MaxCompute中如何通过logview诊断慢作业
建模服务,在MaxCompute执行sql任务的时候有时候作业会很慢,本文通过查看logview排查具体任务慢的原因
在这里把任务跑的慢的问题划分为以下几类
- 资源不足导致的排队(一般是包年包月项目)
- 数据倾斜,数据膨胀
- 用户自身逻辑导致的运行效率低下
一、资源不足
一般的SQL任务会占用CPU、Memory这两个维度的资源,logview如何查看参考链接
1.1 查看作业耗时和执行的阶段


1.2 提交任务的等待
如果提交任务以后一直显示“Job Queueing...”则有可能是由于其他人的任务占用了资源组的资源,使得自己的任务在排队。
在SubStatusHistory中看Waiting for scheduling就是等待的时间

1.3 任务提交后的资源不足
这里还有另一种情况,虽然任务可以提交成功,但是由于所需的资源较大,当前的资源组不能同时启动所有的实例,导致出现了任务虽然有进度,但是执行并不快的情况。这种可以通过logview中的latency chart功能观察到。latency chart可以在detail中点击相应的task看到

上图显示的是一个资源充足的任务运行状态,可以看到蓝色部分的下端都是平齐的,表示几乎在同一时间启动了所有的实例。

而这个图形的下端呈现阶梯向上的形态,表示任务的实例是一点一点的调度起来的,运行任务时资源并不充足。如果任务的重要性较高,可以考虑增加资源,或者调高任务的优先级。
1.4资源不足的原因
1.通过cu管家查看cu是否占满,点到对应的任务点,找到对应时间看作业提交的情况

按cpu占比进行排序
(1)某个任务占用cu特别大,找到大任务看logview是什么原因造成(小文件过多、数据量确实需要这么多资源)。
(2)cu占比均匀说明是同时提交多个大任务把cu资源直接打满。

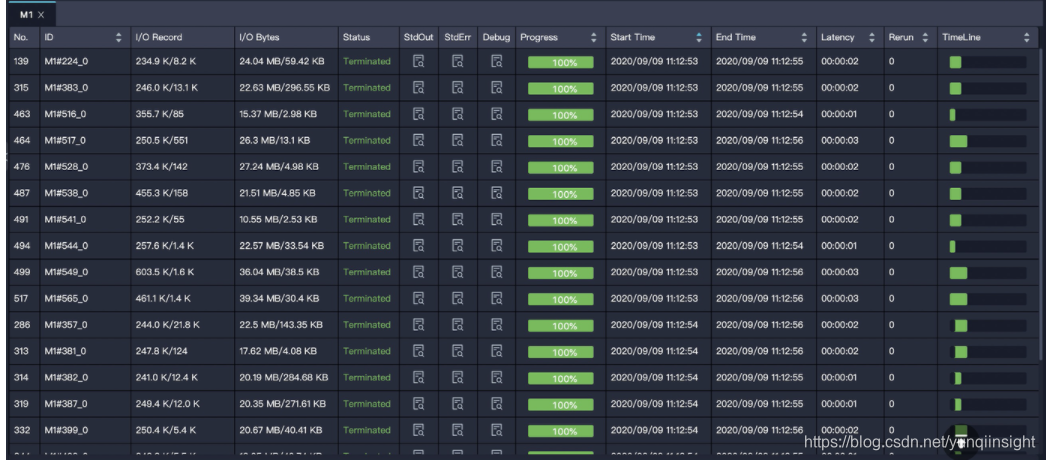
2.由于小文件过多导致cu占慢
map阶段的并行度是根据输入文件的分片大小,从而间接控制每个Map阶段下Worker的数量。默认是256m。如果是小文件会当作一个块读取如下图map阶段m1每个task的i/o bytes都只有1m或者几十kb,所以造成2500多个并行度瞬间把资源打满,说明该表下文件过多需要合并小文件

3.数据量大导致资源占满
可以增加购买资源,如果是临时作业可以加set odps.task.quota.preference.tag=payasyougo;参数,可以让指定作业临时跑到按量付费大资源池,
1.5任务并行度如何调节
MaxCompute的并行度会根据输入的数据和任务复杂度自动推测执行,一般不需要调节,理想情况并行度越大速度处理越快但是对于包年包月资源组可能会把资源组占满,导致任务都在等待资源这种情况会导致任务变慢
map阶段并行度
odps.stage.mapper.split.size :修改每个Map Worker的输入数据量,即输入文件的分片大小,从而间接控制每个Map阶段下Worker的数量。单位MB,默认值为256 MB
reduce的并行度
odps.stage.reducer.num :修改每个Reduce阶段的Worker数量
odps.stage.num:修改MaxCompute指定任务下所有Worker的并发数,优先级低于odps.stage.mapper.split.size、odps.stage.reducer.mem和odps.stage.joiner.num属性。
odps.stage.joiner.num:修改每个Join阶段的Worker数量。
二、数据倾斜
数据倾斜
【特征】task 中大多数 instance 都已经结束了,但是有某几个 instance 却迟迟不结束(长尾)。如下图中大多数(358个)instance 都结束了,但是还有 18 个的状态是 Running,这些 instance 运行的慢,可能是因为处理的数据多,也可能是这些instance 处理特定数据慢。

