Lakehouse 架构解析与云上实践
简介:本文整理自 DataFunCon 2021大会上,阿里云数据湖构建云产品研发陈鑫伟的分享,主要介绍了 Lakehouse 的架构解析与云上实践。
作者简介:陈鑫伟(花名熙康),阿里云开源大数据-数据湖构建云产品研发
内容框架
- Lakehouse 概念与特性
- Lakehouse 架构与实现
- 云上 Lakehouse 架构与实践
- 案例分享及未来展望
Lakehouse 概念与特性
数据架构的演进
1980年后期,以 Teradata、Oracle 等产品为代表的数据仓库,主要用于解决 BI 分析和报表的数据采集与计算需求。通过内置存储系统,对上层提供数据抽象,数据经过清洗和转化,以已定义的schema结构写入,强调建模和数据管理以提供更好的性能和数据一致性,具备细粒度的数据管理和治理能力;支持事务、版本管理;数据深度优化,和计算引擎深度集成,提升了对外的 SQL 查询性能。然而,随着数据量的增长,数据仓库开始面临若干挑战。首先是存储和计算耦合,需要根据两者峰值采购,导致采购成本高、采购周期长;其次越来越多的数据集是非结构化的,数据仓库无法存储和查询这些数据;此外,数据不够开放,导致不易用于其他高级分析(如 ML )场景。
