pyspider 文档介绍
一 代码区结构
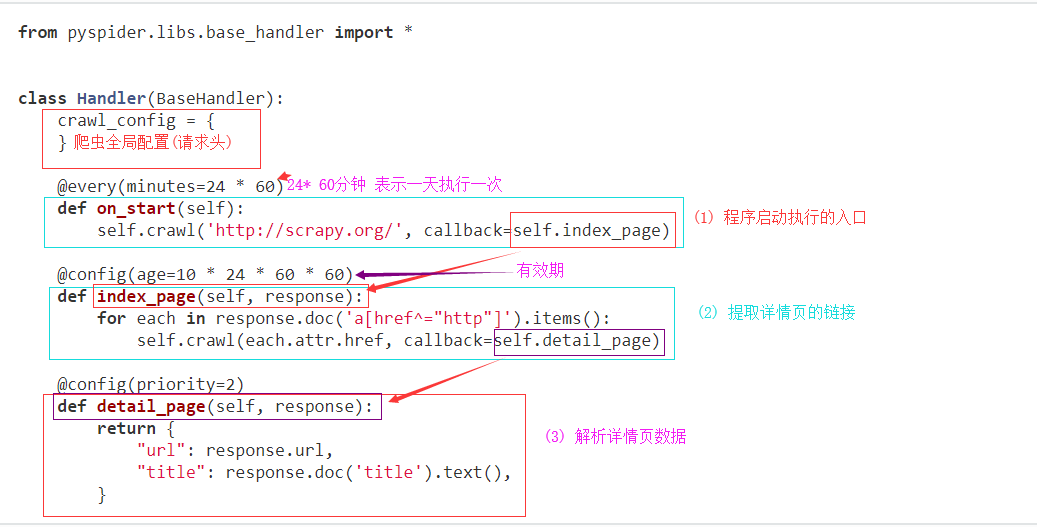
def on_start(self)是脚本的入口点。单击run仪表板上的按钮时将调用它。self.crawl(url, callback=self.index_page)*是这里最重要的API。它将添加一个要爬网的新任务。大多数选项将通过self.crawl参数进行spicified 。def index_page(self, response)得到一个Response*对象。response.doc*是一个pyquery对象,它具有类似jQuery的API来选择要提取的元素。def detail_page(self, response)返回一个dict对象作为结果。结果将resultdb默认捕获。您可以覆盖on_result(self, result)方法来自行管理结果。
您可能想知道的更多内容:
@every(minutes=24*60, seconds=0)*是告诉调度程序on_start应该每天调用方法的帮助程序。@config(age=10 * 24 * 60 * 60)*指定页面类型的默认age参数(when )。参数*可以通过(最高优先级)和(最低优先级)指定。self.crawlindex_pagecallback=self.index_pageageself.crawl(url, age=10*24*60*60)crawl_configage=10 * 24 * 60 * 60* tell scheduler会在10天内抓取该请求。pyspider默认情况下不会抓取同一个URL两次(永远丢弃),即使你修改了代码,对于第一次运行项目并修改它并第二次运行它的初学者来说很常见,它不会再次爬行(阅读itag解决方案)@config(priority=2)*标记应首先抓取详细信息页面。
二 配置启动文件
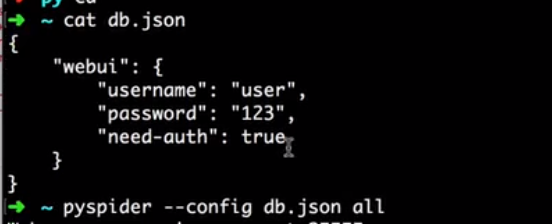
新建 '''db.json''' 配置文件,文件中
{
"taskdb": "mysql+taskdb://username:password@host:port/taskdb",
"projectdb": "mysql+projectdb://username:password@host:port/projectdb",
"resultdb": "mysql+resultdb://username:password@host:port/resultdb",
"message_queue": "amqp://username:password@host:port/%2F",
"webui": {
"username": "some_name",
"password": "some_passwd",
"need-auth": true
}
}
启动配置
pyspider --config db.json all
三 使用PhantomJS(自动执行js文件加载页面)
当连接PhantomJS的pyspider时,您可以通过添加参数fetch_type='js'来启用此功能self.crawl.
