Scrapy爬取豆瓣电影top250的电影数据、海报,MySQL存储
从GitHub得到完整项目(https://github.com/daleyzou/douban.git)
1、成果展示
数据库
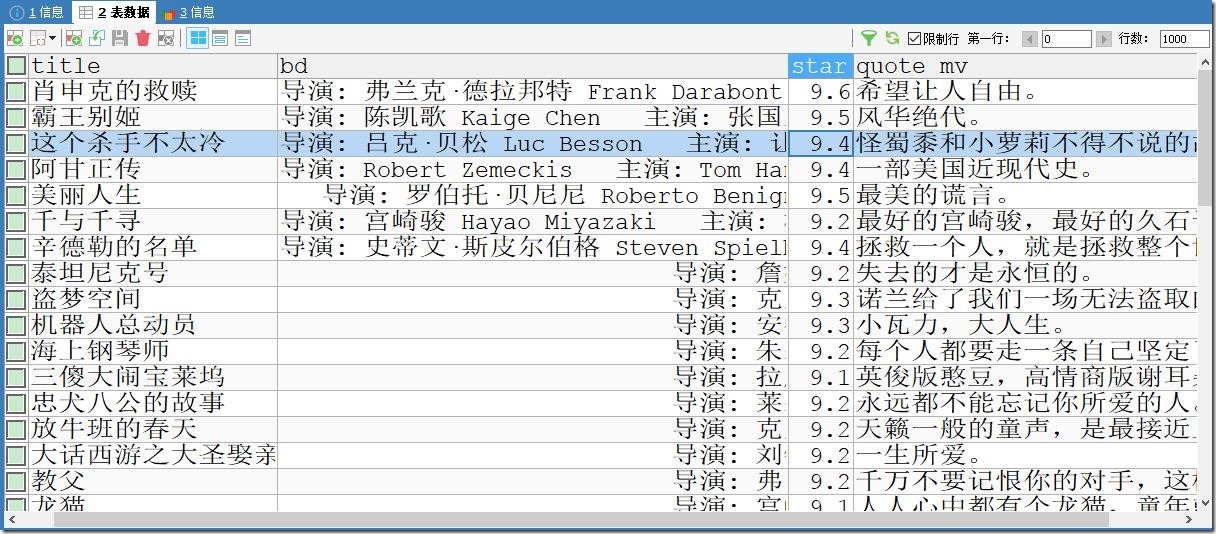
本地海报图片

2、环境
(1)已安装Scrapy的Pycharm
(2)mysql
(3)连上网络的电脑
3、实体类设计
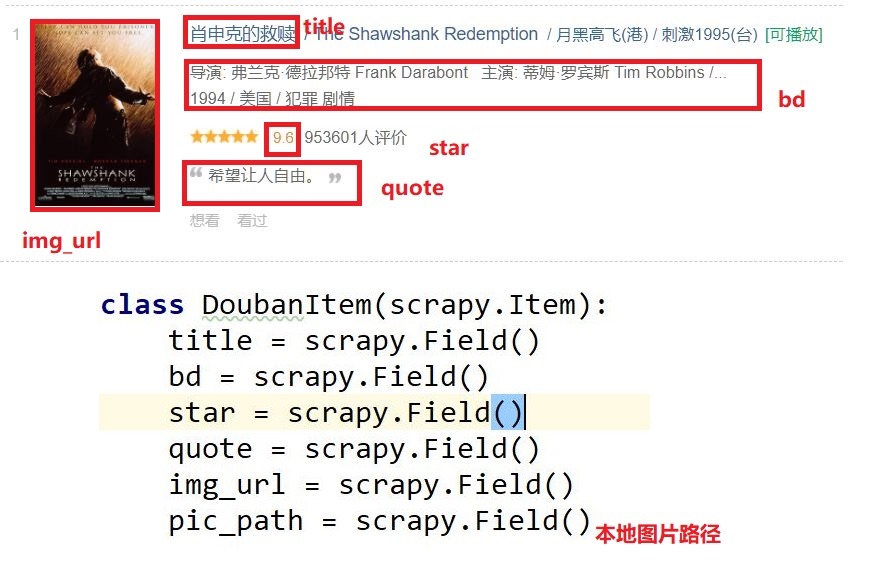
4、代码
items.py
- class DoubanItem(scrapy.Item):
- title = scrapy.Field()
- bd = scrapy.Field()
- star = scrapy.Field()
- quote = scrapy.Field()
- img_url = scrapy.Field()
- pic_path = scrapy.Field()
doubanmovie.py(爬虫类)
- # -*- coding: utf-8 -*-
- import scrapy
- # noinspection PyUnresolvedReferences
- from douban.items import DoubanItem
- import sys
- reload(sys)
- sys.setdefaultencoding('utf-8')
- class DoubanmovieSpider(scrapy.Spider):
- name = 'doubanmovie'
- allowed_domains = ['douban.com']
- offset = 0
- url = "https://movie.douban.com/top250?start="
- start_urls = [url + str(offset),]
- def parse(self, response):
- item = DoubanItem()
- movies = response.xpath("//div[ @class ='info']")
- links = response.xpath("//div[ @class ='pic']//img/@src").extract()
- for (each, link) in zip(movies,links):
- # 标题
- item['title'] = each.xpath('.//span[@class ="title"][1]/text()').extract()[0]
- # 信息
- item['bd'] = each.xpath('.//div[@ class ="bd"][1]/p/text()').extract()[0]
- # 评分
- item['star'] = each.xpath('.//div[@class ="star"]/span[@ class ="rating_num"]/text()').extract()[0]
- # 简介
- quote = each.xpath('.//p[@ class ="quote"] / span / text()').extract()
- # quote可能为空,因此需要先进行判断
- if quote:
- quote = quote[0]
- else:
- quote = ''
- item['quote'] = quote
- item['img_url'] = link
- yield item
- if self.offset < 225:
- self.offset += 25
- yield scrapy.Request(self.url+str(self.offset), callback=self.parse)
pipelines.py
- # -*- coding: utf-8 -*-
- import MySQLdb
- from scrapy import Request
- from scrapy.pipelines.images import ImagesPipeline
- class DoubanPipeline(object):
- def __init__(self):
- self.conn = MySQLdb.connect(host='localhost', port=3306, db='douban', user='root', passwd='root', charset='utf8')
- self.cur = self.conn.cursor()
- def process_item(self, item, spider):
- print '--------------------------------------------'
- print item['title']
- print '--------------------------------------------'
- try:
