Java SpringBoot集成RabbitMq实战和总结
在公司里一直在用RabbitMQ,由于api已经封装的很简单,关于RabbitMQ本身还有封装的实现没有了解,最近在看RabbitMQ实战这本书,结合网上的一些例子和spring文档,实现了RabbitMQ和spring的集成,对着自己平时的疑惑做了一些总结。
关于RabbitMQ基础不在详细讲解(本文不适合RabbitMq零基础),RabbitMQ实战的1,2,4三章讲的非常不错。因为书中讲的都是Python和Php的例子,所以自己结合SpringBoot文档和朱小厮的博客做了一些总结,写了一些Springboot的例子。
交换器、队列、绑定的声明
SpringAMQP项目对RabbitMQ做了很好的封装,可以很方便的手动声明队列,交换器,绑定。如下:
/**
* 队列
* @return
*/
@Bean
@Qualifier(RabbitMQConstant.PROGRAMMATICALLY_QUEUE)
Queue queue() {
return new Queue(RabbitMQConstant.PROGRAMMATICALLY_QUEUE, false, false, true);
}
/**
* 交换器
* @return
*/
@Bean
@Qualifier(RabbitMQConstant.PROGRAMMATICALLY_EXCHANGE)
TopicExchange exchange() {
return new TopicExchange(RabbitMQConstant.PROGRAMMATICALLY_EXCHANGE, false, true);
}
/**
* 声明绑定关系
* @return
*/
@Bean
Binding binding(@Qualifier(RabbitMQConstant.PROGRAMMATICALLY_EXCHANGE) TopicExchange exchange,
@Qualifier(RabbitMQConstant.PROGRAMMATICALLY_QUEUE) Queue queue) {
return BindingBuilder.bind(queue).to(exchange).with(RabbitMQConstant.PROGRAMMATICALLY_KEY);
}
/**
* 声明简单的消费者,接收到的都是原始的{@link Message}
*
* @param connectionFactory
*
* @return
*/
@Bean
SimpleMessageListenerContainer simpleContainer(ConnectionFactory connectionFactory) {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.setMessageListener(message -> log.info("simple receiver,message:{}", message));
container.setQueueNames(RabbitMQConstant.PROGRAMMATICALLY_QUEUE);
return container;
}
消费者和生产者都可以声明,交换器这种一般经常创建,可以手动创建。需要注意对于没有路由到队列的消息会被丢弃。
如果是Spring的话还需要声明连接:
@Bean
ConnectionFactory connectionFactory(@Value("${spring.rabbitmq.port}") int port,
@Value("${spring.rabbitmq.host}") String host,
@Value("${spring.rabbitmq.username}") String userName,
@Value("${spring.rabbitmq.password}") String password,
@Value("${spring.rabbitmq.publisher-confirms}") boolean isConfirm,
@Value("${spring.rabbitmq.virtual-host}") String vhost) {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
connectionFactory.setHost(host);
connectionFactory.setVirtualHost(vhost);
connectionFactory.setPort(port);
connectionFactory.setUsername(userName);
connectionFactory.setPassword(password);
connectionFactory.setPublisherConfirms(isConfirm);
}
在配置类使用@EnableRabbit的情况下,也可以基于注解进行声明,在Bean的方法上加上@RabbitListener,如下:
/**
* 可以直接通过注解声明交换器、绑定、队列。但是如果声明的和rabbitMq中已经存在的不一致的话
* 会报错便于测试,我这里都是不使用持久化,没有消费者之后自动删除
* {@link RabbitListener}是可以重复的。并且声明队列绑定的key也可以有多个.
