二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算



Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Yran
Tachyon是分布式内存文件系统
Spark是核心计算引擎,能够将数据并行大规模计算
Spark Streaming是流式计算引擎,将每个数据切分成小块采用spark运算范式进行运算
Spark SQL是Spark的SQL ON Hadoop,能够用sql来对数据进行查询等功能
GraphX是图计算引擎
MLlib是机器学习库,提供聚类,分类以及推荐等基本的机器学习算法,并且社区中不断开发新的算法

Spark解决了哪些之前专有系统的局限性
重复开发,可能用使用storm来进行流式计算,有用别的框架进行机器学习
系统组合,不同系统之间数据需要约定格式
专有系统适用范围局限,storm适用于流计算,graphX适用于图计算
资源分配与管理,每个系统都有各自的资源管理,不方便协调




弹性分布式数据集RDD:分布式数组,将整个数据切分成不同的块,然后存到不同的节点通过一个统一的元数据RDD进行管理
partition,存储所有数据块的列表
compute函数,支持不同的RDD完成不同的运算(在不同节点上对这些数据块进行不同的运算)
dependencies维持每次RDD的顺序,比如一部分数据首先要进行去重,然后排序,分组,每次一运算数据都要用到上一次RDD的结果,这就需要dependencies来进行管理
partitioner,重新分区,
preferredLocations,优先读取本地数据

transformations,转换数据



编写程序实例:
进入spark官网,下载并解压spark程序包,此处用最新的:


解压之后在IDE中新建Scala项目,此处使用IntelliJ作为IDE:
new一个project并选择Scala,然后选择object:

