[DeeplearningAI笔记]序列模型2.1-2.2词嵌入word embedding
5.2自然语言处理
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.1词汇表征 Word representation
- 原先都是使用词汇表来表示词汇,并且使用1-hot编码的方式来表示词汇表中的词汇。
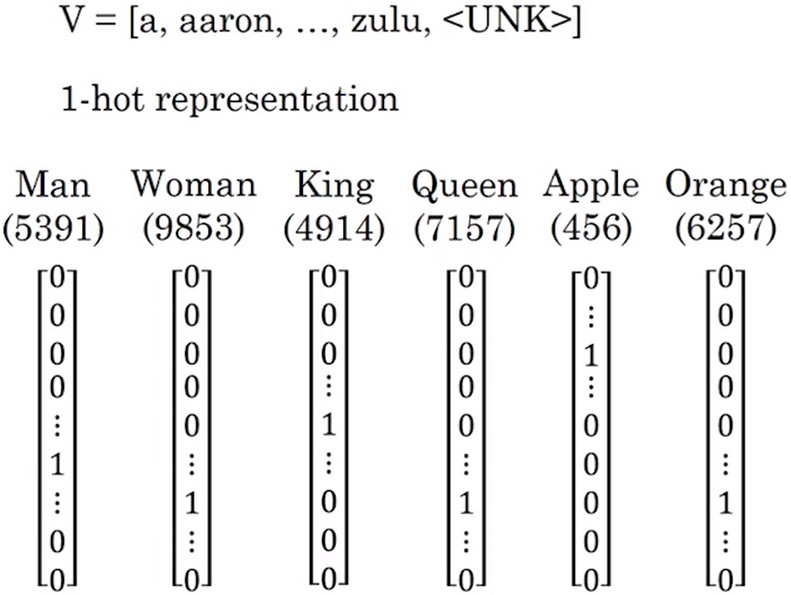
- 这种表示方法最大的缺点是 它把每个词孤立起来,这样使得算法对相关词的泛化能力不强
- 例如:对于已知句子“I want a glass of orange ___ ” 很可能猜出下一个词是"juice".
- 如果模型已知读过了这个句子但是当看见句子"I want a glass of apple ___ ",算法也不能猜出下一个词汇是"juice",因为算法本身并不知道“orange”和“apple”之间的关系。也许比起苹果,橙子与其他单词之间的距离更近。即算法并不能从“orange juice”是一个很常见的短语而推导出“apple juice”也是一个常见的短语。
- 这是因为任意两个用“one-hot”编码表示的单词的内积都是0。
特征表示:词嵌入 (Featurized representation: word embedding)
- 使用特征化的方法来表示每个词,假如使用性别来作为一个特征,用以表示这些词汇和 性别 之间的关系。
| Man | Woman | King | Queen | Apple | Orange | |
|---|---|---|---|---|---|---|
| Gender | -1 | 1 | -0.95 | 0.97 | 0.00 | 0.01 |
- 当然也可以使用这种方法表示这些词汇和 高贵 之间的关系。
| Man | Woman | King | Queen | Apple | Orange | |
|---|---|---|---|---|---|---|
| Royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 | 0.00 |
- 使用各种特征对词汇表中的单词进行表示
| Man | Woman | King | Queen | Apple | Orange | |
|---|---|---|---|---|---|---|
| Gender | -1 | 1 | -0.95 | 0.97 | 0.00 | 0.01 |
| Royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 | 0.00 |
| Age | 0.03 | 0.02 | 0.7 | 0.69 | 0.03 | -0.02 |
| Food | 0.09 | 0.01 | 0.02 | 0.01 | 0.95 | 0.97 |
- 假设为了表示出词汇表中的单词,使用300个特征进行描述,则词汇表中的每个单词都被表示为一个300维的向量。此时使用e_NO.表示特定的单词,例如Man表示为\(e_{5391}\),Woman表示为\(e_{9853}\),King表示为\(e_{4914}\)
- 对于词嵌入的表示形式通过大量不同的特征来表示词汇,在填词处理时,会更容易通过Orange juice而联想到 Apple juice.