*
* @param headers
* @param msg
*/
@RabbitListener(
bindings = @QueueBinding(
exchange = @Exchange(value = RabbitMQConstant.DEFAULT_EXCHANGE, type = ExchangeTypes.TOPIC,
durable = RabbitMQConstant.FALSE_CONSTANT, autoDelete = RabbitMQConstant.true_CONSTANT),
value = @Queue(value = RabbitMQConstant.DEFAULT_QUEUE, durable = RabbitMQConstant.FALSE_CONSTANT,
autoDelete = RabbitMQConstant.true_CONSTANT),
key = DKEY
),
//手动指明消费者的监听容器,默认Spring为自动生成一个SimpleMessageListenerContainer
containerFactory = "container",
//指定消费者的线程数量,一个线程会打开一个Channel,一个队列上的消息只会被消费一次(不考虑消息重新入队列的情况),下面的表示至少开启5个线程,最多10个。线程的数目需要根据你的任务来决定,如果是计算密集型,线程的数目就应该少一些
concurrency = "5-10"
)
public void process(@Headers Map<String, Object> headers, @Payload ExampleEvent msg) {
log.info("basic consumer receive message:{headers = [" + headers + "], msg = [" + msg + "]}");
}
/**
* {@link Queue#ignoreDeclarationExceptions}声明队列会忽略错误不声明队列,这个消费者仍然是可用的
*
* @param headers
* @param msg
*/
@RabbitListener(queuesToDeclare = @Queue(value = RabbitMQConstant.DEFAULT_QUEUE, ignoreDeclarationExceptions = RabbitMQConstant.true_CONSTANT))
public void process2(@Headers Map<String, Object> headers, @Payload ExampleEvent msg) {
log.info("basic2 consumer receive message:{headers = [" + headers + "], msg = [" + msg + "]}");
}
关于消息序列化
这个比较简单,默认采用了Java序列化,我们一般使用的Json格式,所以配置了Jackson,根据自己的情况来,直接贴代码:
@Bean
MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}
同一个队列多消费类型
如果是同一个队列多个消费类型那么就需要针对每种类型提供一个消费方法,否则找不到匹配的方法会报错,如下:
@Component
@Slf4j
@RabbitListener(
bindings = @QueueBinding(
exchange = @Exchange(value = RabbitMQConstant.MULTIPART_HANDLE_EXCHANGE, type = ExchangeTypes.TOPIC,
durable = RabbitMQConstant.FALSE_CONSTANT, autoDelete = RabbitMQConstant.true_CONSTANT),
value = @Queue(value = RabbitMQConstant.MULTIPART_HANDLE_QUEUE, durable = RabbitMQConstant.FALSE_CONSTANT,
autoDelete = RabbitMQConstant.true_CONSTANT),
key = RabbitMQConstant.MULTIPART_HANDLE_KEY
)
)
@Profile(SpringConstant.MULTIPART_PROFILE)
public class MultipartConsumer {
/**
* RabbitHandler用于有多个方法时但是参数类型不能一样,否则会报错
*
* @param msg
*/
@RabbitHandler
public void process(ExampleEvent msg) {
log.info("param:{msg = [" + msg + "]} info:");
}
@RabbitHandler
public void processMessage2(ExampleEvent2 msg) {
log.info("param:{msg2 = [" + msg + "]} info:");
}
/**
* 下面的多个消费者,消费的类型不一样没事,不会被调用,但是如果缺了相应消息的处理Handler则会报错
*
* @param msg
*/
@RabbitHandler
public void processMessage3(ExampleEvent3 msg) {
