云原生时代如何用 Prometheus 实现性能压测可观测-Metrics 篇
简介:可观测性包括 Metrics、Traces、Logs3 个维度。可观测能力帮助我们在复杂的分布式系统中快速排查、定位问题,是分布式系统中必不可少的运维工具。
作者:拂衣
什么是性能压测可观测
可观测性包括 Metrics、Traces、Logs3 个维度。可观测能力帮助我们在复杂的分布式系统中快速排查、定位问题,是分布式系统中必不可少的运维工具。
在性能压测领域中,可观测能力更为重要,除了有助于定位性能问题,其中Metrics性能指标更直接决定了压测是否通过,对系统上线有决定性左右,具体如下:
- Metrics,监控指标
- 系统性能指标,包括请求成功率、系统吞吐量、响应时长
- 资源性能指标,衡量系统软硬件资源使用情况,配合系统性能指标,观察系统资源水位
- Logs,日志
- 施压引擎日志,观察施压引擎是否健康,压测脚本执行是否有报错
- 采样日志,采样记录 API 的请求和响应详情,辅助排查压测过程中的一些出错请求的参数是否正常,并通过响应详情,查看完整的错误信息
- Traces,分布式链路追踪用于性能问题诊断阶段,通过追踪请求在系统中的调用链路,定位报错 API 的报错系统和报错堆栈,快速定位性能问题点
本篇阐述如何使用 Prometheus 实现性能压测 Metrics 的可观测性。
压测监控的核心指标
系统性能指标
压测监控最重要的 3 个指标:请求成功率、服务吞吐量(TPS)、请求响应时长(RT),这 3 个指标任意一个出现拐点,都可以认为系统已达到性能瓶颈。
这里特别说明下响应时长,对于这个指标,用平均值来判断很有误导性,因为一个系统的响应时长并不是平均分布的,往往会出现长尾现象,表现为一部分用户请求的响应时间特别长,但整体平均响应时间符合预期,这样其实是影响了一部分用户的体验,不应该判断为测试通过。因此对于响应时长,常用 99、95、90 分位值来判断系统响应时长是否达标。
另外,如果需要观察请求响应时长的分布细节,可以补充请求建联时长(Connect Time)、等待响应时长(Idle Time)等指标。
资源性能指标
压测过程中,对系统硬件、中间件、数据库资源的监控也很重要,包括但不限于:
- CPU 使用率
- 内存使用率
- 磁盘吞吐量
- 网络吞吐量
- 数据库连接数
- 缓存命中率
... ...
详细可见《测试指标》[1]一文。
施压机性能指标
压测链路中,施压机性能是容易被忽略的一环,为了保证施压机不是整个压测链路的性能瓶颈,需要关注如下施压机性能指标:
- 压测进程的内存使用量
- 施压机 CPU 使用率,Load1、Load5 负载指标
- 基于 JVM 的压测引擎,需要关注垃圾回收次数、垃圾回收时长
为什么用 Prometheus 做压测监控
开源压测工具如 JMeter 本身支持简单的系统性能监控指标,如:请求成功率、系统吞吐量、响应时长等。但是对于大规模分布式压测来说,开源压测工具的原生监控有如下不足:
- 监控指标不够全面,一般只包含了基础的系统性能指标,只能用于判断压测是否通过。但是如果压测不通过,需要排查、定位问题时,如分析一个 API 的 99 分位建联时长,原生监控指标就无法实现。
- 聚合时效性不能保证
- 无法支持大规模分布式的监控数据聚合
- 监控指标不支持按时间轴回溯
综上,在大规模分布式压测中,不推荐使用开源压测工具的原生监控。
下面对比 2 种开源的监控方案:
方案一:Zabbix
Zabbix 是早期开源的分布式监控系统,支持 MySQL 或 PostgreSQL 关系型数据库作为数据源。
对于系统性能监控,需要施压机提供秒级的监控指标,每秒高并发的监控指标写入,使关系型数据库成为了监控系统的瓶颈。
对于资源性能监控,Zabbix 对物理机、虚拟机的指标很全面,但是对容器、弹性计算的监控支持还不够。
方案二:Prometheus
Prometheus 使用时序数据库作为数据源,相比传统关系型数据库,读写性能大大提高,对于施压机大量的秒级监控数据上报的场景,性能表现良好。
对于资源性能监控,Prometheus 更适用于云资源的监控,尤其对 Kubernates 和容器的监控非常全面,对使用云原生技术的用户,上手更简单。
总结下来,Prometheus 相较 Zabbix,更适合于压测中高并发监控指标的采集和聚合,并且更适用于云资源的监控,且易于扩展。
