【pytorch学习】之线性代数
3 线性代数
3.1 标量
如果你曾经在餐厅支付餐费,那么应该已经知道一些基本的线性代数,比如在数字间相加或相乘。例如,北京的温度为52◦F(华氏度,除摄氏度外的另一种温度计量单位)。严格来说,仅包含一个数值被称为标量(scalar)。如果要将此华氏度值转换为更常用的摄氏度,则可以计算表达式$C = \frac{5}{9} \times (F - 32) $ ,并将f赋为52。在此等式中,每一项(5、9和32)都是标量值。符号c和f称为变量(variable),它们表示未知的标量值。使用了数学表示法,其中标量变量由普通小写字母表示(例如,x、y和z)。用R表示所有(连续)实数标量的空间,之后将严格定义空间(space)是什么,但现在只要记住表达式$ x \in \mathbb{R}$是表示x是一个实值标量的正式形式。符号∈称为“属于”,它表示“是集合中的成员”。例如x, y ∈ {0, 1}可以用来表明x和y是值只能为0或1的数字。
标量由只有一个元素的张量表示。下面的代码将实例化两个标量,并执行一些熟悉的算术运算,即加法、乘法、除法和指数。
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
x + y, x * y, x / y, x**y
(tensor(5.), tensor(6.), tensor(1.5000), tensor(9.))
3.2 向量
向量可以被视为标量值组成的列表。这些标量值被称为向量的元素(element)或分量(component)。当向量表示数据集中的样本时,它们的值具有一定的现实意义。例如,如果我们正在训练一个模型来预测贷款违约风险,可能会将每个申请人与一个向量相关联,其分量与其收入、工作年限、过往违约次数和其他因素相对应。如果我们正在研究医院患者可能面临的心脏病发作风险,可能会用一个向量来表示每个患者,其分量为最近的生命体征、胆固醇水平、每天运动时间等。在数学表示法中,向量通常记为粗体、小写的符号(例如,\(x\)、\(y\)和\(z\)))。
人们通过一维张量表示向量。一般来说,张量可以具有任意长度,取决于机器的内存限制。
x = torch.arange(4)
x
tensor([0, 1, 2, 3])
我们可以使用下标来引用向量的任一元素,例如可以通过\(x_i\)来引用第i个元素。注意,元素\(x_i\)是一个标量,所以我们在引用它时不会加粗。大量文献认为列向量是向量的默认方向,在本书中也是如此。在数学中,向量x可以写为: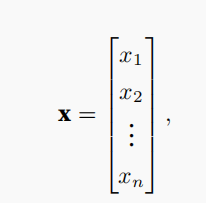
其中\(x_1\), . . . , \(x_n\)是向量的元素。在代码中,我们通过张量的索引来访问任一元素。
x[3]
tensor(3)
长度、维度和形状
向量只是一个数字数组,就像每个数组都有一个长度一样,每个向量也是如此。在数学表示法中,如果我们想说一个向量x由n个实值标量组成,可以将其表示为$ x \in \mathbb{R}^n$
。向量的长度通常称为向量的维度(dimension)。与普通的Python数组一样,我们可以通过调用Python的内置len()函数来访问张量的长度。
len(x)# 4
当用张量表示一个向量(只有一个轴)时,我们也可以通过.shape属性访问向量的长度。形状(shape)是一个元素组,列出了张量沿每个轴的长度(维数)。对于只有一个轴的张量,形状只有一个元素。
x.shape
torch.Size([4])
请注意,维度(dimension)这个词在不同上下文时往往会有不同的含义,这经常会使人感到困惑。为了清楚起见,我们在此明确一下:向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。然而,张量的维度用来表示张量具有的轴数。在这个意义上,张量的某个轴的维数就是这个轴的长度。
3.3 矩阵
正如向量将标量从零阶推广到一阶,矩阵将向量从一阶推广到二阶。矩阵,我们通常用粗体、大写字母来表示(例如,\(X\)、\(Y\)和\(Z\)),在代码中表示为具有两个轴的张量。
数学表示法使用\(A \in \mathbb{R}^{m \times n}\) 来表示矩阵A,其由m行和n列的实值标量组成。我们可以将任意矩阵\(A \in \mathbb{R}^{m \times n}\) 视为一个表格,其中每个元素aij属于第i行第j列:
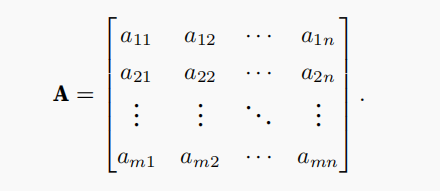