log.info("param:{msg3 = [" + msg + "]} info:");
}
}
注解将消息和消息头注入消费者方法
在上面也看到了@Payload等注解用于注入消息。这些注解有:
- @Header 注入消息头的单个属性
- @Payload 注入消息体到一个JavaBean中
- @Headers 注入所有消息头到一个Map中
这里有一点主要注意,如果是com.rabbitmq.client.Channel,org.springframework.amqp.core.Message和org.springframework.messaging.Message这些类型,可以不加注解,直接可以注入。
如果不是这些类型,那么不加注解的参数将会被当做消息体。不能多于一个消息体。如下方法ExampleEvent就是默认的消息体:
public void process2(@Headers Map<String, Object> headers,ExampleEvent msg);
关于消费者确认
RabbitMq消费者可以选择手动和自动确认两种模式,如果是自动,消息已到达队列,RabbitMq对无脑的将消息抛给消费者,一旦发送成功,他会认为消费者已经成功接收,在RabbitMq内部就把消息给删除了。另外一种就是手动模式,手动模式需要消费者对每条消息进行确认(也可以批量确认),RabbitMq发送完消息之后,会进入到一个待确认(unacked)的队列,如下图红框部分:
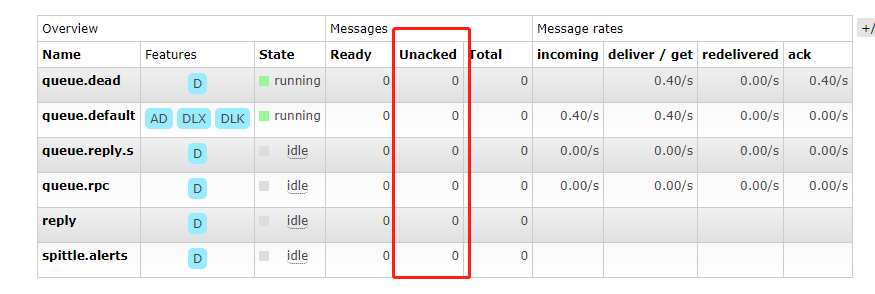
如果消费者发送了ack,RabbitMq将会把这条消息从待确认中删除。如果是nack并且指明不要重新入队列,那么该消息也会删除。但是如果是nack且指明了重新入队列那么这条消息将会入队列,然后重新发送给消费者,被重新投递的消息消息头amqp_redelivered属性会被设置成true,客户端可以依靠这点来判断消息是否被确认,可以好好利用这一点,如果每次都重新回队列会导致同一消息不停的被发送和拒绝。消费者在确认消息之前和RabbitMq失去了连接那么消息也会被重新投递。所以手动确认模式很大程度上提高可靠性。自动模式的消息可以提高吞吐量。
spring手动确认消息需要将SimpleRabbitListenerContainerFactory设置为手动模式:
simpleRabbitListenerContainerFactory.setAcknowledgeMode(AcknowledgeMode.MANUAL);
手动确认的消费者代码如下:
@SneakyThrows
@RabbitListener(bindings = @QueueBinding(
exchange = @Exchange(value = RabbitMQConstant.CONFIRM_EXCHANGE, type = ExchangeTypes.TOPIC,
durable = RabbitMQConstant.FALSE_CONSTANT, autoDelete = RabbitMQConstant.true_CONSTANT),
value = @Queue(value = RabbitMQConstant.CONFIRM_QUEUE, durable = RabbitMQConstant.FALSE_CONSTANT,
autoDelete = RabbitMQConstant.true_CONSTANT),
key = RabbitMQConstant.CONFIRM_KEY),
containerFactory = "containerWithConfirm")
public void process(ExampleEvent msg, Channel channel, @Header(name = "amqp_deliveryTag") long deliveryTag,
@Header("amqp_redelivered") boolean redelivered, @Headers Map<String, String> head) {
try {
log.info("ConsumerWithConfirm receive message:{},header:{}", msg, head);
channel.basicAck(deliveryTag, false);
} catch (Exception e) {
log.error("consume confirm error!", e);
//这一步千万不要忘记,不会会导致消息未确认,消息到达连接的qos之后便不能再接收新消息
//一般重试肯定的有次数,这里简单的根据是否已经重发过来来决定重发。第二个参数表示是否重新分发
channel.basicReject(deliveryTag, !redelivered);
//这个方法我知道的是比上面多一个批量确认的参数
// channel.basicNack(deliveryTag, false,!redelivered);
}
}
关于spring的AcknowledgeMode需要说明,他一共有三种模式:NONE,MANUAL,AUTO,默认是AUTO模式。这比RabbitMq原生多了一种。这一点很容易混淆,这里的NONE对应其实就是RabbitMq的自动确认,MANUAL是手动。而AUTO其实也是手动模式,只不过是Spring的一层封装,他根据你方法执行的结果自动帮你发送ack和nack。如果方法未抛出异常,则发送ack。如果方法抛出异常,并且不是AmqpRejectAndDontRequeueException则发送nack,并且重新入队列。如果抛出异常时AmqpRejectAndDontRequeueException则发送nack不会重新入队列。我有一个例子专门测试NONE,见CunsumerWithNoneTest。
