Python读写文件你真的了解吗?
内容概述
Python文件操作
针对大文件如何操作
为什么不能修改文件?
你需要知道的基本知识
1. Python文件操作
这一部分内容不是重点,因为很简单网上很多,主要看看文件操作的步骤就可以了。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# Author: rex.cheny
# E-mail: rex.cheny@outlook.com import os
import time
import sys FILE_PATH = "/Volumes/Work/ProgrammingStudy/AutoOperationStudy/Day03/file.txt"
if os.path.exists(FILE_PATH):
# 把文件对象给一个变量,这样后续才能操作这个文件对象,这里默认是以只读方式打开
FILE_HANDLER = open(FILE_PATH, encoding="utf-8")
# 读取
"""
read(size) 不加SIZE可以是整个文件读取,加上SIZE可以一部分一部分的读取,对于大文件要使用SIZE分段读取,对于小文件可以整体读取
readline() 一次读取一行
readlines() 一次读取全部文件到一个列表,适合读取配置文件,因为配置文件通常都是一行一行的,对于配置文件这种非常适合因为它比较小而且
配置文件都是一行一行的
"""
data = FILE_HANDLER.read()
print(FILE_HANDLER.fileno())
time.sleep(600)
print(data)
# 关闭
FILE_HANDLER.close()
else:
print("文件:", FILE_PATH, "不存在。") # 一行一行读取
if os.path.exists(FILE_PATH):
FILE_HANDLER = open(FILE_PATH, encoding="utf-8")
dataList = FILE_HANDLER.readlines()
for line in dataList:
print(line)
FILE_HANDLER.close() # 写入一行文件
if os.path.exists(FILE_PATH):
"""
mode r 是只读模式
w 是只写模式打开文件,其实是创建,所以如果原来的文件有内容它就给它清空了,所以在原有的内容写就不能用这种模式
a 追加模式,只能追加
r+ 读写模式,可以读取也能追加,只能追加
rb 读取二进制文件
wb 写入二进制文件
"""
FILE_HANDLER = open(FILE_PATH, encoding="utf-8", mode="a")
FILE_HANDLER.write("你好吗\n")
# 这个语句是立即落盘, 因为延迟写入,上面的write只是写入缓存并没有真正写入磁盘,如果对于写入内容比较多,你不去调用flush的话可能如果执行完write语句后刚好计算机
# 断电,那么就容易出现数据丢失的情况。
FILE_HANDLER.flush()
# 关闭已打开的文件流
FILE_HANDLER.close()
更加简单的创建文件对象的方式,上面的方式需要手动关闭文件流,下面的方式它会自动关闭文件流
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# Author: rex.cheny
# E-mail: rex.cheny@outlook.com import os
import sys FILE_PATH = "/Volumes/Work/ProgrammingStudy/AutoOperationStudy/Day03/file.txt" if os.path.exists(FILE_PATH):
with open(FILE_PATH, encoding="utf-8", mode="a") as FILE_HANDLER:
FILE_HANDLER.write("你好吗\n")
通过with open还可以打开多个文件
with open (FILE1, "r") as f1, open(FILE2, "w") as f2:
pass
2. 针对大文件如何操作
如何操作大文件比如10G一个文件,显然不能使用read()和readlines(),就算你的内存够大,这样一个文件都读取到内存里显然不是一个好办法,太浪费了内存了,另外从磁盘加载到内存页需要时间。是不是可以使用readline()?可以一行行读取,不过读的时候虽然是一行,可是不断的读取到内存最终还是会占用很大内存,所以一个好的方法是,读取一行到内存,处理完后把内存的那一行内容删除,然后再读取一行,也就是内存只保留一行。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# Author: rex.cheny
# E-mail: rex.cheny@outlook.com import os
import sys FILE_PATH = "/Volumes/Work/ProgrammingStudy/AutoOperationStudy/Day03/file.txt" if os.path.exists(FILE_PATH):
with open(FILE_PATH, encoding="utf-8", mode="r") as FILE_HANDLER:
# 这里并没有调用文件对象的read方法,此时这里这个文件对象是一个迭代器
for line in FILE_HANDLER:
print(line)
说明:由于上面使用的是迭代器而不是一个列表,所以你想控制输出N行或者第N行你就需要自己来做一个计数器,也就自己记录当前是第几行。
3. 为什么不能修改文件
你通过r+打开文件发现即便你使用当前读取到第N行(假设有M行)你调用write()还是无法插入,这个新增的内容只会显示在最后一行
你通过w打开文件发现源文件被清空了,感觉好危险的样子。
感觉vi编辑器、word这些都能直接修改啊?
