Inception模型和Residual模型卷积操作的keras实现
Inception模型和Residual残差模型是卷积神经网络中对卷积升级的两个操作。
一、 Inception模型(by google)
这个模型的trick是将大卷积核变成小卷积核,将多个卷积核的运算结果进行连接,充分利用多尺度信息,这也体现了这篇文章的标题
Going Deeper with Convolutions。更加深的卷积操作。
废话不多说,上图
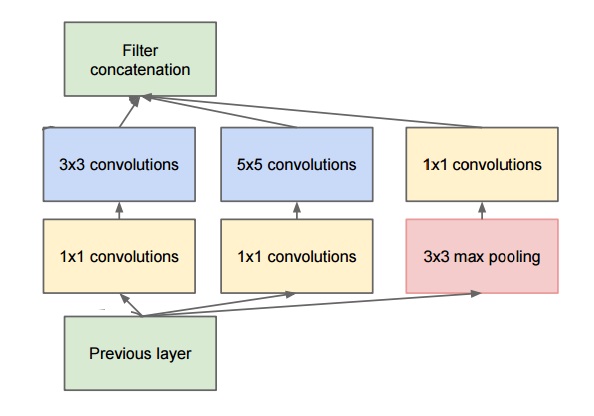
注意输入层在底部,输出层在顶部。废话不多说,上keras代码。
from keras.layers import Conv2D, MaxPooling2D, Input input_img = Input(shape=(256, 256, 3)) tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1) tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2) tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3) output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)
最后的concatenate是核心,其实就是连接在一起,比如两列向量和两列向量,连接成四列向量即可。 二、 Residual模型(by microsoft) 这个模型的trick是将进行了一种跨连接操作,将特征跨过一定的操作后在后面进行求和。这个意义一个是减轻梯度消失,
还有个目的其实让后续的卷积结果变得越来越强。DenseNet 其实也是这种思想。 废话不多说,上图

从上图看,输出的结果就是X+F(X) 直接相加,逐个元素对应相加,而不是连接。F(X) 是什么呢? 看下图
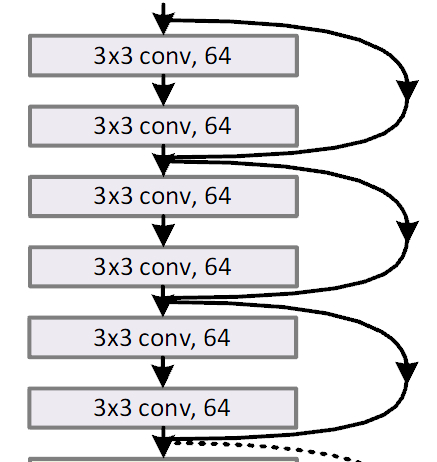
F(X)实际上就是一个或者多个卷积操作,非常简单直观。废话不多说,上keras代码。下面代码只演示了一个卷积操作。
from keras.layers import Conv2D, Input # input tensor for a 3-channel 256x256 image
x = Input(shape=(256, 256, 3))
# 3x3 conv with 3 output channels (same as input channels)
y = Conv2D(3, (3, 3), padding='same')(x)
# this returns x + y.
z = keras.layers.add([x, y])
以上,就是现在目前最最有效的两种卷积升级操作的keras实现。
参考文献:
Keras文档
Inception模型和Residual模型卷积操作的keras实现的更多相关文章
- 贫血模型和DDD模型
贫血模型和DDD模型 1.贫血模型 1.1 概念 常见的mvc三层架构 简单.没有行为 2.领域驱动设计 2.1 概念(2004年提出的) Domain Driven Design 简称 DDD DD ...
- 复杂领域的Cynefin模型和Stacey模型
最近好奇“复杂系统”,收集了点资料,本文关于Cynefin模型和Stacey模型.图文转自互联网后稍做修改. Cynefin模型提供一个从因果关系复杂情度来分析当前情况而作决定的框架,提出有五个领域: ...
