[Codeforces]605E Intergalaxy Trips
小C比较棘手的概率期望题,感觉以后这样的题还会贴几道出来。
Description
给定一个n*n的邻接矩阵,邻接矩阵中元素pi,j表示的是从 i 到 j 这条单向道路在这一秒出现的概率百分比,走一条道路的时间需要1秒,问从1号点出发到n号点最短所需花费时间的期望。最短所需花费时间即在每一个点都按照最优决策移动。
Input
第一行一个正整数n。接下来n行,每行n个整数,描述一个邻接矩阵。
Output
输出一行一个小数,表示最短花费时间期望。你的答案和标准答案相差的绝对值不超过10^-6时,被视为正确答案。
Sample Input
3
100 50 50
0 100 80
0 0 100
Sample Output
1.75000000000
HINT
1<=n<=1000,0<=pi,j<=100。
Solution
这道题有两个难点:
一是怎么处理反复做这件事的概率,因为道路不是100%存在,所以有极小的概率永远走不到下一个点;
二是怎么处理DP的顺序,概率DP的做法很显然,但这张图不是一张拓扑图(后面会讲到就算是拓扑图也不是按照拓扑序转移)。
曾经有一位贤者说过,“计算概率要正着算,计算期望要倒着算”。
姑且不论这句话的片面性,小C把这句话作为导语。
所以终点的期望值肯定是0,然后一步步推到起点。
为了解决第一个难点,首先我们考虑一下这样的情况:
假设现在要计算期望f的点为x,它可以到达的点为e[1]~e[cnt],到达这些点的路出现的概率为p[1]~p[cnt]。
而且e[1]~e[cnt]到达终点的期望f都是已知的。
所以我们把e[1]~e[cnt]按照期望f从小到大排序,设排序后的数组为e'。
由于最小花费要求我们总是向着最优策略移动,所以当有路径通向e'[1]时,往e'[1]走肯定是最优的。
而通向e'[1]的路没出现时,我们就必须往e'[2]走。同理当e'[1]~e'[cnt-1]都没出现时,就必须往e'[cnt]走。
然而当e'[1]~e'[cnt]都没出现时,我们就必须原地等待一秒,继续重复上面的操作。
所以我们也就得到了求得f[x]的转移方程:
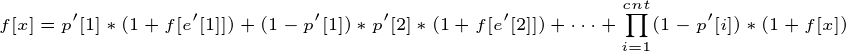
把1提出来,得到:
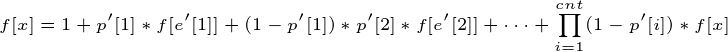
移项然后除过去,得:
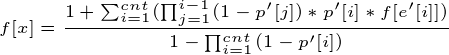
是不是很简单?
但是你可能会有疑问,为什么x是从e'[1]~e'[cnt]转移,万一f[e'[cnt]]很大怎么办?是不是只转移到e'[cnt-1]甚至更早就够了?
这就涉及到了第二个难点,关于转移顺序的问题。
我们发现这样求最短路期望其实和求最短路没有什么两样。
对于所有的f[x],我们首先可以明确它是一个定值,所以每个f[x]都是从比f[x]小的期望f转移得来;
如果遇到比f[x]大的期望,那还不如原地等待一秒来的优呢!(其实就是从自己转移,请读者大约脑补一下)
所以我们可以像dijkstra那样从小到大求出最短路期望。
也就是每次选出当前未确定最短路期望的最小值,用这个最小值继续更新其他未确定的点。
这个当前选出的最小值一定就是这个点的最短路径期望,因为比它f[x]大的期望一定不会更新f[x]。
所以我们得出,依次求得的最短路径期望是递增的,其实这就是dijkstra算法本身的证明思路。
于是这两个难点都完美解决了。
至于如何维护信息已经很容易了,根据求f[x]的公式,我们只要维护  和
和 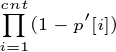 即可。
即可。
时间复杂度为dijkstra算法的O(n^2)。
#include <cstdio>
#include <cstring>
#include <algorithm>
#define MN 1005
#define INF 1LL<<62
using namespace std;
double pem[MN][MN],rem[MN],dis[MN];
double mn;
bool u[MN];
int n,mni; inline int read()
{
int n=,f=; char c=getchar();
while (c<'' || c>'') {if(c=='-')f=-; c=getchar();}
while (c>='' && c<='') {n=n*+c-''; c=getchar();}
return n*f;
} int main()
{
register int i,j;
n=read();
for (i=;i<=n;++i)
for (j=;j<=n;++j) pem[i][j]=(double)read()/;
for (i=;i<=n;++i) rem[i]=,dis[i]=;
rem[n]=dis[n]=;
for (i=;i<=n;++i)
{
mn=INF;
for (j=;j<=n;++j)
if (!u[j]&&rem[j]<&&dis[j]/(-rem[j])<mn) mn=dis[j]/(-rem[j]),mni=j;
dis[mni]=mn; u[mni]=true;
if (mni==) return *printf("%.10lf",dis[mni]);
for (j=;j<=n;++j)
if (!u[j]) dis[j]+=rem[j]*pem[j][mni]*dis[mni],rem[j]*=(-pem[j][mni]);