随着 Hadoop 生态的兴起,以 HDFS、S3、OSS 等产品为代表,统一存储所有数据,支持各种数据应用场景,架构较为复杂的数据湖开始流行。以基于 HDFS 存储、或者基于云上的对象存储这种相对低成本、高可用的统一存储系统,替换了原先的底层存储。可以存储各种原始数据,无需提前进行建模和数据转化,存储成本低且拓展性强;支持半结构化和非结构化的数据;数据更加开放,可以通过各种计算引擎或者分析手段读取数据,支持丰富的计算场景,灵活性强且易于启动。不过随着十年来的发展,数据湖的问题也逐渐暴露。数据链路长/组件多导致出错率高、数据可靠性差;各个系统间不断的数据迁移同步给数据一致性和时效性带来挑战;湖里的数据杂乱无章,未经优化直接访问查询会出现性能问题;整体系统的复杂性导致企业建设和维护成本高等。
为了解决上述问题,结合数据湖和数据仓库优势的 LakeHouse 应运而生。底层依旧是低成本、开放的存储,上层基于类似 Delta lake/Iceberg/Hudi 建设数据系统,提供数据管理特性和高效访问性能,支持多样数据分析和计算,综合了数据仓库以及数据湖的优点形成了新的架构。存算分离架构可以进行灵活扩展;减少数据搬迁,数据可靠性、一致性和实时性得到了保障;支持丰富的计算引擎和范式;此外,支持数据组织和索引优化,查询性能更优。不过,因为 LakeHouse 还处于快速发展期,关键技术迭代快且成熟的产品和系统少。在可借鉴案例不多的情况下,企业如果想采用 LakeHouse,需要有一定技术投入。