class Handler(BaseHandler):
def on_start(self):
self.crawl('http://www.twitch.tv/directory/game/Dota%202',
fetch_type='js', callback=self.index_page)
页面执行js代码
滑动滑动条,加载整个数据
class Handler(BaseHandler):
def on_start(self):
self.crawl('http://www.pinterest.com/categories/popular/',
fetch_type='js', js_script="""
function() {
window.scrollTo(0,document.body.scrollHeight);
}
""", callback=self.index_page)
四 pypider 爬虫结构
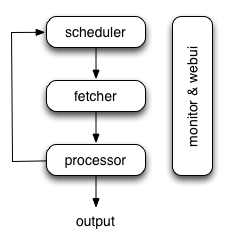
调度器:
调度程序从处理器的newtask_queue接收任务。确定任务是新任务还是需要重新爬网。根据优先级对任务进行排序,并将其提供给具有流量控制的提取器(令牌桶算法)。处理定期任务,丢失任务和失败的任务,然后重试。
提取器
Fetcher负责获取网页,然后将结果发送给处理器。对于灵活的,fetcher支持数据URI和由JavaScript呈现的页面(通过phantomjs)。可以通过API通过脚本控制获取方法,标头,cookie,代理,etag等。
处理器
处理器负责运行用户编写的脚本来解析和提取信息。您的脚本在无限制的环境中运行。虽然我们有各种工具(如PyQuery)可供您提取信息和链接,但您可以使用任何想要处理响应的内容。
执行流程
on_start当您按下RunWebUI上的按钮时,每个脚本都有一个名为callback的回调。将新任务on_start作为项目条目提交给Scheduler。
- Scheduler将此
on_start任务调度为数据URI作为Fetcher的常规任务。
- Fetcher发出请求并对其做出响应(对于数据URI,这是一个虚假的请求和响应,但与其他正常任务没有区别),然后提供给处理器。
- 处理器调用该
on_start方法并生成一些新的URL以进行爬网。处理器向Scheduler发送一条消息,告知此任务已完成,新任务通过消息队列发送到Scheduler(on_start在大多数情况下,这里没有结果。如果有结果,则处理器将它们发送给result_queue)。
- 调度程序接收新任务,在数据库中查找,确定任务是新的还是需要重新爬网,如果是,则将它们放入任务队列。按顺序发送任务。
- 这个过程重复(从第3步开始)并且在WWW死亡之前不会停止;-)。调度程序将检查定期任务以爬网最新数据。
五 self.crawl API
@config(age=10 * 24 * 60 * 60) 任务有效期
priority=1 优先级
exetime=time.time()+30*60 任务执行时间
auto_recrawl = True 自动爬取
params={'a': 123, 'b': 'c'} GET请求参数
method='POST' 请求方式 默认为GET
data={'a': 123, 'b': 'c'} post方式提交数据
{field: {filename: 'content'}} 分段执行文件
User-Agent ='Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36 '
cookies=' '
timeout=' '
allow_redirects=True 默认为false
fetch_type='js' 启用JavaScript fetcher
js_script=''' function() { window.scrollTo(0,document.body.scrollHeight); return 123; } ''' 在页面加载之前或之后运行的JavaScript
load_images 默认False
使用示例
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
age=5*60*60, auto_recrawl=True)
#get请求携带参数
def on_start(self):
self.crawl('http://httpbin.org/get', callback=self.callback,
params={'a': 123, 'b': 'c'})
self.crawl('http://httpbin.org/get?a=123&b=c', callback=self.callback)
#post请求携带参数
def on_start(self):
self.crawl('http://httpbin.org/post', callback=self.callback,
method='POST', data={'a': 123, 'b': 'c'})
#加在页面加载之前或之后运行的JavaScript
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
fetch_type='js', js_script='''
function() {
window.scrollTo(0,document.body.scrollHeight);
return 123;
}
''')
五 全局请求参数
class Handler(BaseHandler):
crawl_config = {
'headers': {
'User-Agent': 'GoogleBot',
}
'proxy': 'localhost:8080'
} ...
六 response 对象
Response.url 返回最终的url
Response.text返回最终的文本
Response.content 响应内容,以字节为单位。
Response.doc
一个PyQuery响应的内容的对象。链接默认为绝对链接。
请参阅PyQuery的文档:https://pythonhosted.org/pyquery/
Response.etree 一个LXML响应的内容的对象。
Response.json 响应的JSON编码内容(如果有)。
pyspider 文档介绍的更多相关文章
- spring-data-solr官方学习文档介绍
spring-data-solr文档介绍如下: 通过http://www.springframework.org/schema/data/solr/spring-solr-1.0.xsd(spring ...
