强化学习基础篇[3]:DQN、Actor-Critic详细讲解
强化学习基础篇[3]:DQN、Actor-Critic详细讲解
1.DQN详解
1.1 DQN网络概述及其创新点
在之前的内容中,我们讲解了Q-learning和Sarsa算法。在这两个算法中,需要用一个Q表格来记录不同状态动作对应的价值,即一个大小为 $[状态个数,动作个数]$ 的二维数组。在一些简单的强化学习环境中,比如迷宫游戏中(图1a),迷宫大小为4*4,因此该游戏存在16个state;而悬崖问题(图1b)的地图大小为 4*12,因此在该问题中状态数量为48,这些都属于数量较少的状态,所以可以用Q表格来记录对应的状态动作价值。但当我们需要应用强化学习来解决实际问题时,比如解决国际象棋问题或围棋问题,那么环境中就会包含 $10^{47}$ 个state或 $10^{170}$ 个state,如此庞大的状态数量已经很难用Q表格来进行存储,更不要说在3D仿真环境中,机器人手脚弯曲的状态是完全不可数的。由此可以看到Q表格在大状态问题和不可数状态问题时的局限性。同时,在一个强化学习环境中,不是所有的状态都会被经常访问,其中有些状态的访问次数很少或几乎为零,这就会导致价值估计并不可靠。

图1: 不同强化学习环境对应的状态量
为解决上述两个问题,一种解决方案即为Q表格参数化,使用深度神经网络拟合动作价值函数 $q_\pi$。参数化可以解决无限状态下的动作价值函数的存储问题,因为算法只需记住一组参数,动作价值函数的具体值可根据这一组参数算出。同时,参数化也有助于缓解因某些状态访问次数少而导致的估值不准问题。因为对于一个处在连续空间内的状态价值函数,如果要对访问次数较多的状态小临域内的状态进行价值估计,其估计结果也是有一定保障的。
但是动作价值函数的参数化也会带来一些新的问题,首先,因为相邻样本来自同一条轨迹,会导致样本间关联性过强,而集中优化关联性过强的样本会导致神经网络处理其他样本时无法取得较好的结果。举一个例子来说明这个问题,比如:假设一个agent的action有上下左右四种选择,神经网络采用一条轨迹为 $s_1 \rightarrow right \rightarrow s_2 \rightarrow right \rightarrow s_3 \rightarrow up$ 的训练样本进行训练,而当该网络处理轨迹 $s_1 \rightarrow left \rightarrow s_2 \rightarrow left \rightarrow s_3 \rightarrow down \rightarrow s_4 \rightarrow ?$ 的样本进行预测时,就不会取得很好的效果。另一个问题是,当参数 $\theta$ 被同时用来计算动作价值函数的目标值和预测的Q值时,对 $\theta$ 的更新会同时影响这两个值,使得损失函数中的优化目标变得不明确,算法收敛不稳定。
为了解决如上两个问题,Mnih 等人提出了深度Q网络 (Deep Q-Network,DQN),其本质上是Q-learning算法,但使用深度学习网络拟合Q函数,解决了无限状态下的动作价值函数存储问题,同时采用经验重现(Experience Replay)和固定Q目标(Fixed-Q-Target)两个创新点来解决上述两个问题。
