论文笔记:AdaScale: Towards real-time video object detection using adaptive scalingAdaScale
AdaScale: Towards real-time video object detection using adaptive scaling
2019-02-18 16:14:17
Paper: https://www.sysml.cc/papers.html
本文提出一种新的技术,AdaScale,来改善视频中物体检测的尺度问题,在提升速度的同时,改善了精度。
作者的实验发现在降低图像分辨率的时候,部分图像的识别精度就会得到改善,并且给出了结果展示:

那么是什么原因导致这种情况呢?作者给出了如下的解释:
i) Reducing the number of false positives that may be introduced by focusing on unnecessary details.
ii) Increasing the number of true positives by scaling the objects that are too large to a size at which the object detector is more confident.
受到这种现象的启发,作者提出通过 “re-size” 图像的方式以得到其最优的 scale,来提升检测的速度和精度。所以,本文提出 AdaScale 来根据当前帧的信息来预测下一阵的最佳的 scale。并且在 ImageNet VID 和 mini YouTube-BB datasets 上同时提升了速度和精度。
其训练和测试过程,如下图所示:

3.1. Optimal Scale:
作者首先定义一个 scale 集合 {600,480,360,240} ,并且定一个度量标准来衡量不同尺寸的检测效果。作者这里采用的是最终的 loss function。总得来说,物体检测的损失函数可以分为包围盒的回归和分类损失:
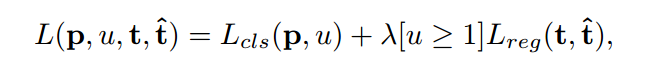
但是,直接用这种方法,也有一个 bug:对于重合度较低的 proposal,会自动归类为 background,该损失函数自动将 regression loss 设置为 0,直接用该指标衡量不同图像尺寸会支持含有较少前景包围盒的图像尺寸(will favor the image scale with fewer foreground bounding boxes)。
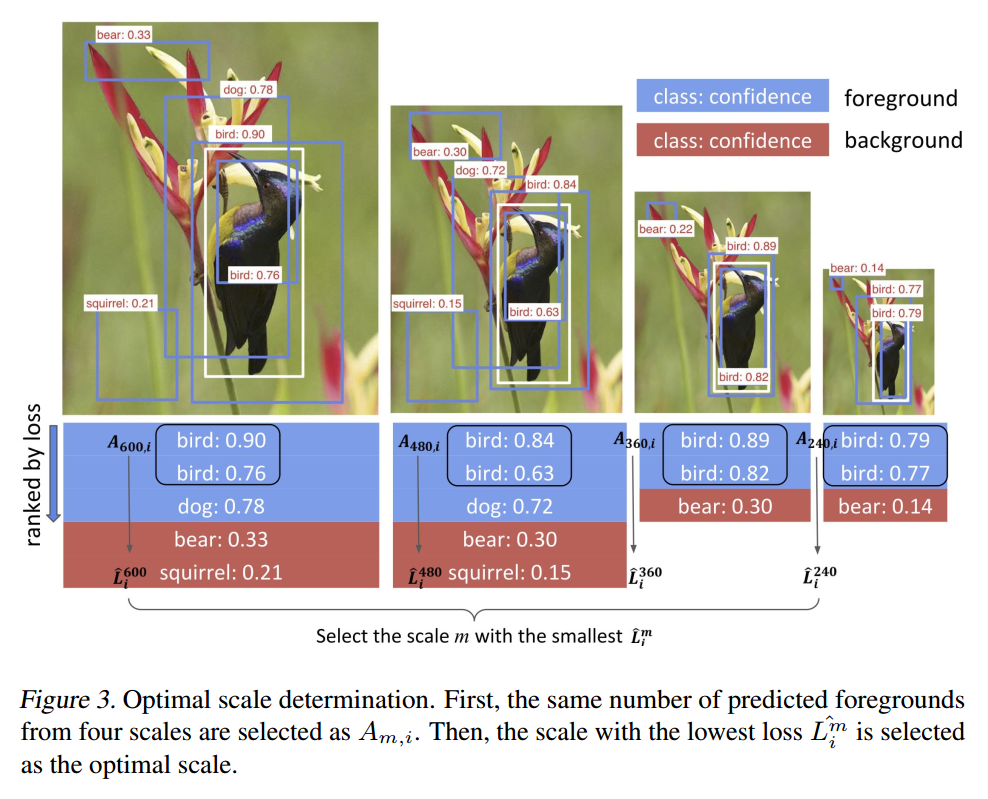
所以,为了处理该问题,作者提出一种新的度量方法来聚焦于拥有相同数量的前景包围盒,来比较不同的图像尺寸。具体来说,
用 $L^m_{i, a}$ 表示 利用上述公式计算得到的 image i 的预测包围盒 a 在 scale m 的损失;
$\hat{L_i^m}$ 表示图像 i 在尺寸 m 的损失,作为我们的提出的指标。
