K-means聚类的Python实现
生物信息学原理作业第五弹:K-means聚类的实现。
转载请保留出处!
原理参考:K-means聚类(上)
数据是老师给的,二维,2 * 3800的数据。plot一下可以看到有7类。
怎么确定分类个数我正在学习,这个脚本就直接给了初始分类了,等我学会了再发。
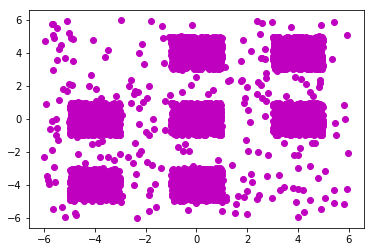
下面贴上Python代码,版本为Python3.6。
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 6 16:01:17 2017 @author: zxzhu
"""
import numpy as np
import matplotlib.pyplot as plt
from numpy import random def Distance(x):
def Dis(y):
return np.sqrt(sum((x-y)**2)) #欧式距离
return Dis def init_k_means(k):
k_means = {}
for i in range(k):
k_means[i] = []
return k_means def cal_seed(k_mean): #重新计算种子点
k_mean = np.array(k_mean)
new_seed = np.mean(k_mean,axis=0) #各维度均值
return new_seed def K_means(data,seed_k,k_means):
for i in data:
f = Distance(i)
dis = list(map(f,seed_k)) #某一点距所有种子点的距离
index = dis.index(min(dis))
k_means[index].append(i) new_seed = [] #存储新种子
for i in range(len(seed_k)):
new_seed.append(cal_seed(k_means[i]))
new_seed = np.array(new_seed)
return k_means,new_seed def run_K_means(data,k):
seed_k = data[random.randint(len(data),size=k)] #随机产生种子点
k_means = init_k_means(k) #初始化每一类
result = K_means(data,seed_k,k_means)
count = 0
while not (result[1] == seed_k).all(): #种子点改变,继续聚类
count+=1
seed_k = result[1]
k_means = init_k_means(k=7)
result = K_means(data,seed_k,k_means)
print('Done')
#print(result[1])
print(count)
plt.figure(figsize=(8,8))
Color = 'rbgyckm'
for i in range(k):
mydata = np.array(result[0][i])
plt.scatter(mydata[:,0],mydata[:,1],color = Color[i])
return result[0] data = np.loadtxt('K-means_data')
run_K_means(data,k=7)
附上结果图:
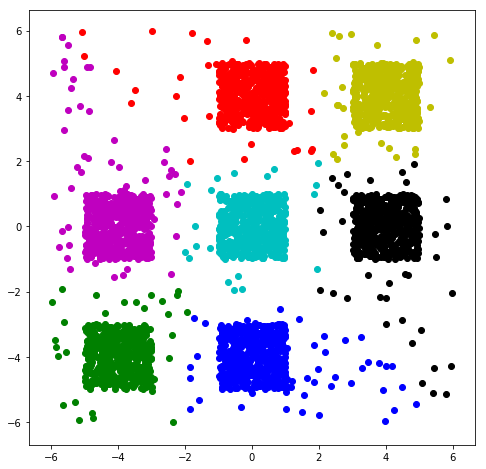
这个算法太依赖于初始种子点的选取了,随机选点很有可能会得到局部最优的结果,所以下一步学习一下怎么设置初始种子点以及分类数目。
K-means聚类的Python实现的更多相关文章
- Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=> ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- K-means聚类 的 Python 实现
K-means聚类 的 Python 实现 K-means聚类是一个聚类算法用来将 n 个点分成 k 个集群. 算法有3步: 1.初始化– K 个初始质心会被随机生成 2.分配 – K 集群通过关联到 ...
- (转) K-Means聚类的Python实践
本文转自: http://python.jobbole.com/87343/ K-Means聚类的Python实践 2017/02/11 · 实践项目 · K-means, 机器学习 分享到:1 原文 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- Kmeans 聚类 及其python实现
主要参考 K-means 聚类算法及 python 代码实现 还有 <机器学习实战> 这本书,当然前面那个链接的也是参考这本书,懂原理,会用就行了. 1.概述 K-means ...
随机推荐
- 创建jedis对象
1.先在taotao-parent的pom.xml中复制 以下内容到rest的pom.xml中 <!-- Redis客户端 --> <dependency> <group ...
- [学习OpenCV攻略][017][ARM9下移植OpenCV]
安装环境 宿主机: Red Hat Enterprise Linux Server 6.3 开发板: mini2440 相关软件: cmake-3.5.1.tar.gz.OpenCV-2.3.1a.t ...
- [国嵌攻略][159][SPI子系统]
SPI 子系统架构 1.SPI core核心:用于连接SPI客户驱动和SPI主控制器驱动,并且提供了对应的注册和注销的接口. 2.SPI controller driver主控制器驱动:用来驱动SPI ...
- .28-浅析webpack源码之compiler.resolvers
原本该在过WebpackOptionsApply时讲解这个方法的,但是当时一不小心过掉了,所以在这里补上. compiler.resolvers 该对象的三个方法均在WebpackOptionsApp ...
- 解决:mysql is blocked because of many connection errors;
标签:because service foreign errors closed 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http:// ...
- 遇到安装app不识别的情况
一般->blokfile->证书设定设置
- sqlite3使用事务处理[zz]
<!-- /* Font Definitions */ @font-face {font-family:宋体; panose-1:2 1 6 0 3 1 1 1 1 1; mso-font-al ...
- 【编程技巧】applicationContext.xml 里面可配置bean和数据库地址
<bean id="vendorManagerDao" class="com.active.vendor.dao.VendorManagerDaoImpl" ...
- 通读cheerio API ——NodeJs中的jquery
通读cheerio API ——NodeJs中的jquery 所谓工欲善其事,必先利其器,所以通读了cheerio的API,顺便翻译了一遍,有些地方因为知道的比较少,不知道什么意思,保留了英文,希望各 ...
- servlet入门学习之生命周期
一. 什么是Servlet Servlet是用Java语言编写的服务器端小程序,驻留在web服务器中,并在其中运行,扩展了web服务器的动态处理功能. 用java语言编写的java类 在web容器中运 ...