python3 爬取qq音乐作者所有单曲 并且下载歌曲
1 import requests
import re
import json
import os # 便于存放作者的姓名
zuozhe = [] headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'} def get_singermid():
name = input('请输入你要下载歌曲的作者:')
zuozhe.append(name)
if not os.path.exists(name):
os.mkdir(name)
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'}
data = {
'w': name,
'jsonpCallback': 'MusicJsonCallback885332333726736',}
response = requests.get(url,headers=headers,params=data).text
patt = re.compile('MusicJsonCallback\d+\((.*?)\}\)')
singermid = re.findall(patt,response)[0]
singermid = singermid+'}'
dic = json.loads(singermid)
return dic['data']['song']['list'][0]['singer'][0]['mid'] def get_page_html(singermid):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg'
params = {
'g_tk': 5381,
'jsonpCallback': 'MusicJsonCallbacksinger_track',
'loginUin': 0,
'hostUin': 0,
'format': 'jsonp',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': 0,
'platform': 'yqq',
'needNewCode': 0,
'singermid': singermid,
'order': 'listen',
'begin': 0,# 页数 0 30 60
'num': 30,
'songstatus': 1,
}
response = requests.get(url,headers=headers,params=params)
return response.text def get_vkey_data(songmid,strMediaMid,name):
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg'
strMediaMid1 = 'C400'+strMediaMid+'.m4a'
data = {
'g_tk': 5381,
'jsonpCallback': "MusicJsonCallback4327043425715609",
'loginUin': 0,
'hostUin': 0,
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': 0,
'platform': 'yqq',
'needNewCode': 0,
'cid': 205361747,
'callback': 'MusicJsonCallback4327043425715609',
'uin': 0,
'songmid': songmid,
'filename': strMediaMid1,
'guid': 4428680404,
}
response = requests.get(url,headers=headers,params=data).text
try:
patt = re.compile('\"vkey\":\"(.*?)\"')
vkey = re.findall(patt,response)[0]
patt = re.compile('\"filename\":\"(.*?)\"')
filename = re.findall(patt, response)[0]
url1 = 'http://dl.stream.qqmusic.qq.com/' + filename + '?vkey=' + vkey + '&guid=4428680404&uin=0&fromtag=66'
yingyue = requests.get(url1,headers=headers).content
with open(zuozhe[0]+'/'+name+'.m4a','wb') as f:
f.write(yingyue)
f.close()
print('下载完成《'+name+'》')
except Exception as e:
print(e)
pass def get_detail_html(html):
if html:
patt = re.compile('data\":{\"list\":(.*?),\"singer_id',re.S)
json_html = re.findall(patt,html)[0]
data_html = json.loads(json_html)
for data in data_html:
name = data['musicData']['songname']
songmid = data['musicData']['songmid']
strMediaMid = data['musicData']['strMediaMid']
print('正在下载《' + name + '》......')
get_vkey_data(songmid,strMediaMid,name) def main():
# 获取 singermid
singermid = get_singermid()
html = get_page_html(singermid)
get_detail_html(html) if __name__ == '__main__':
main()
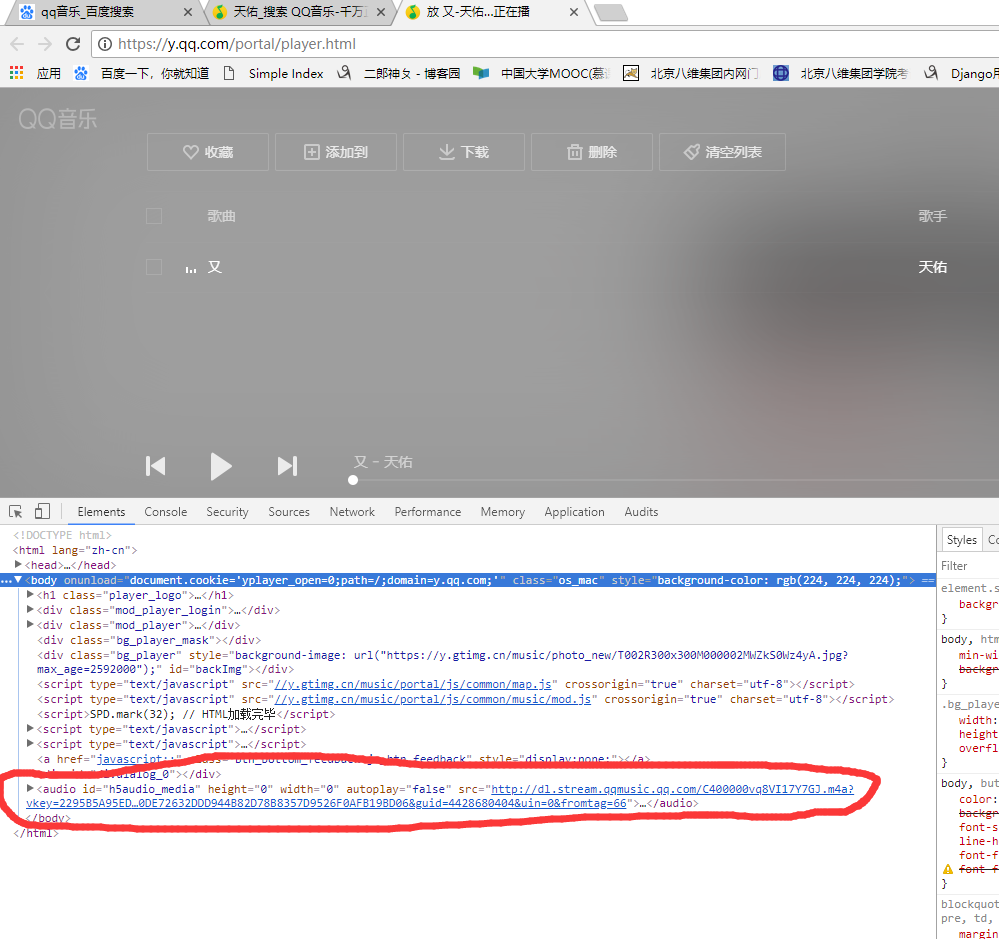

爬取qq音乐首先得找到'http://dl.stream.qqmusic.qq.com/' + filename + '?vkey=' + vkey + '&guid=4428680404&uin=0&fromtag=66'这个链接 然后其中只有filename 和vkey 在变化 然后就在列表页寻找这两个参数,找到以后拼接到这个url,然后请求就可以了 。
代码在上面只供参考
python3 可以直接复制然后运行
python3 爬取qq音乐作者所有单曲 并且下载歌曲的更多相关文章
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- 爬取QQ音乐歌手的歌单
import requests# 引用requests库res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search ...
