Code Llama:Llama 2 学会写代码了!
引言
Code Llama 是为代码类任务而生的一组最先进的、开放的 Llama 2 模型,我们很高兴能将其集成入 Hugging Face 生态系统!Code Llama 使用与 Llama 2 相同的社区许可证,且可商用。
今天,我们很高兴能发布 Hugging Face 对 Code Llama 的全面支持 , 包括:
- Hub 上的模型支持,包括模型卡及许可证
- Transformers 已集成 Code Llama
- TGI 已集成 Code Llama,以支持对其进行快速高效的产品级推理
- 推理终端 (Inference Endpoints) 已集成 Code Llama
- 对 Code Llama 的代码基准测试结果已发布
代码大语言模型的发展对于软件工程师来说无疑是振奋人心的,因为这意味着他们可以通过 IDE 中的代码补全功能来提高生产力,并利用其来处理重复或烦人的任务,例如为代码编写文档字符串或创建单元测试。
目录
Code Llama 简介
Code Llama 包含 3 个不同参数量的版本,分别为: 7 亿参数版、13 亿参数版 以及 340 亿参数版。在训练基础模型时,先用同等参数量的 Llama 2 模型初始化权重,然后在 5000 亿词元的代码数据集上训练。 Meta 还对训得的基础模型进行了两种不同风格的微调,分别为: Python 专家版 (再加 1000 亿个额外词元) ; 以及指令微调版,其可以理解自然语言指令。
这些模型在 Python、C++、Java、PHP、C#、TypeScript 和 Bash 中都展现出最先进的性能。7B 和 13B 基础版和指令版支持完形填空,因此非常适合用作代码助手。
Code Llama 基于 16k 上下文窗口训练。此外,这三个尺寸的模型还进行了额外的长上下文微调,使其上下文窗口最多可扩展至 10 万词元。
受益于 RoPE 扩展方面的最新进展,将 Llama 2 的 4k 上下文窗口增加到 Code Llama 的 16k (甚至可以外插至 100k) 成为可能。社区发现可以对 Llama 的位置嵌入进行线性插值或频域插值,这使得通过微调让基础模型轻松扩展到更大的上下文窗口成为可能。在 Code Llama 中,他们把频域缩放和松弛技术二者结合起来: 微调长度是缩放后的预训练长度的一小部分。这个做法赋予了模型强大的外推能力。
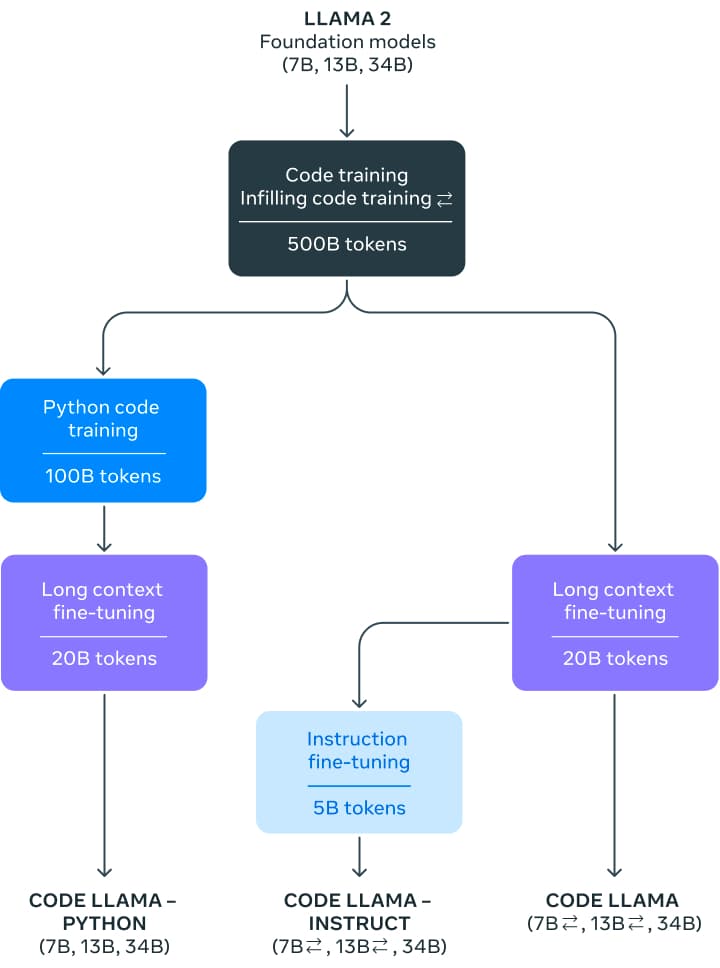
第一步是在 5000 亿词元的公开代码数据集上训练出一个模型。该数据集中除了有代码数据集外,还包含一些自然语言数据集,例如有关代码和代码片段的讨论,且最终数据集是使用近似去重法去过重的。不幸的是,Meta 没有披露有关该数据集的更多信息。
在对模型进行指令微调时,使用了两个数据集: 为 Llama 2 Chat 收集的指令微调数据集和自指令数据集。自指令数据集收集了 Llama 2 编制出的编程面试问题,然后使用 Code Llama 生成单元测试和解答,最后通过执行测试来评估解答。
如何使用 Code Llama?
