Django之无名分组,有名分组
在Django 2.0版本之前,在urls,py文件中,用url设定视图函数
urlpatterns = [
url(r'login/',views.login),
]
其中第一个参数是正则匹配,如下代码,输入http://127.0.0.1:8000/login,出现的是login页面,但是输入login2,出现的还是login页面,这是因为Django会将匹配成功的返回,不会继续往下匹配
urlpatterns = [
url(r'login',views.login),
url(r'login2',views.login2),
]
所以为了避免上面这种情况,可以在第一个参数加上正则表达式
urlpatterns = [
url(r'^login/$',views.login),
url(r'^login2/$',views.login2),
]
^号限定开头,$限定结尾,' / '为匹配机制,比如第一次输入:http://127.0.0.1:8000/login,没有匹配成功,系统会自动加上‘/‘再进行一次匹配
这样就可以写出首页和尾页(尾页是指找不到对应页面时打开的页面,俗称404)
urlpatterns = [
url(r'^$',views.home), #这是首页
url(r'',views.error) #这是尾页
]
同样的既然可以进行正则匹配,那么就可以写更多的正则语法:
urlpatterns = [
url(r'^login/[0-9]{4}$',views.login),
]
类似上面写出的正则,就是login/ 后面随意加上4位数字都可以访问login页面
同样的正则还有分组的概念,但是在Django中把分组分为两种:无名分组和有名分组
无名分组:
urlpatterns = [
url(r'^login/([0-9]{4})$',views.login),
]
在普通的正则匹配中加上()就是无名分组,那么这样有什么意义呢?
首先在后端的views上,会得到一个分组的参数,以上面代码为例,那么views.login函数的参数除了request,还需要添加一个参数(名字随意),进行几次分组那么就需要多添加几次参数
进入view页面,其中xxx的名字是随意的,传进来的分组的数据例如我输入的网址是:login/222,那么xxx的值为222
def login(request,xxx):
print(xxx)
有名分组:
有名分组其实就是在无名的分组的基础上加上了名字
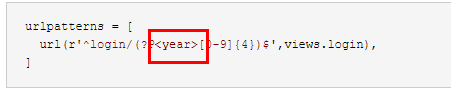
urlpatterns = [
url(r'^login/(?P<year>[0-9]{4})$',views.login),
]
语法为:(?P<名字> 正则表达式),就是在无名分组的括号里面加上了?P<名字>,注意其中P为大写
既然有了名字,那么在views页面就不能给函数传递随意的参数了:
def login(request,year):
print(year)
第二个参数year是urls页面命名的名字:
如果名字不一样则会报错
这里有一个坑,既然分组有有名分组和无名分组,那么能不能一起使用?
答:不行,别问,问就是不行
Django之无名分组,有名分组的更多相关文章
- Web框架之Django_03 路由层了解(路有层 无名分组、有名分组、反向解析、路由分发 视图层 JsonResponse,FBV、CBV、文件上传)
摘要: 路由层 无名分组 有名分组 反向解析 路由分发 名称空间 伪静态网页.虚拟环境 视图层 JsonResponse FBV 与 CBV(function base views与class bas ...
- Django 的路由层URL 分组 路由分发 反向解析
URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表:你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调 ...
- django基础之有名分组和无名分组
在Django 2.0版本之前,在urls,py文件中,用url设定视图函数 urlpatterns = [ url(r'login/',views.login), ] 其中第一个参数是正则匹配,如下 ...
- Django学习——路由层之路由匹配、无名分组、有名分组、反向解析
路由层之路由匹配 """路由你可以看成就是出去ip和port之后的地址""" url()方法 1.第一个参数其实是一个正则表达式 2.一旦第 ...
- Django之ORM操作(聚合 分组、F Q)
Django之ORM操作(聚合 分组.F Q) 聚合 aggregate()是QuerySet的一个终止子句,也就是说,他返回一个包含一些键值对的字典,在它的后面不可以再进行点(.)操作. 键的名 ...
- Django路由系统---django重点之url命名分组
django重点之url命名分组[参数无顺序要求]. settigs.py:增加STATICFILES_DIRS静态资源路径配置,名称为创建的文件夹名称 'DIRS': [os.path.join(B ...
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
pandas学习(数据分组与分组运算.离散化处理.数据合并) 目录 数据分组与分组运算 离散化处理 数据合并 数据分组与分组运算 GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表 ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
- django 中的聚合和分组 F查询 Q查询 事务cookies和sessions 066
1 聚合和分组 聚合:对一些数据进行整理分析 进而得到结果(mysql中的聚合函数) 1aggregate(*args,**kwargs) : 通过对QuerySet进行计算 ,返回一个聚合值的字典. ...
随机推荐
- JAVA基础第三章-类与对象、抽象类、接口
业内经常说的一句话是不要重复造轮子,但是有时候,只有自己造一个轮子了,才会深刻明白什么样的轮子适合山路,什么样的轮子适合平地! 我将会持续更新java基础知识,欢迎关注. 往期章节: JAVA基础第一 ...
- WebGL展示3D房屋内景
原文地址:WebGL展示3D房屋内景 由于生活和工作上的原因,从年前开始一直到处奔波,没有太多的时间去关注和学习WebGL图形学相关的技术, 不过陆陆续续都有学习使用blender进行3D建模 ...
- Boosting(提升方法)之XGBoost
XGBoost是一个机器学习味道非常浓厚的模型,在数学上非常规范,运用正则化.L2范数.二阶梯度.泰勒公式和分布式计算方法,对GBDT等提升树模型进行优化,不仅能处理更大规模的数据,而且运行效率特别高 ...
- python接口自动化(二十一)--unittest简介(详解)
简介 前边的随笔主要介绍的requests模块的有关知识个内容,接下来看一下python的单元测试框架unittest.熟悉 或者了解java 的小伙伴应该都清楚常见的单元测试框架 Junit 和 T ...
- 服务端预渲染之Nuxt(介绍篇)
现在前端开发一般都是前后端分离,mvvm和mvc的开发框架,如Angular.React和Vue等,虽然写框架能够使我们快速的完成开发,但是由于前后台分离,给项目SEO带来很大的不便,搜索引擎在检索的 ...
- LeetCode重建二叉树系列问题总结
二叉树天然的递归特性,使得我们可以使用递归算法对二叉树进行遍历和重建.之前已经写过LeetCode二叉树的前序.中序.后序遍历(递归实现),那么本文将进行二叉树的重建,经过对比,会发现二者有着许多相似 ...
- java基础(八)-----深入解析java四种访问权限
Java中的访问权限理解起来不难,但完全掌握却不容易,特别是4种访问权限并不是任何时候都可以使用.下面整理一下,在什么情况下,有哪些访问权限可以允许选择. 一.访问权限简介 访问权限控制: 指的是本类 ...
- spring boot 2.0 Feign的客户端
1.pom.xml <dependency> <groupId>org.springframework.cloud</groupId> <artifactId ...
- 简单几步用纯CSS3实现3D翻转效果
作为前端开发人员的必修课,CSS3翻转能带我们完成许多基本动效,本期我们将用CSS3实现hover翻转效果~ 第一步非常简单,我们简单画1个演示方块,为其 添加transition和transform ...
- 前端笔记之CSS(下)浮动&BFC&定位&Hack
一.浮动 1.1 各个语言的主要知识点 HTML:标签语义化(那么怎么样布局才是合理的?没有绝对的对和错) CSS: 样式: 布局: 标准流(标准文档流.普通文档流):盒子模型(width/heigh ...