为了得到 $\hat{L_i^m}$,我们首先计算预测的前景包围盒的数量 $n_{m, i}$,对于图像 i 的每一个尺寸 m,使得 $n_{min, i} = min_{m}(n_{m, i}).$
所以,所提出的度量标准可以通过如下的方法计算得到:
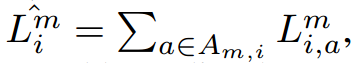
为了得到 $A_{m, i}$,对于每一个 scale,我们对预测的前景包围盒进行排序,并且挑选出前 $n_{min, i}$ 添加到 $A_{m, i}$。
有了这个度量标准,我们就可以定义最优尺寸:
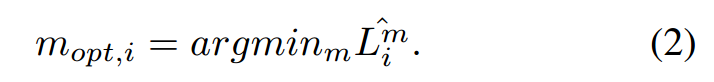
3.2. Scale Regressor:
作者采用的 RFCN 是依赖于最后一层卷积层特征的,作者认为该深度特征的通道已经包含了尺寸的信息。所以,可以利用该深度特征直接构建 scale regressor 来预测最优的尺寸,如图4所示。
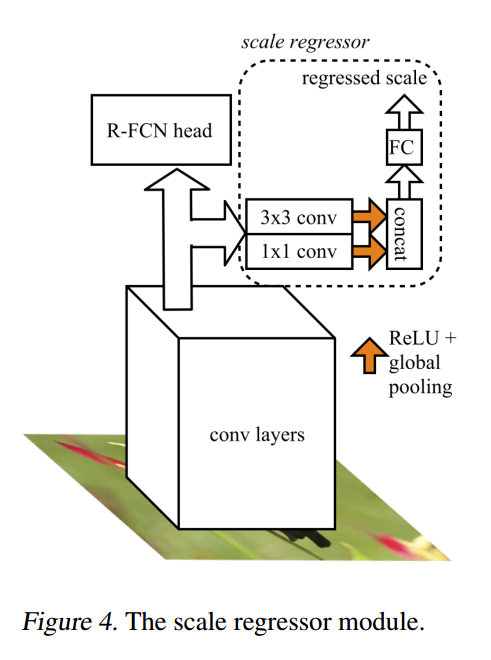
作者用 1*1 卷积来捕获不同特征图的尺寸信息 (the size information from different feature maps),用 3*3 卷积来捕获特征图上的复杂度(the complexity of each 3*3 patch in the fature maps)。这些特征在经过 ReLU 和 global pooling 之后,进行组合,输入到 fc 层,进行回归。需要注意的是,本文不是直接进行最优尺寸的估计,而是回归一个相对尺寸,使得模型可以学会 react (up-sample,down-sample,or stay the same)。对于图像 i 来说,回归尺寸的目标是:
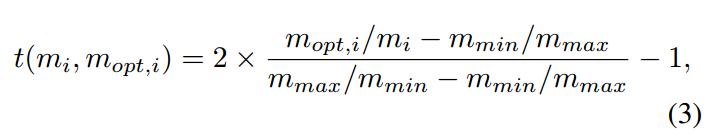
其中,$m_i$ 是 是图像 i 的尺寸,$m_{min}$ 是定义的最小尺寸,$m_{max}$ 是定义的最大尺寸。所以,我们是要回归出一个归一化的范围(relative scales): [-1, 1]。
在训练数据集上,我们利用公式(2)得到需要回归的标签。并且采用均方误差来进行回归:
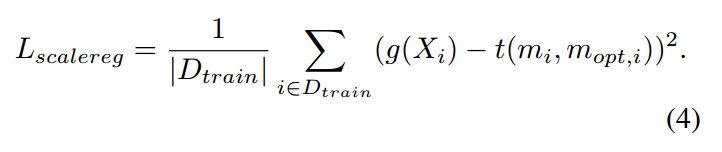

==
论文笔记:AdaScale: Towards real-time video object detection using adaptive scalingAdaScale的更多相关文章
- 论文笔记:Learning Region Features for Object Detection
中心思想 继Relation Network实现可学习的nms之后,MSRA的大佬们觉得目标检测器依然不够fully learnable,这篇文章类似之前的Deformable ROI Pooling ...
- video object detection
先说一下,我觉得近两年最好的工作吧.其他的,我就不介绍了,因为我懂得少. 微软的jifeng dai的工作. Deep Feature Flow github: https://github.co ...