这都是为什么呢?
数据存储简要原理
磁盘分区的最小单位是柱面,但是数据存储的最小单位是block也就是块,这个是文件系统相关内容,不是磁盘的物理特性。一个文件通常会占用1个或多个块。下面简要画图来看:

为了性能通常都会寻找连续的块来存放数据(读写效率最高,减少寻址时间),但是随着时间的推移(删除、新建、更新文件等操作)导致很多文件存放的块并不是连续的,就想文档2。假设我们现在修改文档1
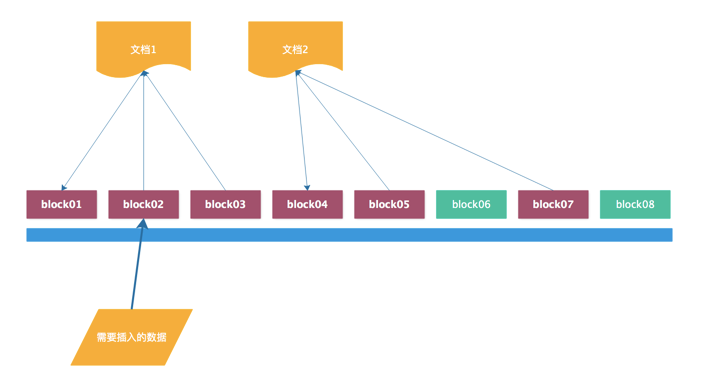
而且需要修改的数据正好在文档1的块2中。如果这时候允许你直接修改,那就意味着原来的数据存放位置要想后挪动,可是你看如果挪动,block03的内容就容易覆盖了block04也就是文档2的内容,显然这是不允许的,所以肯定不允许你从数据物理存放的角度来插入数据,所以就算你通过r+模式打开也无法插入。如果你以w模式打开系统会当做新文件来处理所以清空原来的数据。
那么为什么r+可以追加呢?追加是在文件末尾,假设block03还有空间那么就继续使用这个块,如果发现这个块空间不够,那么除了使用这个块剩余的空间它在最后保存的时候还会去申请新的块来保存内容,总之原有数据顺序不能变。
VI或者word为什么可以修改?
我们用VI打开文件尤其是一个大文件你会感觉慢,其实是因为它要把内容加载内存,然后你在内存中修改,也就是可以在文件任意位置修改,当修改完成保存磁盘的时候它会覆盖原有内容,同时如果本次修改增加了更多内容则会申请新的磁盘块用于存放。对于word来说也是一样的,你发现打开一个10M以上的word文件也并不快它也是加载到内存里,有人说如果文件很大,我的内存不是很大,能不能打开呢?可以,你是否还记得一个叫做虚拟内存的东西么,当然如果物理内存+虚拟内存都不够了,你也就打不开了。我记得之前用Windows电脑的时候出现过打开文件提示说内存不够。
4. 如何实现修改文件呢
在python中其实也一样,因为它底层调用的就是库函数。如果你想实现修改的效果怎么办?你要么读取都读取到内存中然后修改,最后再保存其实也就是覆盖源文件
我这里有一个之前替换线上配置文件某些信息的例子,main()方法不是重点,可以忽略,后面的replacepath才是文件修改部分。
#!/usr/bin/python
# -*- coding: UTF-8 -*- import sys
import os
import re def main(argv=None):
if argv is None:
argv = sys.argv # 规范化路径
path = os.path.normpath(r"/Users/rex.chen/Downloads/apps/")
config_path = os.path.normpath(r"product/conf") # 获取目录列表
appnamelist = os.listdir(path)
modifyappname = []
# 遍历目录
for appname in appnamelist:
print appname
# 拼接路径
app_config_full_path = os.path.join(path, appname, config_path)
filename = r"log4j.properties"
filefullpath = os.path.join(app_config_full_path, filename)
# 判断路径是否存在
if os.path.exists(filefullpath):
print filefullpath
key_word = r"${CATALINA_OUT}"
new_word = r"/work/logs/{{appname}}-{{port}}"
# 调用自定义函数并获取返回值
result = replacepath(appname, filefullpath, key_word, new_word)
if result:
modifyappname.append(appname)
else:
pass
else:
print "文件路径:%s 不存在" % filefullpath print "需要修改日志文件的程序个数为:%s 名称如下:" % len(modifyappname)