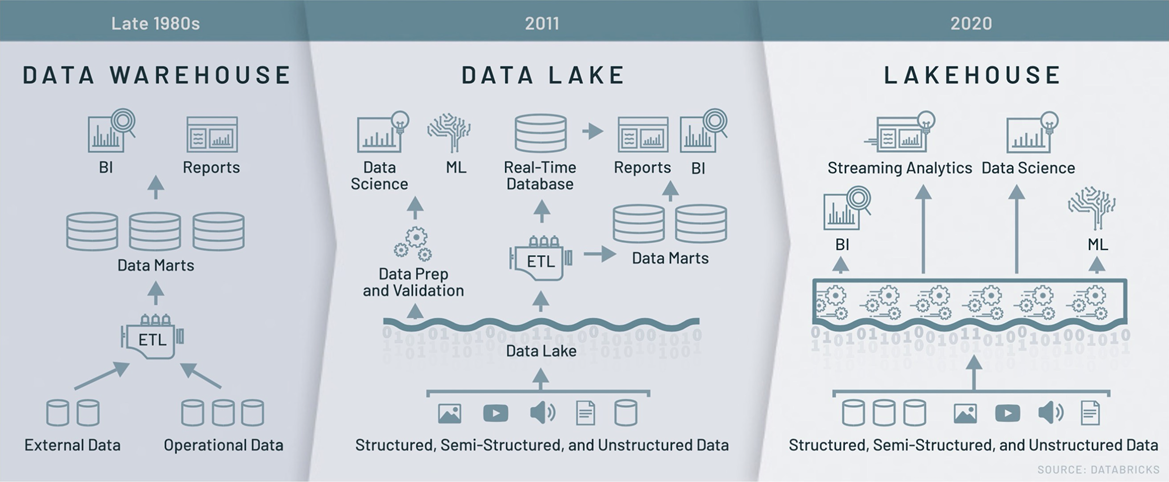
数据架构的对比
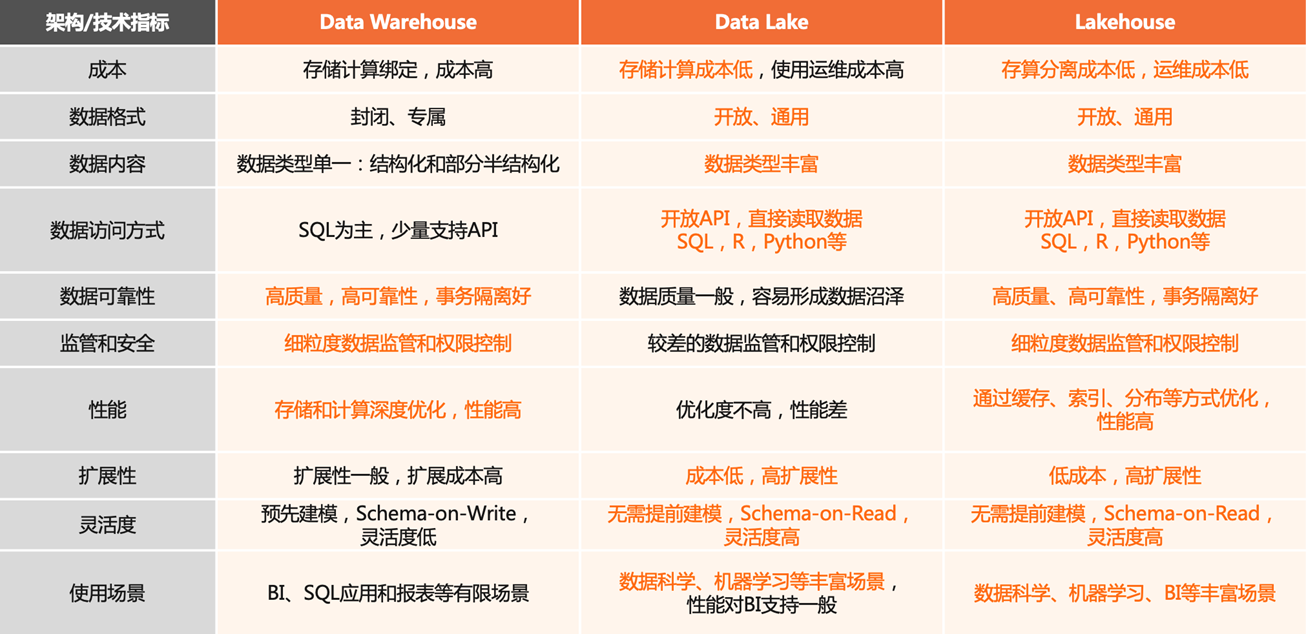
上图从多维度对数据仓库、数据湖、LakeHouse 进行了对比,可以明显看到 LakeHouse 综合了数据仓库和数据湖的优势,这也是 LakeHouse 被期待为“新一代数据架构基本范式”的原因。
Lakehouse 架构与实现
Lakehouse 架构图
Lakehouse = 云上对象存储 + 湖格式 + 湖管理平台
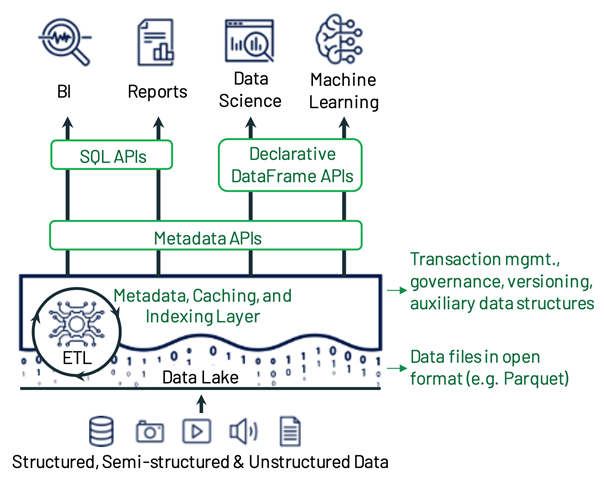
访问层
- 元数据层查询和定位数据
- 对象存储支持高吞吐的数据访问
- 开放的数据格式支持引擎直接读取
- Declarative DataFrame API 利用SQL引擎的优化和过滤能力
优化层
- Caching、Auxiliary data structures(indexing and statistics)、data layout optimization,Governance
事务层
- 实现支持事务隔离的元数据层,指明每个Table版本所包含的数据对象



存储层