对于任意\(A \in \mathbb{R}^{m \times n}\),A的形状是\((m,n)\)或\(m × n\)。当矩阵具有相同数量的行和列时,其形状将变为正方形;因此,它被称为方阵(square matrix)。
当调用函数来实例化张量时,我们可以通过指定两个分量m和n来创建一个形状为m × n的矩阵。
A = torch.arange(20).reshape(5, 4)
A
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
我们可以通过行索引(i)和列索引(j)来访问矩阵中的标量元素\(a_{ij}\),例如\([A]_{ij}\)。如果没有给出矩阵A的标量元素,如在 (2.3.2)那样,我们可以简单地使用矩阵A的小写字母索引下标\(a_{ij}\) 来引用\([A]_{ij}\)。为了表示起来简单,只有在必要时才会将逗号插入到单独的索引中,例如$ a_{2,3j}\(和\)[A]_{2i-1,3}$。
当我们交换矩阵的行和列时,结果称为矩阵的转置(transpose)。通常用 \(a^\top\)来表示矩阵的转置,如果\(B = A^\top\),则对于任意\(i\)和\(j\),都有\(b_{ij} = a_{ji}\)。因此,在 (2.3.2)中的转置是一个形状为\(n × m\)的矩阵:

现在在代码中访问矩阵的转置。
A.T
tensor([[ 0, 4, 8, 12, 16],
[ 1, 5, 9, 13, 17],
[ 2, 6, 10, 14, 18],
[ 3, 7, 11, 15, 19]])
作为方阵的一种特殊类型,对称矩阵(symmetric matrix)A等于其转置:\(A = A^\top\)。这里定义一个对称矩阵B:
B = torch.tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B
tensor([[1, 2, 3],
[2, 0, 4],
[3, 4, 5]])
现在我们将B与它的转置进行比较。
B == B.T
tensor([[True, True, True],
[True, True, True],
[True, True, True]])
矩阵是有用的数据结构:它们允许我们组织具有不同模式的数据。例如,我们矩阵中的行可能对应于不同的房屋(数据样本),而列可能对应于不同的属性。因此,尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中,将每个数据样本作为矩阵中的行向量更为常见。这种约定将支持常见的深度学习实践。例如,沿着张量的最外轴,我们可以访问或遍历小批量的数据样本。
3.4 张量
就像向量是标量的推广,矩阵是向量的推广一样,我们可以构建具有更多轴的数据结构。张量(“张量”指代数对象)是描述具有任意数量轴的n维数组的通用方法。例如,向量是一阶张量,矩阵是二阶张量。张量用特殊字体的大写字母表示(例如,\(X、Y和Z\)),它们的索引机制与矩阵类似。
当我们开始处理图像时,张量将变得更加重要,图像以n维数组形式出现,其中3个轴对应于高度、宽度,以及一个通道(channel)轴,用于表示颜色通道(红色、绿色和蓝色)。现在先将高阶张量暂放一边,而是专注学习其基础知识。
X = torch.arange(24).reshape(2, 3, 4)
X
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
3.5 张量算法的基本性质
标量、向量、矩阵和任意数量轴的张量(“张量”指代数对象)有一些实用的属性。例如,从按元素操作的定义中可以注意到,任何按元素的一元运算都不会改变其操作数的形状。同样,给定具有相同形
状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。例如,将两个相同形状的矩阵相加,会在这两个矩阵上执行元素加法。
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B
(tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.]]),
tensor([[ 0., 2., 4., 6.],
[ 8., 10., 12., 14.],
[16., 18., 20., 22.],
[24., 26., 28., 30.],
[32., 34., 36., 38.]]))
具体而言,两个矩阵的按元素乘法称为Hadamard积.