- sql = "INSERT IGNORE INTO doubanmovies(title,bd,star,quote_mv,img_url) VALUES(\'%s\',\'%s\',%f,\'%s\',\'%s\')" %(item['title'], item['bd'], float(item['star']), item['quote'], item['title']+".jpg")
- self.cur.execute(sql)
- self.conn.commit()
- except Exception, e:
- print "----------------------inserted faild!!!!!!!!-------------------------------"
- print e.message
- return item
- def close_spider(self, spider):
- print '-----------------------quit-------------------------------------------'
- # 关闭数据库连接
- self.cur.close()
- self.conn.close()
- # 下载图片
- class DownloadImagesPipeline(ImagesPipeline):
- def get_media_requests(self, item, info):
- image_url = item['img_url']
- # 添加meta是为了下面重命名文件名使用
- yield Request(image_url,meta={'title': item['title']})
- def file_path(self, request, response=None, info=None):
- title = request.meta['title'] # 通过上面的meta传递过来item
- image_guid = request.url.split('.')[-1]
- filename = u'{0}.{1}'.format(title, image_guid)
- print '++++++++++++++++++++++++++++++++++++++++++++++++'
- print filename
- print '++++++++++++++++++++++++++++++++++++++++++++++++'
- return filename
middlewares.py
- import random
- import base64
- from settings import USER_AGENTS
- from settings import PROXIES
- class RandomUserAgent(object):
- def process_request(self, request, spider):
- useragent = random.choice(USER_AGENTS)
- request.headers.setdefault("User-Agent",useragent)
- class RandomProxy(object):
- def process_request(self, request, spider):
- proxy = random.choice(PROXIES)
- print '---------------------'
- print proxy
- if proxy['user_passwd'] is None:
- # 如果没有代理账户验证
- request.meta['proxy'] = "http://" + proxy['ip_port']
- else:
- base64_userpasswd = base64.b64encode(proxy['user_passwd'])
- # 对账户密码进行base64编码转换
- request.meta['proxy'] = "http://" + proxy['ip_port']
- # 对应到代理服务器的信令格式里
- request.headers['Proxy-Authorization'] = 'Basic '+ base64_userpasswd
解释HTTP代理使用base64编码
为什么HTTP代理要使用base64编码:
HTTP代理的原理很简单,就是通过HTTP协议与代理服务器建立连接,
协议信令中包含要连接到的远程主机的IP和端口号,如果有需要身份验证的话还需要加上授权信息,
服务器收到信令后首先进行身份验证,通过后便与远程主机建立连接,连接成功之后会返回给客户端200,
表示验证通过,就这么简单,下面是具体的信令格式:
CONNECT 59.64.128.198:21 HTTP/1.1
Host: 59.64.128.198:21
Proxy-Authorization: Basic bGV2I1TU5OTIz
User-Agent: OpenFetion
其中Proxy-Authorization是身份验证信息,
Basic后面的字符串是用户名和密码组合后进行base64编码的结果,