还有一点需要注意的是消费者有一个参数prefetch,它表示的是一个Channel(也就是SimpleMessageListenerContainer的一个线程)预取的消息数量,这个参数只会在手动确认的消费者才生效。可以客户端利用这个参数来提高性能和做流量控制。如果prefetch设置的是10,当这个Channel上unacked的消息数量到达10条时,RabbitMq便不会在向你发送消息,客户端如果处理的慢,便可以延迟确认在方法消息的接收。至于提高性能就非常容易理解,因为这个是批量获取消息,如果客户端处理的很快便不用一个一个去等着去新的消息。SpringAMQP2.0开始默认是250,这个参数应该已经足够了。注意之前的版本默认值是1所以有必要重新设置一下值。当然这个值也不能设置的太大,RabbitMq是通过round robin这个策略来做负载均衡的,如果设置的太大会导致消息不多时一下子积压到一台消费者,不能很好的均衡负载。另外如果消息数据量很大也应该适当减小这个值,这个值过大会导致客户端内存占用问题。如果你用到了事务的话也需要考虑这个值的影响,因为事务的用处不大,所以我也没做过多的深究。
关于发送者确认模式
考虑这样一个场景:你发送了一个消息给RabbitMq,RabbitMq接收了但是存入磁盘之前服务器就挂了,消息也就丢了。为了保证消息的投递有两种解决方案,最保险的就是事务(和DB的事务没有太大的可比性), 但是因为事务会极大的降低性能,会导致生产者和RabbitMq之间产生同步(等待确认),这也违背了我们使用RabbitMq的初衷。所以一般很少采用,这就引入第二种方案:发送者确认模式。
发送者确认模式是指发送方发送的消息都带有一个id,RabbitMq会将消息持久化到磁盘之后通知生产者消息已经成功投递,如果因为RabbitMq内部的错误会发送nack。注意这里的发送者和RabbitMq之间是异步的,所以相较于事务机制性能大大提高。其实很多操作都是不能保证绝对的百分之一百的成功,哪怕采用了事务也是如此,可靠性和性能很多时候需要做一些取舍,想很多互联网公司吹嘘的5个9,6个9也是一样的道理。如果不是重要的消息如:性能计数器,完全可以不采用发送者确认模式。
这里有一点我当时纠结了很久,我一直以为发送者确认模式的回调是客户端的ack触发的,这里是大大的误解!发送者确认模式和消费者没有一点关系,消费者确认也和发送者没有一点关系,两者都是在和RabbitMq打交道,发送者不会管消费者有没有收到,只要消息到了RabbitMq并且已经持久化便会通知生产者,这个ack是RabbitMq本身发出的,和消费者无关
发送者确认模式需要将Channel设置成Confirm模式,这样才会收到通知。Spring中需要将连接设置成Confirm模式:
connectionFactory.setPublisherConfirms(isConfirm);
然后在RabbitTemplate中设置确认的回调,correlationData是消息的id,如下(只是简单打印下):
// 设置RabbitTemplate每次发送消息都会回调这个方法
rabbitTemplate.setConfirmCallback((correlationData, ack, cause)
-> log.info("confirm callback id:{},ack:{},cause:{}", correlationData, ack, cause));
发送时需要给出唯一的标识(CorrelationData):
rabbitTemplateWithConfirm.convertAndSend(RabbitMQConstant.DEFAULT_EXCHANGE, RabbitMQConstant.DEFAULT_KEY,
new ExampleEvent(i, "confirm message id:" + i),
new CorrelationData(Integer.toString(i)));
还有一个参数需要说下:mandatory。这个参数为true表示如果发送消息到了RabbitMq,没有对应该消息的队列。那么会将消息返回给生产者,此时仍然会发送ack确认消息。
设置RabbitTemplate的回调如下:
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey)
-> log.info("return callback message:{},code:{},text:{}", message, replyCode, replyText));
另外如果是RabbitMq内部的错误,不会调用该方法。所以如果消息特别重要,对于未确认的消息,生产者应该在内存用保存着,在确认时候根据返回的id删除该消息。如果是nack可以将该消息记录专门的日志或者转发到相应处理的逻辑进行后续补偿。RabbitTemplate也可以配置RetryTemplate,发送失败时直接进行重试,具体还是要结合业务。
最后关于发送者确认需要提的是spring,因为spring默认的Bean是单例的,所以针对不同的确认方案(其实有不同的确认方案是比较合理的,很多消息不需要确认,有些需要确认)需要配置不同的bean.