- 经验重现(Experience Replay):使用一个经验池存储多条经验 $s, a, r, s^{'}$, 再从中随机抽取一批用于训练,很好的解决了样本关联性的问题,同时,因为经验池里的经验可以得到重复利用,也提升了利用效率。
- 固定Q目标(Fixed-Q-Target):复制一个和原来Q网络结构一样的Target Q网络,用于计算Q目标值,这样在原来的Q网络中,target Q就是一个固定的数值,不会再产生优化目标不明确的问题。
1.2. 算法流程
在DQN算法中,智能体会在与所处环境 $environment$ 进行交互后,获得一个环境提供的状态 $s_{t}$。 接收状态后,智能体会根据深度学习网络预测出在该状态下不同行动 $action$ 对应的Q值,并给出一个行动 $a_{t}$,当行动反馈给环境后,环境会给出对应的奖励 $r_{t}$、新的状态 $s_{t+1}$,以及是否触发终止条件 $done$。每一次交互完成,DQN算法都会将 $s_{t}, a_{t}, r_{t}, s_{t+1}, done$ 作为一条经验储存在经验池中,每次会从经验池中抽取一定量的经验作为输入数据训练神经网络。
DQN算法流程:
- 初始化经验池,随机初始化Q网络;
- for episode = 1, M do:
- 重置环境,获得第一个状态;
- for t = 1, T do:
- 用 $\epsilon-greedy$ 策略生成一个action:其中有 $\epsilon$ 的概率会随机选择一个action,即为探索模式;其他情况下,则$a_{t} = max_{a}Q(s_{t}, a;\theta)$,选择在 $s_t$ 状态下使得Q最大的action,即为经验模式;
- 根据动作与环境的交互,获得反馈的reward $r_{t}$、下一个状态 $s_{t+1}$ 和是否触发终止条件done;
- 将经验 $s_{t}, a_{t}, r_{t}, s_{t+1}, done$ 存入经验池;
- 从经验池中随机获取一个minibatch的经验;
- $Qtarget_{t} = \left{\begin{matrix} r_{t},\quad if{,} done \r_{t} + \gamma max_{a^{'}}Qtarget(s_{t+1}, a^{'}; \theta),\quad if{,}not{,}done \end{matrix}\right.$
- 根据 $Qpred_{t}$ 和 $Qtarget_{t}$ 求loss,梯度下降法更新Q网络
- end for
- 每隔固定个episode,更新Qtarget网络
- end for
2.Actor-Critic
