv_list:
#格式化汉字字符串,去掉特殊符号
temp_str=remove_punctuation(item['colnum7'])
#获取首字母字符串
temp_letter=getPinyin(temp_str)
# print(item['colnum7'])
# temp_letter=getPinyin(temp_letter)
# temp_letter=getPinyin(item['colnum7'])
# print(temp_letter)
#拼接为图片路径,一个放到图片集合中给后面重命名使用,一份直接增加到excel行字典中
source_file="excel_pic_dir/"+temp_str+".jpg"
target_file="excel_pic_dir/mv_"+temp_letter+".jpg"
pic_list.append([source_file,target_file])
# copy_file(source_file,target_file)
item["pic_path"]=target_file
exec_log.write("给单集列表生成图片路径列完毕\n") #给剧集新增加一列key,值是图片列的英文首字母加上路径名拼接字符串,比如"excel_pic_dir/tv_hj.jpg" 这种格式
def add_pic_col_for_tv(tv_list):
exec_log.write("给剧集列表生成图片路径列excel_pic_dir/mv_hj.jpg 这种格式\n")
for item in tv_list:
#格式化汉字字符串,去掉特殊符号
temp_str=remove_punctuation(item['colnum7'])
#获取首字母字符串
temp_letter=getPinyin(temp_str)
#拼接为图片路径
source_file="excel_pic_dir/"+temp_str+".jpg"
target_file="excel_pic_dir/tv_"+temp_letter+".jpg"
#拼接为图片路径,一个放到图片集合中给后面重命名使用,一份直接增加到excel行字典中
pic_list.append([source_file,target_file])
# copy_file(source_file,target_file)
# temp_path="excel_pic_dir/tv_"+temp_letter+".jpg"
item["pic_path"]=target_file
exec_log.write("给剧集列表生成图片路径列完毕\n") #把剧集的都放在一个字典中,key是剧集首字母,value是剧集列表
def format_tv(tv_list):
# tv_dict={}
exec_log.write("把剧集的都放在一个大字典中,key是剧集首字母,value是剧集列表\n")
for tv_item in tv_list:
#先获取字符串,去掉标点符号
temp_str=remove_punctuation(tv_item['colnum1'])
#获取首字母字符串
temp_key=getPinyin(temp_str)
if temp_key in tv_dict:
tv_dict[temp_key].append(tv_item)
else:
tv_dict[temp_key]=[]
tv_dict[temp_key].append(tv_item)
exec_log.write("把剧集的都放在一个大字典中完毕\n") if __name__ == "__main__":
ReadExcel("001.xlsx")
# print(mv_list[0])
add_pic_col_for_mv(mv_list)
add_pic_col_for_tv(tv_list)
format_tv(tv_list)
copy_file_from_list(pic_list)
print("单集个数:",len(mv_list))
print("剧集套数:",len(tv_dict)) # print(mv_list[0])
# for k,v in tv_dict.items():
# print(k,v)
# break #获取单集最终字典列表
programMovieList=[]
for item in mv_list:
new_item={}
new_item["programName"]=item["colnum3"]
new_item["programYear"]=""
new_item["programType"]=""
new_item["programDirector"]=""
new_item["programActor"]=""
new_item["programPoster"]=item["pic_path"]
new_item["programIntroduce"]=item["colnum5"]
new_item["sitnum"]=0
new_item["code"]=item["colnum2"]
new_item["cpCode"]=item["colnum6"]
programMovieList.append(new_item)
exec_log.write("单集最终字典列表获取完毕\n") exec_log.write("开始dump---单集---数据到json文件中\n")
with open('mv.json', 'w',encoding='utf-8') as f_mv:
json.dump(programMovieList, f_mv,ensure_ascii=False,sort_keys=True, indent=4)
exec_log.write("dump---单集---数据完毕\n")
print("dump---单集---数据完毕..")
time.sleep(2) def get_seriesList(item_list):
seriesList=[]
for item in item_list:
new_item={}
new_item["programName"]=item["colnum3"]
new_item["code"]=item["colnum2"]
seriesList.append(new_item)
return seriesList
#获取剧集最终字典列表
programTvList=[]
for item in tv_dict:
new_item={}
# print(item)
new_item["programName"]=tv_dict[item][0]["colnum1"]
new_item["programYear"]=""
new_item["programType"]=""
new_item["programDirector"]=""
new_item["programActor"]=""
new_item["programPoster"]=tv_dict[item][0]["pic_path"]
new_item["programIntroduce"]=tv_dict[item][0]["colnum5"]
new_item["sitnum"]=len(tv_dict[item])
new_item["cpCode"]=tv_dict[item][0]["colnum6"]
new_item["recommend"]=""
new_item["seriesList"]=get_seriesList(tv_dict[item])
programTvList.append(new_item)
# for k,v in new_item.items():
# print("\""+k+"\"",v)
#indent参数是缩进的意思,它可以使得数据存储的格式变得更加优雅。
# with open('data.json', 'w',encoding='utf-8') as f:
# json.dump(new_item, f,sort_keys=True, indent=4)
exec_log.write("开始dump---剧集---数据到json文件中\n")
with open('tv.json', 'w',encoding='utf-8') as f_tv:
json.dump(programTvList, f_tv,ensure_ascii=False,sort_keys=True, indent=4)
exec_log.write("dump---剧集---数据完毕\n")
print("dump---剧集---数据完毕..")