Transformers 从 4.33 版开始支持 Code Llama。在此之前,需要从主分支进行源代码安装才行。
演示
我们准备了 这个 Space 或下面的 Playground 以供大家尝试 Code Llama 模型 (130 亿参数!):
这个演示背后使用了 Hugging Face TGI,HuggingChat 也用了相同的技术,具体内容见下文。
你还可以玩玩 这个聊天机器人,或者复制一份到自己的账号下以供你使用 – 它是自含的,因此你可以随心所欲地修改代码!
Transformers
从最新发布的 transformers 4.33 开始,你可以在 Code Llama 上应用 HF 生态系统中的所有工具,例如:
- 训练和推理脚本和示例
- 安全的文件格式 (
safetensors) - 与
bitsandbytes(4 比特量化) 和 PEFT 等工具结合使用 - 运行模型生成所需的工具及辅助代码
- 导出模型以进行部署的机制
在 transformers 4.33 发布之前,用户需要从主分支源码安装 transformers 。
!pip install git+https://github.com/huggingface/transformers.git@main accelerate
代码补全
我们可以使用 7B 和 13B 模型进行文本/代码补全或填充。下述代码演示了如何使用 pipeline 接口来进行文本补全。运行时,只需选择 GPU 即可在 Colab 的免费 GPU 上运行。
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
其输出如下:
Result: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return
Code Llama 虽然专精于代码理解,但其仍是一个语言模型。你仍然可以使用相同的生成策略来自动完成注释或自然语言文本。
代码填充
这是代码模型才能完成的专门任务。该模型经过训练后,可以生成与给定上下文最匹配的代码 (包括注释)。这是代码助理的典型使用场景: 要求它们根据上下文填充当前光标处的代码。
此任务需要使用 7B 和 13B 的 基础 或 指令 模型。任何 34B 或 Python 版模型不能用于此任务。
填充类任务需要在生成时使用与训练时相同格式的输入文本,因为训练时会使用特殊的分隔符来区分提示的不同部分。幸运的是, transformers 的 CodeLlamaTokenizer 已经帮你把这事做了,如下所示:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prompt = '''def remove_non_ascii(s: str) -> str:
""" <FILL_ME>
return result
'''
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
output = model.generate(
input_ids,
max_new_tokens=200,
)
output = output[0].to("cpu")
filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True)
print(prompt.replace("<FILL_ME>", filling))
输出如下:
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s: The string to remove non-ASCII characters from.
