Hadoop生态圈初识
一、简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
二、HDFS
Hadoop Distributed File System,简称HDFS,是个分布式文件系统,是hadoop的一个核心部分。HDFS有这高容错性(fault-tolerent)的特点,并且设计用来部署在低廉价的(low-cost)的硬件上,提供了高吞吐量(high-throughout)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS开始是为开源的apache项目nutch的基础结构而创建的。
三、MapReduce
Mapreduce是一个编程模型,一个处理和生成超大数据集算法模型的实现,简单概括就是“数据分解、并行计算、结果合并“。Mapreduce最大的优点是它简单的编程模型,程序猿只需根据该模型框架设计map和reduce函数,剩下的任务,如:分布式存储、节点任务调度、节点通讯、容错处理和故障处理都由mapreudce框架来完成,程序的设计有很高的扩展性。
四、生态圈
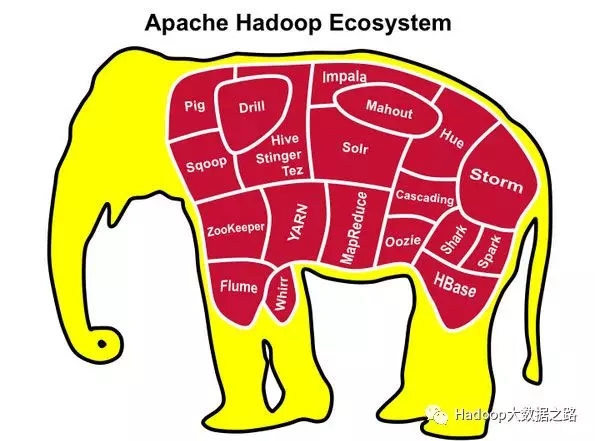
Pig:Hadoop上的数据流执行引擎,由Yahoo开源,基于HDFS和MapReduce,使用Pig Latin语言表达数据流,目的在于让MapReduce用起来更简单。
Sqoop:主要用于在Hadoop和传统数据库进行数据互导。
ZooKeeper:分布式的,开放源码的分布式应用程序协调服务。
Flume:分布式、可靠、高可用的服务,它能够将不同数据源的海量日志数据进行高效收集、汇聚、移动,最后存储到一个中心化数据存储系统中,它是一个轻量级的工具,简单、灵活、容易部署,适应各种方式日志收集并支持failover和负载均衡。
Hive:构建在Hadoop之上的数据仓库,用于解决海量结构化的日志数据统计,定义了一种类SQL查询语言。
YARN:资源协调者、Hadoop 资源管理器,提供统一的资源管理和调度。
Impala:基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata。
Solr:基于Lucene的全文检索引擎。
Hue:开源的Apache Hadoop UI系统,基于Python Web框架Django实现的。通过使用Hue可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据。
Oozie:基于工作流引擎的服务器,可以在上面运行Hadoop任务,是管理Hadoop作业的工作流调度系统。
Storm:分布式实时大数据处理系统,用于流计算。
Hbase:构建在HDFS上的分布式列存储系统,海量非结构化数据仓库。
Spark:海量数据处理的内存计算引擎,Spark框架包含Spark Streaming、Spark SQL、MLlib、GraphX四部分。
Mahout:Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现。
Drill:低延迟的分布式海量数据(涵盖结构化、半结构化以及嵌套数据)交互式查询引擎,使用ANSI SQL兼容语法,支持本地文件、HDFS、HBase、MongoDB等后端存储,支持Parquet、JSON、CSV、TSV、PSV等数据格式。
Tez:有向无环图的执行引擎,DAG作业的开源计算框架。
Shark:SQL on Spark,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。

Hadoop生态圈初识的更多相关文章
- hadoop生态圈介绍
原文地址:大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分 ...
