大数据开篇 MapReduce初步
最近在学习大数据相关的东西,开这篇专题来记录一下学习过程。今天主要记录一下MapReduce执行流程解析
引子(我们需要解决一个简单的单词计数(WordCount)问题)
- 1000个单词
嘿嘿,1000单词还不简单,我们直接一句shell搞定
cat file | tr ' ' '\n' | sort | uniq -c | sort -rk1 | head -n 20
- 1000G
感觉良好,写个简单的程序也很好解决。 - 1000*1000G
有点懵逼了。 - 1000*1000*1000G
这时候就该请出我们的主角MapReduce了,MapReduce能解决海量数据的计算,海到什么程度呢,理论上来说是无限。那么它是怎么解决这么大量的数据的呢?
MapReduce思想(分治思想)
| 分治思想 | MapReduce |
|---|---|
| 分解-求解 | 分:map |
| 合并 | 合:reduce |
- 下面来看看MapReduce的与单点程序具体执行流程比较
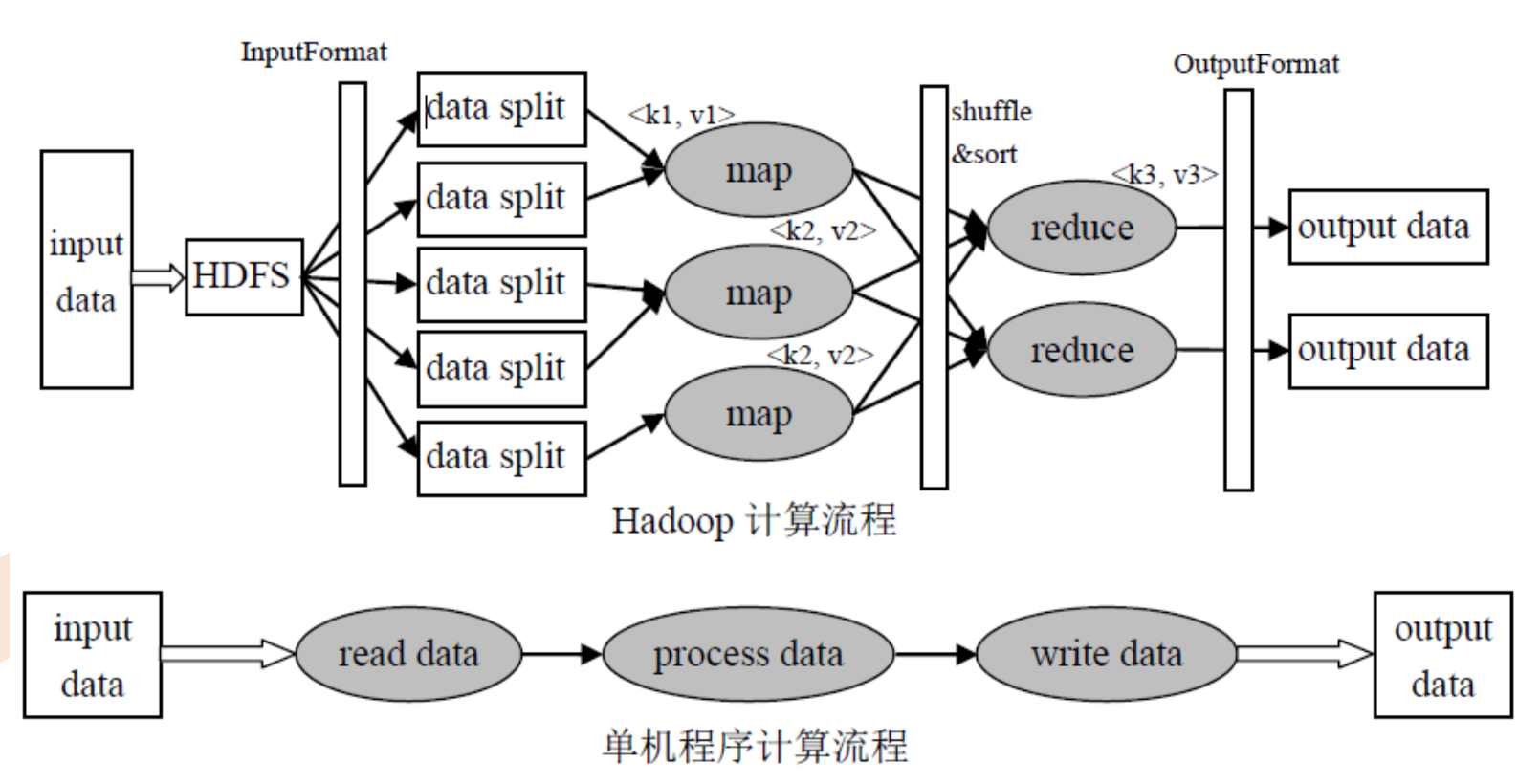
可以明显的看到和单点程序相比MapReduce数据来源于HDFS,在read data阶段作分片处理,把数据源按照不同的规模进行拆分;在process data阶段一样把任务分配给很多map来做;同样在write data阶段由一定数量的reduce来处理最终的结果。
- 上面流程是一个整体的架构图,让我们近一步看看单个MapReduce流程是怎么运行的
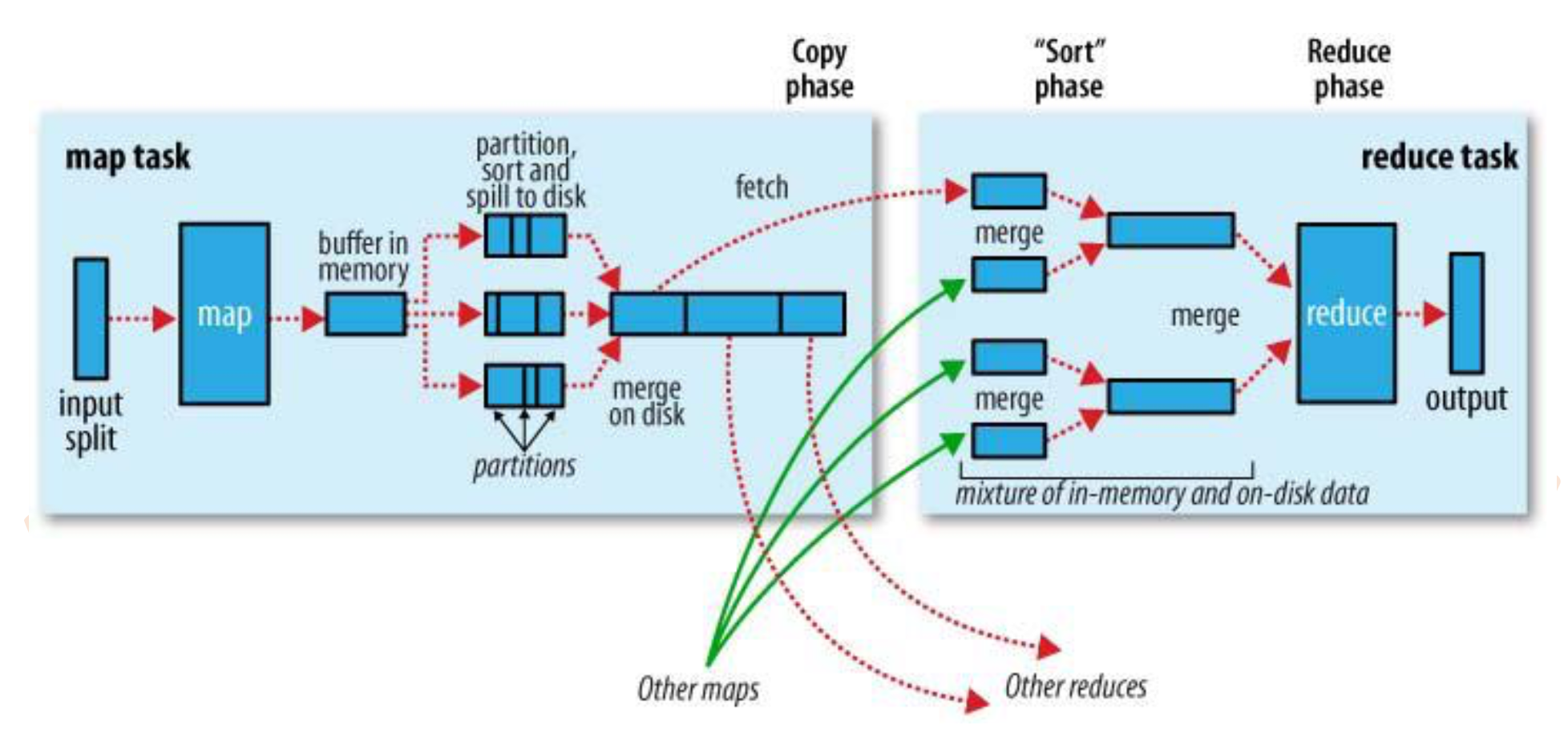
在这个阶段,一个map其实就是对应着一个split。