[十]基础数据类型之Unicode编码简介
编码含义
Unicode诞生
Unicode不够用了

| 00 01 02 03 04 05 06 07 08 0A 0B 0C 0D 0E 0F 10 |

|
于是按照扩展位,划分了17个维度,这每个维度,叫做一个平面
17个平面,编号从 0~16
|
| 每个平面 65536个字符 |
| 17个平面,扩展后总共可以表示1114112个字符 |
|
扩展后的范围为
U+000000 ~ U+10FFFF
|
编码方式
| 听起来可能有点迷惑,不是知道具体的值了么?怎么还不知道如何表示?
比如数字1 他的码点是1 最直观的例子就是网络中报文的传输,都会附加自己的头信息 |
|
UTF-8 是变长
UTF-32 是定长
UTF-16介于他们之间 2个字节或者4个字节
|
utf-16
| UTF-16编码以16位无符号整数为单位 |
|
我们把Unicode编码记作U 编码规则如下
如果U<0x010000, 也就是0x000000 ~ 0x00FFFF
U的UTF-16编码, 就是U对应的16位无符号整数
|
| 如果U≥0x010000 也就是0x010000 ~ 0x10FFFF 我们先计算下 U'=U-0x010000 可以得出来 U' 范围是 0x000000 ~ 0x0FFFFF 显然, U'的最大值为0xFFFFF 也就是最多20个1 也就是可以被写成20个二进制位 既然是20个二进制位,那么我们是不是可以把它拆分成两组呢? 每组10个二进制位 00 0000 0000 它能表示的范围是2的10次方=1024个 BMP是2个字节,16位, 很显然,如果把U' 拆分成两组,每组10个二进制位的话 所以Unicode标准规定:基本多语言平面内,U+D800..U+DFFF的值不对应于任何字符,为代理区 ,其中又分为高代理区和低代理区 U+D800 加上10个二进制位的数值的最大值,可以得到高代理区的范围 下一个就是0xDBFF +1 = 0xDC00,所以低代理区从0xDC00 开始 |
| 高代理区范围 U+D800 ~0xDBFF 低代理区范围 0xDC00 ~ 0xDFFF 代理区间是U+D800....U+DFFF |
| 所以UTF-16的编码方式就是 先计算 U'=U-0x010000 然后将U'写成二进制形式:yyyy yyyy yyxx xxxx xxxx 然后分别计算高位代理和低位代理 U+D800 --->1101 10 00 0000 0000 + 0000 00 yy yyyy yyyy = 1101 10 yy yyyy yyyy 0xDC00----> 1101 1100 0000 0000 + 0000 00 xx xxxx xxxx = 1101 11xx xxxx xxxx |
| 再精简下步骤 1. 先计算 U'=U-0x010000 2. 然后将U'写成二进制形式:yyyy yyyy yyxx xxxx xxxx 3.两个值为 1101 10 yy yyyy yyyy / 1101 11xx xxxx xxxx |
|
之前我们提到过,Unicode中的一个字符的值,被称之为一个码点
显然,一个码点,可能被一个代码单元存储,也可能被两个连续的代码单元存储
|
UTF-32
UTF-8
| 规则 可以把编码分解成两部分,head和body head中记录需要字节的个数,使用第一个字节中1 的个数来表示 body记录真实的数据, 如果需要不止一个字节,那么body自然由多个字节组成,每个body的前两个字节为10 其余为数据 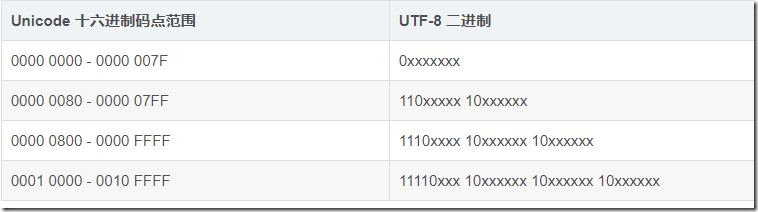 UTF-8编码的最大长度是4个字节,也就是最多有21个x 表示 Unicode的最大码位0x10FFFF 0001 0000 1111 1111 1111 1111也只有21位 |
| 如果一个字节足够表示 只需要一个字节即可表示,那么第一位为0 其余7位用于表示字符编码的值 看得出来明显的好处,可以兼容ASCII |
| 如果一个字节不够表示,根据范围选择,需要几个字节,就有几个1,然后补一个0 后面的body依次存放数据即可 |
| 想要确定一个码点的编码 1. 查看范围,根据上表确定格式 2.转换为对应的二进制序列 3. 替换掉x即可 |
字节序
|
在内存中0x01020304的存储方式
内存地址 4000 4001 4002 4003
BE 01 02 03 04
LE 04 03 02 01
|
[十]基础数据类型之Unicode编码简介的更多相关文章
- Java基础-二进制以及字符编码简介
Java基础-二进制以及字符编码简介 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必计算机毕业的小伙伴或是从事IT的技术人员都知道数据存储都是以二进制的数字存储到硬盘的.从事开 ...