在 REINFORCE 算法中,每次需要根据一个策略采集一条完整的轨迹,并计算这条轨迹上的回报。这种采样方式的方差比较大,学习效率也比较低。我们可以借鉴时序差分学习的思想,使用动态规划方法来提高采样的效率,即从状态 $s$ 开始的总回报可以通过当前动作的即时奖励 $r(s,a,s')$ 和下一个状态 $s'$ 的值函数来近似估计。
演员-评论家算法(Actor-Critic Algorithm)是一种结合策略梯度和时序差分学习的强化学习方法,包括两部分,演员(Actor)和评价者(Critic),跟生成对抗网络(GAN)的流程类似:
- 演员(Actor)是指策略函数 $\pi_{\theta}(a|s)$,即学习一个策略来得到尽量高的回报。用于生成动作(Action)并和环境交互。
- 评论家(Critic)是指值函数 $V^{\pi}(s)$,对当前策略的值函数进行估计,即评估演员的好坏。用于评估Actor的表现,并指导Actor下一阶段的动作。
借助于值函数,演员-评论家算法可以进行单步更新参数,不需要等到回合结束才进行更新。
在Actor-Critic算法 里面,最知名的方法就是 A3C(Asynchronous Advantage Actor-Critic)。
- 如果去掉 Asynchronous,只有 Advantage Actor-Critic,就叫做
A2C。 - 如果加了 Asynchronous,变成Asynchronous Advantage Actor-Critic,就变成
A3C。
2.1 Actor-Critic
2.1.1 Q-learning
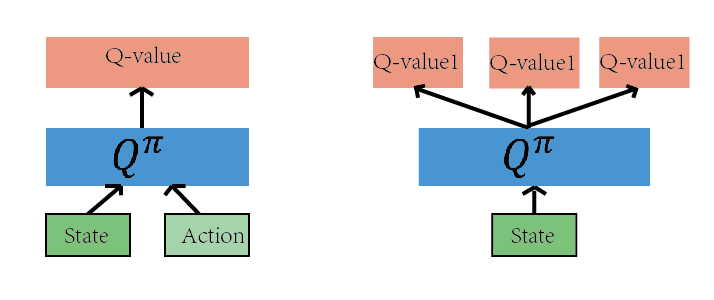
如上图的网络都是为了近似 Q(s,a)函数,有了 Q(s,a),我们就可以根据Q(s,a)的值来作为判断依据,作出恰当的行为。
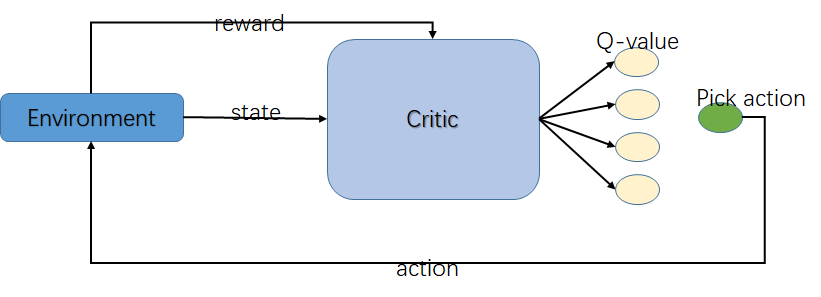
Q-learning算法最主要的一点是:决策的依据是Q(s,a)的值。即算法的本质是在计算 当前状态s, 采取某个动作 a 后会获得的未来的奖励的期望,这个值就是 Q(s,a)。换句话说,我们可以把这个算法的核心看成一个评论家(Critic),而这个评论家会对我们在当前状态s下,采取的动作a这个决策作出一个评价,评价的结果就是Q(s,a)的值。
Q-learning 算法却不怎么适合解决连续动作空间的问题。因为如果动作空间是连续的,那么用Q-learning算法就需要对动作空间离散化,而离散化的结果会导致动作空间的维度非常高,这就使得Q-learning 算法在实际应用起来很难求得最优值,且计算速度比较慢。
2.1.2 Policy Gradient
Policy Gradient 算法的核心思想是: 根据当前状态,直接算出下一个动作是什么或下一个动作的概率分布是什么。即它的输入是当前状态 s, 而输出是具体的某一个动作或者是动作的分布。
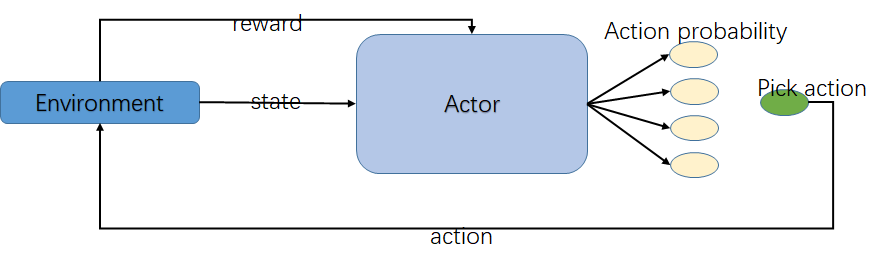
我们可以想像,Policy Gradient 就像一个演员(Actor),它根据某一个状态s,然后作出某一个动作或者给出动作的分布,而不像Q-learning 算法那样输出动作的Q函数值。