- 论文阅读笔记三十五:R-FCN:Object Detection via Region-based Fully Convolutional Networks(CVPR2016)
论文源址:https://arxiv.org/abs/1605.06409 开源代码:https://github.com/PureDiors/pytorch_RFCN 摘要 提出了基于区域的全卷积网 ...
- 论文阅读笔记七:Structure Inference Network:Object Detection Using Scene-Level Context and Instance-Level Relationships(CVPR2018)
结构推理网络:基于场景级与实例级目标检测 原文链接:https://arxiv.org/abs/1807.00119 代码链接:https://github.com/choasup/SIN Yong ...
- [论文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation 概括 这是一篇2016年的目标检测 ...
- Flow-Guided Feature Aggregation for Video Object Detection论文笔记
摘要 目前检测的准确率受物体视频中变化的影响,如运动模糊,镜头失焦等.现有工作是想要在框的级别上寻找时序信息,但这样的方法通常不能端到端训练.我们提出了flow-guided feature aggr ...
- 论文笔记:Fully-Convolutional Siamese Networks for Object Tracking
Fully-Convolutional Siamese Networks for Object Tracking 本文作者提出一个全卷积Siamese跟踪网络,该网络有两个分支,一个是上一帧的目标,一 ...
- 论文笔记-Deep Affinity Network for Multiple Object Tracking
作者: ShijieSun, Naveed Akhtar, HuanShengSong, Ajmal Mian, Mubarak Shah 来源: arXiv:1810.11780v1 项目:http ...
- 【CV论文阅读】YOLO:Unified, Real-Time Object Detection
YOLO的一大特点就是快,在处理上可以达到完全的实时.原因在于它整个检测方法非常的简洁,使用回归的方法,直接在原图上进行目标检测与定位. 多任务检测: 网络把目标检测与定位统一到一个深度网络中,而且可 ...
随机推荐
- less的使用(好文章)
好文章链接:30分钟学会less 自己总结一下这篇文章中的几个关键字:变量.混合.函数.嵌套.@import 下面贴上自己照着上面写的一些代码: <template> <div cl ...
- 10个用于处理日期和时间的 Python 库
Python本身提供了处理时间日期的功能,也就是datetime标准库.除此之外,还有很多优秀的第三方库可以用来转换日期格式,格式化,时区转化等等.今天就给大家分享10个这样的Python库. 上期入 ...
- 一、初识CocoaPods——XCode的依赖库管理工具
概述 任意一款功能完整的APP,其中所涉及的内容都将是来自各个领域各个方面的.如果每个领域的每个方面都要重新开发并给予充分测试,那么1个APP的开发周期将会变得非常漫长,长到足以让房价再涨一倍,长到足 ...
- phpstorm----------phpstorm如何安装和使用laravel plugin
1.安装 2.安装成功以后,删除项目里面的.idea文件.然后关闭phpstrom,重新打开该项目,就会提示你 然后.idea里面就会生成 laravel-plugin.xml 文件.就可以使用直接C ...
- 解决:启用多线程调用webBrowsers函数报错:指定的转换无效
这里就需要委托. 定义一个 委托.加载之后给他绑定一个方法Callback,也就是所说的回掉函数. 然后写一个线程,线程需要一个object 的参数.将你定义的委托当作参数传进线程中的方法. 在线程中 ...
- nuget包管理nuget服务器发布包时出现请求报错 406 (Not Acceptable)
在window服务器上部署nuget服务器时,发布包时出现请求报错 406 (Not Acceptable) 验证用户名.密码正确的情况下,还是出现上面错误.后面跟踪服务器日志,发现window\te ...
- 前端学习历程--http与https
一.CA(证书授权中心)证书 1.ca是通信的中介,具有足够的权威性 2.信任可嵌套如:C 信任 A1,A1 信任 A2,A2 信任 A3 二.根本区别 1.https需要基于ssl的ca证书认证(判 ...
- 【转】jenkins自动化部署项目7 -- 新建job(将服务代码部署在windows上)
关于构建结束后jenkins会kill所有衍生子进程的官方解决方案:https://wiki.jenkins.io/display/JENKINS/Spawning+processes+from+bu ...
- Redmine(window7)安装
首先要准备Ruby相关文件,Redmine是基于Ruby on rails开发的. 1.下载railsinstaller,我这时下载的版本是railsinstaller-2.2.1.exe,对应的官网 ...
- 微信小程序将网络图片转化为base64
网络图片需用wx.downloadFile下载,然后调用微信自带的base64转化 可能会存在兼容, let image_to_base64 = function(img){ return new P ...