- 云上对象存储,低成本,高可靠性,无限扩展,高吞吐,免运维
- 通用的数据格式,Parquet / Orc 等
Lakehouse 实现核心--湖格式
本文主要围绕 Delta Lake、IceBerg 两种湖格式展开介绍 Lakehouse 的特性。
Delta Lake
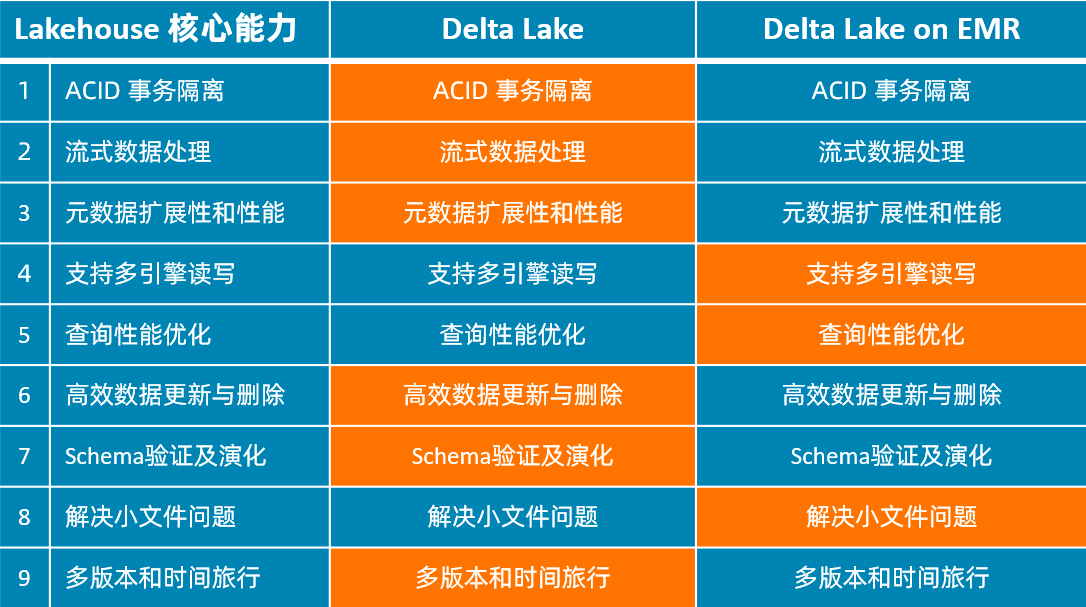
Delta Lake
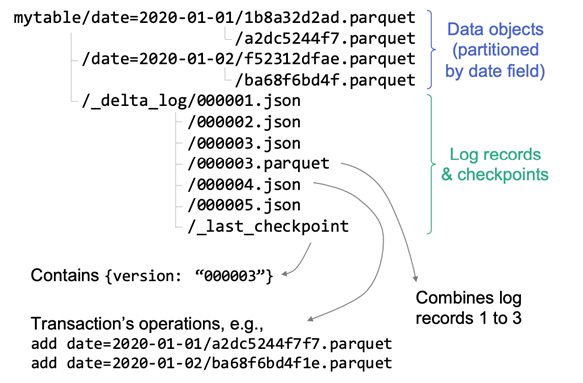
关键实现:事务日志 – Single Source of Truth
- 事务日志以事务提交为粒度,按序记录了所有对表的操作
- 串行化隔离写操作,写操作保证原子性,MVCC+乐观锁控制并发冲突
- 快照隔离读操作,支持读历史版本数据,实现时间旅行
- 文件级别数据更新重新,实现局部数据更新和删除
- 基于增量日志的数据处理
Delta Lake on EMR
针对 Delta Lake 开源版本的不足之处,阿里云 EMR 团队做了如下功能开发:
Optimize&Zorder
- 支持Zorder重新布局数据,结合dataskipping加速查询
- 实现高效的Zorder执行,7.8亿数据,2个字段,20分钟完成
- 支持Optimize,解决小文件问题,并支持自动compact
SavePoint