消费消息、死信队列和RetryTemplate
上面也提到了如果消费者抛出异常时默认的处理逻辑。另外我们还可以给消费者配置RetryTemplate,如果是采用SpringBoot的话,可以在application.yml配置中配置如下:
spring:
rabbitmq:
listener:
retry:
# 重试次数
max-attempts: 3
# 开启重试机制
enabled: true
如上,如果消费者失败的话会进行重试,默认是3次。注意这里的重试机制RabbitMq是为感知的!到达3次之后会抛出异常调用MessageRecoverer。默认的实现为RejectAndDontRequeueRecoverer,也就是打印异常,发送nack,不会重新入队列。
我想既然配置了重试机制消息肯定是很重要的,消息肯定不能丢,仅仅是日志可能会因为日志滚动丢失而且信息不明显,所以我们要讲消息保存下来。可以有如下这些方案:
- 使用RepublishMessageRecoverer这个MessageRecoverer会发送发送消息到指定队列
- 给队列绑定死信队列,因为默认的RepublishMessageRecoverer会发送nack并且requeue为false。这样抛出一场是这种方式和上面的结果一样都是转发到了另外一个队列。详见DeadLetterConsumer
- 注册自己实现的MessageRecoverer
- 给MessageListenerContainer设置RecoveryCallback
- 对于方法手动捕获异常,进行处理
我比较推荐前两种。这里说下死信队列,死信队列其实就是普通的队列,只不过一个队列声明的时候指定的属性,会将死信转发到该交换器中。声明死信队列方法如下:
@RabbitListener(
bindings = @QueueBinding(
exchange = @Exchange(value = RabbitMQConstant.DEFAULT_EXCHANGE, type = ExchangeTypes.TOPIC,
durable = RabbitMQConstant.FALSE_CONSTANT, autoDelete = RabbitMQConstant.true_CONSTANT),
value = @Queue(value = RabbitMQConstant.DEFAULT_QUEUE, durable = RabbitMQConstant.FALSE_CONSTANT,
autoDelete = RabbitMQConstant.true_CONSTANT, arguments = {
@Argument(name = RabbitMQConstant.DEAD_LETTER_EXCHANGE, value = RabbitMQConstant.DEAD_EXCHANGE),
@Argument(name = RabbitMQConstant.DEAD_LETTER_KEY, value = RabbitMQConstant.DEAD_KEY)
}),
key = RabbitMQConstant.DEFAULT_KEY
))
其实也就只是在声明的时候多加了两个参数x-dead-letter-exchange和x-dead-letter-routing-key。这里一开始踩了一个坑,因为@QueueBinding注解中也有arguments属性,我一开始将参数声明到@QueueBinding中,导致一直没绑定成功。如果绑定成功可以在控制台看到queue的Featrues有DLX(死信队列交换器)和DLK(死信队列绑定)。如下:
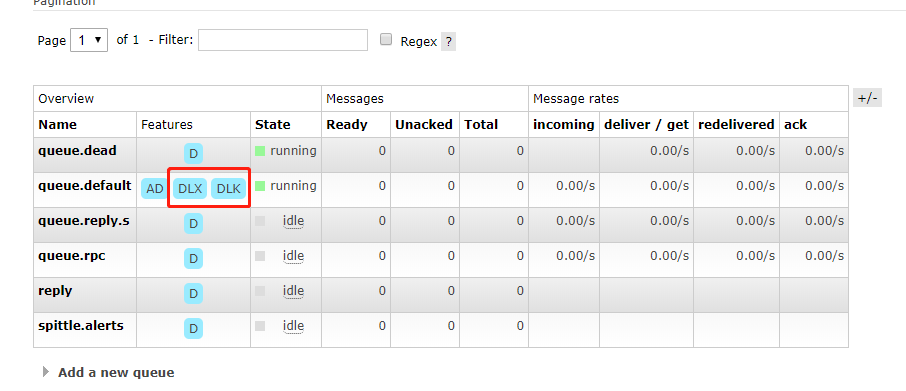
- 消息被拒绝(basic.reject/basic.nack)并且requeue=false
- 消息TTL过期
- 队列达到最大长度
我们用到的就是第一种。
RPC模式的消息(不常用)
本来生产者和消费者是没有耦合的,但是可以通过一些属性产生耦合。在早期版本中,如果一个生产者想要收到消费者的回复,实现方案是生产者在消息头中加入reply-to属性也就是队列(一般是私有,排他,用完即销毁)的名字,然后在这个队列上进行监听,消费者将回复发送到这个队列中。RabbitMq3.3之后有了改进,就是不用没有都去创建一个临时队列,这样很耗费性能,可以采用drect-to模式,省去了每次创建队列的性能损耗,但是还是要创建一次队列。现在Spring默认的就是这个模式。RabbitTemplate中有一系列的sendAndReceiveXX方法。默认等待5秒,超时返回null。用
法和不带返回的差不多。
消费者的方法通过返回值直接返回消息(下面的方法是有返回值的):
public String receive(@Headers Map<String, Object> headers, @Payload ExampleEvent msg) {
