python实战——文本挖掘+xgboost预测+数据处理+准确度计算整合版
if __name__=="__main__":
'''============================先导入数据=================================='''
file_train = 'F:/goverment/exceloperating/all_tocai_train.csv'
file_test = 'F:/goverment/exceloperating/all_tocai_test.csv'
importSmallContentdata(file_train,Straindata,Sart_train,Strainlabel,0)
importSmallContentdata(file_test,Stestdata,Sart_test,Stestlabel,1)
#print("Stestlabel" ,len(Stestlabel))
#print("小类导入数据完毕")
importBtestlabel(file_test)
#print("大类标签导入完毕")#共1329*4
from pandas import read_csv
import numpy as np
from sklearn.datasets.base import Bunch
import pickle #导入cPickle包并且取一个别名pickle #持久化类
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
import xlwt
import operator#排序用 Straindata=[]
Strainlabel=[]
Sart_train=[] Stestdata=[]
Stestlabel=[]
Sart_test=[] Slast=[]
Snew=[] BvsS=[]
Bnew=[]
Blast=[] class obj:
def __init__(self):
self.key=0
self.weight=0.0 def importSmallContentdata(file,data,art,label,f):
dataset=read_csv(file)
Sdata = dataset.values[:,:]
print(type(Sdata)) if f==1:
for line in Sdata:
ls=[]
ls.append(line[18])
ls.append(line[19])
ls.append(line[20])
ls.append(line[21])
Slast.append(ls)
#print(len(Slast))
#print("需要对照的小类数据准备完毕")
if f==0:
BvsS2=[]
for line in Sdata:
BvsS2.append(line[18])
BvsS2.append(line[19])
BvsS2.append(line[20])
BvsS2.append(line[21])
'''去重'''
bol=np.zeros(len(Sdata)+1)
for i in BvsS2:
if bol[i]== 0:
BvsS.append(i)
bol[i]=1
BvsS.sort()
print(BvsS) '''找到smalli不为0的装入Straindata,把数据分开'''
for smalli in range(18,22):
#print(smalli)
count=0
for line in Sdata:
count=count+1
if line[smalli]!='' and line[smalli]!=0 :
k=1
ls=[]
for i in line:
if k==1:
art.append(i)
k=k+1
continue
if k==15:#k为14并不代表是line[14],因为line是从0开始
break
ls.append(float(i))
k=k+1
data.append(ls)
label.append(line[smalli])
if f==1:
Snew.append(count) # print("为什么都超限",len(Snew)) def importBtestlabel(file):
dataset=read_csv(file)
Bdata = dataset.values[:,:] for line in Bdata:
ls=[]
ls.append(line[14])
ls.append(line[15])
ls.append(line[16])
ls.append(line[17])
Blast.append(ls)
首先导入数据

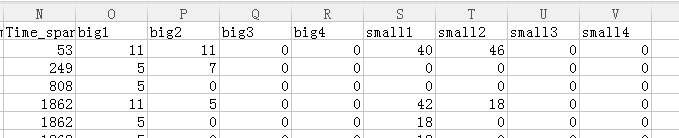
列O到列P为标签,我们先预测small的4列,先将四列分开,预测完以后,取支持度最高的前四个作为预测结果,与原数据比较,比较的准则是:本该有的都有的即可,即eg:原:1,2,0,9,则预测出来是 9,2,5,1,也是正确的,方法:将预测出来一条记录的放到由52(small的范围是0-51)个01组成的列表中中,若预测出来是9,2,5,1,那么第9个,第2个,第5个,第1个为1,其余为0,对照的时候,只要第9个,第1个,第2个为0就正确(0代表没有,不需要对照)
对文字部分我们要提取特征,取前71个特征,不足补齐为-1
def getKvector(train_set,vec,n):
nonzero=train_set.tdm.nonzero()
k=0
lis=[]
gather=[]
p=-1
for i in nonzero[0]:
p=p+1
if k==i:
a=obj()
a.key=nonzero[1][p]
a.weight=train_set.tdm[i,nonzero[1][p]]
lis.append(a)
else:
lis.sort(key=lambda obj: obj.weight, reverse=True)#对链表内为类对象的排序
gather.append(lis)
while k < i:
k=k+1
lis=[]
a=obj()
a.key=nonzero[1][p]
a.weight=train_set.tdm[i,nonzero[1][p]]
lis.append(a)
gather.append(lis)#gather存储的是每条数据的事实描述的特征向量,已经从小到大排好了,只不过每个存既有key又有weight #我们只要key,不再需要weight sj=1