也就是对username:password进行base64编码。
HTTP/1.0 200 Connection established
OK,客户端收到收面的信令后表示成功建立连接,
接下来要发送给远程主机的数据就可以发送给代理服务器了,
代理服务器建立连接后会在根据IP地址和端口号对应的连接放入缓存,
收到信令后再根据IP地址和端口号从缓存中找到对应的连接,将数据通过该连接转发出去。
settings.py
- USER_AGENTS = [
- 'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
- 'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
- 'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
- 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)',
- 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)',
- 'Opera/9.27 (Windows NT 5.2; U; zh-cn)',
- 'Opera/8.0 (Macintosh; PPC Mac OS X; U; en)',
- 'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0 ',
- 'Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Version/3.1 Safari/525.13',
- 'Mozilla/5.0 (iPhone; U; CPU like Mac OS X) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/4A93 Safari/419.3',
- 'Mozilla/5.0 (Linux; U; Android 4.0.3; zh-cn; M032 Build/IML74K) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'
- ]
- PROXIES = [
- {"ip_port":"202.103.14.155:8118","user_passwd":""},
- {"ip_port":"110.73.11.21:8123","user_passwd":""}
- ]
- # Enable or disable extensions
- # See https://doc.scrapy.org/en/latest/topics/extensions.html
- #EXTENSIONS = {
- # 'scrapy.extensions.telnet.TelnetConsole': None,
- #}
- # Configure item pipelines
- # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
- ITEM_PIPELINES = {
- 'douban.pipelines.DoubanPipeline': 1,
- 'douban.pipelines.DownloadImagesPipeline': 100
- }
- IMAGES_STORE = 'D:\Python\Scrapy\douban\Images'
5、运行
(1)打开本地MySQL数据库
(2)创建一个douban的数据库,并新建一个doubanmovie的表
(3)更改代码中连接到数据库代码中的端口、用户名、密码
(4)切换到项目目录下的/douban/douban/spiders中
(5)运行scrapy crawl doubanmovie
Scrapy爬取豆瓣电影top250的电影数据、海报,MySQL存储的更多相关文章
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- Python 2.7_利用xpath语法爬取豆瓣图书top250信息_20170129
大年初二,忙完家里一些事,顺带有人交流爬取豆瓣图书top250 1.构造urls列表 urls=['https://book.douban.com/top250?start={}'.format(st ...
- scrapy爬取豆瓣电影信息
最近在学python,对python爬虫框架十分着迷,因此在网上看了许多大佬们的代码,经过反复测试修改,终于大功告成! 原文地址是:https://blog.csdn.net/ljm_9615/art ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
- python3爬取豆瓣排名前250电影信息
#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : doubanmovie.py # @Author: Anthony.waa # @Dat ...