- Docx组件读写Word文档介绍
Docx介绍 官方原文:DocX is a .NET library that allows developers to manipulate Word 2007/2010/2013 files, i ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
- esdoc 自动生成接口文档介绍
原文地址:https://www.xingkongbj.com/blog/esdoc/creat-esdoc.html 官网 ESDoc:https://esdoc.org/ JSDoc:http:/ ...
- 【2】PRD文档介绍
首先,我想说,题主是一个不严肃的人(严肃脸),所以每次干个啥事之前我都喜欢唠唠嗑,说说废话,沟通沟通感情,曾经以为自己将会成为一个幻想中的产品经理那般大展身手,作为非计算机专业出身的应届生,后来才发现 ...
- PySide_Qt文档介绍
http://qt-project.org/wiki/PySideDocumentation/
- EasyUI文档学习心得
概述 jQuery EasyUI 是一组基于jQuery 的UI 插件集合,它可以让开发者在几乎完全不需要CSS以及复杂的JS代码情况下完成美观且功能强大的Web界面. 本文主要说明一些如何利用Eas ...
- [中文版] 可视化 CSS References 文档
本文分享了我将可视化 CSS References 文档翻译成中文版的介绍,翻译工作还在陆续进行中,供学习 CSS 参考. 1. 可视化 CSS References 文档介绍 许多 CSS 的文档都 ...
- LINUX 内核文档地址
Linux的man很强大,该手册分成很多section,使用man时可以指定不同的section来浏览,各个section意义如下: 1 - commands2 - system calls3 - l ...
随机推荐
- Netty中如何写大型数据
因为网络饱和的可能性,如何在异步框架中高效地写大块的数据是一个特殊的问题.由于写操作是非阻塞的,所以即使没有写出所有的数据,写操作也会在完成时返回并通知ChannelFuture.当这种情况发生时,如 ...
- java并发包java.util.concurrent详解
线程池ThreadPoolExecutor的使用 并发容器之CopyOnWriteArrayList 并发容器之CopyOnWriteArraySet 数据结构之ConcurrentHashMap,区 ...
- Python3实现ICMP远控后门(下)之“Boss”出场
ICMP后门 前言 第一篇:Python3实现ICMP远控后门(上) 第二篇:Python3实现ICMP远控后门(上)_补充篇 第三篇:Python3实现ICMP远控后门(中)之"嗅探&qu ...
- Linux的文本处理工具浅谈-awk sed grep
Linux的文本处理工具浅谈 awk 老大 [功能说明] 用于文本处理的语言(取行,过滤),支持正则 NR代表行数,$n取某一列,$NF最后一列 NR==20,NR==30 从20行到30行 FS ...
- sql server 死锁排查
记得以前客户在使用软件时,有偶发出现死锁问题,因为发生的时间不确定,不好做问题的重现,当时解决问题有点棘手了. 现总结下查看死锁的常用二种方式: 第一种是图形化监听: sqlserver --> ...
- 基于opencv3.0下的运动车辆识别
在opencv的初等应用上,对运动物体的识别主要有帧差或背景差两种方式. 帧差法主要的原理是当前帧与前一帧作差取绝对值: 背景差主要的原理是当前帧与背景帧作差取绝对值: 在识别运动车辆上主要需要以下9 ...
- Deep Learning Enables You to Hide Screen when Your Boss is Approaching
https://github.com/Hironsan/BossSensor/ 背景介绍 学生时代,老师站在窗外的阴影挥之不去.大家在玩手机,看漫画,看小说的时候,总是会找同桌帮忙看着班主任有没有来. ...
- SpringCloud微框架系列整体模块梳理
以下为Spring Cloud的核心功能: 分布式/版本化配置服务注册和发现路由服务和服务之间的调用负载均衡断路器分布式消息传递 通过这张图,我们来了解一下各组件配置使用运行流程: 1.请求统一通过A ...
- React-----input中的value不更新 - 提问
原文:http://blog.csdn.net/lihongxun945/article/details/46730835 表单是前端非常重要的一块内容,并且往往包含了错误校验等逻辑. React对表 ...
- Ubuntu18.04美化主题(mac主题)
前端时间Ubuntu18.04LTS发布,碰巧之前用的Ubuntu16.04出了一点问题,懒得解决,索性就换了Ubuntu18.04. 成果: 参考博客:https://www.cnblogs.com ...