2.1.3 Actor Critic
Actor-Critic 是Q-learning 和 Policy Gradient 的结合。
为了导出 Actor-Critic 算法,必须先了解Policy Gradient 算法是如何一步步优化策略的。
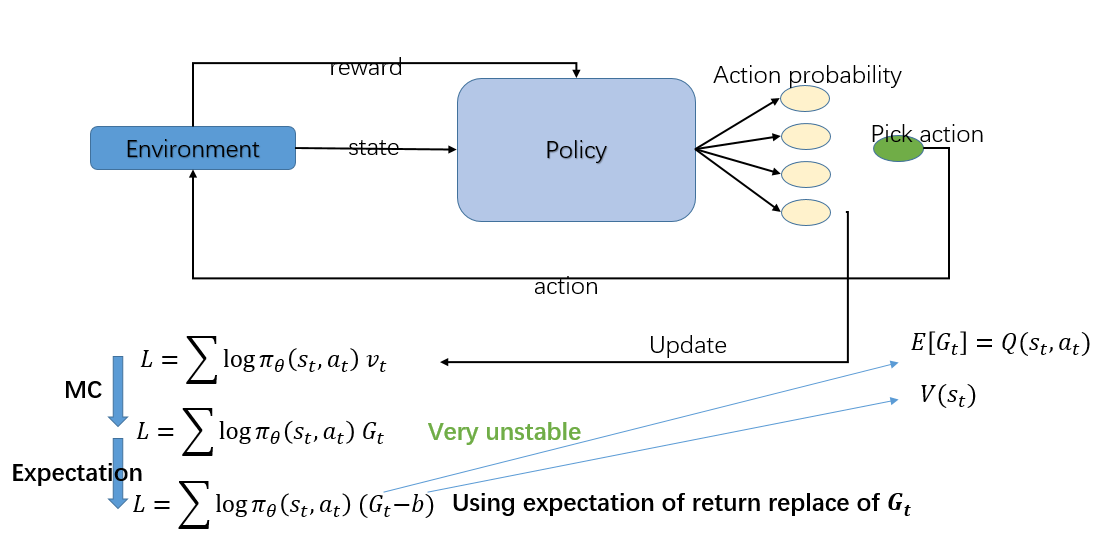
如上图所示, 最简单的Policy Gradient 算法要优化的函数如下:
$$L=\sum log \pi_{\theta}(s_{t},a_{t})v_{t}$$
其中$v_{t}$要根据 Monte-Carlo 算法估计,故又可以写成:
$$L=\sum log \pi_{\theta}(s_{t},a_{t})G_{t}$$
但是这个$G_{t}$方差会比较大,因为$G_{t}$是由多个随机变量得到的,因此,我们需要寻找减少方差的办法。
一个方法就是引入一个 baseline 的函数 b, 这个 b 会使得$(G_{t}-b)$的期望不变,但是方差会变小,常用的 baseline函数就是$V(s_{t})$。再来,为了进一步降低$G_{t}$的随机性,我们用$E(G_{t})$替代$G_{t}$,这样原式就变成:
$$L=\sum log\pi_{\theta}(s_{t},a_{t})(E(G_{t}-V_{s_{t}}))$$
因为$E(G_{t}|s_{t},a_{t})=Q(s_{t},a_{t})$,故进一步变成:
$$L=\sum log \pi_{\theta}(s_{t},a_{t})(Q(s_{t},a_{t}),V(s_{t}))$$
照上面的式子看来,我们需要两个网络去估计$Q(s_{t},a_{t})$和$V(s_{t})$,但是考虑到贝尔曼方程:
$$Q(s_{t},a_{t})=E(r+\gamma V(s_{t+1}))$$
弃掉期望:
$$Q(s_{t},a_{t})=r+\gamma V(s_{t+1})$$
在原始的A3C论文中试了各种方法,最后做出来就是直接把期望值拿掉最好,这是根据实验得出来的。
最终的式子为:
$$L=\sum log\pi_{\theta}(s_{t},a_{t})(r+\gamma V(s_{t+1})-V(s_{t}))$$
这样只需要一个网络就可以估算出V值了,而估算V的网络正是我们在 Q-learning 中做的,所以我们就把这个网络叫做 Critic。这样就在 Policy Gradient 算法的基础上引进了 Q-learning 算法了
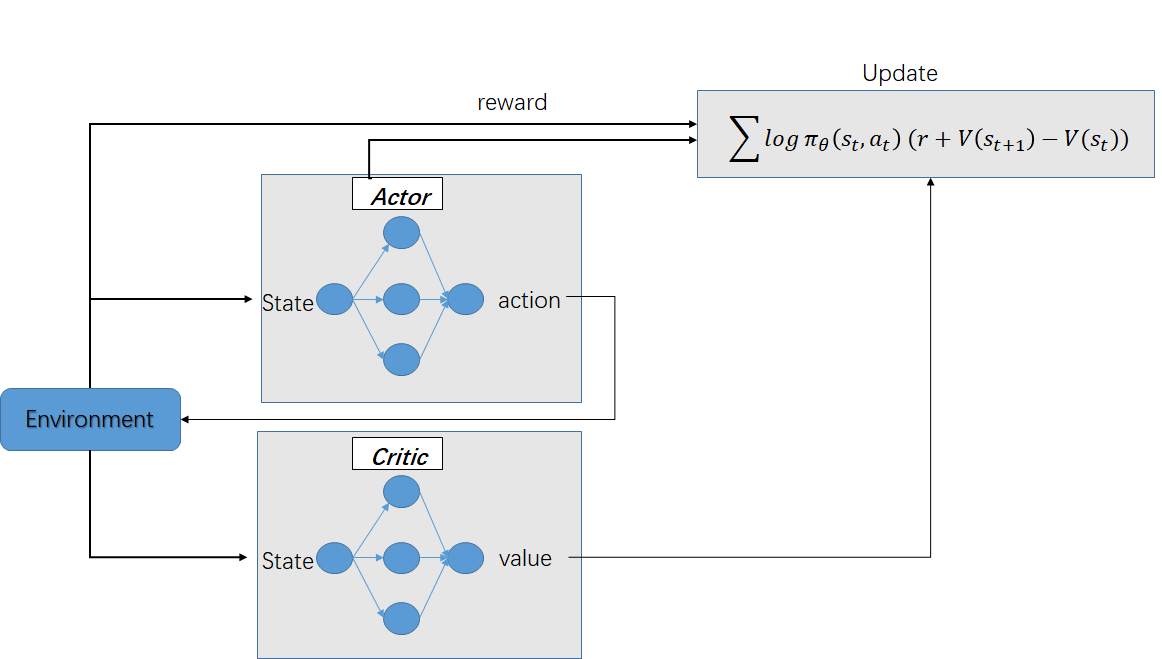
2.2 Actor-Critic算法流程
评估点基于TD误差,Critic使用神经网络来计算TD误差并更新网络参数,Actor也使用神经网络来更新网络参数
输入:迭代轮数T,状态特征维度n,动作集A,步长$\alpha$,$\beta$,衰减因子$\gamma$,探索率$\epsilon$, Critic网络结构和Actor网络结构。
输出:Actor网络参数$\theta$,Critic网络参数$w$