- 【C# 基础概念】Unicode编码详解
Unicode定义:Unicode(统一码.万国码.单一码)是计算机科学领域里的一项业界标准,包括字符集.编码方案等.Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字 ...
- python基础数据类型补充以及编码的进阶
一.基本数据类型的补充循环列表改变列表大小的问题#请把列表中索引为基数的元素写出l1=[1,2,3,4,5,6]for i in l1: if i%2!=0: print(i)结果:135二:基本数据 ...
- 基础数据类型之AbstractStringBuilder
String内部是一个private final char value[]; 也就意味着每次调用的各种处理方法,返回的字符串都是一个新的,性能上,显然.... 所以,对于可变字符序列的需求是很明确的 ...
- Python基础编程:字符编码、数据类型、列表
目录: python简介 字符编码介绍 数据类型 一.Python简介 Python的创始人为Guido van Rossum.1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心 ...
- Unicode/UTF-8/GBK/ASCII 编码简介
转载:http://blog.csdn.net/u014785687/article/details/73928167 一.字符编码简介 1.ASCII编码 每一个ASCII码与一个8位(bit)二进 ...
- day02_20190106 基础数据类型 编码 运算符
一.格式化输出 name = input('请输入姓名') age = input('请输入年龄') hobby = input('请输入爱好') job = input('请输入你的工作') # m ...
- 记录我的 python 学习历程-Day07 基础数据类型进阶 / 数据类型之间的转换 / 基础数据类型总结 / 编码的进阶
基础数据类型 str(字符串) str:补充方法练习一遍就行 s.capitalize() 首字母大写,其余变小写 s = 'dyLAn' print(s.capitalize()) # Dylan ...
- python27期day07:基础数据类型补充、循环删除的坑、二次编码、作业题。
1.求最大位数bit_length: a = 10 #8421 1010print(a.bit_length())结果:42.capitalize首字母变大写: s = "alex" ...
随机推荐
- python爬取房天下数据Demo
import requests from bs4 import BeautifulSoup res = requests.get('http://sh.esf.fang.com/chushou/3_3 ...
- PyQt4转换ui为py文件需添加如下代码才可执行
1)转换ui为py 命令行进入ui文件所在文件夹,输入pyuic4 ui_name.ui > py_name.py即可 或新建ui2py.bat文件,写入: @echo off @cd /d & ...
- Prometheus 自定义exporter 监控key
当Prometheus的node_exporter中没有我们需要的一些监控项时,就可以如zabbix一样定制一些key,让其支持我们所需要的监控项. 例如,我要根据 逻辑cpu核数 来确定load的告 ...
- su;su -;sudo;sudo -i;sudo su;sudo su - 之间的区别
今天我们来聊聊su;su -;sudo;sudo -i;sudo su;sudo su -他们之间的区别. su :su 在不加任何参数,默认为切换到root用户,但没有转到root用户家目录下,也就 ...
- Servlet 自定义标签
自定义标签 1)用户定义的一种jsp标记,当一个含有自定义标签的jsp页面被jsp引擎编译成servlet时,tag标签被转化成了对一个称为 标签处理类 的对象的操作.于是,当jsp页面被jsp引擎转 ...
- vue学习笔记:在vue项目里面使用引入公共方法
首先新建一个文件夹:commonFunction ,然后在里面建立 一个文件common.js 建立好之后,在main.js里面引入这个公共方法 最后是调用这个公共方法 测试一下,我在公共方法里面写了 ...
- Android Studio 设置不同分辨率的图标Icon
右键你的项目 -->"NEW"-->"Image Asset" 'Asset Type' 勾选”Image“才可以选择”Path“,其他选项可以自己 ...
- 浅拷贝 &&&深拷贝 实现
1.浅拷贝 //1.直接赋值给一个变量 //浅拷贝 //2.Object.assign() //浅拷贝 let obj4={} let obj5={money:50000} obj4.__proto_ ...
- Lua学习链接
Lua捕获 Lua中_G 是个什么鬼 Lua与ObjC的交互
- Unity进阶----Lua语言知识点(2018/11/08)
国内开发: 敏捷开发: 集中精力加班堆出来第一个版本 基本没啥大的bug 国外开发: 1).需求分析: 2).讨论 3).分模块 4).框架 5).画UML图(类图class function)(e- ...