 解决方法:https://help.aliyun.com/document_detail/102614.html?spm=a2c4g.11186623.6.1160.28c978569uyE9f
解决方法:https://help.aliyun.com/document_detail/102614.html?spm=a2c4g.11186623.6.1160.28c978569uyE9f
三、逻辑问题
这里指用户的SQL或者UDF逻辑低效,或者没有使用最优的参数设定。表现出来的现象时一个Task的运行时间很长,而且每个实例的运行时间也比较均匀。这里的情况更加多种多样,有些是确实逻辑复杂,有些则有较大的优化空间。
数据膨胀
【特征】task 的输出数据量比输入数据量大很多。
比如 1G 的数据经过处理,变成了 1T,在一个 instance 下处理 1T 的数据,运行效率肯定会大大降低。输入输出数据量体现在 Task 的 I/O Record 和 I/O Bytes 这两项:
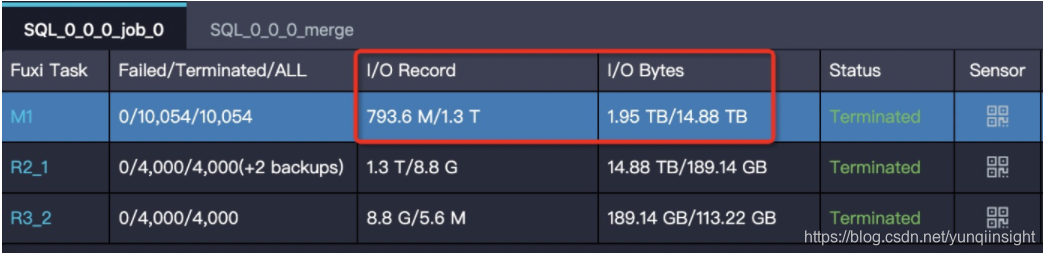
解决方法:确认业务逻辑确实需要这样,增大对应阶段并行度
UDF执行效率低
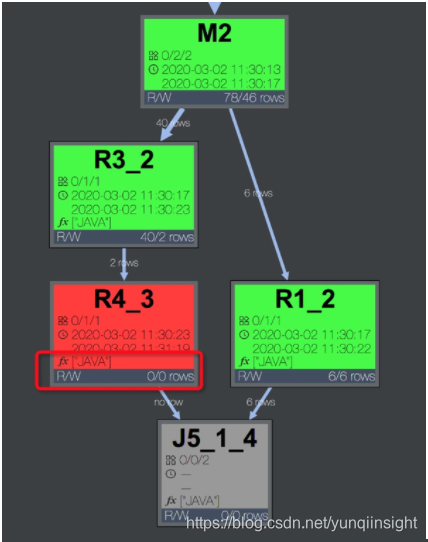
【特征】某个 task 执行效率低,且该 task 中有用户自定义的扩展。甚至是 UDF 的执行超时报错:“Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance”。
首先确定udf位置,点看慢的fuxi task, 可以看到operator graph 中是否包含udf,例如下图说明有java 的udf。
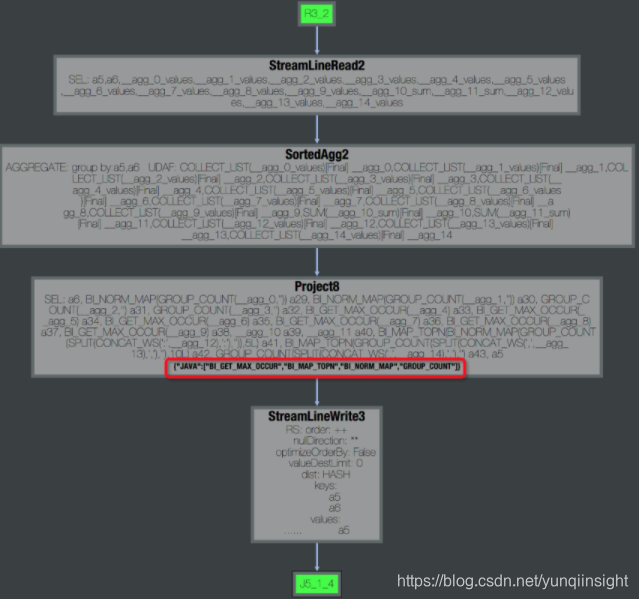
通过查看logview 中fuxi instance 的stdout 可以查看该operator 运行速度,正常情况 Speed(records/s) 在百万或者十万级别。
解决方法:检查udf逻辑尽量使用内置函数
本文为阿里云原创内容,未经允许不得转载。
MaxCompute中如何通过logview诊断慢作业的更多相关文章
- 在MaxCompute中利用bitmap进行数据处理
很多数据开发者使用bitmap技术对用户数据进行编码和压缩,然后利用bitmap的与/或/非的极速处理速度,实现类似用户画像标签的人群筛选.运营分析的7日活跃等分析.本文给出了一个使用MaxCompu ...
- 在MaxCompute中配置Policy策略遇到结果不一致的问题
背景信息: 本文以如下场景为基准进行编写,如下: 用户通过DataWorks-简单模式使用MaxCompute: 用户具有DataWorks默认角色,如DataWorks开发者角色: 用户通过cons ...
- 【监控笔记】【2.4】SQL Server中的 Ring Buffer 诊断各种系统资源压力情况
SQL Server 操作系统(SQLOS)负责管理特定于SQL Server的操作系统资源. 其中相关的动态管理试图sys.dm_os_ring_buffers将被标识为仅供参考.不提供支持.不保证 ...
- Hive中SQL查询转换成MapReduce作业的过程
- 一探究竟:善用 MaxCompute Studio 分析 SQL 作业
头疼的问题 MaxCompute 用户一个常见的问题是:同一个周期任务,为什么最近几天比之前慢了很多?或者为什么之前都能按时产出的作业最近经常破线? 通常来说,引起作业执行变慢的原因有:quota 组 ...
- 一条SQL在 MaxCompute 分布式系统中的旅程
摘要:2019杭州云栖大会大数据技术专场,由阿里云资深技术专家侯震宇.阿里云高级技术专家陈颖达以及阿里云资深技术专家戴谢宁共同以“SQL在 MaxCompute 分布式系统中的旅程 ”为题进行了演讲. ...
- 如何清除 DBA_DATAPUMP_JOBS 视图中的异常数据泵作业