当然,使用成熟的云产品也是一个很好选择,如压测工具 PTS[2]+可观测工具 ARMS[3],就是一组黄金搭档。PTS 提供压测时的系统性能指标,ARMS 提供资源监控和整体可观测的能力,一站式解决压测可观测的问题。
怎么使用 Prometheus 实现压测监控
开源 JMeter 改造
Prometheus 是拉数据模型,因此需要压测引擎暴露 HTTP 服务,供 Prometheus 获取各压测指标。
JMeter 提供了插件机制,可以自定义插件来扩展 Prometheus 监控能力。在自定插件中,需要扩展 JMeter 的 BackendListener,让在采样器执行完成时,更新每个压测指标,如成功请求数、失败请求数、请求响应时长。并将各压测指标在内存中保存,在 Prometheus 拉数据时,通过 HTTP 服务暴露出去。整体结构如下:
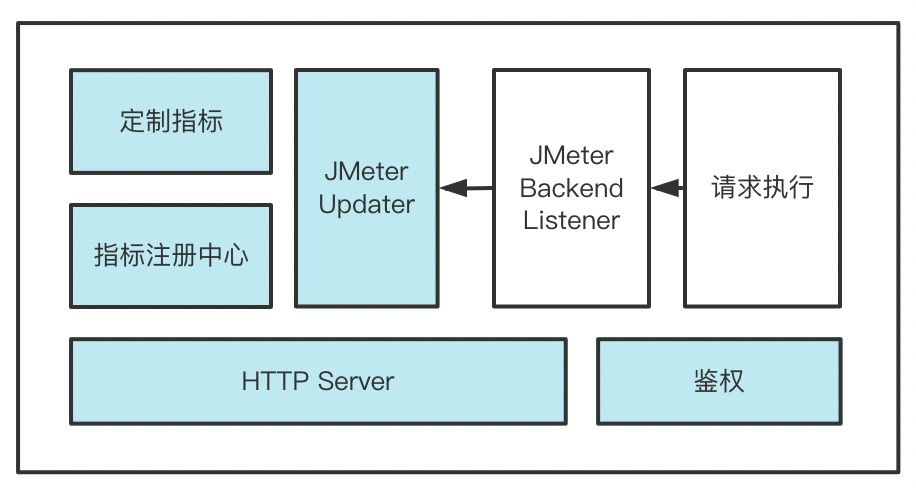
JMeter 自定义插件需要改造的点:
- 增加指标注册中心
- 扩展 Prometheus 指标更新器
- 实现自定义 JMeter BackendListener,在采样器执行结束后,调用 Prometheus 更新器
- 实现 HTTP Server,如果有安全需要,补充鉴权逻辑
PTS 压测工具
性能测试 PTS(Performance Testing Service)是一款阿里云 SaaS 化的性能测试工具。PTS支持自研压测引擎,同时支持开源 JMeter 压测,在 PTS 上开放压测指标到 Prometheus,无需开发自定义插件来改造引擎,只需 3 步白屏化操作即可。
具体步骤如下:
- PTS 压测的高级设置中,打开【Prometheus】开关
- 压测开始后,在【监控导出】一键复制 Prometheus 配置
- 自建的 Prometheus 中粘贴并热加载此配置,即可生效
详细参考:《如何将 PTS 压测的指标数据输出到 Prometheus》[4]
快速搭建 Grafana 监控大盘
PTS 提供了官方 Grafana 大盘模板[5],支持一键导入监控大盘,并可以灵活编辑和扩展,满足您的定制监控需求。
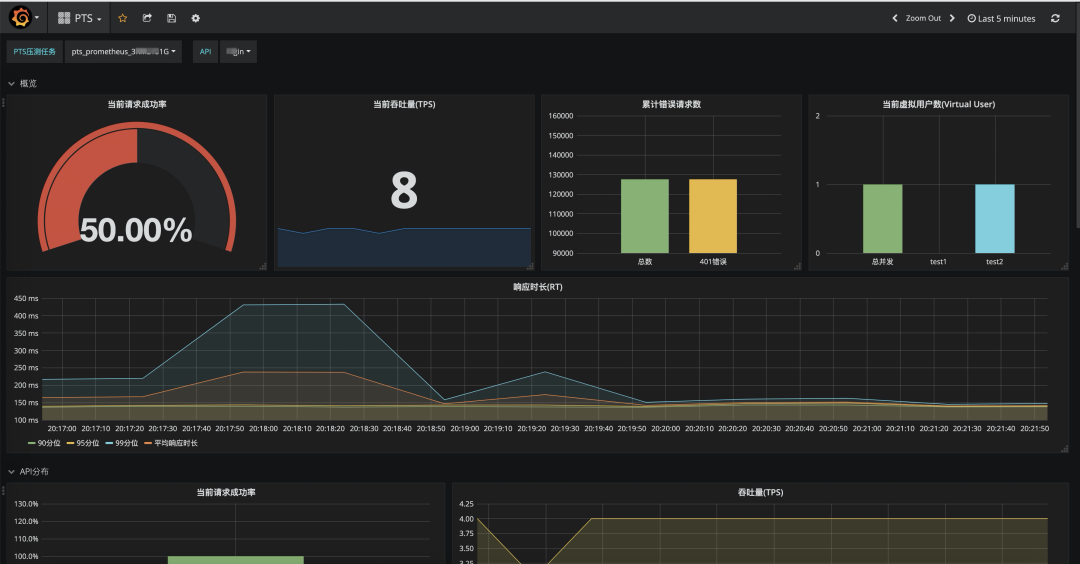