Returns:
The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
在底层,分词器会 自动按 <fill_me> 分割 并生成一个格式化的输入字符串,其格式与 训练时的格式 相同。这样做既避免了用户自己格式化的很多麻烦,也避免了一些很难调试的陷阱,例如词元粘合 (token glueing)。
对话式指令
如上所述,基础模型可用于补全和填充。Code Llama 还包含一个适用于对话场景的指令微调模型。
为此类任务准备输入时,我们需要一个提示模板。一个例子是我们在 Llama 2 博文 中描述的模板,如下:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST]{{ model_answer_1 }} </s><s>[INST]{{ user_msg_2 }} [/INST]
请注意,系统提示 ( system prompt ) 是可选的 - 没有它模型也能工作,但你可以用它来进一步指定模型的行为或风格。例如,如果你希望获得 JavaScript 的答案,即可在此声明。在系统提示之后,你需要提供对话交互历史: 用户问了什么以及模型回答了什么。与填充场景一样,你需要注意分隔符的使用。输入的最后必须是新的用户指令,这对模型而言是让其提供答案的信号。
以下代码片段演示了如何在实际工作中使用该模板。
- 首次用户输入,无系统提示
user = 'In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?'
prompt = f"<s>[INST]{user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
- 首次用户查询,有系统提示
system = "Provide answers in JavaScript"
user = "Write a function that computes the set of sums of all contiguous sublists of a given list."
prompt = f"<s><<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
- 含对话历史的多轮对话
该过程与 Llama 2 中的过程相同。为了最清楚起见,我们没有使用循环或泛化此示例代码:
system = "System prompt"
user_1 = "user_prompt_1"
answer_1 = "answer_1"
user_2 = "user_prompt_2"
answer_2 = "answer_2"
user_3 = "user_prompt_3"
prompt = f"<<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user_1}"
prompt = f"<s>[INST]{prompt.strip()} [/INST]{answer_1.strip()} </s>"
prompt += f"<s>[INST]{user_2.strip()} [/INST]{answer_2.strip()} </s>"
prompt += f"<s>[INST]{user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
4 比特加载
将 Code Llama 集成到 Transformers 中意味着我们可以立即获得 4 比特加载等高级功能的支持。这使得用户可以在英伟达 3090 卡等消费类 GPU 上运行大型的 32B 参数量模型!
以下是在 4 比特模式下运行推理的方法:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
使用 TGI 和推理终端
TGI 是 Hugging Face 开发的生产级推理容器,可用于轻松部署大语言模型。它包含连续批处理、流式输出、基于张量并行的多 GPU 快速推理以及生产级的日志记录和跟踪等功能。
你可以在自己的基础设施上使用 TGI,也可以使用 Hugging Face 的 推理终端。要部署 Codellama 2 模型,请登陆其 模型页面,然后单击 Deploy -> Inference Endpoints 按钮。
- 推理 7B 模型,我们建议选择“GPU [medium] - 1x Nvidia A10G”。
- 推理 13B 模型,我们建议选择“GPU [xlarge] - 1x Nvidia A100”。
- 推理 34B 模型,我们建议启用
bitsandbytes量化并选择“GPU [1xlarge] - 1x Nvidia A100”或“GPU [2xlarge] - 2x Nvidia A100”
注意: 你可能需要发邮件给 api-enterprise@huggingface.co 申请配额升级才能访问 A100
你可以在我们的博文中详细了解如何 使用 Hugging Face 推理终端部署 LLM,该 博文 还包含了有关其支持的超参以及如何使用 Python 和 Javascript API 流式生成文本的相关知识。
评估
代码语言模型通常在 HumanEval 等数据集上进行基准测试,其包含了一系列编程题,我们将函数签名和文档字符串输入给模型,模型需要完成函数体代码的编写。接着是运行一组预定义的单元测试来验证所提出的解答。最后是报告通过率,即有多少解答通过了所有测试。pass@1 度量了模型一次生成即通过的频率,而 pass@10 描述了模型生成 10 个候选解答其中至少有一个解答通过的频率。