for i in gather:
ls=[]
for j in i:
sj=sj+1
ls.append(float(j.key))
while sj<=n:
sj=sj+1
ls.append(-1)
sj=1
vec.append(ls) '''读取停用词'''
def _readfile(path):
with open(path, "rb") as fp:
content = fp.read()
return content ''' 读取bunch对象'''
def _readbunchobj(path):
with open(path, "rb") as file_obj:
bunch = pickle.load(file_obj)
return bunch '''写入bunch对象'''
def _writebunchobj(path, bunchobj):
with open(path, "wb") as file_obj:
pickle.dump(bunchobj, file_obj) def buildtrainbunch(bunch_path,art_train,trainlabel):
bunch = Bunch(label=[],contents=[])
for item1 in trainlabel:
bunch.label.append(item1) #trainContentdatasave=[] #存储所有训练和测试数据的分词
for item2 in art_train:
item2=str(item2)
item2 = item2.replace("\r\n", "")
item2 = item2.replace(" ", "")
content_seg=jieba.cut(item2)
save2=''
for item3 in content_seg:
if len(item3) > 1 and item3!='\r\n':
#trainContentdatasave.append(item3)
save2=save2+","+item3
bunch.contents.append(save2)
with open(bunch_path, "wb") as file_obj:
pickle.dump(bunch, file_obj)
print("构建训练数据文本对象结束!!!") def buildtestbunch(bunch_path,art_test,testlabel):
bunch = Bunch(label=[],contents=[])
for item1 in testlabel:
bunch.label.append(item1) #testContentdatasave=[] #存储所有训练和测试数据的分词
for item2 in art_test:
item2=str(item2)
item2 = item2.replace("\r\n", "")
item2 = item2.replace(" ", "")
content_seg=jieba.cut(item2)
save2=''
for item3 in content_seg:
if len(item3) > 1 and item3!='\r\n':
#testContentdatasave.append(item3)
save2=save2+","+item3
bunch.contents.append(save2)
with open(bunch_path, "wb") as file_obj:
pickle.dump(bunch, file_obj)
print("构建测试数据文本对象结束!!!")
def vector_space(stopword_path,bunch_path,space_path): stpwrdlst = _readfile(stopword_path).splitlines()#读取停用词
bunch = _readbunchobj(bunch_path)#导入分词后的词向量bunch对象
#构建tf-idf词向量空间对象
tfidfspace = Bunch(label=bunch.label,tdm=[], vocabulary={}) #权重矩阵tdm,其中,权重矩阵是一个二维矩阵,tdm[i][j]表示,第j个词(即词典中的序号)在第i个类别中的IF-IDF值 #使用TfidVectorizer初始化向量空间模型
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5, min_df=0.0001,use_idf=True,max_features=15000)
#print(vectorizer)
#文本转为词频矩阵,单独保存字典文件
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary = vectorizer.vocabulary_
#创建词袋的持久化
_writebunchobj(space_path, tfidfspace)
print("if-idf词向量空间实例创建成功!!!") def testvector_space(stopword_path,bunch_path,space_path,train_tfidf_path): stpwrdlst = _readfile(stopword_path).splitlines()#把停用词变成列表
bunch = _readbunchobj(bunch_path)
tfidfspace = Bunch(label=bunch.label,tdm=[], vocabulary={})
#导入训练集的TF-IDF词向量空间 ★★
trainbunch = _readbunchobj(train_tfidf_path)
tfidfspace.vocabulary = trainbunch.vocabulary vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.7, vocabulary=trainbunch.vocabulary, min_df=0.001) tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
_writebunchobj(space_path, tfidfspace)
print("if-idf词向量空间实例创建成功!!!")