本大盘提供了全局请求成功率,系统吞吐量(TPS),99、95、90 分位响应时长,以及按错误状态码聚合的错误请求数等数据。
在 API 分布专栏中,可以直观的对比各 API 的监控指标,快速定位性能短板 API。
在 API 详情专栏中,可以查看单个 API 的详细指标,准确定位性能瓶颈。
另外,大盘还提供了施压机的JVM垃圾回收监控指标,可以辅助判断施压机是否是压测链路中的性能瓶颈。
导入步骤如下:
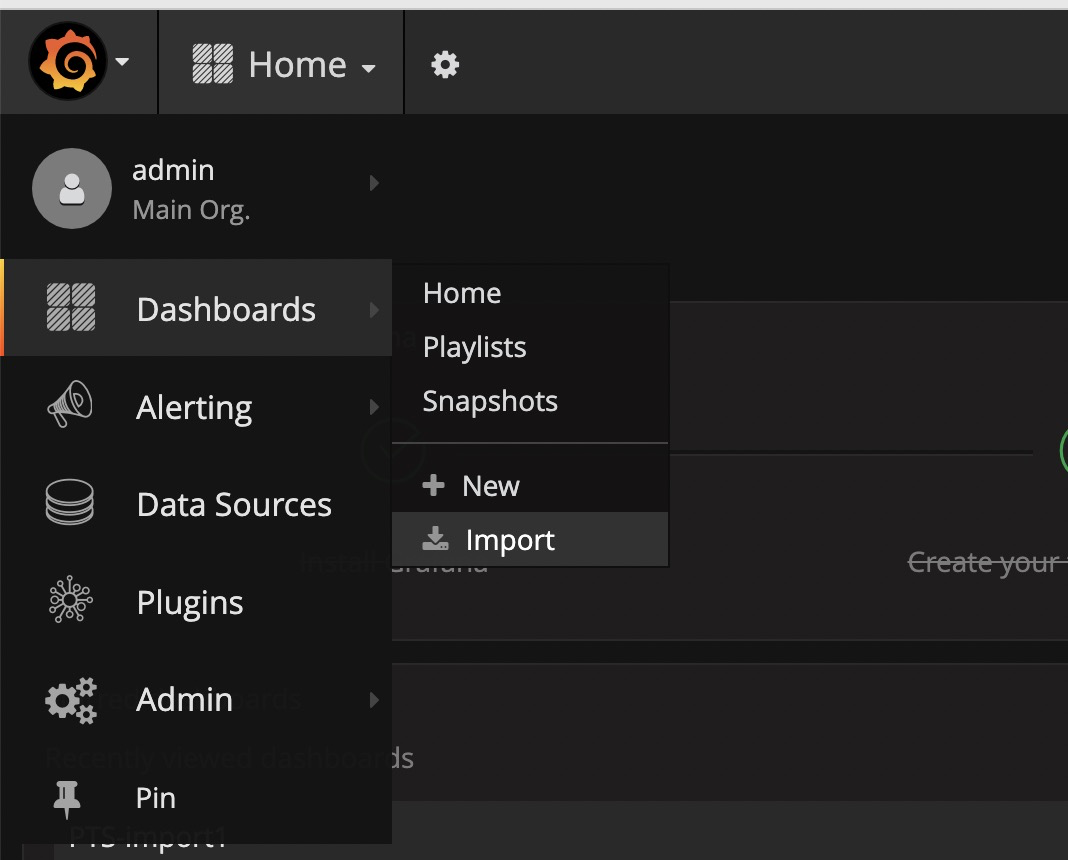
步骤一
在菜单栏,点击 Dashboard 下的 import:
步骤二
填写 PTS Dashboard 的 id:15981
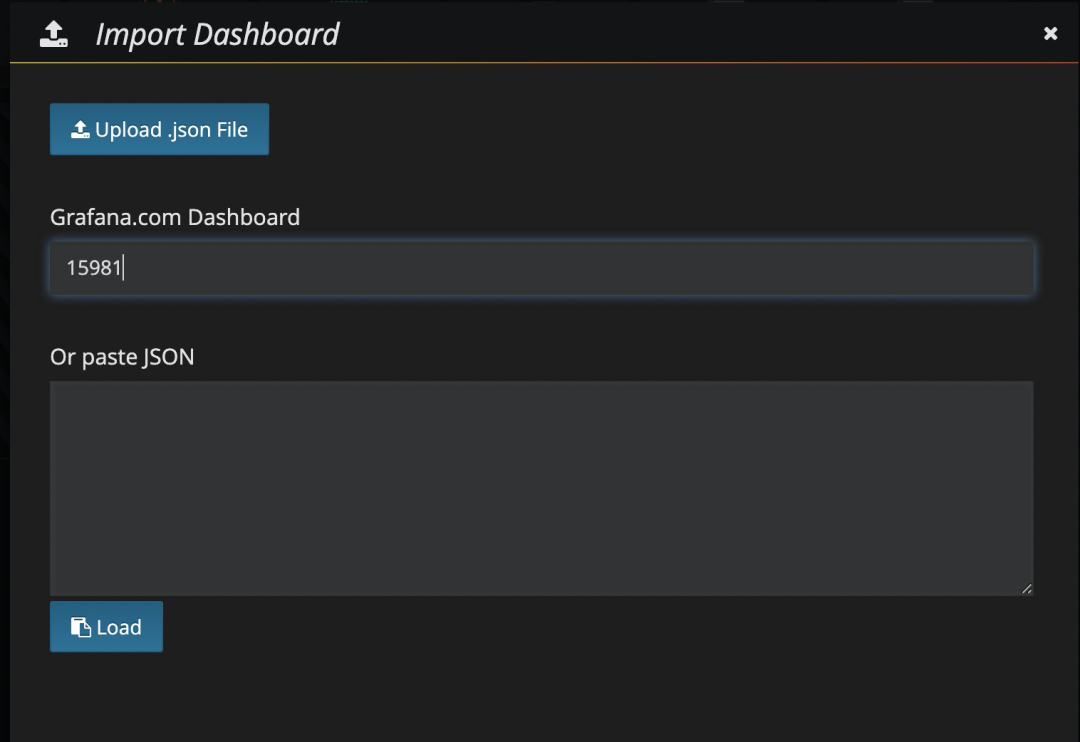
在 Prometheus 选择您已有的数据源,本示例中数据源名为 Prometheus。选中后,单击 Import 导入
步骤三
导入后,在左上角【PTS 压测任务】,选择需要监控的压测任务,即可看到当前监控大盘。
此任务名对应 PTS 控制台在监控导出-Prometheus 配置中的 jobname。
总结
本文阐述了
- 什么是性能测试可观测
- 为什么用 Prometheus 做压测性能指标监控
- 如何使用开源 JMeter 和云上 PTS 实现基于 Prometheus 的压测监控
PTS 压测监控导出 Prometheus 功能,目前免费公测中,欢迎使用。
本文为阿里云原创内容,未经允许不得转载。
云原生时代如何用 Prometheus 实现性能压测可观测-Metrics 篇的更多相关文章
- 阿里云弹性容器实例产品 ECI ——云原生时代的基础设施
阿里云弹性容器实例产品 ECI ——云原生时代的基础设施 1. 什么是 ECI 弹性容器实例 ECI (Elastic Container Instance) 是阿里云在云原生时代为用户提供的基础计算 ...
- 进击的 Java ,云原生时代的蜕变
作者| 易立 阿里云资深技术专家 导读:云原生时代的来临,与Java 开发者到底有什么联系?有人说,云原生压根不是为了 Java 存在的.然而,本文的作者却认为云原生时代,Java 依然可以胜任&qu ...