讲Spark中jar文件下的jar包全部导入project:
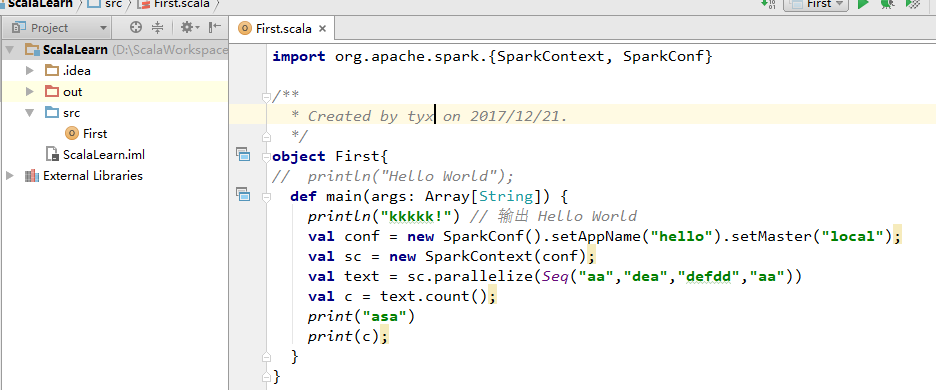
编写如上代码运行,先建立连接spark实例,然后命名,之后选择地址,目前用本地环境
之后编写数据,用parallelize将数据写入RDD,然后可以开始统计count,或者take数据等操作
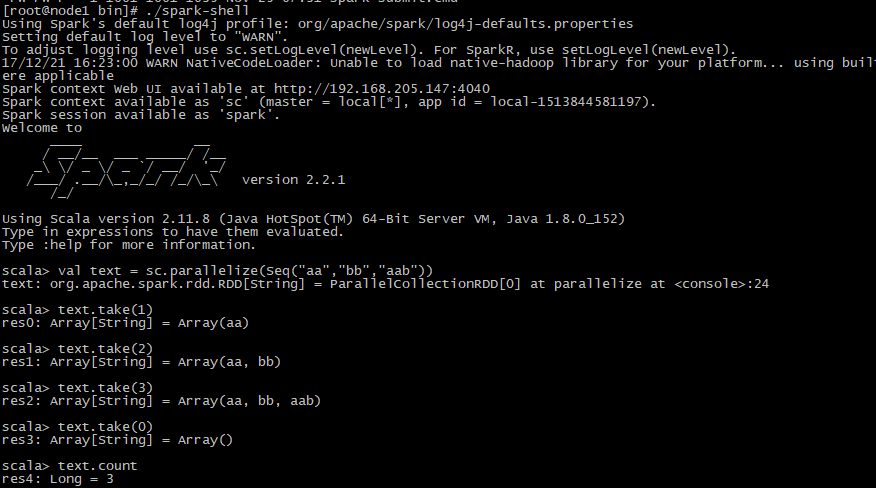
还可以在服务器上用spark-shell执行代码,还是先解压下载好的scala包,然后进入bin目录,执行./spark-shell,由于是内环境操作,不需要实例化链接,然后与上述操作一样:
二十三、Hadoop学记笔记————Spark简介与计算模型的更多相关文章
- 二十四、Hadoop学记笔记————Spark的架构
master为主节点 一个集群中可能运行多个application,因此也可能会有多个driver DAG Scheduler就是讲RDD Graph拆分成一个个stage 一个Task对应一个Spa ...
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 二十一、Hadoop学记笔记————kafka的初识
这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统 Apache flume系统,用于日志收集 Apache storm系统,用于实时数据处理 Spark ...
- 二十、Hadoop学记笔记————Hive On Hbase
Hive架构图: 一般用户接口采用命令行操作, hive与hbase整合之后架构图: 使用场景 场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经 ...
- 二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序 Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HD ...
- 十九、Hadoop学记笔记————Hbase和MapReduce
概要: hadoop和hbase导入环境变量: 要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到: 如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问 ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 笔记:Spark简介
Spark简介 [TOC] Spark是什么 Spark是基于内存计算的大数据并行计算框架 Spark是MapReduce的替代方案 Spark与Hadoop Spark是一个计算框架,而Hadoop ...
随机推荐
- 将 MVVM 演化为 MVVMM
众所周知,MVVM模式解决了Controller的臃肿并方便单元测试,为了方便后续代码维护,在上版本新功能开发中,项目开始使用MVVM模式进行开发. 但从上图可以看出,MVVM模式中,Controll ...
- ”()“和”[]“引发的血案——由此引出C++中关键词new
先来看一个程序吧: #include <iostream> #include <cassert> using namespace std; int main() { ; int ...
- Leetcode_235_Lowest Common Ancestor of a Binary Search Tree
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/48392713 Given a binary search ...
- 图像处理程序框架—MFC相关知识点
CDC:Windows使用与设备无关的图形设备环境(DC :Device Context) 进行显示 . MFC基础类库定义了设备环境对象类----CDC类. CDC与CGdiObject的关系 说道 ...
- LeetCode(34)-Palindrome Number
题目: Determine whether an integer is a palindrome. Do this without extra space. 思路: 求一个整数是不是回文树.负数不是, ...
- windows下ruby中显示中文的3种方法
A: 1将x.rb编码为ascii格式 2 在x.rb开头加上 #code:gbk或者 #coding:gbk B: 1 将x.rb编码为utf-8格式 2 在x.rb开头加上 #code:utf-8 ...
- window 8.1 + python 3.6 + chrome 59 + selenium 3.4 环境配置
系统环境 window 8.1 python 3.6 (已经安装了pip) chrome 59.0.3071.115 步骤 安装selenium pip install selenium 下载chro ...
- 我应该跟libuv说声对不起,我错怪了libuv(转)
一开始,我得向Libuv库和Libuv库开发者以及相关粉丝们道一个歉,对不起,我错怪你们了.深深感到自己的无知,是多么羞愧的事情!! 事情的经过是这样的. 原先按照公司要求,我在开发Win ...
- Spring Boot Kafka
1.创建集群 http://kafka.apache.org/documentation/#quickstart 有一句我觉得特别重要: For Kafka, a single broker is j ...
- Python__flask初识
1. debug:在app.run()里面加上app.run(debug=True), 在浏览器中调试的时候可以直接显示出错误. 2. 在url中传递参数,可以这样 @app.route('/ch ...