'''==========================================================tf-idf对Bar进行文本特征提取============================================================================'''
#导入分词后的词向量bunch对象
train_bunch_path ="F:/goverment/exceloperating/trainbunch.bat"#Bunch保存路径
train_space_path = "F:/goverment/exceloperating/traintfdifspace.dat"
test_bunch_path ="F:/goverment/exceloperating/testbunch.bat"
test_space_path = "F:/goverment/exceloperating/testtfdifspace.dat"
stopword_path ="F:/goverment/exceloperating/hlt_stop_words.txt" '''============================================================tf-idf对Sart进行文本特征提取=============================================================================='''
buildtrainbunch(train_bunch_path,Sart_train,Strainlabel)
buildtestbunch(test_bunch_path,Sart_test,Stestlabel) vector_space(stopword_path,train_bunch_path,train_space_path)
testvector_space(stopword_path,test_bunch_path,test_space_path,train_space_path) train_set=_readbunchobj(train_space_path)
test_set=_readbunchobj(test_space_path) '''训练数据''' S_vec_train=[]
getKvector(train_set,S_vec_train,76) '''测试数据''' S_vec_test=[]
getKvector(test_set,S_vec_test,76) '''=================将得到的61个特征和之前的其它特征合并Btraindata==================''' '''小类训练数据'''
S_vec_train=np.array(S_vec_train)
#print(type(S_vec_train))
#print(S_vec_train.shape)
Straindata=np.array(Straindata)
#print(type(Straindata))
#print(Straindata.shape)
Straindata=np.hstack((S_vec_train,Straindata))
#print(Straindata) '''小类测试数据'''
S_vec_test=np.array(S_vec_test)
Stestdata=np.array(Stestdata)
Stestdata=np.hstack((S_vec_test,Stestdata)) '''
B_vec_test=np.array(B_vec_test)
Btestdata=np.array(Btestdata)
Btestdata=np.hstack((B_vec_test,Btestdata))
import xlwt
myexcel = xlwt.Workbook()
sheet = myexcel.add_sheet('sheet')
si=-1
sj=-1
for i in range(len(Btraindata)):
si=si+1
for j in range(len(Btraindata[0])):
sj=sj+1
sheet.write(si,sj,str(Btraindata[i,j]))
sj=-1
myexcel.save("vector.xls")
# =============================================================================
# import xlwt
# myexcel = xlwt.Workbook()
# sheet = myexcel.add_sheet('sheet')
# si=-1
# sj=-1
# for i in range(len(Btestdata)):
# si=si+1
# for j in range(len(Btestdata[0])):
# sj=sj+1
# sheet.write(si,sj,str(Btestdata[i,j]))
# sj=-1
# myexcel.save("vector.xls")
接下里,我用了XGBClassifier来分类,因为这是我尝试了多个分类器后,准确度最高的。
'''==========================分类算精度==========================='''
print("分类算小类精度")
Strainlabel=np.array(Strainlabel)
Strainlabel=np.array(Strainlabel)
from xgboost import XGBClassifier
from sklearn import metrics
clf= XGBClassifier(learning_rate =0.1,
n_estimators=1150,
max_depth=2,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,#没用
scale_pos_weight=1,#没用
seed=27)
clf.fit(Straindata, Strainlabel)
predict=clf.predict(Stestdata)
aa=metrics.accuracy_score(Stestlabel, predict)
最后就是对照的过程,数据处理过程比较繁琐。把大类的概率定义为小类相加,比如预测一个工程存在的大类技术问题,大类1的概率=小类1.1的概率+1.2+1.3,以此类推,再从11个概率中挑前3个最大概率对应的大类问题。
下图是大类与小类的对应关系:
''''============================输出技术问题及其可能性================'''
class attri:
def __init__(self):
self.key=0
self.weight=0.0 '''====================小类======================='''
attribute_proba=clf.predict_proba(Stestdata)
#print(type(attribute_proba)) '''======================================================='''
# =============================================================================
# myexcel = xlwt.Workbook()
# sheet = myexcel.add_sheet('sheet')
# si=-1
# sj=-1
# #cys=1
# for i in attribute_proba:
# si=si+1
# #print("对于记录 %d:" % cys)
# #cys=cys+1
# for j in i:
# sj=sj+1
# sheet.write(si,sj,str(j))
# #print ("发生技术问题 %d 的可能性是:%.2f %%" % (j.key,j.weight*100))
# sj=-1
# myexcel.save("proba.xls")
# =============================================================================
'''==========================================================================='''