虽然 HumanEval 是一个 Python 基准测试,但社区付出了巨大努力将其转成更多编程语言,从而实现更全面的评估。其中一种方法是 MultiPL-E,它将 HumanEval 翻译成十多种编程语言。我们正在基于其制作一个 多语言代码排行榜,这样社区就可以用它来比较不同模型在各种编程语言上的表现,以评估哪个模型最适合他们的需求。
| 模型 | 许可证 | 训练数据集是否已知 | 是否可商用 | 预训练词元数 | Python | JavaScript | Leaderboard Avg Score |
|---|---|---|---|---|---|---|---|
| CodeLlaMa-34B | Llama 2 license | 2,500B | 45.11 | 41.66 | 33.89 | ||
| CodeLlaMa-13B | Llama 2 license | 2,500B | 35.07 | 38.26 | 28.35 | ||
| CodeLlaMa-7B | Llama 2 license | 2,500B | 29.98 | 31.8 | 24.36 | ||
| CodeLlaMa-34B-Python | Llama 2 license | 2,620B | 53.29 | 44.72 | 33.87 | ||
| CodeLlaMa-13B-Python | Llama 2 license | 2,620B | 42.89 | 40.66 | 28.67 | ||
| CodeLlaMa-7B-Python | Llama 2 license | 2,620B | 40.48 | 36.34 | 23.5 | ||
| CodeLlaMa-34B-Instruct | Llama 2 license | 2,620B | 50.79 | 45.85 | 35.09 | ||
| CodeLlaMa-13B-Instruct | Llama 2 license | 2,620B | 50.6 | 40.91 | 31.29 | ||
| CodeLlaMa-7B-Instruct | Llama 2 license | 2,620B | 45.65 | 33.11 | 26.45 | ||
| StarCoder-15B | BigCode-OpenRail-M | 1,035B | 33.57 | 30.79 | 22.74 | ||
| StarCoderBase-15B | BigCode-OpenRail-M | 1,000B | 30.35 | 31.7 | 22.4 | ||
| WizardCoder-15B | BigCode-OpenRail-M | 1,035B | 58.12 | 41.91 | 32.07 | ||
| OctoCoder-15B | BigCode-OpenRail-M | 1,000B | 45.3 | 32.8 | 24.01 | ||
| CodeGeeX-2-6B | CodeGeeX License | 2,000B | 33.49 | 29.9 | 21.23 | ||
| CodeGen-2.5-7B-Mono | Apache-2.0 | 1400B | 45.65 | 23.22 | 12.1 | ||
| CodeGen-2.5-7B-Multi | Apache-2.0 | 1400B | 28.7 | 26.27 | 20.04 |
注意: 上表中的分数来自我们的代码排行榜,所有模型均使用相同的设置。欲了解更多详情,请参阅 排行榜。
其他资源
宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
英文原文: https://hf.co/blog/codellama
原文作者: Philipp Schmid,Omar Sanseviero,Pedro Cuenca,Lewis Tunstall,Leandro von Werra,Loubna Ben Allal,Arthur Zucker,Joao Gante
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
Code Llama:Llama 2 学会写代码了!的更多相关文章
- 【腾讯Bugly干货分享】深入理解 ButterKnife,让你的程序学会写代码
本文来自于腾讯bugly开发者社区,非经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/578753c0c9da73584b025875 0.引子 话说我们做程序员的,都 ...
- 将目录下面所有的 .cs 文件合并到一个 code.cs 文件中,写著作权复制代码时的必备良药
将目录下面所有的 .cs 文件合并到一个 code.cs 文件中,写著作权复制代码时的必备良药 @echo off echo 将该目录下所有.cs文件的内容合并到一个 code.cs 文件中! pau ...
- 使用Code::blocks在windows下写网络程序
使用Code::blocks在windows下写网络程序 作者 He YiJun – storysnail<at>gmail.com 团队 ls 版权 转载请保留本声明! 本文档包含的原创 ...
- web前端入门:一小时学会写页面
一小时学会写页面 作为一个懒癌晚期患者,总是习惯找各种简单的解决问题的方法,也习惯性把问题简单化,所以今天想分享给大家简单的web前端入门方法.既然题目已经定了一个小时那么废话就不多说了,计时开始 1 ...
- jQuery 之父:每天写代码
去年秋天我的支线代码项目 遇到了一些问题,项目进展不足,而且我没法找到一个完成更多代码的方法(在不影响我在Khan Academy方面的工作的前提下). 我主要在周末进行我的支线,当然有时候也在晚上进 ...
