Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一、效果如下:

二、运行环境:
win10系统;python3;PyCharm
三、QQ机器人用的是qqbot模块
用pip安装命令是: pip install qqbot (前提需要有requests库)
实现自己的机器人:网上好几种写法,很简单,不过有时候环境不同会出现错误,下面是亲测可以运行的:
from qqbot import QQBotSlot as qqbotslot, RunBot
@qqbotslot
def onQQMessage(bot, contact, member, content):
if content == "-hello":#content是好友发的信息
bot.SendTo(contact,"我是,QQ机器人")
if __name__ == "__main__":
RunBot()
四、爬取百度文库
需要模块:import urllib.request,urllib,re
获取原网页代码:
提前说下百度文库网页编码是gb2312
def baidu(self,world):
data={}
data['word'] = world
url_World=urllib.parse.urlencode(data,encoding="GBK")
url = "https://wenku.baidu.com/search?"+url_World+"&org=0&ie=gbk"
page = urllib.request.urlopen(url)
html = page.read()
html = html.decode('gbk')
代码解析:
data['word'] = world #world是搜索的内容,也就是关键词
url不必多说就是网页链接
但是二者之间多了一行代码:url_World=urllib.parse.urlencode(data,encoding="GBK")
看一下百度文库搜索"大学":https://wenku.baidu.com/search?word=%B4%F3%D1%A7&org=0&ie=gbk
其中%B4%F3%D1%A7 就是"大学"的十六进制。
也就是说我们想搜索“大学”的相关内容需要把“大学”的中文转成上面格式,如果不转会出现什么状况
我们直接把中文“大学”塞到链接里去访问:https://wenku.baidu.com/search?word=大学&lm=0&od=0&fr=top_home&ie=gbk
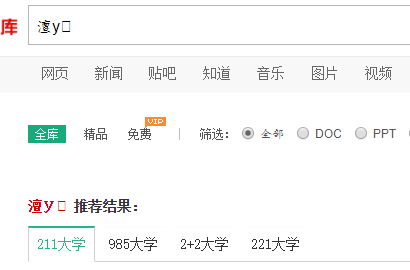
会有乱码这个乱码直接导致后面获取原网页解码错误也就是:
html = html.decode('gbk')
解码是让中文能够正常显示,但是上面的乱码是不能通过gbk编码进行解码的,也就会出现错误。
所以不能直接把参数world直接放进去。
而urllib.parse.urlencode(data)这行代码就是把中文转成url格式的。
不过默认的编码是utf-8,直接把data放进去会按照utf-8进行转的话会得到如下链接:
https://wenku.baidu.com/search?word=%E5%A4%A7%E5%AD%A6&org=0&ie=gbk
此链接得到网页效果是和之前把中文放进链接效果一样
网上找到的基本上都是这样的写法,不过百度文库是采用gb2312编码所以需要在那行转码代码中再添加一个编码参数就能够达到目的
如下:urllib.parse.urlencode(data,encoding="GBK")
这样无论是url转码还是后面的解码都会正常运行了。
此过程就能够得到正常的搜索结果的原网页了
用正则获取想要的信息:

上面代码就能把需要的是标题和相应的链接给提取出来
其他的就是容错问题了。
全部代码如下:
from qqbot import QQBotSlot as qqbotslot, RunBot
import urllib.request,urllib,re
class pyth(object):
def baidu(self,world):
data={}
data['word'] = world
url_World=urllib.parse.urlencode(data,encoding="GBK")
url = "https://wenku.baidu.com/search?"+url_World+"&org=0&ie=gbk"
page = urllib.request.urlopen(url)
html = page.read()
html = html.decode('gbk')
title= re.compile(r'<span title=".*?" class="ic ic-.*?title="(.*?)"',re.S)
url1= re.compile(r'<span title=".*?" class="ic .*?<a href="(.*?)"',re.S)
title1= re.findall(title,html)
url11= re.findall(url1,html)
pri = "百度文库搜索结果:"
if len(title1)>2:
for i in range(2):
pri += "\n"+title1[i]+"\n链接:"+url11[i];
else:
pri = "相关内容过少,请换个题目"
return pri @qqbotslot
def onQQMessage(bot, contact, member, content):
if "搜索" in content[0:2]:
if len(content)>2:
world = content.split("搜索",1)[1].encode('gbk')
run=pyth()
run.baidu(world)
jieguo = run.baidu(world).encode("utf-8")
bot.SendTo(contact,jieguo) if __name__ == "__main__":
RunBot()
Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)的更多相关文章
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html 在下面这种类型文件中的请求头的url打开后会得到一个页面 你会得到如下图 ...
- python爬取百度文库所有内容
转载自 GitHub 的 Jack-Cherish 大神 基本环境配置 版本:python3 系统:Windows 相关模块: import requests import re import jso ...
- python 爬取百度url
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-29 18:38:23 # @Author : EnderZhou (z ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频 国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶-- 我身边的很多小伙伴们在朋友圈里面晒着出去游玩 ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
随机推荐
- IOS学习笔记25—HTTP操作之ASIHTTPRequest(一)
ASIHTTPRequest是一个第三方开源项目,在现在的IOS应用中多使用到这个开源类库来提供网络操作,相比于SDK提供的网络操作类库,ASIHTTPRequest使用上更加方便.效率更高,同时功能 ...
- 【编程技巧】NSTimer类的使用
创建一个 Timer + scheduledTimerWithTimeInterval: invocation: repeats: + (NSTimer *)scheduledTimerWithTim ...
- input===》name属性异常错误
<input type="text" name="status" /> 使用springMVC时,如果有这个输入框,此框必须要填,且必须是数字,否者 ...
- Intel系列微处理器的三种工作模式
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- set类型
set 集合 是string类型的无序集合.我们可以对集合去交集 并集 差集 sadd 添加元素 不允许有重复的值 smembers 查看元素中的值 srem 删除set中的值
- python_百文买百鸡问题
百文买百鸡问题 -- 不定方程 -- 公鸡5文钱一只,母鸡3文钱一只,小鸡3只一文钱,用100文钱买100只鸡,如何买? -- 列出方程式 x + y + z = 100 5x + 3y + z/3 ...
- 转-Linux硬件装置和磁盘分区MBR
1 各硬件装置在Linux中的文件名 『在Linux系统中,每个装置都被当成一个文件来对待』 举例来说,SATA接口的硬盘的文件名即为/dev/sd[a-d],其中, 括号内的字母为a-d当中的任意一 ...
- 流API--流的收集
前面的一系列博客中,我们都是从一个集合中拿到一个流,但是有时候需要执行反操作,就是从流中获得集合.实际编码中,当我们处理完流后,我们通常想查看下结果,而不是将他们聚合成一个值.我们可以调用iterat ...
- jdk源码->集合->ConcurrentHashMap
类的属性 public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentM ...
- ueditor表格边框没有颜色的解决
问题: 用ueditor画表格,会发现表格存在,但是表格边框没有颜色. 解决方法: 需要对js文件中的样式进行修改,这里我引用的编辑器样式文件是ueditor.all.min.js,所以先找到该文件, ...