'''获得小类发生概率和序号的结合,第一个数为序号'''
Bnew2=[]
count=0 for i in attribute_proba:
ls=[]
ls.append(Snew[count])
count=count+1
for j in i:
ls.append(j)
Bnew2.append(ls)
'''对Bnew去重'''
bol=np.zeros(len(Slast)+1)
for lis in Bnew2:
if bol[lis[0]]==0:
Bnew.append(lis)
bol[lis[0]]=1 #print(len(Bnew))#去重后为1162 for i in range(len(Slast)+1):
if i==0:
continue
if bol[i]==0:
ls=[]
ls.append(i)
for j in range(len(attribute_proba[0])):
ls.append(0)
Bnew.append(ls)
#print("Bnew",len(Bnew)) #为1329 Bnew.sort(key=operator.itemgetter(0))
#print(Bnew) Bpro=[] for line in Bnew:
ls=np.zeros(12)
for i in range(len(line)):
if i==0:
continue
elif BvsS[i]==0:
ls[0]+=line[i]
elif BvsS[i]==1 or BvsS[i]==2 or BvsS[i]==3:
ls[1]+=line[i]
elif BvsS[i]==4 or BvsS[i]==5 or BvsS[i]==6:
ls[2]+=line[i]
elif BvsS[i]==8 or BvsS[i]==9 or BvsS[i]==10 or BvsS[i]==11 or BvsS[i]==12:
ls[3]+=line[i]
elif BvsS[i]==13 or BvsS[i]==14 or BvsS[i]==15 or BvsS[i]==16:
ls[4]+=line[i]
elif BvsS[i]==17 or BvsS[i]==18 or BvsS[i]==19 or BvsS[i]==20 or BvsS[i]==21 or BvsS[i]==22 or BvsS[i]==23 or BvsS[i]==24:
ls[5]+=line[i]
elif BvsS[i]==25 or BvsS[i]==26 or BvsS[i]==27 or BvsS[i]==28 or BvsS[i]==29:
ls[6]+=line[i]
elif BvsS[i]==30 or BvsS[i]==31 or BvsS[i]==32:
ls[7]+=line[i]
elif BvsS[i]==33:
ls[8]+=line[i]
elif BvsS[i]==34 or BvsS[i]==35 or BvsS[i]==36 or BvsS[i]==37:
ls[9]+=line[i]
elif BvsS[i]==38 or BvsS[i]==39 :
ls[10]+=line[i]
else:
ls[11]+=line[i]
Bpro.append(ls) Bnew=[]
Bnew4=[]
for line in Bpro:
ls=[]
for i in range(len(line)):
a=obj()
a.key=i
a.weight=line[i]
ls.append(a)
ls.sort(key=lambda obj: obj.weight, reverse=True)
Bnew.append(ls)
lis=[]
lis.append(ls[0].key)
lis.append(ls[1].key)
lis.append(ls[2].key)
lis.append(ls[3].key)
Bnew4.append(lis) #print(Bnew4) '''计算大类准确率,转成01编码'''
Bnew_one=[]
for lis in Bnew4:
bol=np.zeros(12)
bol=bol.tolist()
bol[lis[0]],bol[lis[1]],bol[lis[2]],bol[lis[3]]=1,1,1,1
Bnew_one.append(bol) Bnew_one=np.array(Bnew_one)
#print(Snew_one.shape)
#print(Slast_one.shape)#都为1329*51 count=0
si=-1
for line in Blast:
si+=1
f=1
for j in line:
if j == 0:
continue
if Bnew_one[si,j]!=1:
f=0
break
if f==1:
count=count+1
print("大类准确率为:",count*1.0/s) '''准确率计算完毕''' # =============================================================================
#
# myexcel = xlwt.Workbook()
# sheet = myexcel.add_sheet('sheet')
# si=-1
# sj=-1
# #cys=1
# for i in Bnew4:
# si=si+1
# #print("对于记录 %d:" % cys)
# #cys=cys+1
# for j in i:
# sj=sj+1
# sheet.write(si,sj,str(j))
# #print ("发生技术问题 %d 的可能性是:%.2f %%" % (j.key,j.weight*100))
# sj=-1
# myexcel.save("Bpro_new.xls")
#
# myexcel = xlwt.Workbook()
# sheet = myexcel.add_sheet('sheet')
# si=-1
# sj=-1
# #cys=1
# for i in Blast:
# si=si+1
# #print("对于记录 %d:" % cys)
# #cys=cys+1
# for j in i:
# sj=sj+1
# sheet.write(si,sj,str(j))
# #print ("发生技术问题 %d 的可能性是:%.2f %%" % (j.key,j.weight*100))
# sj=-1
# myexcel.save("Bpro_last.xls")
#
# =============================================================================
# =============================================================================
# class obj:
# def __init__(self):
# self.key=0
# self.weight=0.0
# ============================================================================= '''================================================================================''' label=[]
for i in attribute_proba:
lis=[]
k=0
while k<4:
k=k+1
p=1
mm=0
sj=-1
for j in i:
sj=sj+1
if j>mm:
mm=j
p=sj
i[p]=0#难道是从1开始?