- Delphi/C#之父首次访华:55岁了 每天都写代码
Delphi.C#之父Anders Hejlsberg 近日首次访华,并在10月24日和27日参加了两场见面会,分享了他目前领导开发的TypeScript项目,并与国内前端开发者近距离交流.本文就为读 ...
- I2C(四)linux3.4(写代码)
title: I2C(四)linux3.4(写代码) date: 2019/1/29 17:18:42 toc: true --- I2C(四)linux3.4(写代码) 老师的参考代码 https: ...
- [No000018B]写代码要用 Vim,因为越难入门的工具回报越大
编者按:现在的技术界有一种倾向,将软件/应用操作简单化,用户能轻松上手.但是工具是否强大,取决于它能否灵活地满足使用者的各种需要.有些工具虽然很难入门,学会了便能对自己的操作有更深的层次的了解,能赋予 ...
- VS Code的golang开发配置 之 代码提示
之前用VS Code的时候,发现自己的代码的提示一直不好,换用JetBrain的Goland的代码提示是好了,但是比较占用资源.在网上找了一些资料,发现很多人也是遇到第三方或者自己的代码无法提示的情况 ...
- [翻译] Canvas 不用写代码的动画
Canvas 不用写代码的动画 https://github.com/CanvasPod/Canvas Canvas is a project to simplify iOS development ...
随机推荐
- web自动化09-frame切换、多窗口切换
frame切换 1.html代码: <frameset cols="25%,50%,25%"> <frame src="a.htm"> ...
- CANoe学习笔记(三):CANoe的诊断功能和cdd文件
内容: UDS诊断学习 CDD文件配置 诊断功能 一.UDS诊断学习: ①.UDS请求命令4种构成方式: SIDSID+SF(Sub-function)SID+DID(Data Identifier) ...
- 适合Windows桌面、Material Design设计风格、WPF美观控件库【强烈推荐】
推荐一个在Github已start超过13.6K,非常流行.美观的WPF控件库. 项目简介 这是一个适用于Windows桌面,全面且易于使用的控件库,遵循Google推测的Material Desig ...
- Transformer编码器和解码器被广泛应用于自然语言处理、计算机视觉、语音识别等领域。下面是一些Trans
目录 1. 引言 2. 技术原理及概念 2.1 基本概念解释 2.1.1 编码器 2.1.2 解码器 2.2 技术原理介绍 2.2.1 编码器 2.2.2 解码器 2.3 相关技术比较 3. 实现步骤 ...
- Dlang 与 C 语言交互(二)
Dlang 与 C 语言交互(二) 随着需求不断增加,发现好像需要更多的东西了.在官网上找不到资料,四处拼凑才有了本文的分享. 上一文(DLang 与 C 语言交互(一) - jeefy - 博客园) ...
- https 原理分析进阶-模拟https通信过程
大家好,我是蓝胖子,之前出过一篇https的原理分析 ,完整的介绍了https概念以及通信过程,今天我们就来比较完整的模拟实现https通信的过程,通过这篇文章,你能了解到https核心的概念以及原理 ...
- 国标GB28181协议客户端开发(四)实时视频数据传输
国标GB28181协议客户端开发(四)实时视频数据传输 本文是<国标GB28181协议设备端开发>系列的第四篇,介绍了实时视频数据传输的过程.通过解读INVITE报文中的SDP信息,读取和 ...
- 如何不加锁地将数据并发写入Apache Hudi?
最近一位 Hudi 用户询问他们是否可以在不需要任何锁的情况下同时从多个写入端写入单个 Hudi 表. 他们场景是一个不可变的工作负载. 一般来说对于任何多写入端功能,Hudi 建议启用锁定配置. 但 ...
- 【调制解调】SSB 单边带调幅
说明 学习数字信号处理算法时整理的学习笔记.同系列文章目录可见 <DSP 学习之路>目录,代码已上传到 Github - ModulationAndDemodulation.本篇介绍 SS ...
- freeswitch的mod_cdr_csv模块
概述 freeswitch是一款简单好用的VOIP开源软交换平台. 在语音呼叫的过程中,话单是重要的计价和结算依据,话单的产生需要稳定可靠,可回溯. fs中基本的话单模块mod_cdr_csv,可以满 ...