log.info("reply to consumer param:{headers = [" + headers + "], msg = [" + msg + "]} info:");
return REPLY;
}
这里的提一下最后一个注解@SendTo,用在消费方法上,指明返回值的目的地,默认不用的话就是返回给发送者,可以通过这个注解改变这种行为。如下代码:
@RabbitListener(
bindings = @QueueBinding(
exchange = @Exchange(value = RabbitMQConstant.REPLY_EXCHANGE, type = ExchangeTypes.TOPIC,
durable = RabbitMQConstant.FALSE_CONSTANT, autoDelete = RabbitMQConstant.true_CONSTANT),
value = @Queue(value = RabbitMQConstant.REPLY_QUEUE, durable = RabbitMQConstant.FALSE_CONSTANT,
autoDelete = RabbitMQConstant.true_CONSTANT),
key = RabbitMQConstant.REPLY_KEY
)
)
@SendTo("queue.reply.s")
public ExampleEvent log(ExampleEvent event) {
log.info("log receive message:O{}", event);
return new ExampleEvent(1, "log result");
}
上面的代码就是会将消息直接发送到默认交换器,并且以queue.reply.s作为路由键。@SendTo的格式为exchange/routingKey用法如下:
- foo/bar: 指定的交换器和key
- foo/: 指定的交换器,key为空
- bar或者/bar: 到空交换器
- /或者空:空的交换器和空的key
这里还需要提一下,因为默认所有的队列都会绑定到空交换器,并且以队列名字作为Routekey, 所以SendTo里面可以直接填写队列名字机会发送到相应的队列.如日志队列。因为RPC模式不常用,专业的东西做专业的事,就像我们一般不用Redis来做消息队列一样(虽然他也可以实现),一般公司都有特定的技术栈,肯定有更合适的RPC通信框架。当然如果要跨语言的集成这个方案也是一种不错的方案,可以继续考虑采用异步发送AsyncRabbitTemplate来降低延迟等优化方案!
关于消费模型
RabbitMQ底层的消费模型有两种Push和Pull。我在网上查阅资料的时候发现有很多教程采用了pull这种模式。RabbitMq实战和
RabbitMQ之Consumer消费模式(Push & Pull)都指出这种模式性能低,会影响消息的吞吐量,增加不必要的IO,所以除非有特殊的业务需求,不要采用这种方案。Spring的封装就是采用了push的方案。
关于RabbitMq客户端的线程模型
这里讲的是消费者的,生产者没什么好讲的。先看消息流转图:
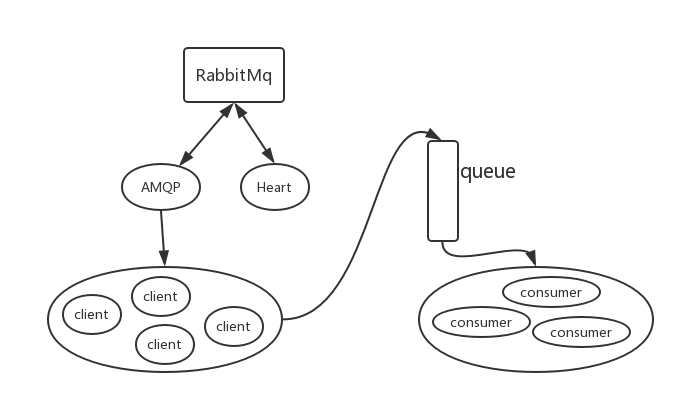
图中椭圆表示线程,矩形是队列。消息到达AMQP的连接线程,然后分发到client线程池,随后分发到监听器。注意除了监听器的线程,其他都是在com.rabbitmq.client.impl.AMQConnection中创建的线程,我们对线程池做一些修改。连接线程名字不能修改就是AMQP Connection打头。心跳线程可以设置setConnectionThreadFactory来设置名字。如下:
connectionFactory.setConnectionThreadFactory(new ThreadFactory() {
public final AtomicInteger id = new AtomicInteger();
@Override
public Thread newThread(Runnable r) {
return new Thread(r, MessageFormat.format("amqp-heart-{0}", id.getAndIncrement()));
}
});
client线程池见:com.rabbitmq.client.impl.ConsumerWorkService构造方法。Executors.newFixedThreadPool(DEFAULT_NUM_THREADS, threadFactory)。
final ExecutorService executorService = Executors.newFixedThreadPool(5, new ThreadFactory() {
public final AtomicInteger id = new AtomicInteger();
@Override