- Hadoop生态圈
1.Hadoop是什么? 适合大数据的分布式存储与计算平台 HDFS: Hadoop Distributed File System分布式文件系统 MapReduce:并行计算框架 解决的问题: HD ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- Hadoop生态圈以及各组成部分的简介
1.Hadoop是什么? 适合大数据的分布式存储与计算平台 HDFS: Hadoop Distributed File System分布式文件系统 MapReduce:并行计算框架 解决的问题: HD ...
- Hortworks Hadoop生态圈简介
Hortworks 作为Apache Hadoop2.0社区的开拓者,构建了一套自己的Hadoop生态圈,包括存储数据的HDFS,资源管理框架YARN,计算模型MAPREDUCE.TEZ等,服务于数据 ...
- 基于Hadoop生态圈的数据仓库实践 —— ETL
使用Hive转换.装载数据 1. Hive简介 (1)Hive是什么 Hive是一个数据仓库软件,使用SQL读.写.管理分布式存储上的大数据集.它建立在Hadoop之上,具有以下功能和 ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- Hadoop生态圈-zookeeper完全分布式部署
Hadoop生态圈-zookeeper完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客部署是建立在Hadoop高可用基础之上的,关于Hadoop高可用部署请参 ...
- 1.1大数据平台架构及Hadoop生态圈
1.硬件架构实例 2.软件架构实例 3.数据流通用概念模型 a.数据源(互联网.物联网.企业数据):App.Device.Site b.数据收集(ETL.提取.转换.加载):Flume.Kafka.S ...
随机推荐
- linux杀死进程的简单讲解
一. 终止进程的工具kill .killall.pkill.xkill 终止一个进程或终止一个正在运行的程序,一般是通过kill .killall.pkill.xkill 等进行.比如一个程序已经死掉 ...
- MySQL学习笔记_6_SQL语言的设计与编写(下)
SQL语言的设计与编写(下) --SELECT查询精讲 概要: SELECT[ALL | DISTINCT] #distinct 明显的,清楚的,有区别的 {*|table.*|[table.]fie ...
- linux shell (()) 双括号运算符使用
估计很多朋友都感觉比较难以接受.特变逻辑运算符"[]"使用时候,必须保证运算符与算数 之间有空格. 四则运算也只能借助:let,expr等命令完成. 今天讲的双括号"(( ...
- java注解及在butternife中的实践和原理
1. 背景 之前去一个公司,说到了java的注解,问java的注解有几种方式,然后我提到了android中的butternife和afinal注解工具,我们知道butternife在6.1版本的时候 ...
- Linux set命令参数及用法详解
linux set 命令 功能说明:设置shell. 语 法:set [+-abCdefhHklmnpPtuvx] 补充说明:用set 命令可以设置各种shell选项或者列 出shell变量.单个选 ...
- android wheelview实现三级城市选择
很早之前看淘宝就有了ios那种的城市选择控件,当时也看到网友有分享,不过那个写的很烂,后来(大概是去年吧),我们公司有这么一个项目,当时用的还是网上比较流行的那个黑框的那个,感觉特别的丑,然后我在那个 ...
- Windows系统版本判定那些事儿
v:* { } o:* { } w:* { } .shape { }p.MsoNormal,li.MsoNormal,div.MsoNormal { margin: 0cm; margin-botto ...
- 50行代码实现的一个最简单的基于 DirectShow 的视频播放器
本文介绍一个最简单的基于 DirectShow 的视频播放器.该播放器对于初学者来说是十分有用的,它包含了使用 DirectShow 播放视频所有必备的函数. 直接贴上代码,具体代码的含义都写在注释中 ...
- 不错的网络协议栈测试工具 — Packetdrill
Packetdrill - A network stack testing tool developed by Google. 项目:https://code.google.com/p/packetd ...
- 【45】java的封装剖析
类是构造对象的模板或蓝图. 封装的一些概念 从形式上看,封装不过是将数据和行为组合到一个包中,并对对象的使用者隐藏了数据的实现形式. 每个对象都包含实例域和方法.实例域的集合代表了一个集合的状态,通过 ...