- 支持创建/删除/查询SAVEPOINT,永久保留指定版本的数据
Rollback
- 回退到历史某版本,用于修复数据
自动同步元数据到MetaStore
- 无需额外操作,将完整表信息和分区信息自动同步到metastore,用于Hive/Presto查询等;
多引擎查询支持
- 支持 Hive / Trino / Impala / 阿里云 MaxCompute 查询
Iceberg
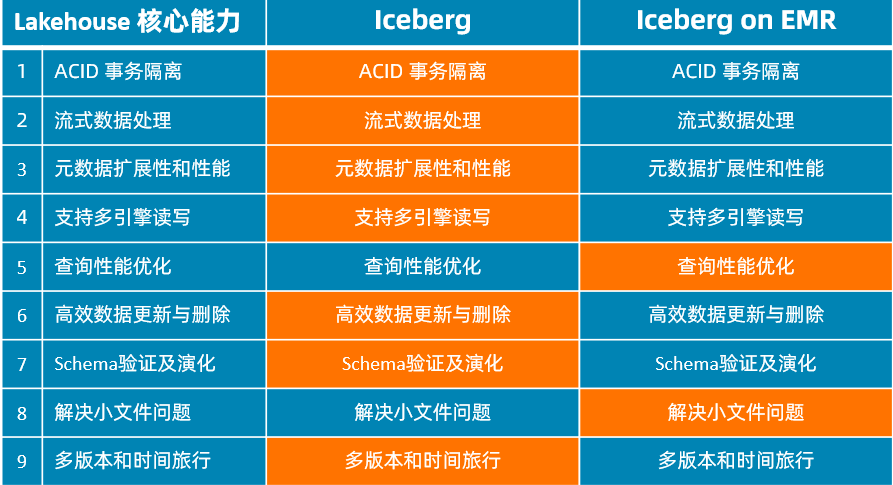
Iceberg
关键实现:基于 Snapshot 的元数据层
- Snapshot 中记录表当前版本的所有文件
- 每次写操作提交一个新的版本
- 基于 Snapshot 的读写隔离
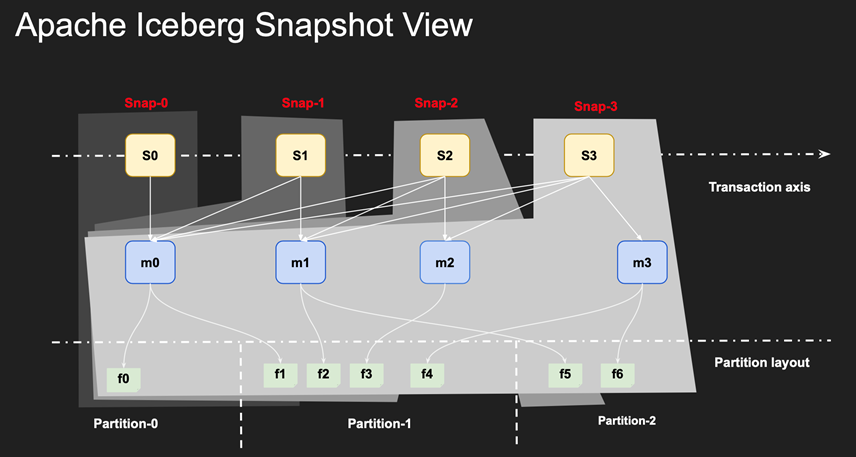
基于snapshot差异做增量数据消费
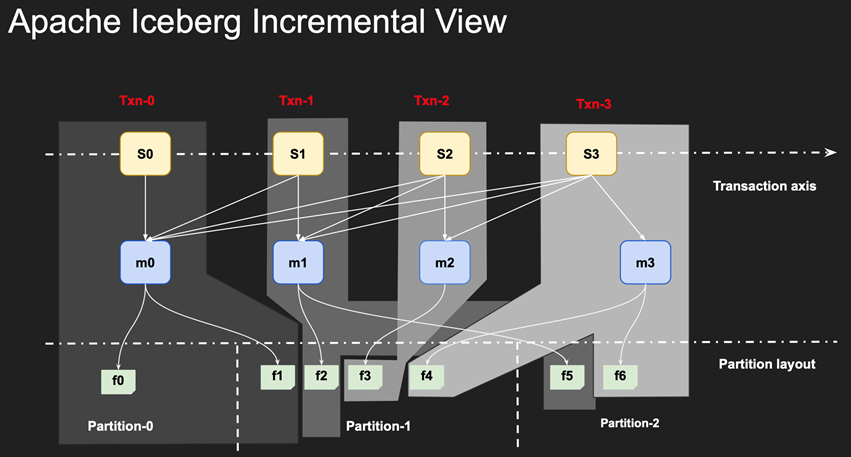
Iceberg on EMR
阿里云在 Iceberg 上做的贡献:
Optimize
- 结合 JindoFS 提供缓存加速
- 自动小文件合并事务
阿里云云生态对接
- 原生接入 OSS 对象存储
- 原生接入 DLF 元数据
开源社区投入
- 1位 IcebergPMC,1位 Iceberg Committer