map读取对应分片的数据,经过map函数(我们自己实现的)处理后并且经过partition到一个默认大小100M(可配置)的buffer上,当它写到80M(可配置)的时候,开始spill数据到文件,每次都会产生一个小文件,在spill的过程中写的时候会对数据进行sort(默认排序算法是快排)、Combiner。写到磁盘后每一个小文件都是有序的,那么这个多的小文件该怎么处理呢,不用想,肯定是merge,那么这么多有序的小文件,肯定是直接归并排序。每个map的数据merge完成以后,会根据不同的partition被fetch对应的reduce上面处理,reduce拿到这些数据先对数据进行merge,然后经过reduce函数(我们自己实现的)处理,并且合并多个reduce结果得到最终结果。
- 更进一步,继续深入
我们把上面的步骤进一步拆解,更详细的看看每一个步骤
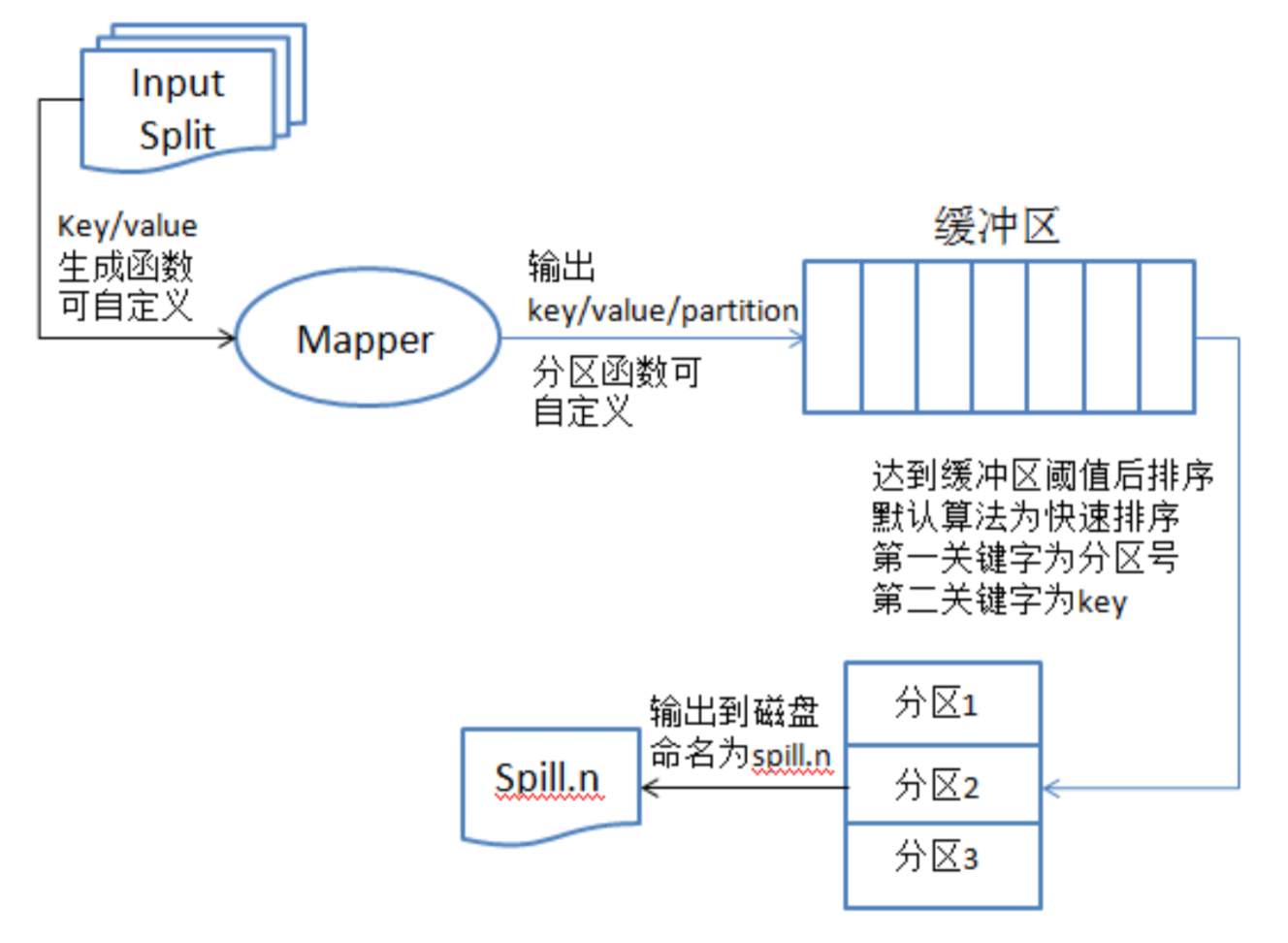
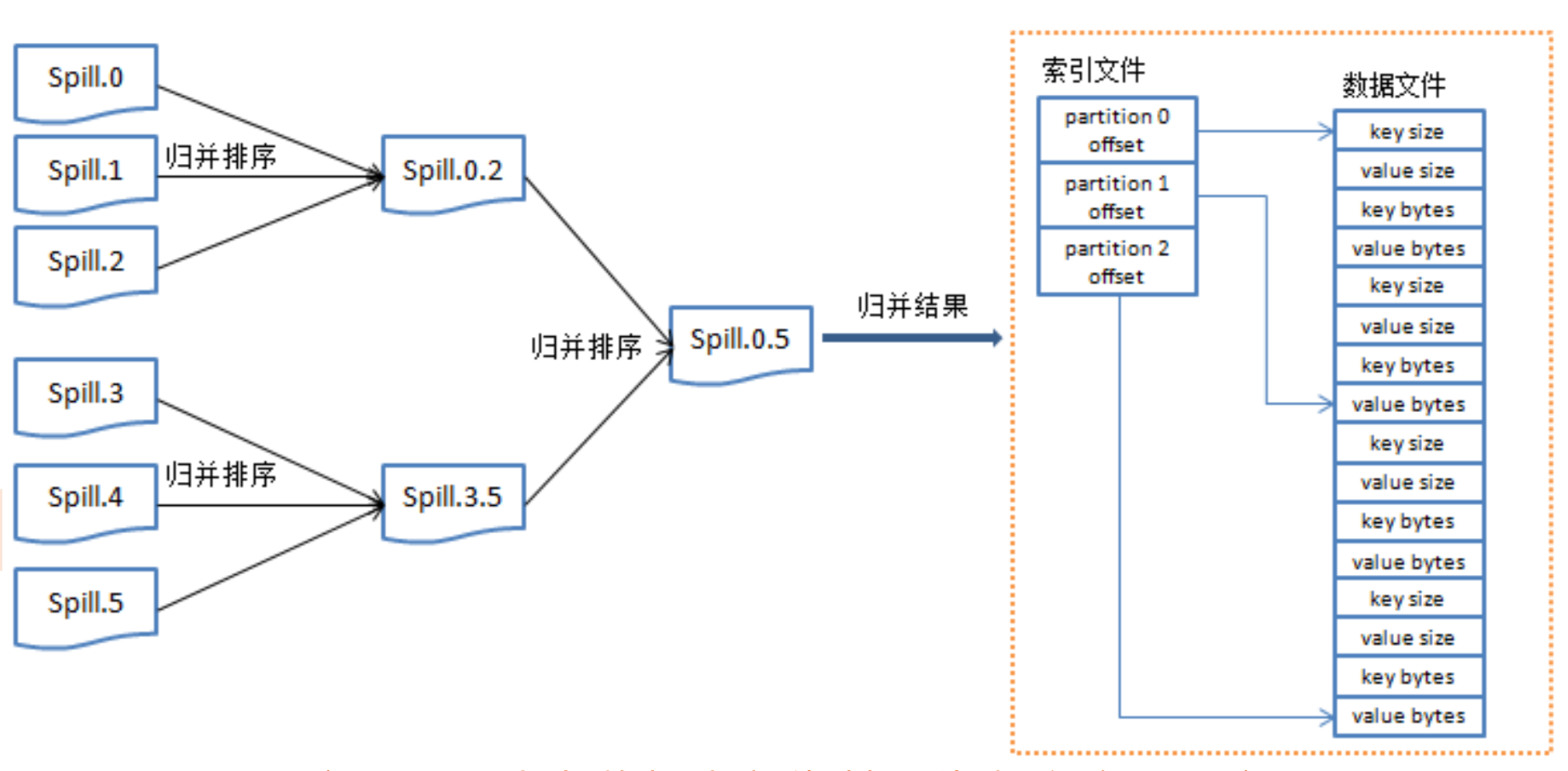

MapReduce原理
- JobTracker 主进程,负责接收客户端作业提交,调度任务到作业节点,并提供监控任务节点状态及任务进度等功能,一个MapReduce集群有一个JobTracker节点
- TaskTraceker 运行JobTracker指派的任务,并且定期的汇报状态,通过心跳实现,每一次心跳包含可用map和reduce任务数目、占用数目以及运行中的任务详情等。
附上具体任务提交流程:

大数据开篇 MapReduce初步的更多相关文章
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
- 大数据与Mapreduce
第十五章 大数据与Maprudece 一.引言 实际生活中的数据量是非常庞大的,采用单机运行的方式可能需要若干天才能出结果,这显然不符合我们的预期,为了尽快的获得结果,我们将采用分布式的方式,将计算分 ...