A * B
tensor([[ 0., 1., 4., 9.],
[ 16., 25., 36., 49.],
[ 64., 81., 100., 121.],
[144., 169., 196., 225.],
[256., 289., 324., 361.]])
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
a = 2
X = torch.arange(24).reshape(2, 3, 4)
a + X, (a * X).shape
(tensor([[[ 2, 3, 4, 5],
[ 6, 7, 8, 9],
[10, 11, 12, 13]],
[[14, 15, 16, 17],
[18, 19, 20, 21],
[22, 23, 24, 25]]]),
torch.Size([2, 3, 4]))
3.6 降维
我们可以对任意张量进行的一个有用的操作是计算其元素的和。数学表示法使用\(\sum\)符号表示求和。为了表示长度为d的向量中元素的总和,可以记为\(\sum_{i=1}^{d} x_i\)。在代码中可以调用计算求和的函数:
x = torch.arange(4, dtype=torch.float32)
x, x.sum()
(tensor([0., 1., 2., 3.]), tensor(6.))
我们可以表示任意形状张量的元素和。例如,矩阵A中元素的和可以记为\(\sum_{i=1}^{m} \sum_{j=1}^{n} a_{ij}\)
A.shape, A.sum()
(torch.Size([5, 4]), tensor(190.))
默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。我们还可以指定张量沿哪一个轴来通过求和降低维度。以矩阵为例,为了通过求和所有行的元素来降维(轴0),可以在调用函数时指定axis=0。由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape
(tensor([40., 45., 50., 55.]), torch.Size([4]))
指定axis=1将通过汇总所有列的元素降维(轴1)。因此,输入轴1的维数在输出形状中消失。
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape
沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
A.sum(axis=[0, 1]) # 结果和A.sum()相同
tensor(190.)
一个与求和相关的量是平均值(mean或average)。我们通过将总和除以元素总数来计算平均值。在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean(), A.sum() / A.numel()
(tensor(9.5000), tensor(9.5000))
同样,计算平均值的函数也可以沿指定轴降低张量的维度。
A.mean(axis=0), A.sum(axis=0) / A.shape[0]
(tensor([ 8., 9., 10., 11.]), tensor([ 8., 9., 10., 11.]))
非降维求和
但是,有时在调用函数来计算总和或均值时保持轴数不变会很有用。
sum_A = A.sum(axis=1, keepdims=True)
sum_A
tensor([[ 6.],
[22.],
[38.],
[54.],
[70.]])
由于sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A。
A / sum_A
tensor([[0.0000, 0.1667, 0.3333, 0.5000],
[0.1818, 0.2273, 0.2727, 0.3182],
[0.2105, 0.2368, 0.2632, 0.2895],
[0.2222, 0.2407, 0.2593, 0.2778],
[0.2286, 0.2429, 0.2571, 0.2714]])
如果我们想沿某个轴计算A元素的累积总和,比如axis=0(按行计算),可以调用cumsum函数。此函数不会沿任何轴降低输入张量的维度。
A.cumsum(axis=0)
tensor([[ 0., 1., 2., 3.],
[ 4., 6., 8., 10.],
[12., 15., 18., 21.],
[24., 28., 32., 36.],
[40., 45., 50., 55.]])
3.7 点积(Dot Product)
我们已经学习了按元素操作、求和及平均值。另一个最基本的操作之一是点积。给定两个向量\(x, y ∈ \mathbb{R}^d\),它们的点积(dot product)\(x^\top y\) (或\(( \langle x, y \rangle )\))是相同位置的按元素乘积的和:\(x^\top y = \sum_{i=1}^{d} x_i y_i\)。
y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y)
(tensor([0., 1., 2., 3.]), tensor([1., 1., 1., 1.]), tensor(6.))
注意,我们可以通过执行按元素乘法,然后进行求和来表示两个向量的点积:
torch.sum(x * y)
tensor(6.)
3.8 矩阵-向量积
现在我们知道如何计算点积,可以开始理解矩阵-向量积(matrix‐vector product).在代码中使用张量表示矩阵‐向量积,我们使用mv函数。当我们为矩阵A和向量x调用torch.mv(A, x)时,会执行矩阵‐向量积。注意,A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。
A.shape, x.shape, torch.mv(A, x)
(torch.Size([5, 4]), torch.Size([4]), tensor([ 14., 38., 62., 86., 110.]))