}
}
Last Word
这算是小C少有的一次头脑清晰地码出概率/期望DP的一道题,但小C知道丧病的题还会有多,再接再厉吧。
[Codeforces]605E Intergalaxy Trips的更多相关文章
- CodeForces 605 E. Intergalaxy Trips
E. Intergalaxy Trips time limit per test:2 seconds memory limit per test:256 megabytes input:standar ...
- 【CF605E】Intergalaxy Trips(贪心,动态规划)
[CF605E]Intergalaxy Trips(贪心,动态规划) 题面 Codeforces 洛谷 有\(n\)个点,每个时刻第\(i\)个点和第\(j\)个点之间有\(p_{ij}\)的概率存在 ...
- CF#335 Intergalaxy Trips
Intergalaxy Trips time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- CF605E Intergalaxy Trips
CF605E Intergalaxy Trips 考虑你是不知道后来的边的出现情况的,所以可以这样做:每天你都选择一些点进行观察,知道某天往这些点里面的某条边可用了,你就往这条边走.这样贪心总是对的. ...
- Intergalaxy Trips CodeForces - 605E (期望,dijkstra)
大意: 给定矩阵$p$, $p_{i,j}$表示每一秒点$i$到点$j$有一条边的概率, 每秒钟可以走一条边, 或者停留在原地, 求最优决策下从$1$到$n$的期望用时. $f_x$为从$x$到$n$ ...
- CF605E Intergalaxy Trips 贪心 概率期望
(当时写这篇题解的时候,,,不知道为什么,,,写的非常冗杂,,,不想改了...) 题意:一张有n个点的图,其中每天第i个点到第j个点的边都有$P_{i, j}$的概率开放,每天可以选择走一步或者留在原 ...
- E. Intergalaxy Trips
完全图,\(1 \leq n \leq 1000\)每一天边有 \(p_{i,j}=\frac{A_{i,j}}{100}\) 的概率出现,可以站在原地不动,求 \(1\) 号点到 \(n\) 号点期 ...
- [Manthan, Codefest 18][Codeforces 1037E. Trips]
题目链接:1037E - Trips 题目大意:有n个人,m天,每天晚上都会有一次聚会,一个人会参加一场聚会当且仅当聚会里有至少k个人是他的朋友.每天早上都会有一对人成为好朋友,问每天晚上最多能有多少 ...
- Codeforces Manthan, Codefest 18 (rated, Div. 1 + Div. 2) E.Trips
比赛的时候想到怎么做了 没调出来(感觉自己是个睿智) 给你N个点M条边,这M条边是一条一条加进去的 要求你求出加入每一条边时图中极大'K度'子图的大小 极大'K度'子图的意思是 要求出一个有尽量多的点 ...
随机推荐
- 在Apache中运行Python WSGI应用
我们介绍如何使用Apache模块mod_wsgi来运行Python WSGI应用. 安装mod_wsgi 我们假设你已经有了Apache和Python环境,在Linux或者Mac上,那第一步自然是安装 ...
- 常用的 html 标签及注意事项
<a> 标签 用法:用于定义超链接 清除浏览器默认样式: a { text-decoration: none;/* 去除下划线 */ color: #333;/* 改变链接颜色 */ } ...
- 测试驱动开发实践3————从testList开始
[内容指引] 运行单元测试: 装配一条数据: 模拟更多数据测试列表: 测试无搜索列表: 测试标准查询: 测试高级查询. 一.运行单元测试 我们以文档分类(Category)这个领域类为例,示范如何通过 ...
- Python机器学习—导入各种数据的N种办法
pandas 读取数据 一.导入一般的文件 1.read_csv(),用来读取CSV文件 官方文档是这么说的:Read CSV (comma-separated) file into DataFram ...
- babel基本用法
babel-cli babel-cli是本地使用编译js文件 1.安装: cnpm i babel-cli babel-preset-env -D 2.配置packjson: "script ...
- hibernate_exercise-many- to-one(1)
多对一关系 1.创建t_user表.t_group表 2.在eclipse中创建对应的实体类 package com.eneity; public class User { private int i ...
- 安装 docker-compose
安装Docker-Compose之前,请先安装 python-pip,安装好pip之后,就可以安装Docker-Compose了. 一.检查是否已经安装 二.安装 docker-compose 1.安 ...
- Python基础学习篇章四
一. Python数据类型之字典 1. 键的排序:for循环 由于字典不是序列,因此没有可靠的从左至右的顺序.这就导致当建立一个字典,将它打印出来,它的键也许会以与我们输入时的不同的顺序出现.有时候我 ...
- leetcode算法: Find All Duplicates in an Array
Given an array of integers, 1 ≤ a[i] ≤ n (n = size of array), some elements appear twice and others ...
- Java-Maven(四):Eclipse集成Maven环境配置
一般maven都需要集成到IDE上使用的,而不是单独的使用,常见的maven可集成IDE:eclipse.IntelliJ IDEA.但这里就只学习eclipse集成maven的基础上,进行maven ...