print("程序执行完毕,2秒后退出..")
error_log.close()
exec_log.close()
time.sleep(2)
最后打包成exe交给开发那边
把使用说明告诉开发即可



运行结果

提取excel表数据成json格式的以及对图片重命名的更多相关文章
- Python mysql表数据和json格式的相互转换
功能: 1.Python 脚本将mysql表数据转换成json格式 2.Python 脚本将json数据转成SQL插入数据库 表数据: SQL查询:SELECT id,NAME,LOCAL,mobil ...
- 利用 js-xlsx 实现 Excel 文件导入并解析Excel数据成json格式的数据并且获取其中某列数据
演示效果参考如下:XML转JSON 另一个搭配SQL实现:http://sheetjs.com/sexql/index.html 详细介绍: 1.首先需要导入js <script src=&qu ...
- ABAP内表数据和JSON格式互转
本程序演示ABAP内表数据如何转为JSON格式,以及JSON数据如何放入内表. 注:json字符串格式如:jsonstr = '[ {flag: "0",message: &quo ...
- 通过jquery的serializearray处理表单数据成json格式,并提交到后台处理
var params = $("#myform").serializeArray(); var values = {}; for (var item in params) { va ...
- 利用python将excel数据解析成json格式
利用python将excel数据解析成json格式 转成json方便项目中用post请求推送数据自定义数据,也方便测试: import xlrdimport jsonimport requests d ...
- <form> 标签 // HTML 表单 // from 表单转换成json 格式
<form> 标签 // HTML 表单 // from 表单转换成json 格式 form 表单,对开发人员来说是在熟悉不过的了,它是页面与web服务器交互时的重要信息来源 表 ...
- android实现json数据的解析和把数据转换成json格式的字符串
利用android sdk里面的 JSONObject和JSONArray把集合或者普通数据,转换成json格式的字符串 JSONObject和JSONArray解析json格式的字符串为集合或者一般 ...
- java将XML文档转换成json格式数据
功能 将xml文档转换成json格式数据 说明 依赖包:1. jdom-2.0.2.jar : xml解析工具包;2. fastjson-1.1.36.jar : 阿里巴巴研发的高性能json工具包 ...
- oracle 10g 用dbms_xmlgen将数据表转成xml格式
oracle 10g 用dbms_xmlgen将数据表转成xml格式 oracle 10g 用dbms_xmlgen将数据表转成xml格式 oracle用plsql将sql查询的所有数据导出为xml
随机推荐
- WPF实现按钮鼠标停留样式的一个坑
弄了个按钮鼠标停留样式,发现把它应用到某些窗体的Button上会发生样式模糊的问题,而其它窗体又不会. 百思不得其解,真是活久见. 后来发现是跟包着Button的容器控件有关,只要是那些会自适应的容器 ...
- JSON与JS对象的区别
<script> var obj2={};//这只是JS对象 var obj3={width:100,height:200};/*这跟JSON就更不沾边了,只是JS的 对象 */ var ...
- 高精度加法——经典题 洛谷p1601
题目背景 无 题目描述 高精度加法,x相当于a+b problem,[b][color=red]不用考虑负数[/color][/b] 输入输出格式 输入格式: 分两行输入a,b<=10^500 ...
- this.$nextTick()作用
当data中的某个属性改变的时候,这个值并不是立即渲染到页面上,而是先放到watcher队列上(异步),只有当前任务空闲的时候才会去执行watcher队列上的任务.所以导致,改变的数据挂载到dom上会 ...
- Python matplotlib绘图学习笔记
测试环境: Jupyter QtConsole 4.2.1Python 3.6.1 1. 基本画线: 以下得出红蓝绿三色的点 import numpy as npimport matplotlib. ...
- 运维route语法
Linux系统的route命令用于显示和操作IP路由表(show / manipulate the IP routing table).要实现两个不同的子网之间的通信,需要一台连接两个网络的路由器,或 ...
- 大数字加法(hduoj)
Problem Description I have a very simple problem for you. Given two integers A and B, your job is to ...
- git特殊命令
1.git追踪远程分支,该命令使用Tab不会自动补全 git branch --set-upstream-to=远程分支名(origin/xxx) 2.从远程分支创建本地新分支 git checkou ...
- MySQL之UNION与UNION ALL
数据表中的数据如下: UNION: 可以获取books表与articles表中所有不同的title,如果两个表中title相同的只会显示一个. UNION ALL : 可以获取books表与arti ...
- 神州数码HSRP(热备份路由协议)配置
实验要求:掌握HSRP配置方法 拓扑如下 R1 enable 进入特权模式 config 进入全局模式 hostname R1 修改名称 interface g0/6 进入端口 ip address ...