3.9 矩阵-矩阵乘法
在掌握点积和矩阵‐向量积的知识后,那么矩阵‐矩阵乘法(matrix‐matrix multiplication)应该很简单.我们可以将矩阵‐矩阵乘法AB看作简单地执行m次矩阵‐向量积,并将结果拼接在一起,形成一个n × m矩阵。在下面的代码中,我们在A和B上执行矩阵乘法。这里的A是一个5行4列的矩阵,B是一个4行3列的矩阵。两者相乘后,我们得到了一个5行3列的矩阵。
B = torch.ones(4, 3)
torch.mm(A, B)
tensor([[ 6., 6., 6.],
[22., 22., 22.],
[38., 38., 38.],
[54., 54., 54.],
[70., 70., 70.]])
矩阵‐矩阵乘法可以简单地称为矩阵乘法,不应与“Hadamard积”混淆。
3.10 范数
线性代数中最有用的一些运算符是范数(norm)。非正式地说,向量的范数是表示一个向量有多大。这里考虑的大小(size)概念不涉及维度,而是分量的大小。在线性代数中,向量范数是将向量映射到标量的函数f。给定任意向量x,向量范数要满足一些属性。第一个性质是:如果我们按常数因子α缩放向量的所有元素,其范数也会按相同常数因子的绝对值缩放:
\]
第二个性质是熟悉的三角不等式:
\]
第三个性质简单地说范数必须是非负的:
\]
这是有道理的。因为在大多数情况下,任何东西的最小的大小是0。最后一个性质要求范数最小为0,当且仅当向量全由0组成。
\]
范数听起来很像距离的度量。欧几里得距离和毕达哥拉斯定理中的非负性概念和三角不等式可能会给出一些启发。事实上,欧几里得距离是一个L2范数:假设n维向量x中的元素是\(x_1, . . . , x_n,\)其L2范数是向量元素平方和的平方根:
\]
u = torch.tensor([3.0, -4.0])
torch.norm(u)
tensor(5.)
深度学习中更经常地使用\(L_2\)范数的平方,也会经常遇到\(L_1\)范数,它表示为向量元素的绝对值之和:
\]
\(与L_2范数相比,L_1范数受异常值的影响较小。为了计算L_1范数,我们将绝对值函数和按元素求和组合起来\)。
torch.abs(u).sum()
tensor(7.)
范数和目标
在深度学习中,我们经常试图解决优化问题:最大化分配给观测数据的概率; 最小化预测和真实观测之间的距离。用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。目标,或许是深度学习算法最重要的组成部分(除了数据),通常被表达为范数。
声明:
本系列学习笔记主要以《动手学深度学习》的pytorch版本为主。
详细见GitHub:https://github.com/d2l-ai/d2l-zh
或者 https://zh.d2l.ai/
【pytorch学习】之线性代数的更多相关文章
- 【深度学习】Pytorch学习基础
目录 pytorch学习 numpy & Torch Variable 激励函数 回归 区分类型 快速搭建法 模型的保存与提取 批训练 加速神经网络训练 Optimizer优化器 CNN MN ...
- Pytorch学习之源码理解:pytorch/examples/mnists
Pytorch学习之源码理解:pytorch/examples/mnists from __future__ import print_function import argparse import ...
- Pytorch学习记录-torchtext和Pytorch的实例( 使用神经网络训练Seq2Seq代码)
Pytorch学习记录-torchtext和Pytorch的实例1 0. PyTorch Seq2Seq项目介绍 1. 使用神经网络训练Seq2Seq 1.1 简介,对论文中公式的解读 1.2 数据预 ...
- Pytorch学习--编程实战:猫和狗二分类
Pytorch学习系列(一)至(四)均摘自<深度学习框架PyTorch入门与实践>陈云 目录: 1.程序的主要功能 2.文件组织架构 3. 关于`__init__.py` 4.数据处理 5 ...
