二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
Requests请求
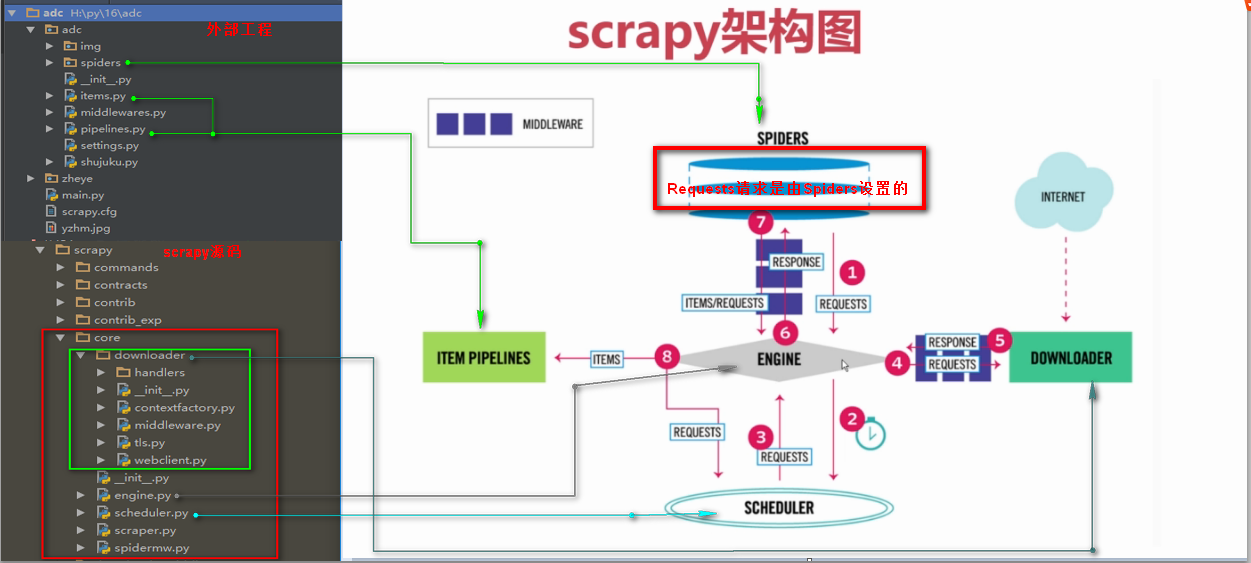
Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的
Requests()方法提交一个请求
参数:
url= 字符串类型url地址
callback= 回调函数名称
method= 字符串类型请求方式,如果GET,POST
headers= 字典类型的,浏览器用户代理
cookies= 设置cookies
meta= 字典类型键值对,向回调函数直接传一个指定值
encoding= 设置网页编码
priority= 默认为0,如果设置的越高,越优先调度
dont_filter= 默认为False,如果设置为真,会过滤掉当前url

# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
Response响应
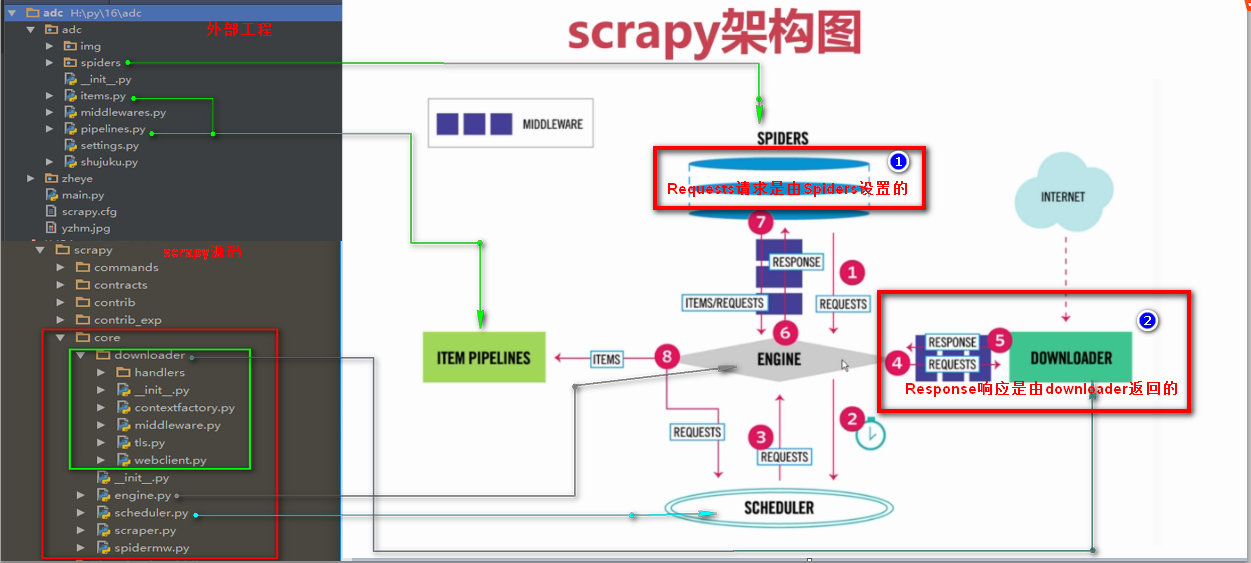
Response响应是由downloader返回的响应

Response响应参数
headers 返回响应头
status 返回状态吗
body 返回页面内容,字节类型
url 返回抓取url
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
print(response.headers)
print(response.status)
# print(response.body)
print(response.url)
二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍的更多相关文章
- 第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍 Requests请求 Requests请求就是我们在爬虫文件写的Requests() ...
- 二十六 Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
downloadmiddleware介绍中间件是一个框架,可以连接到请求/响应处理中.这是一种很轻的.低层次的系统,可以改变Scrapy的请求和回应.也就是在Requests请求和Response响应 ...
- 三十五 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 二十九 Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以 ...
- 二十八 Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
cookie禁用 就是在Scrapy的配置文件settings.py里禁用掉cookie禁用,可以防止被通过cookie禁用识别到是爬虫,注意,只适用于不需要登录的网页,cookie禁用后是无法登录的 ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- 四十五 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