- 随机初始化所有的状态和动作对应的价值Q;
- for i from 1 to T,进行迭代:
- 初始化S为当前状态序列的第一个状态,拿到其特征向量$\phi (S)$
- 在Actor网络中使用$\phi (S)$作为输入,输出动作A,基于动作A得到新的状态S',反馈R;
- 在Critic网络中分别使用$\phi (S)$,$\phi (S')$作为输入,得到Q值输出V(S),V(S');
- 计算TD误差$\delta=R+\gamma V(S')-V(S)$
- 使用均方差损失函数$\sum (R+\gamma V(S')-V(S,w))^2$作Critic网络参数w的梯度更新;
- 更新Actor网络参数$\theta$:
$$\theta=\theta+\alpha \nabla_{\theta} log \pi_{\theta}(S_{t},A)\delta $$
对于Actor的分值函数$\nabla_{\theta} log \pi_{\theta}(S_{t},A)$,可以选择softmax或者高斯分值函数。
2.3 Actor-Critic优缺点
优点
- 相比以值函数为中心的算法,Actor - Critic 应用了策略梯度的做法,这能让它在连续动作或者高维动作空间中选取合适的动作,而Q-learning 做这件事会很困难甚至瘫痪。、
- 相比单纯策略梯度,Actor - Critic 应用了Q-learning 或其他策略评估的做法,使得Actor Critic 能进行单步更新而不是回合更新,比单纯的Policy Gradient 的效率要高。
缺点
- 基本版的Actor-Critic算法虽然思路很好,但是难收敛
目前改进的比较好的有两个经典算法:
- DDPG算法,使用了双Actor神经网络和双Critic神经网络的方法来改善收敛性。
- A3C算法,使用了多线程的方式,一个主线程负责更新Actor和Critic的参数,多个辅线程负责分别和环境交互,得到梯度更新值,汇总更新主线程的参数。而所有的辅线程会定期从主线程更新网络参数。这些辅线程起到了类似DQN中经验回放的作用,但是效果更好。
更多文章请关注公重号:汀丶人工智能

强化学习基础篇[3]:DQN、Actor-Critic详细讲解的更多相关文章
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- 【转载】 强化学习(十一) Prioritized Replay DQN
原文地址: https://www.cnblogs.com/pinard/p/9797695.html ------------------------------------------------ ...
- 分布式强化学习基础概念(Distributional RL )
分布式强化学习基础概念(Distributional RL) from: https://mtomassoli.github.io/2017/12/08/distributional_rl/ 1. Q ...