for tempname in modifyappname:
print tempname def replacepath(temp_appname, temp_filepath, temp_keyword, temp_newword, ismodify=False): # 打开文件
file1 = open(temp_filepath, 'r') # 这里不能直接使用传递过来的keyword进行搜索是因为这里需要一个正则表达式。字符串虽然是一个特殊的正则表达式,但是因为有特殊符号需要转义
# 这里的含义是读取文件整体内容,并对内容进行搜索查找符合表达式的内容,把找到的放到变量中,这是一个列表
allchars = re.findall("\$\{CATALINA_OUT\}", file1.read())
# 统计列表长度,这样就获取了匹配的个数
count = len(allchars)
print "关键字 %s 在程序 %s 出现次数: %s" % (temp_keyword, temp_appname, count) # 如果count大于0,表示这个文件里面有我们要替换的字符,如果不大于0则退出该函数
if count > 0:
ismodify = True
else:
file1.close()
return ismodify # 移动指针到文件首部
file1.seek(0)
# 读取所有内容
alllines = file1.readlines()
# 关闭文件流
file1.close() # 设置正则
p = re.compile("\$\{CATALINA_OUT\}")
# 以写模式打开文件,因为这里是同一个文件,所以w参数会清空该文件,这样就实现了在同一个文件中查找和替换
file2 = open(temp_filepath, 'w')
# 遍历之前的所有内容
for line in alllines:
try:
# 使用sub进行替换,p对象包含正则也就是需要匹配的内容,temp_newword是新内容,line是在哪里进行查找匹配
c = p.sub(temp_newword, line)
# c 对象为替换后的新内容,然后写入文件
file2.write(c)
except IOError as err:
print "文件写入错误:"+str(err)
file2.close() ismodify = True
return ismodify if __name__ == "__main__":
sys.exit(main())
我上面采取的方式就是全部读取到内存,然后进行处理最后写入。如果文件很大怎么办呢?
如果文件过大你可以一次读取一部分然后进行修改或者用上面提到的文件迭代器,修改后保存到一个新文件,然后在读取一部分修改后追加到那个新文件,所有修改和保存完成之后,删除原文件把新文件重命名为原来的文件名。
5. 额外的基础知识
延迟写入:磁盘是低速设备,内存是高速设备,如果高速设备向低速设备写入数据那根据木桶原理其速度不会高于短板,所以程序就会等待,那么系统中通常有很多服务如果是一个对外提供服务的服务器那么写入数据的操作一定少不了,如果都实时写入磁盘那性能将会非常地下。所以所有写入都先写入buffer也就是缓存,然后由系统来觉得什么时候把缓存中的数据同步到磁盘上。通常来说缓存写满了就会进行一次同步或者在到了一个同步周期也会进行同步。这就是为什么会有flush()的原因。你可以尝试一下,当你调用完write(),然后让程序睡眠一下,你去查看原来的文件一定没有你写入的数据。
Python读写文件你真的了解吗?的更多相关文章
- [Python]读写文件方法
http://www.cnblogs.com/lovebread/archive/2009/12/24/1631108.html [Python]读写文件方法 http://www.cnblogs.c ...
- Python读写文件
Python读写文件1.open使用open打开文件后一定要记得调用文件对象的close()方法.比如可以用try/finally语句来确保最后能关闭文件. file_object = open('t ...