解决方案 用于这个例子中的作业: - 导出作业 SCOTT.EXPDP_20051121 是一个正在运行的 schema 级别的导出作业 - 导出作业 SCOTT.SYS_EXPORT_TABLE_0 ...
- Yarn源码分析之MapReduce作业中任务Task调度整体流程(一)
v2版本的MapReduce作业中,作业JOB_SETUP_COMPLETED事件的发生,即作业SETUP阶段完成事件,会触发作业由SETUP状态转换到RUNNING状态,而作业状态转换中涉及作业信息 ...
- C#作业系统中的安全系统
比赛条件 编写多线程代码时,总是存在竞争条件的风险.当一个操作的输出取决于其控制之外的另一个过程的定时时,发生竞争条件. 竞争条件并不总是一个错误,但它是不确定行为的来源.当竞争条件确实导致错误时,可 ...
- MaxCompute Spark开发指南
0. 概述 本文档面向需要使用MaxCompute Spark进行开发的用户使用.本指南主要适用于具备有Spark开发经验的开发人员. MaxCompute Spark是MaxCompute提供的兼容 ...
随机推荐
- FFmpeg命令行之ffprobe
一.简述 ffprobe是ffmpeg命令行工具中相对简单的,此命令是用来查看媒体文件格式的工具. 二.命令格式 在命令行中输入如下格式的命令: ffprobe [文件名] 三.使用ffprobe查看 ...
- java的对象内存和数据类型
一.三种情况的对象内存图 (1)Java内存分配介绍: 栈: 队: 方法区(jdk7):加载字节码文件.(从jdk8开始取消方法区,新增元空间,把原来方法区的多种功能进行拆分,有的功能放到堆中,有的功 ...
- [Java]细节与使用经验
[版权声明]未经博主同意,谢绝转载!(请尊重原创,博主保留追究权) https://www.cnblogs.com/cnb-yuchen/p/18032072 出自[进步*于辰的博客] 纯文字阐述,内 ...
- LOTO示波器电源环路增益分析客户实测
我们在之前有文章介绍过LOTO示波器+信号源扫频测电源环路增益稳定性的方法和过程,可以参考演示视频如下: https://www.ixigua.com/7135738415382790663?logT ...
- Oracle的md5
CREATE OR REPLACE FUNCTION MD5(passwd IN VARCHAR2) RETURN VARCHAR2 IS retval varchar2(32); BEGIN ret ...
- MySQL联结
创建联结 mysql> SELECT vend_name,prod_name,prod_price FROM vendors,products WHERE vendors.vend_id=pro ...
- #主席树,并查集#CodeChef Sereja and Ballons
SEABAL 分析 考虑用并查集维护当前连续被打破的气球段,那么每次新增的区间就是 \([l_{x-1},x]\) 到 \([x,r_{x+1}]\) 的连接. 只要 \(l,r\) 分别满足在这之间 ...
- #差分约束系统,Spfa,SLF优化#HDU 3666 THE MATRIX PROBLEM
题目 多组询问,给定一个\(n*m\)的矩阵\(C\)和一个区间\([L,R]\), 问是否存在一个长度为\(n\)的序列\(A\)和一个长度为\(m\)的序列\(B\), 使得所有 \[\frac{ ...
- Python 条件和 if 语句
Python支持来自数学的通常逻辑条件: 等于:a == b 不等于:a != b 小于:a < b 小于或等于:a <= b 大于:a > b 大于或等于:a >= b 这些 ...
- Pandas通用函数和运算
Pandas继承了Numpy的运算功能,可以快速对每个元素进行运算,即包括基本运算(加减乘除等),也包括复杂运算(三角函数.指数函数和对数函数等). 通用函数使用 apply和applymap app ...