- 爬取QQ音乐(讲解爬虫思路)
一.问题描述: 本次爬取的对象是QQmusic,为自己后面做django音乐网站的开发获取一些资源. 二.问题分析: 由于QQmusic和网易音乐的方式差不多,都是讲歌曲信息放入到播放界面播放,在其他 ...
- python3爬取咪咕音乐榜信息(附源代码)
参照上一篇爬虫小猪短租的思路https://www.cnblogs.com/aby321/p/9946831.html,继续熟悉基础爬虫方法,本次爬取的是咪咕音乐的排名 咪咕音乐榜首页http://m ...
- 爬取qq音乐巅峰榜---内地音乐的榜单
import requestsimport jsonimport sys for i in range(0,10): url = "https://szc.y.qq.com/v8/fcg-b ...
- python3 爬去QQ音乐
import requests import re import json import os def get_name(singer): url = 'https://c.y.qq.com/soso ...
- 手把手教你使用Python抓取QQ音乐数据(第一弹)
[一.项目目标] 获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 由浅入深,层层递进,非常适合刚入门的同学练手. [二.需要的库] 主要涉及的库有:requests.json ...
- 手把手教你使用Python抓取QQ音乐数据(第二弹)
[一.项目目标] 通过Python爬取QQ音乐数据(一)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 此次我们在之前的基础上获取QQ音乐指定歌曲的歌词及前15个精 ...
- python3爬取全民K歌
Python3爬取全民k歌 环境 python3.5 + requests 1.通过歌曲主页链接爬取 首先打开歌曲主页,打开开发者工具(F12). 选择Network,点击播放,会发现有一个请求返回的 ...
随机推荐
- Ext.Net 1.x_Ext.Net.GridPanel之Access数据库分页显示
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.D ...
- 一个炫字都不够??!!!手把手带你打造3D自定义view
分享一则最近流行的笑话: 最新科学研究表明:寒冷可以使人保持年轻,楼下的王大爷表示虽然今年已经60多岁了,但是仍然冷的跟孙子一样. 呃.好吧,这个冬天确实有点冷,在广州活生生的把我这个原生北方人,冻成 ...
- 从头到尾解析Hash表算法
via:点击打开链接 十一.从头到尾解析Hash 表算法 作者:July.wuliming.pkuoliver 出处:http://blog.csdn.net/v_JULY_v. 说明:本文分 ...
- 嵌入式C快速翻转一个任何类型的数的二进制位
unsigned char reverse_bits(unsigned char value) { unsigned char answer , i ; answer = 0 ; for(i = 1 ...
- Linux变量键盘读取、数组与声明: read, array, declare
[root@www ~]# read [-pt] variable 选项与参数: -p :后面可以接提示字符! -t :后面可以接等待的『秒数!』这个比较有趣-不会一直等待使用者啦! 范例一:让用户由 ...
- ThreadPoolExecutor运行机制
最近发现几起对ThreadPoolExecutor的误用,其中包括自己,发现都是因为没有仔细看注释和内部运转机制,想当然的揣测参数导致,先看一下新建一个ThreadPoolExecutor的构建参数: ...
- 高通 android平台LCD驱动分析
目前手机芯片厂家提供的源码里包含整个LCD驱动框架,一般厂家会定义一个xxx_fb.c的源文件,注册一个平台设备和平台驱动,在驱动的probe函数中来调用register_framebuffer(), ...
- HBase行锁
1 行锁简介 在事务特性方面,hbase只支持单row的事务,不能保证跨row(cross-row)的事务.hbase通过行锁来实现单row事务.客户端进行操作时,可以显式对某一个行加锁,但是大部分情 ...
- The 14th tip of DB Query Analyzer
The 14th tip of DB Query Analyzer Ma Genfeng (Guangdong Unitoll Services incorporated, Guangzhou 5 ...
- 查询oracle数据库的数据库名、实例名、ORACLE_SID
数据库名.实例名.数据库域名.全局数据库名.服务名 , 这是几个令很多初学者容易混淆的概念.相信很多初学者都与我一样被标题上这些个概念搞得一头雾水.我们现在就来把它们弄个明白. 一.数据库名 什么是数 ...