public Thread newThread(Runnable r) {
return new Thread(r, MessageFormat.format("amqp-client-{0}", id.getAndIncrement()));
}
});
listener的线程设置如下:
simpleRabbitListenerContainerFactory.setTaskExecutor(new SimpleAsyncTaskExecutor"amqp-consumer-"));
注意:SimpleAsyncTaskExecutor每次执行一个任务都会新建一个线程,对于生命周期很短的任务不要使用这个线程池(如client线程池的任务), 这里的消费者线程生命周期直到SimpleMessageListenerContainer停止所以比较适合这个场景
修改过之后的线程如下:
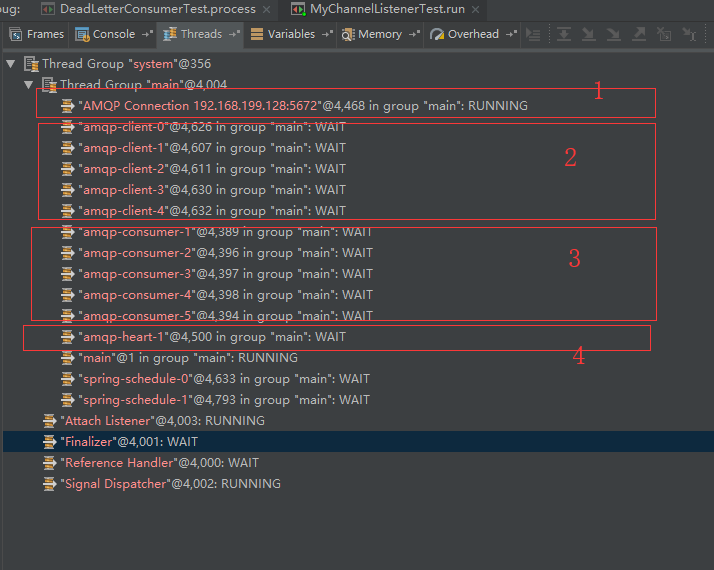
消息投递过程如下:
- 在AMQConnection中开启连接线程,该线程用于处理和RabbitMq的通信:
public void startMainLoop() {
MainLoop loop = new MainLoop();
final String name = "AMQP Connection " + getHostAddress() + ":" + getPort();
mainLoopThread = Environment.newThread(threadFactory, loop, name);
mainLoopThread.start();
}
- AMQConnection.heartbeatExecutor是心跳线程。
- AMQConnection.consumerWorkServiceExecutor则是用来处理事件的线程池,AMQConnection线程收到消息投递到这里。
分发逻辑详见com.rabbitmq.client.impl.ChannelN#processAsync->com.rabbitmq.client.impl.ConsumerDispatcher#handleDelivery->投递到线程池. - 线程池中继续将消息投递到org.springframework.amqp.rabbit.listener.BlockingQueueConsumer#queue中
- consumer线程进行最终消息
上面的是默认的消费者监听器。SpringAMQP 2.0引入了一个新的监听器实现DirectMessageListenerContainer。这个实现最大的变化在于消费者的处理逻辑不是在自己的线程池中执行而是直接在client线程池中处理,这样最明显的是省去了线程的上下文切换的开销,而且设计上也变得更为直观。所以如果采用这个监听器需要覆盖默认的线程池加大Connection的线程池。采用这个监听器只需要设置@RabbitListener的containerFactory属性。声明方法如下:
@Bean
DirectRabbitListenerContainerFactory directRabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
final DirectRabbitListenerContainerFactory directRabbitListenerContainerFactory = new DirectRabbitListenerContainerFactory();
directRabbitListenerContainerFactory.setConsumersPerQueue(Runtime.getRuntime().availableProcessors());
directRabbitListenerContainerFactory.setConnectionFactory(connectionFactory);
directRabbitListenerContainerFactory.setMessageConverter(new Jackson2JsonMessageConverter());
directRabbitListenerContainerFactory.setConsumersPerQueue(10);
return directRabbitListenerContainerFactory;
}
这时的消息流转图如下:

还有一些关于监听器的例子和Springboot配置我放在了源码里,这里不再讲述。
Java SpringBoot集成RabbitMq实战和总结的更多相关文章
- SpringBoot集成rabbitmq(二)
前言 在使用rabbitmq时,我们可以通过消息持久化来解决服务器因异常崩溃而造成的消息丢失.除此之外,我们还会遇到一个问题,当消息生产者发消息发送出去后,消息到底有没有正确到达服务器呢?如果不进行特 ...