bool查询说明 filter:[],字段的过滤,不参与打分must:[],如果有多个查询,都必须满足[并且]should:[],如果有多个查询,满足一个或者多个都匹配[或者]must_not:[], ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
随机推荐
- JAVA集合详解(Collection和Map接口)
原文地址http://blog.csdn.net/lioncode/article/details/8673391 在JAVA的util包中有两个所有集合的父接口Collection和Map,它们的父 ...
- javascript笔记——js获取input标签中光标的索引
出处:http://www.cnblogs.com/MrZouJian/p/5850553.html function getTxt1CursorPosition(){ var oTxt1 = doc ...
- Linux系统——最小化安装
一.虚拟机进行Linux minimal 安装 网络连接:选择“自定义”——>VMnet8(NAT模式) #PC与NAT网络的虚拟机在不同网段,此时虚拟网卡作为网关建立通信 NAT模式可直接上I ...
- java反射子之获取方法信息(二)
一.获取方法 1.方法作用. 2. 二.获取方法信息.(修饰符,返回值,方法名称,参数列表,抛出的异常). ############################################## ...
- 基于TSUNG对MQTT进行压力测试-基础概念温习
[单台Broker压测结果]请移步另一篇博客:http://www.cnblogs.com/lingyejun/p/7941271.html 一.TCP报头部中的SYN.FIN.ACK: ACK : ...
- 32. Longest Valid Parentheses(最长括号匹配,hard)
Given a string containing just the characters '(' and ')', find the length of the longest valid (w ...
- Codeforces Round #412 (rated, Div. 2, base on VK Cup 2017 Round 3) A Is it rated?
地址:http://codeforces.com/contest/807/problem/C 题目: C. Success Rate time limit per test 2 seconds mem ...
- Codeforces Round #403 (Div. 2, based on Technocup 2017 Finals) E Underground Lab
地址:http://codeforces.com/contest/782/problem/E 题目: E. Underground Lab time limit per test 1 second m ...
- window连接linux共享
前提说明:windows主机信息:192.168.1.100 帐号:abc 密码:123 共享文件夹:sharelinux主机信息:192.168.1.200 帐号:def 密码:456 共享文件夹: ...
- Apache-solr
1.1. 下载 从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr4.10.3,根据Solr的运行环境,Linux下需要下载lucene-4.10.3.t ...