- 大数据技术 - MapReduce的Shuffle及调优
本章内容我们学习一下 MapReduce 中的 Shuffle 过程,Shuffle 发生在 map 输出到 reduce 输入的过程,它的中文解释是 “洗牌”,顾名思义该过程涉及数据的重新分配,主要 ...
- FusionInsight大数据开发---MapReduce与YARN应用开发
MapReduce MapReduce的基本定义及过程 搭建开发环境 代码实例及运行程序 MapReduce开发接口介绍 1. MapReduce的基本定义及过程 MapReduce是面向大数据并行处 ...
- 大数据技术 —— MapReduce 简介
本文为senlie原创,转载请保留此地址:http://www.cnblogs.com/senlie/ 1.概要很多计算在概念上很直观,但由于输入数据很大,为了能在合理的时间内完成,这些计算必须分布在 ...
- 大数据开发 | MapReduce介绍
1. MapReduce 介绍 1.1MapReduce的作用 假设有一个计算文件中单词个数的需求,文件比较多也比较大,在单击运行的时候机器的内存受限,磁盘受限,运算能力受限,而一旦将单机版程序扩展 ...
- 大数据技术 - MapReduce 作业的运行机制
前几章我们介绍了 Hadoop 的 MapReduce 和 HDFS 两大组件,内容比较基础,看完后可以写简单的 MR 应用程序,也能够用命令行或 Java API 操作 HDFS.但要对 Hadoo ...
- 大数据框架-Mapreduce过程
1.Shuffle [从mapTask到reduceTask: Mapper -> Partitioner ->Combiner -> Sort ->Reducer] mapp ...
随机推荐
- 爬取知乎话题async使用协程
import requests import json import time from pyquery import PyQuery import pandas as pd from collect ...
- 【CODEVS】2800 送外卖
[算法]最短路(floyd)+状态压缩型动态规划 [题解] 经典的TSP问题(货郎担问题):求最小权哈密顿回路(遍历全图点一次且仅一次).本题稍作改动,先说原TSP问题解法:状压DP. 状态用二进制表 ...
- Oozie与Coordinator调度讲解及系统时区配置与定时触发两种配置方式
1:修改本地linux时区 查看时区 - 号代表西 + 号 代表东 北京时间是东八区 设置时区的配置文件所在位置 cd /usr/share/zoneinfo/ 选择以亚洲的上海 的时区为基址 删除 ...
- 自定义li项目符号
使用background-image属性 先清除ul的默认list-style ul{ list-style:none } li{ background-image:url('./image/symb ...
- 爬虫--Scrapy框架的基本使用
流程框架 安装Scrapy: (1)在pycharm里直接就可以进行安装Scrapy (2)若在conda里安装scrapy,需要进入cmd里输入指令conda install scrapy ...
- jquery.cookie.js——jquery的cookie插件
一.JS文件 /*! * jQuery Cookie Plugin v1.4.1 * https://github.com/carhartl/jquery-cookie * * Copyright 2 ...
- python3学习笔记.2.基础
1.编码 默认编码是 utf-8 # -*- coding: utf-8 -*- 2.注释 单行注释 # 多行注释,用三个单引号或双引号 3.关键字 可在交互窗口查询. >>> i ...
- 配置tomcat多域名访问
C:\Windows\System32\drivers\etc下的hosts文件改成:127.0.0.1 localhost 127.0.0.1 www.greenmood.net 127.0.0.1 ...
- 关于SQLite3 编译及交叉编译的一些问题
from : http://blog.sina.com.cn/s/blog_5f2e119b0101ibwn.html SQLite3 (http://www.sqlite.org)是一个非常强大的小 ...
- acm专题---dfs+bfs
题目来源:http://hihocoder.com/problemset/problem/1049 #1049 : 后序遍历 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描 ...