- 文本信息检索——布尔模型和TF-IDF模型
文本信息检索--布尔模型和TF-IDF模型 1. 布尔模型 如要检索"布尔检索"或"概率检索"但不包括"向量检索"方面的文档,其相应的查 ...
- 并发编程:Actors 模型和 CSP 模型
https://mp.weixin.qq.com/s/emB99CtEVXS4p6tRjJ2xww 并发编程:Actors 模型和 CSP 模型 ImportNew 2017-04-27
- 三分钟掌控Actor模型和CSP模型
回顾一下前文<三分钟掌握共享内存模型和 Actor模型> Actor vs CSP模型 传统多线程的的共享内存(ShareMemory)模型使用lock,condition等同步原语来强行 ...
- Actor模型和CSP模型的区别
引用至:http://www.jdon.com/concurrent/actor-csp.html Akka/Erlang的actor模型与Go语言的协程Goroutine与通道Channel代表的C ...
- 利用生产者消费者模型和MQ模型写一个自己的日志系统-并发设计里一定会用到的手段
一:前言 写这个程序主要是用来理解生产者消费者模型,以及通过这个Demo来理解Redis的单线程取原子任务是怎么实现的和巩固一下并发相关的知识:这个虽然是个Demo,但是只要稍加改下Appender部 ...
- NLP中word2vec的CBOW模型和Skip-Gram模型
参考:tensorflow_manual_cn.pdf Page83 例子(数据集): the quick brown fox jumped over the lazy dog. (1)CBO ...
- 比较一下Linux下的Epoll模型和select模型的区别
一. select 模型(apache的常用) 1. 最大并发数限制,因为一个进程所打开的 FD (文件描述符)是有限制的,由 FD_SETSIZE 设置,默认值是 1024/2048 ,因此 Sel ...
随机推荐
- Netty学习笔记(二)
只是代码,建议配合http://ifeve.com/netty5-user-guide/此网站观看 package com.demo.netty; import org.junit.Before;im ...
- 2019/1/10 redis学习笔记(二)
本文不涉及集群搭建操作 关于在lua脚本中操作redis的应用场景 大家都知道redis对于单个集合的操作是原子性的;但是有可能有一种场景是这样.比如说抢红包,现在有十个人抢五份红包,抽象到我们jav ...
- JSONP && CORS
前天面试被问到了跨域的问题,自我感觉回答的并不理想,下面我就分享一下整理后的总结分享给大家 一.为什么要跨域 安全限制 JavaScript或Cookie只能访问同域下的内容——同源策略 同源策略 下 ...
- php header解决跨域问题
header('Access-Control-Allow-Credentials:true'); header('Access-Control-Allow-Origin:http://wdjkj.co ...
- LeetCode - 307. Range Sum Query - Mutable
Given an integer array nums, find the sum of the elements between indices i and j (i ≤ j), inclusive ...
- 常用VI操作命令
# ------------------- VI basic ------------------------------- # file name: VI_basic # author : # da ...
- Jenkins配置备份恢复插件ThinBackup
一.系统管理-管理插件-找到ThinBackup并安装 二.系统管理-找到ThinBackup-点击Setting进行设置 第一个参数备份目录是必选,其它可选,点保存. 三.保存后返回到ThinBac ...
- ubuntu 双网卡建网桥脚本实现
#!/bin/bash interface1=`ls /sys/class/net|grep en|awk 'NR==1{print}'` interface2=`ls /sys/class/net| ...
- 01_JavaSE之OOP--面向对象(类和面向对象的简单认识)
面向对象(一) 一.面向对象概述 谈到面向对象就不得不谈谈面向过程,面向对象也是由面向过程发展而来. 面向过程思想概述 面向过程,简而言之就是分步骤,过程化的去解决问题,代表语言有:Pascal,C等 ...
- java实现 redis的发布订阅(简单易懂)
redis的应用场景实在太多了,现在介绍一下它的几大特性之一 发布订阅(pub/sub). 特性介绍: 什么是redis的发布订阅(pub/sub)? Pub/Sub功能(means Publ ...