可视化词向量 (Visualizing word embedding)
Maaten L V D, Hinton G. Visualizing Data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(2605):2579-2605.
- 对于词向量的可视化,是将300维的特征映射到一个2维空间中--t-SNE算法

2.2使用词嵌入 Using word embeddings
- 继续使用实体命名识别(named entity recognition)的例子,示例:"Sally Johnson is an orange farmer"Sally Johnson 是一个种橙子的农民。对于Sally Johnson,我们能很快识别出这是一个人名,这是因为看到了"orange farmer"这个词,告诉我们Sally Johnson是一个农民。
- 使用词嵌入的方式,很快能够识别出橙子和苹果是同类事物。在句子“Sally Johnson is an orange farmer”中识别出Sally Johnson是一个人名后,在句子“Robert Lin is an apple farmer”中也可以很容易的识别出Robert Lin是一个人名。
- 词嵌入文本识别的方法基于的是一个巨大的文本库,只有使用巨量的文本作为训练集的基础上,系统才会真正的有效。一个NLP系统中,使用的文本数量达到了1亿甚至是100亿。
- 在你的识别系统中,也许训练集只有100K的训练数据,但是可以使用迁移学习的方法,从大量无标签的文本中学习到大量语言知识。
将迁移学习运用到词嵌入 (Transfer learning and word embeddings)
- 先从一个非常大的文本集中学习词嵌入,或者从网上下载预训练好的词嵌入模型。
- 使用词嵌入模型,将其迁移到自己的新的只有少量标注的训练集的任务中。
- 优化模型:持续使用新的数据来微调自身的词嵌入模型。
- 词嵌入技术在自身的标注训练集相对较少时优势最为明显。在 实体命名识别(named entity recognition),文本摘要(text summarization),文本解析(co-reference resolution),指代消解(parsing)中应用最为广泛 在 语言模型(language modeling), 机器翻译(Machine translation)中应用较少 因为这些任务中,你有大量的数据而不一定需要使用到词嵌入技术。
词嵌入与人脸编码(word embeddings and face encoding)
Taigman Y, Yang M, Ranzato M, et al. DeepFace: Closing the Gap to Human-Level Performance in Face Verification[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2014:1701-1708.
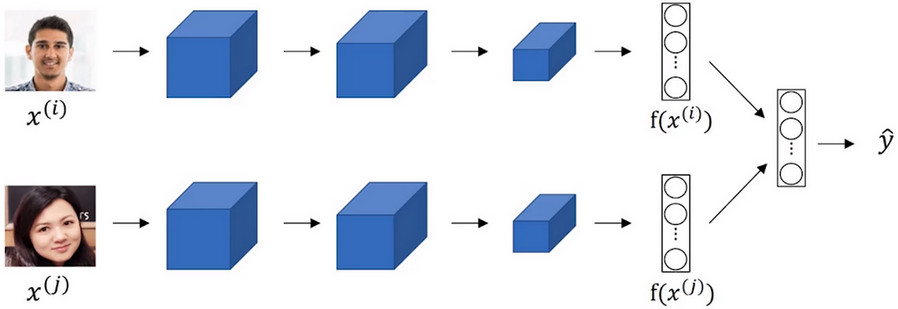
- 词嵌入技术与人脸编码技术之间有奇妙的关系,在人脸编码任务中,通过卷积神经网路将两张人脸图片进行编码成为两个128维的数据向量,然后经过比较判断两张图片是否来自于同一张人脸。
- 对于人脸识别问题,无论这张图片原先是否认识过,经过卷积神经网络处理后,都会得到一个向量表征。
- 对于词嵌入问题,则是有一个固定的词汇表,对于词汇表中的每个单词学习一个固定的词嵌入表示方法。而对于没有出现在词汇表中的单词,视其为UNK(unknowed word)
[DeeplearningAI笔记]序列模型2.1-2.2词嵌入word embedding的更多相关文章
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- [DeeplearningAI笔记]序列模型2.3-2.5余弦相似度/嵌入矩阵/学习词嵌入
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3词嵌入的特性 properties of word embedding Mikolov T, Yih W T, Zwe ...