- 使用scrapy爬取豆瓣上面《战狼2》影评
这几天一直在学习scrapy框架,刚好学到了CrawlSpider和Rule的搭配使用,就想着要搞点事情练练手!!! 信息提取 算了,由于爬虫运行了好几次,太过分了,被封IP了,就不具体分析了,附上& ...
- Scrapy爬取豆瓣图书数据并写入MySQL
项目地址 BookSpider 介绍 本篇涉及的内容主要是获取分类下的所有图书数据,并写入MySQL 准备 Python3.6.Scrapy.Twisted.MySQLdb等 演示 代码 一.创建项目 ...
- Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP.但也不要太频繁爬取. 涉及知识点:requests.html.xpath.csv 一.准备工作 需要安装reques ...
- 实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB 豆瓣TOP网址:传送门 一.连接数据库 打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,d ...
- 爬取豆瓣音乐TOP250的数据
参考网址:https://music.douban.com/top250 因为详细页的信息更丰富,本次爬虫在详细页中进行,因此先爬取进入详细页的网址链接,进而爬取数据. 需要爬取的信息有:歌曲名.表演 ...
随机推荐
- C语言实现万年历
给出你想知道的年份,便可以计算出该年对应的每个月每个日所对应的星期数,是不是感觉很好玩 ? #include <stdio.h> #include<stdlib.h> long ...
- 20_Android中apk安装器,通过WebView来load进一个页面,Android通知,程序退出自动杀死进程,通过输入包名的方式杀死进程
场景:实现安装一个apk应用程序的过程.界面如下: 编写如下应用,应用结构如下: <RelativeLayout 编写activity_main.xml布局: <Relative ...
- XBMC源代码分析 2:Addons(皮肤Skin)
前文已经对XBMC源代码的整体架构进行了分析: XBMC源代码分析 1:整体结构以及编译方法 从这篇文章开始,就要对XBMC源代码进行具体分析了.首先先不分析其C++代码,分析一下和其皮肤相关的代码. ...
- 开源视频监控系统:iSpy
iSpy是一个开源的视频监控软件,目前已经支持中文.自己用了一下,感觉还是很好用的.翻译了一下它的介绍. iSpy将PC变成一个完整的安全和监控系统 iSpy使用您的摄像头和麦克风来检测和记录声音或运 ...
- TCP 的那些事儿(上)(转)
本文转载自陈皓博文TCP 的那些事儿(上). TCP是一个巨复杂的协议,因为他要解决很多问题,而这些问题又带出了很多子问题和阴暗面.所以学习TCP本身是个比较痛苦的过程,但对于学习的过程却能让人有很多 ...
- Hadoop 的 TotalOrderPartitioner
Partition所处的位置 Partition位置 Partition主要作用就是将map的结果发送到相应的reduce.这就对partition有两个要求: 1)均衡负载,尽量的将工作均匀的分配给 ...
- tomcat中的线程问题2
最近在看线程的有关知识,碰到一个小问题,目前还没有解决,现记录下来. 如果在我们自己写的servlet里有成员变量,因为多线程的访问就会出现一些线程问题.这点大家都知道,我们看下面的例子. publi ...
- git rebase之前需要commit才行
更新好本地代码后,git fetch, 接着合并,但是git rebase 不行, git status一看,有很多更新的文件. 于是 git add --后,再rebase,还是不行. 注意,reb ...
- iOS课程表
最近在做课程表,刚开始的时候完全不知道那个周课表的网格是怎么实现的有木有,各种查资料,寻思路,只找到一个安卓版的.没事,咱要的是思路而已.可能思路不是最优的,但还是总结一下,也希望能给其他人一点思路. ...
- MacRuby 0.3发布,支持Interface Builder,和创建GUI用的HotCocoa
作者 Werner Schuster ,译者 贾晓楠 发布于 2008年9月24日 | 分享到: 微博 微信 QQ空间 LinkedIn Facebook 邮件分享 稍后阅读 我的阅读清单 现在,Ma ...