- 进击的.NET 在云原生时代的蜕变
你一定看过这篇文章 <进击的 Java ,云原生时代的蜕变>, 本篇文章的灵感来自于这篇文章.明天就将正式发布.NET Core 3.0, 所以写下这篇文章让大家全面认识.NET Cor ...
- [转帖]从 SOA 到微服务,企业分布式应用架构在云原生时代如何重塑?
从 SOA 到微服务,企业分布式应用架构在云原生时代如何重塑? 2019-10-08 10:26:28 阿里云云栖社区 阅读数 54 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权 ...
- .NET 在云原生时代的蜕变,让我在云时代脱颖而出
.NET 生态系统是一个不断变化的生态圈,我相信它正在朝着一个伟大的方向发展.有了开源和跨平台这两个关键优先事项,我们就可以放心了.云原生对应用运行时的不同需求,说明一个.NET Core 在云原生时 ...
- 【转】.NET 在云原生时代的蜕变,让我在云时代脱颖而出
原创:张善友 原文:https://www.cnblogs.com/shanyou/p/12198741.html .NET 生态系统是一个不断变化的生态圈,我相信它正在朝着一个伟大的方向发展.有了开 ...
- 云原生时代 给予.NET的机会
.NET诞生于与Java的竞争,微软当年被罚款20亿美元. Java绝不仅仅是一种语言,它是COM的替代者! 而COM恰恰是Windows的编程模型.而Java编程很多时候比C++编程要容易的多,更致 ...
- 云原生时代,Java的危与机(周志明)
说明 本篇文章是转载自周志明老师的文章,链接地址:https://www.infoq.cn/article/RQfWw2R2ZpYQiOlc1WBE 今天,25 岁的 Java 仍然是最具有统治力的编 ...
- 云原生时代的Java
原文链接(作者:周志明):https://time.geekbang.org/column/article/321185 公开课链接:https://time.geekbang.org/opencou ...
- CODING —— 云原生时代的研发工具领跑者
本文为 CODING 创始人兼 CEO 张海龙在腾讯云 CIF 工程效能峰会上所做的分享. 文末可前往峰会官网,观看回放并下载 PPT. 大家上午好,很高兴能有机会与大家分享 CODING 最近的一些 ...
随机推荐
- YUV亮度扫描小工具,如何确定尺寸以及错误尺寸下图像发生什么变化
地址https://github.com/bbqz007/zhelper-wxWidgets 当你有一个帧yuv,但却不知道长宽还有格式时,本demo可以帮你通过扫描Y分量灰度图,确定长宽,然后选择合 ...
- Ubuntu 14.04 升级到Gnome3.12z的折腾之旅(警示后来者)+推荐Extensions.-------(一)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文发布于 2014-12-19 22:40:20 ...
- java方法的内存及练习
方法的内存 一.方法调用的基本内存原理: Java内存分配 栈: 方法运行时使用的内存方法进栈运行,运行完毕就出栈 堆: newl出来的,都在堆内存中开辟了一个小空间 方法区: 存储可以运行的clas ...
- AI金融预测领域综述文章筛选,附论文及代码链接,2021年版
21年的综述最近读了3篇,总结笔记如下: (2021)Systematic Literature Review: Stock Price Prediction Using Machine Learni ...
- CenterNet:Corner-Center三元关键点,检测性能全面提升 | ICCV 2019
为了解决CornerNet缺乏目标内部信息的问题,提出了CenterNet使用三元组进行目标检测,包含一个中心关键点和两个角点.从实验结果来看,CenterNet相对于CornerNet只增加了少量推 ...
- KingbaseES 优化之sql优化方法
金仓数据库在sql层面提供了多种优化手段,但是这些的前提时需要保证我们的统计信息准确,优化器已经在正确信息下选择了它认为的最优的执行计划, 优化手段包括 •使用索引 索引解决的问题用于在进行表的扫描时 ...
- .NET分布式Orleans - 7 - Streaming
概念 在Orleans中,Streaming是一组API和功能集,它提供了一种构建.发布和消费数据流的方式. 这些流可以是任何类型的数据,从简单的消息到复杂的事件或数据记录.Streaming API ...
- C++移动构造与std::move()
背景及问题 如下程序所示: #include<iostream> class MyString { public: MyString() = default; MyString(const ...
- Java解析json数据(fastjson2)
Json数据 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式.它以易于阅读和编写的方式来表示结构化数据,常用于在不同系统之间进行数据交互和传输. JSON使 ...
- HTTP内容协商机制和断点续传