Google图片和NASA 网站图片的爬虫
1.根据关键字爬取NASA网站上的图片
首先针对需要爬取的网站进行分析,输入关键字查找需要的内容

通过关键字请求,网页每次会加载20张的缩略图,分析网页源码能够很容易的找到缩略图的url:

然后再点开缩略图,会链接的另一个网页,从这里可以分析出更高分辨率大图的url:
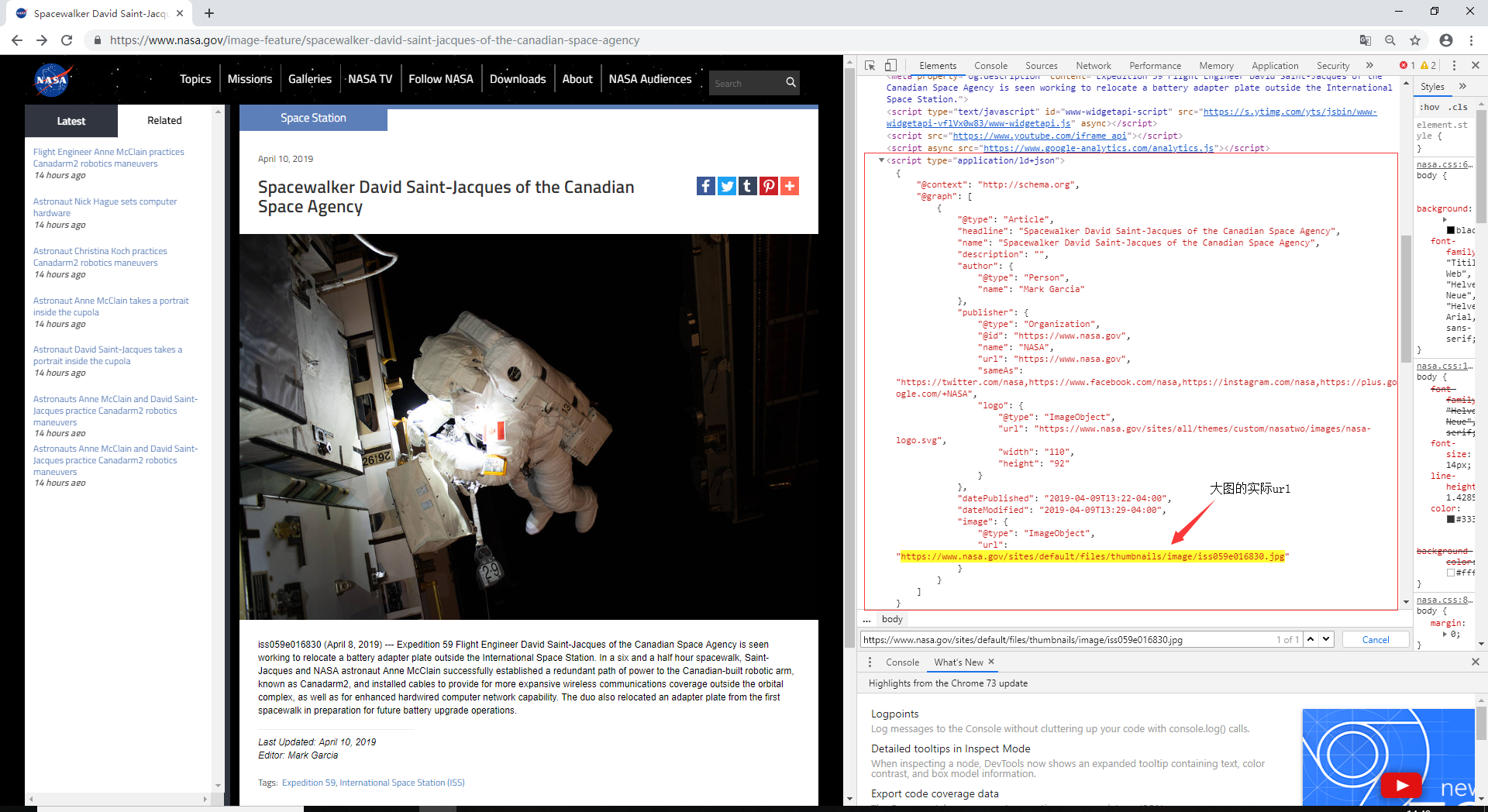
最后根据取得的url地址下载原图就可以了,下面附上源代码
# -*- coding: utf-8 -*-import urllibimport requestsfrom bs4 import BeautifulSoupimport reimport jsondef getUrl(keyword):user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:53.0) Gecko/20100101 Firefox/53.0'results = requests.get("https://nasasearch.nasa.gov/search/images",params={'affiliate': 'nasa', 'query': keyword},headers={'User-Agent': user_agent})results.encoding = 'utf-8's = requests.session()s.keep_alive = Falsesoup = BeautifulSoup(results.text, 'lxml')# 获取网页中的所有div ,class=url的文本for link in soup.find_all('div', class_='url'):# 拼接urlhtml = requests.get('https://'+link.text)soup1 = BeautifulSoup(html.text, 'lxml')# 获取字段data = soup1.find('script', attrs={"type": "application/ld+json"})# json字符串转换为字典jsonobj = json.loads(data.text)# 从json块中获取图片地址imageUrl = jsonobj['@graph'][0]['image']['url']namelist = imageUrl.split('/')# 获取图片名称name = namelist[-1].split('.')[0]downloadImage(imageUrl, name)def downloadImage(imageUrl, name):path = 'D:/space/'print(name)if imageUrl is not None:try:image_file = requests.get(imageUrl, stream=True, timeout=9)except requests.exceptions.RequestException:print('网络异常')# else:# if image_file.status_code is not requests.codes.ok:#print('{}'.format(imageUrl) + '链接为空!')else:image_file_path = '{}{}.jpg'.format(path, name)print('正在下载:' + '{}.jpg'.format(name))with open(image_file_path, 'wb') as f:f.write(image_file.content)print('下载完成!')if __name__ == "__main__":keyword = input()getUrl(keyword)
2.爬取谷歌图片
这里主要使用了一个开源代码,爬虫作者github地址:https://github.com/YoongiKim/AutoCrawler
爬虫的效果还是很不错的,具体的使用作者在主页也详细的说明了
Google图片和NASA 网站图片的爬虫的更多相关文章
- C#获取网页的HTML码、下载网站图片、获取IP地址
1.根据URL请求获取页面HTML代码 /// <summary> /// 获取网页的HTML码 /// </summary> /// <param name=" ...