#a=attri()
#a.key=p
#a.weight=mm
#lis.append(a)
lis.append(p)
label.append(lis)
#接下来将label和snew结合,再排序去重就可以和slast比较了
#print("为什么都超限",len(Snew))
#print("label",len(label))
count=0
for lis in label:
lis.append(Snew[count])
count=count+1
print("结合完成,准备去重!")#此时label和Snew的长度都为1439 bol=np.zeros(len(label)+1)
Snew=[]
for lis in label:
if bol[lis[4]]==0:
Snew.append(lis)
bol[lis[4]]=1 #print(len(Snew))#去重后为1162 for i in range(len(Slast)+1):
if i==0:
continue
if bol[i]==0:
ls=[]
ls.append(0)
ls.append(0)
ls.append(0)
ls.append(0)
ls.append(i)
Snew.append(ls)
#print("Snew",len(Snew)) #为1329 print("去重完毕,准备排序!") Snew.sort(key=operator.itemgetter(4))
print("排序完毕,准备比较!") s=len(Snew)
#print(s) Snew_one=[]
for lis in Snew:
bol=np.zeros(51)
bol=bol.tolist()
bol[lis[0]],bol[lis[1]],bol[lis[2]],bol[lis[3]]=1,1,1,1
Snew_one.append(bol) Snew_one=np.array(Snew_one)
#print(Snew_one.shape)
#print(Slast_one.shape)#都为1329*51 count=0
si=-1
for line in Slast:
si+=1
f=1
for j in line:
if j == 0:
continue
if Snew_one[si,j]!=1:
f=0
break
if f==1:
count=count+1
print(si)
print(count)
print(s)
print("小类准确率为:",count*1.0/s) myexcel = xlwt.Workbook()
sheet = myexcel.add_sheet('sheet')
si=-1
sj=-1
#cys=1
#print(Snew)
for i in Snew:
si=si+1
#print("对于记录 %d:" % cys)
#cys=cys+1
for j in i:
sj=sj+1
sheet.write(si,sj,str(j))
#print ("发生技术问题 %d 的可能性是:%.2f %%" % (j.key,j.weight*100))
sj=-1
myexcel.save("Snew.xls") myexcel = xlwt.Workbook()
sheet = myexcel.add_sheet('sheet')
si=-1
sj=-1
#cys=1
for i in Slast:
si=si+1
#print("对于记录 %d:" % cys)
#cys=cys+1
for j in i:
sj=sj+1
sheet.write(si,sj,str(j))
#print ("发生技术问题 %d 的可能性是:%.2f %%" % (j.key,j.weight*100))
sj=-1
myexcel.save("Slast1.xls") # =============================================================================
# print('挑几个输出')
# import xlwt
# myexcel = xlwt.Workbook()
# sheet = myexcel.add_sheet('sheet')
# si=-2
# sj=-1
# #cys=1
# for i in label:
# si=si+2
# #print("对于记录 %d:" % cys)
# #cys=cys+1
# for j in i:
# sj=sj+1
# sheet.write(si,sj,str(j.key))
# sheet.write(si+1,sj,str(j.weight))
# #print ("发生技术问题 %d 的可能性是:%.2f %%" % (j.key,j.weight*100))
# sj=-1
# myexcel.save("proba_small.xls")
#
# ============================================================================= # -*- coding: utf-8 -*-
python实战——文本挖掘+xgboost预测+数据处理+准确度计算整合版的更多相关文章
- 自然语言处理之中文分词器-jieba分词器详解及python实战
(转https://blog.csdn.net/gzmfxy/article/details/78994396) 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自 ...