- 新手必备 | 史上最全的PyTorch学习资源汇总
目录: PyTorch学习教程.手册 PyTorch视频教程 PyTorch项目资源 - NLP&PyTorch实战 - CV&PyTorch实战 PyTorch论 ...
- [深度学习] Pytorch学习(一)—— torch tensor
[深度学习] Pytorch学习(一)-- torch tensor 学习笔记 . 记录 分享 . 学习的代码环境:python3.6 torch1.3 vscode+jupyter扩展 #%% im ...
- pytorch学习笔记(6)--神经网络非线性激活
如果神经元的输出是输入的线性函数,而线性函数之间的嵌套任然会得到线性函数.如果不加非线性函数处理,那么最终得到的仍然是线性函数.所以需要在神经网络中引入非线性激活函数. 常见的非线性激活函数主要包括S ...
- pytorch学习-WHAT IS PYTORCH
参考:https://pytorch.org/tutorials/beginner/blitz/tensor_tutorial.html#sphx-glr-beginner-blitz-tensor- ...
- Pytorch学习笔记(一)——简介
一.Tensor Tensor是Pytorch中重要的数据结构,可以认为是一个高维数组.Tensor可以是一个标量.一维数组(向量).二维数组(矩阵)或者高维数组等.Tensor和numpy的ndar ...
- Pytorch学习笔记(二)---- 神经网络搭建
记录如何用Pytorch搭建LeNet-5,大体步骤包括:网络的搭建->前向传播->定义Loss和Optimizer->训练 # -*- coding: utf-8 -*- # Al ...
随机推荐
- k8s标签的增删改查和选择器
在 Kubernetes(K8s)中,标签(Label)是与资源对象相关联的键值对,用于实现多维度的资源分组管理功能.下面是关于 Kubernetes 标签的增删改查操作的简要说明: 查询标签 (查) ...
- 各种O总结及阿里代码规范总结
首先梳理下POJO POJO包括 DO/DTO/BO/VO(所有的POJO类属性必须使用包装数据类型.) 定义 DO/DTO/VO 等 POJO 类时,不要设定任何属性默认值. controller使 ...
- MyBatis Java 和 Mysql数据库 数据类型对应表
类型处理器(typeHandlers) MyBatis 在设置预处理语句(PreparedStatement)中的参数或从结果集中取出一个值时, 都会用类型处理器将获取到的值以合适的方式转换成 Jav ...
- Welcome to YARP - 1.认识 YARP 并构建反向代理服务
目录 Welcome to YARP - 1.认识YARP并搭建反向代理服务 Welcome to YARP - 2.配置功能 Welcome to YARP - 3.负载均衡 Welcome to ...
- python面向对象(继承)
一 继承 1.什么是继承1)继承是一种创建新类的方式,新建的类可称为子类或派生类,父类又可称为基类或超类子类会遗传父类的属性2)需要注意的是:python支持多继承 在python中,新建的类可以继承 ...
- JS数据扁平化
最近找到了一些数据扁平化的精品文章,这里分享给大家,希望对大家有所帮助 什么是扁平化 数组的扁平化,就是将一个嵌套多层的数组 array (嵌套可以是任何层数)转换为只有一层的数组. 举个例子,假设有 ...
- 学习笔记-安装kafka集群
官网地址:https://kafka.apache.org/ 1.下载解压 #下载 wget https://mirror.bit.edu.cn/apache/kafka/2.6.0/kafka_2. ...
- 基于proteus的555的门铃计数电路
基于proteus的555的门铃计数电路 1.实验原理 555定时器可以作为单稳态触发器完成计数所需的时钟.门铃工作时,需要进行一次计数.计数器使用前面使用的4026就可以将结果直接显示在数码管上. ...
- java使用ftp连接linux处理文件
1.Maven依赖 <!-- FTP使用包 --> <dependency> <groupId>commons-net</groupId> <ar ...
- Gaussian YOLOv3 : 对bbox预测值进行高斯建模输出不确定性,效果拔群 | ICCV 2019
在自动驾驶中,检测模型的速度和准确率都很重要,出于这个原因,论文提出Gaussian YOLOv3.该算法在保持实时性的情况下,通过高斯建模.损失函数重建来学习bbox预测值的不确定性,从而提高准确率 ...