- [DeeplearningAI笔记]序列模型3.9-3.10语音辨识/CTC损失函数/触发字检测
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.9语音辨识 Speech recognition 问题描述 对于音频片段(audio clip)x ,y生成文本 ...
- [DeeplearningAI笔记]序列模型3.7-3.8注意力模型
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.7注意力模型直观理解Attention model intuition 长序列问题 The problem of ...
- [DeeplearningAI笔记]序列模型3.6Bleu得分/机器翻译得分指标
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.6Bleu得分 在机器翻译中往往对应有多种翻译,而且同样好,此时怎样评估一个机器翻译系统是一个难题. 常见的解决 ...
- [DeeplearningAI笔记]序列模型3.3集束搜索
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.3 集束搜索Beam Search 对于机器翻译来说,给定输入的句子,会返回一个随机的英语翻译结果,但是你想要一 ...
- [DeeplearningAI笔记]序列模型3.2有条件的语言模型与贪心搜索的不可行性
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.2选择最可能的句子 Picking the most likely sentence condition lan ...
- [DeeplearningAI笔记]序列模型3.1基本的 Seq2Seq /image to Seq
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.1基础模型 [1] Sutskever I, Vinyals O, Le Q V. Sequence to Se ...
- [DeeplearningAI笔记]序列模型1.10-1.12LSTM/BRNN/DeepRNN
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10长短期记忆网络(Long short term memory)LSTM Hochreiter S, Schmidhu ...
- [DeeplearningAI笔记]序列模型1.7-1.9RNN对新序列采样/GRU门控循环神经网络
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.7对新序列采样 基于词汇进行采样模型 在训练完一个模型之后你想要知道模型学到了什么,一种非正式的方法就是进行一次新序列采 ...
随机推荐
- winform界面之固定大小随dpi
场景: 已经更改成大小可随dpi改变,可是在用applyresoures()之后(添加更改语言功能),发现控件大小失真. 分析:applyresoures()是把该控件的属性改为程序设计的固定大小,不 ...
- DescriptionAttribute Class
指定属性或事件的描述. [Description("The image associated with the control"),Category("Appearanc ...
- 使用 python 管理 mysql 开发工具箱 - 2
这篇博文接着上篇文章<使用 python 管理 mysql 开发工具箱 - 1>,继续写下自己学习 python 管理 MySQL 中的知识记录. 一.MySQL 的读写分离 学习完 My ...
- VMware12 pro装unlocker207补丁后依然没有apple mac选项,问题解决
把VMware所有的服务先停止,任务管理器里面的也停止.然后再安装unlocker207补丁就行了.亲测.
- 服务器BMC(带外)
服务器除了装linux,windows系统外,相应还有一个可通过网线(服务器默认带外地址--可改)连接具体厂商服务器的BMC(Baseboard Management Controller,基板管理控 ...
- 【Biocode】产生三行的seq+01序列
代码说明: sequence.txt与site.txt整合 如下图: sequence.txt: site.txt: 整理之后如下: 蛋白质序列中发生翻译后修饰的位置标记为“1”,其他的位置标记为“0 ...
- 【week8】psp~~进度条
本周psp 项目 内容 开始时间 结束时间 中断时间 净时间 10月7日 星期一 论文 看生物信息方面的论文 10:00 12:00 5 115 写代码 注册信息从前台传入servlet 18:00 ...
- ant build.xml 解释!
Ant的概念 Make命令是一个项目管理工具,而Ant所实现功能与此类似.像make,gnumake和nmake这些编译工具都有一定的缺陷,但是Ant却克服了这些工具的缺陷.最初Ant开发者在开发跨 ...
- IDEA中Git的更新/提交/还原方法
记录一下在IDEA上怎样将写的代码提交到GitHub远程库: 下面这个图是基本的提交代码的顺序: 1. 将代码Add到stage暂存区本地修改了代码后,需先将代码add到暂存区,最后才能真正提价到gi ...
- 理解promise 01
原文地址: http://pouchdb.com/2015/05/18/we-have-a-problem-with-promises.html 用Javascript的小伙伴们,是时候承认了,关于 ...