- SpringBoot集成RabbitMQ消息队列搭建与ACK消息确认入门
1.RabbitMQ介绍 RabbitMQ是实现AMQP(高级消息队列协议)的消息中间件的一种,最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性.扩展性.高可用性等方面表现不俗.Rabbi ...
- Spring Boot 集成 RabbitMQ 实战
Spring Boot 集成 RabbitMQ 实战 特别说明: 本文主要参考了程序员 DD 的博客文章<Spring Boot中使用RabbitMQ>,在此向原作者表示感谢. Mac 上 ...
- go-micro集成RabbitMQ实战和原理
在go-micro中异步消息的收发是通过Broker这个组件来完成的,底层实现有RabbitMQ.Kafka.Redis等等很多种方式,这篇文章主要介绍go-micro使用RabbitMQ收发数据的方 ...
- springboot集成rabbitmq(实战)
RabbitMQ简介RabbitMQ使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现(AMQP的主要特征是面向消息.队列.路由.可靠性.安全).支持多种客户端,如:Python.Ru ...
- SpringBoot集成rabbitmq(一)
前言 Rabbitmq是一个开源的消息代理软件,是AMQP协议的实现.核心作用就是创建消息队列,异步发送和接收消息.通常用来在高并发中处理削峰填谷.延迟处理.解耦系统之间的强耦合.处理秒杀订单. 入 ...
- SpringBoot集成RabbitMQ
官方说明:http://www.rabbitmq.com/getstarted.html 什么是MQ? MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.MQ ...
- springboot集成swagger实战(基础版)
1. 前言说明 本文主要介绍springboot整合swagger的全过程,从开始的swagger到Knife4j的进阶之路:Knife4j是swagger-bootstarp-ui的升级版,包括一些 ...
- SpringBoot集成RabbitMQ并实现消息确认机制
原文:https://blog.csdn.net/ctwy291314/article/details/80534604 RabbitMQ安装请参照RabbitMQ应用 不啰嗦直接上代码 目录结构如下 ...
随机推荐
- zabbix安装及简单使用备注
1.安装mysql yum install -y mariadb mariadb-server systemctl start mariadb 2.安装apache yum -y install ht ...
- notepad++ 快速运行PHP代码
notepad++ 运行PHP代码 1. 按下快捷键 F52. 将输入如下命令 cmd /k D:\xampp\php\php.exe "$(FULL_CURRENT_PATH)" ...
- 基于python脚本,实现Unity全平台的自动打包
转载请标明出处:http://www.cnblogs.com/zblade/ 0. 概述 本文主要针对项目中自动打包过程进行调研,实现用python脚本来打出win/android/ios三个平台下的 ...
- Python:鲜为人知的功能特性(上)
GitHub 上有一个名为<What the f*ck Python!>的项目,这个有趣的项目意在收集 Python 中那些难以理解和反人类直觉的例子以及鲜为人知的功能特性,并尝试讨论这些 ...
- jquery快速入门(三)
捕获内容和属性 1.DOM 操作 获得内容 - text().html() 以及 val() text() - 设置或返回所选元素的文本内容,如果不带值则是返回值,如果带值则是修改值,如:$('p') ...
- vue项目使用MD5进行密码加盐
首先给项目安装MD5模块:npm install --save js-md5 使用方法有两种: 使用方法1: 在需要使用的项目文件中引入MD5:import md5 from 'js-md5'; 使 ...
- 【Vuex】vuex基本介绍与使用
Vuex是什么? 官方解释: Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化.Vuex 也集 ...
- 使用C#开发windows服务定时发消息到钉钉群_群组简单消息
前言:本提醒服务,是由C#语言开发的,主要由windows服务项目和winform项目组成,运行服务可实现功能:向钉钉自定义机器人群组里,定时,定次,推送多个自定义消息内容,并实现主要功能的日志记录. ...
- 从零开始学安全(四十三)●Wireshark分析ICMP(IP)协议
存活时间与IP分片 这里我们首先来研究一下关于IP协议的两个非常重要的概念:存活时间与IP分片.存活时间(TTL,Time to Live)用于定义数据包的生存周期,也就是在该数据包被丢弃之前,所能够 ...
- Netty解决粘包和拆包问题的四种方案
在RPC框架中,粘包和拆包问题是必须解决一个问题,因为RPC框架中,各个微服务相互之间都是维系了一个TCP长连接,比如dubbo就是一个全双工的长连接.由于微服务往对方发送信息的时候,所有的请求都是使 ...