- Storm 实战:构建大数据实时计算
Storm 实战:构建大数据实时计算(阿里巴巴集团技术丛书,大数据丛书.大型互联网公司大数据实时处理干货分享!来自淘宝一线技术团队的丰富实践,快速掌握Storm技术精髓!) 阿里巴巴集团数据平台事业部 ...
- 再一波Python实战项目列表
前言: 近几年Python可谓是大热啊,很多人都纷纷投入Python的学习中,以前我们实验楼总结过多篇Python实战项目列表,不但有用还有趣,最主要的是咱们实验楼不但有详细的开发教程,更有在线开发环 ...
- python实战:用70行代码写了一个山炮计算器!
python实战训练:用70行代码写了个山炮计算器! 好了...好了...各位因为我是三年级而发牢骚的各位伙伴们,我第一次为大家插播了python的基础实战训练.这个,我是想给,那些python基础一 ...
- 科学经得起实践检验-python3.6通过决策树实战精准准确预测今日大盘走势(含代码)
科学经得起实践检验-python3.6通过决策树实战精准准确预测今日大盘走势(含代码) 春有百花秋有月,夏有凉风冬有雪: 若无闲事挂心头,便是人间好时节. --宋.无门慧开 不废话了,以下训练模型数据 ...
- XGBoost:在Python中使用XGBoost
原文:http://blog.csdn.net/zc02051126/article/details/46771793 在Python中使用XGBoost 下面将介绍XGBoost的Python模块, ...
- 零基础入门Python实战:四周实现爬虫网站 Django项目视频教程
点击了解更多Python课程>>> 零基础入门Python实战:四周实现爬虫网站 Django项目视频教程 适用人群: 即将毕业的大学生,工资低工作重的白领,渴望崭露头角的职场新人, ...
- python数据分析 Numpy基础 数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
- 【原】python中文文本挖掘资料集合
这些网址是我在学习python中文文本挖掘时觉得比较好的网站,记录一下,后期也会不定期添加: 1.http://www.52nlp.cn/python-%E7%BD%91%E9%A1%B5%E7% ...
随机推荐
- 破解google翻译API全过程
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/6554340.html 前言 google的翻译不得不承认它 ...
- idea 配置springmvc+mybatis(图文教程)
idea配置 spirngmvc+maven+mybatis 数据库采用的是mysql 服务器容器用的是tomcat8 废话不多说直接干! 首先新建一个 maven工程, "File&qu ...
- continue的作用
特别有用,用于循环中-跳过不满足某个条件的某轮循环continue后面的语句
- SpringMVC札集(06)——转发和重定向
自定义View系列教程00–推翻自己和过往,重学自定义View 自定义View系列教程01–常用工具介绍 自定义View系列教程02–onMeasure源码详尽分析 自定义View系列教程03–onL ...
- Java基础从头再来?
今天遇到一个就是从后台解析的时候出现null字符串的处理 bug图如下每一个name属性都包含null 对于那些java基础好的直接撸码了,我就是不会哈哈! 最后请教别人还是解决了这个问题 简单分享下 ...
- D. Closest Equals(线段树)
题目链接: D. Closest Equals time limit per test 3 seconds memory limit per test 256 megabytes input stan ...
- 【剑指offer】09-3变态跳台阶
原创博文,转载请注明出处! # 本文是牛客网<剑指offer>刷题笔记,笔记索引连接 1.题目 # 一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级.求该青蛙跳上一个n级的 ...
- CocoaPods(pod install一直不动)
CocoaPods安装和使用教程 如何在Mac 终端升级ruby版本 RubyGems 镜像 cocoapods无法使用(mac os 10.11升级导致pod: command not found)
- Jmeter查看结果树
取样结果: Thread Name: test 1-2 线程名称:测试1 - 2Sample S ...
- request接收表单提交数据及其中文参数乱码问题
一.request接收表单提交数据: getParameter(String)方法(常用) getParameterValues(String name)方法(常用) getParameterMap( ...