- Python读写文件实际操作的五大步骤
Python读写文件在计算机语言中被广泛的应用,如果你想了解其应用的程序,以下的文章会给你详细的介绍相关内容,会你在以后的学习的过程中有所帮助,下面我们就详细介绍其应用程序. 一.打开文件 Pytho ...
- python的re模块一些方法 && Tkinter图形界面设计 && 终止python运行函数 && python读写文件 && python一旦给字符串赋值就不能单独改变某个字符,除非重新给变量赋值
Tkinter图形界面设计见:https://www.cnblogs.com/pywjh/p/9527828.html#radiobutton 终止python运行函数: 采用sys.exit(0)正 ...
- Python 读写文件的正确方式
当你用 Python 写程序时,不论是简单的脚本,还是复杂的大型项目,其中最常见的操作就是读写文件.不管是简单的文本文件.繁杂的日志文件,还是分析图片等媒体文件中的字节数据,都需要用到 Python ...
- python 读写文件和设置文件的字符编码
一. python打开文件代码如下: f = open("d:\test.txt", "w") 说明:第一个参数是文件名称,包括路径:第二个参数是打开的模式mo ...
- Python读写文件乱码问题
对开发者来说,最恼人的问题之一莫过于读写文件的时候,由于编码千差万别,出现乱码问题.好难快速解决啊... 最近我也遇到了这样的问题,经研究,把大致的解决思路拿出来共享. 1. python中习惯首先声 ...
- 从用python自动生成.h的头文件集合和类声明集合到用python读写文件
最近在用python自动生成c++的类.因为这些类会根据需求不同产生不同的类,所以需要用python自动生成.由于会产生大量的类,而且这些类是变化的.所以如果是在某个.h中要用include来加载这些 ...
- Python 读写文件操作
python进行文件读写的函数是open或file file_handler = open(filename,,mode) Table mode 模式 描述 r 以读方式打开文件,可读取文件信息. w ...
随机推荐
- CentOS下SVN服务的启动与关闭
CentOS下SVN服务的启动与关闭 操作系统:CentOS 6.5 SVN版本:1.8.11 启动SVN服务: svnserve -d -r /home/svn /home/svn 为版本库的根 ...
- Python序列化proto中repeated修饰的数据
一.repeated修饰复合数据结构,即message时 1.使用message的add方法初始化新实例 2.分别对新实例中的每个元素赋值:或使用CopyFrom(a)拷贝a中的元素值 message ...
- CMD 中常见命令
引自百度经验:https://jingyan.baidu.com/article/67508eb41d44a09cca1ce4f1.html ipConfig:查询ip ping:查询连接速度: pi ...
- webpack学习--安装
webpack需要在node环境运行,可以去node官网进行下载安装包:http://nodejs.cn/download/ 1.打开cmd命令窗口,运行node -v 2.全局安装webpack:n ...
- css实用属性
background-size: 100% 100%; 背景通过拉伸实现填充 自适应 overflow: hidden; ...
- 航班座位_hihocoder
题目2 : 航班座位 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi在给一个家庭旅游团订某次航班的机票.该航班的飞机一共有N排座位,每排座位有10个座位,从左到右 ...
- CrypMic分析报告
一.概述 病毒伪装为NirSoft公司的软件NirCmd并加了MPRESS壳,脱壳后是一个混淆过的PE程序,运行时会用到类似PE映像切换的方式来释放出实际的恶意代码,恶意代码主要对文件进行加密. 二. ...
- idea导入maven项目,找不到jar包,出现红色波浪线【转】
参考链接 点击跳转
- 企业IT管理员IE11升级指南【14】—— IE11代理服务器配置
企业IT管理员IE11升级指南 系列: [1]—— Internet Explorer 11增强保护模式 (EPM) 介绍 [2]—— Internet Explorer 11 对Adobe Flas ...
- Asp.Net Core中使用Swagger,你不得不踩的坑
很久不来写blog了,换了新工作后很累,很忙.每天常态化加班到21点,偶尔还会到凌晨,加班很累,但这段时间,也确实学到了不少知识,今天这篇文章和大家分享一下:Asp.Net Core中使用Swagge ...