- C#获取网页的HTML码、下载网站图片
1.根据URL请求获取页面HTML代码 /// <summary> /// 获取网页的HTML码 /// </summary> /// <param name=" ...
- Python爬虫下载美女图片(不同网站不同方法)
声明:以下代码,Python版本3.6完美运行 一.思路介绍 不同的图片网站设有不同的反爬虫机制,根据具体网站采取对应的方法 1. 浏览器浏览分析地址变化规律 2. Python测试类获取网页内容,从 ...
- webmagic 二次开发爬虫 爬取网站图片
webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫. webmagic介绍 编写一个简单的爬虫 webmagic的使用文档:http://w ...
- Python爬虫实战:批量下载网站图片
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: GitPython PS:如有需要Python学习资料的小伙伴可以 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 如何:使用PicturBox实现类似淘宝网站图片的局部放大功能
转载至http://xuzhihong1987.blog.163.com/blog/static/267315872011822113131823/ 概要: 本文将讲述如何使用PictureBox控件 ...
- Web 性能优化: 图片优化让网站大小减少 62%
摘要: 压缩各种格式的图片. 原文:Web 性能优化: 图片优化让网站大小减少 62% 作者:前端小智 Fundebug经授权转载,版权归原作者所有. 这是 Web 性能优化的第二篇,上一篇在下面看点 ...
- 批量下载网站图片的Python实用小工具
定位 本文适合于熟悉Python编程且对互联网高清图片饶有兴趣的筒鞋.读完本文后,将学会如何使用Python库批量并发地抓取网页和下载图片资源.只要懂得如何安装Python库以及运行Python程序, ...
随机推荐
- 2017ACM暑期多校联合训练 - Team 2 1011 HDU 6055 Regular polygon (数学规律)
题目链接 **Problem Description On a two-dimensional plane, give you n integer points. Your task is to fi ...
- IP判断 (字符串处理)
关于IP合法性判断的题目,每个oj上的约束条件不尽相同,我就根据自己做过的题目吧所有的约束条件汇总到一块,到时候做题时只需要把多余的越是条件删掉即可 题目描述: 对于IP我们总会有一定的规定,合法的I ...
- C# 操作资源文件
(1)首先引用这两个命名空间 (2)两种方式调用资源文件中的内容 private void button2_Click(object sender, EventArgs e) { //通过Resour ...
- F - Warm up HDU - 4612 tarjan缩点 + 树的直径 + 对tajan的再次理解
题目链接:https://vjudge.net/contest/67418#problem/F 题目大意:给你一个图,让你加一条边,使得原图中的桥尽可能的小.(谢谢梁学长的帮忙) 我对重边,tarja ...
- [Gym-100625J] 搜索
题目链接:https://cn.vjudge.net/problem/Gym-100625J 具体思路:首先,具体思路是两个人一起走到一个点,然后两个人按照同样的道路走出去,听了别人的思路,还有一种特 ...
- Tornado/Python 学习笔记(二)
部分ssrpc.py代码分析 -- 服务端: 1 #!/usr/bin/python3 2 3 from xmlrpc.client import Fault, dumps, loads 4 impo ...
- struts集合类型封装
1.list类型封装
- Mysql储存过程6: in / out / inout
in 为向函数传送进去的值 out 为函数向外返回的值 intout 传送进去的值, 并且还返回这个值 )) begin then select 'true'; else select 'false' ...
- HBase原理解析(转)
本文属于转载,原文链接:http://www.aboutyun.com/thread-7199-1-1.html 前提是大家至少了解HBase的基本需求和组件. 从大家最熟悉的客户端发起请求开始讲 ...
- “全排列”问题系列(一)[LeetCode] - 用交换元素法生成全排列及其应用,例题: Permutations I 和 II, N-Queens I 和 II,数独问题
转:http://www.cnblogs.com/felixfang/p/3705754.html 一.开篇 Permutation,排列问题.这篇博文以几道LeetCode的题目和引用剑指offer ...