- Docker虚拟化实战学习——基础篇(转)
Docker虚拟化实战学习——基础篇 2018年05月26日 02:17:24 北纬34度停留 阅读数:773更多 个人分类: Docker Docker虚拟化实战和企业案例演练 深入剖析虚拟化技 ...
- 强化学习(十一) Prioritized Replay DQN
在强化学习(十)Double DQN (DDQN)中,我们讲到了DDQN使用两个Q网络,用当前Q网络计算最大Q值对应的动作,用目标Q网络计算这个最大动作对应的目标Q值,进而消除贪婪法带来的偏差.今天我 ...
- 强化学习(四)—— DQN系列(DQN, Nature DQN, DDQN, Dueling DQN等)
1 概述 在之前介绍的几种方法,我们对值函数一直有一个很大的限制,那就是它们需要用表格的形式表示.虽说表格形式对于求解有很大的帮助,但它也有自己的缺点.如果问题的状态和行动的空间非常大,使用表格表示难 ...
- 强化学习(3)-----DQN
看这篇https://blog.csdn.net/qq_16234613/article/details/80268564 1.DQN 原因:在普通的Q-learning中,当状态和动作空间是离散且维 ...
- [转]C++学习–基础篇(书籍推荐及分享)
C++入门 语言技巧,性能优化 底层硬货 STL Boost 设计模式 算法篇 算起来,用C++已经有七八年时间,也有点可以分享的东西: 以下推荐的书籍大多有电子版.对于技术类书籍,电子版并不会带来一 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- ios学习基础篇一
搜集的不错的oc学习资料 大概总结: http://my.oschina.net/luoguankun/blog/208526 详细教程: http://www.w3cschool.cc/ios/io ...
随机推荐
- .NET Moq mock internal类型
问题 Can not create proxy for type xxx because type xxx is not accessible. Make it public, or internal ...
- Java异步编程详解
在现代应用程序开发中,异步编程变得越来越重要,特别是在处理I/O密集型任务时.Java提供了一套强大的异步编程工具,使得开发者能够更有效地处理并发任务.本篇博文将深入探讨Java中异步编程的方方面面, ...
- 0x01 基本算法-位运算
A题:a^b https://ac.nowcoder.com/acm/contest/996/A 题目描述 求 a 的 b 次方对 p 取模的值,其中 0 <= a,b,p <= 10^9 ...
- 【每日一题】41. 德玛西亚万岁 (状态压缩DP)
补题链接:Here 经典状压DP问题 坑点,注意多组输入... const int N = 16, mod = 100000000; int f[N][1 << N]; int a[N]; ...
- ACM | 动态规划-数塔问题变种题型
前言 数塔问题,又称数字三角形.数字金字塔问题.数塔问题是多维动态规划问题中一类常见且重要的题型,其变种众多,难度遍布从低到高,掌握该类型题目的算法思维,对于攻克许多多维动态规划的问题有很大帮助. 当 ...
- java调用百度地图接口输入名称查经度纬度
如何注册ak号请参考https://blog.csdn.net/weixin_42512684/article/details/115843299 package manager.tool; impo ...
- 深度学习基础课:“判断性别”Demo需求分析和初步设计(上)
大家好~我开设了"深度学习基础班"的线上课程,带领同学从0开始学习全连接和卷积神经网络,进行数学推导,并且实现可以运行的Demo程序 线上课程资料: 本节课录像回放 扫码加QQ群, ...
- vue权限管理
https://www.bilibili.com/video/BV1nq4y1i7BU/?spm_id_from=333.788.recommend_more_video.6&vd_sourc ...
- C#设计模式16——中介者模式的写法
是什么: 中介者模式是一种行为型设计模式,它定义了一个中介者对象来封装一系列对象之间的交互.中介者模式可以使得对象间的交互更加松耦合,避免了对象之间的直接依赖,从而使系统更加灵活.易于扩展和维护. 为 ...
- C# 排序算法2:选择排序
选择排序法 ,是在要排序的一组数中,选出最小(或最大)的一个数与第一个位置的数交换:在剩下的数当中找最小的与第二个位置的数交换,即顺序放在已排好序的数列的最后,如此循环,直到全部数据元素排完为止. 原 ...