- 贡献和维护 Iceberg 与 Flink 的集成模块
- 主导并设计社区的 MOR 流式 upsert 功能
中文社区运营
- 维护国内最大的 Apache Iceberg 数据湖技术社区(成员1250+)。
- 国内最活跃的 Apache Iceberg 布道师之一:
- 组织举办 Apache Iceberg 深圳站、Apache Iceberg 上海站
选型参考
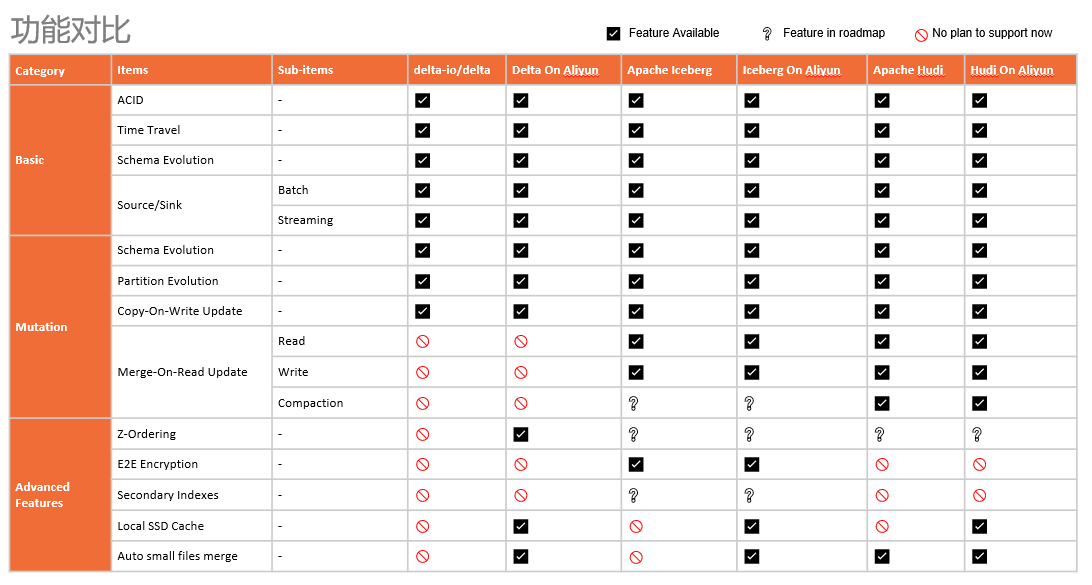
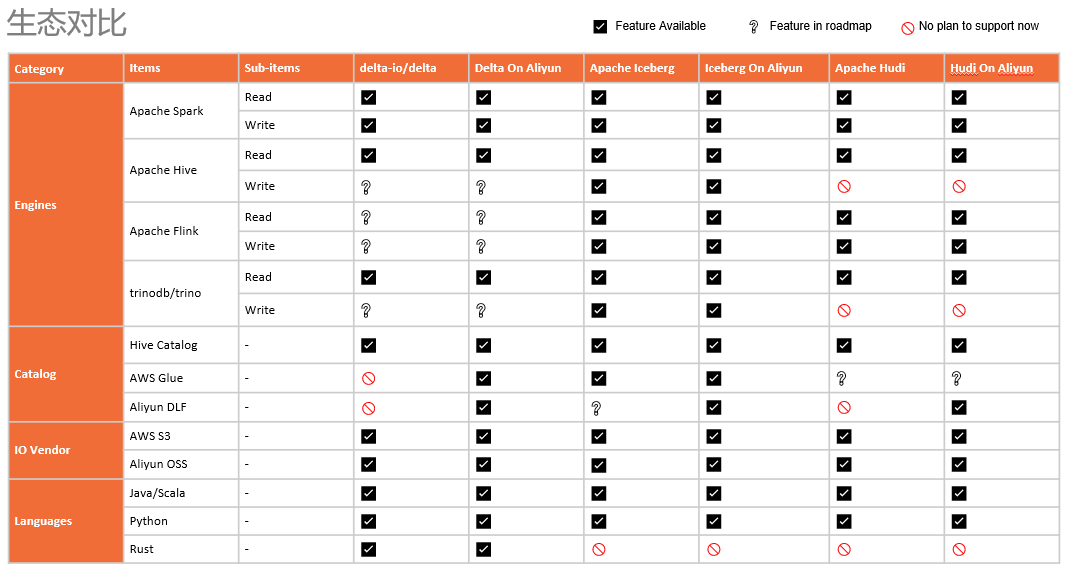
云上 Lakehouse 架构与实践
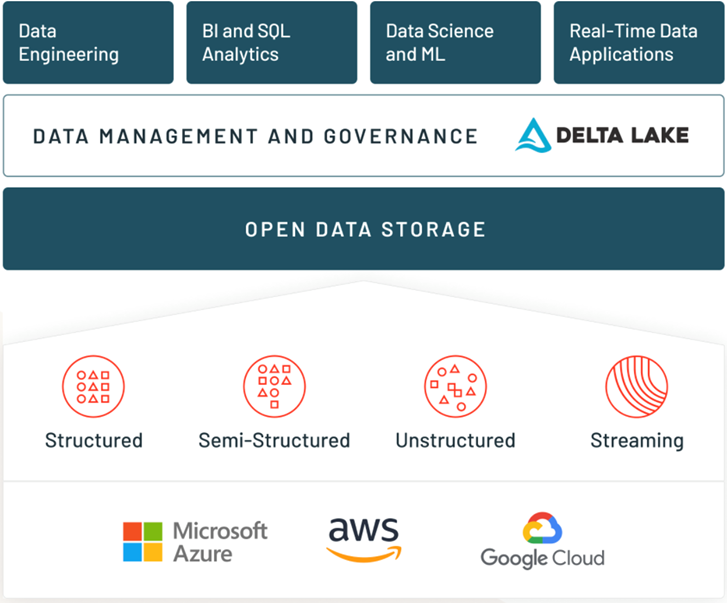
Databricks 在推出 Lakehouse 的概念后,就把公司的介绍改成了 The Databricks Lakehouse Platform。如下方的架构图所示,底层是云的基础设施(其中阿里云跟 Databricks 也有合作推出 Databricks 数据洞察);数据入湖之后,在开放的数据存储之上,是结合了 Delta Lake 数据湖格式的较为重点的数据管理和治理层(Data Management and Governance)。
数据湖构建、管理、与分析过程
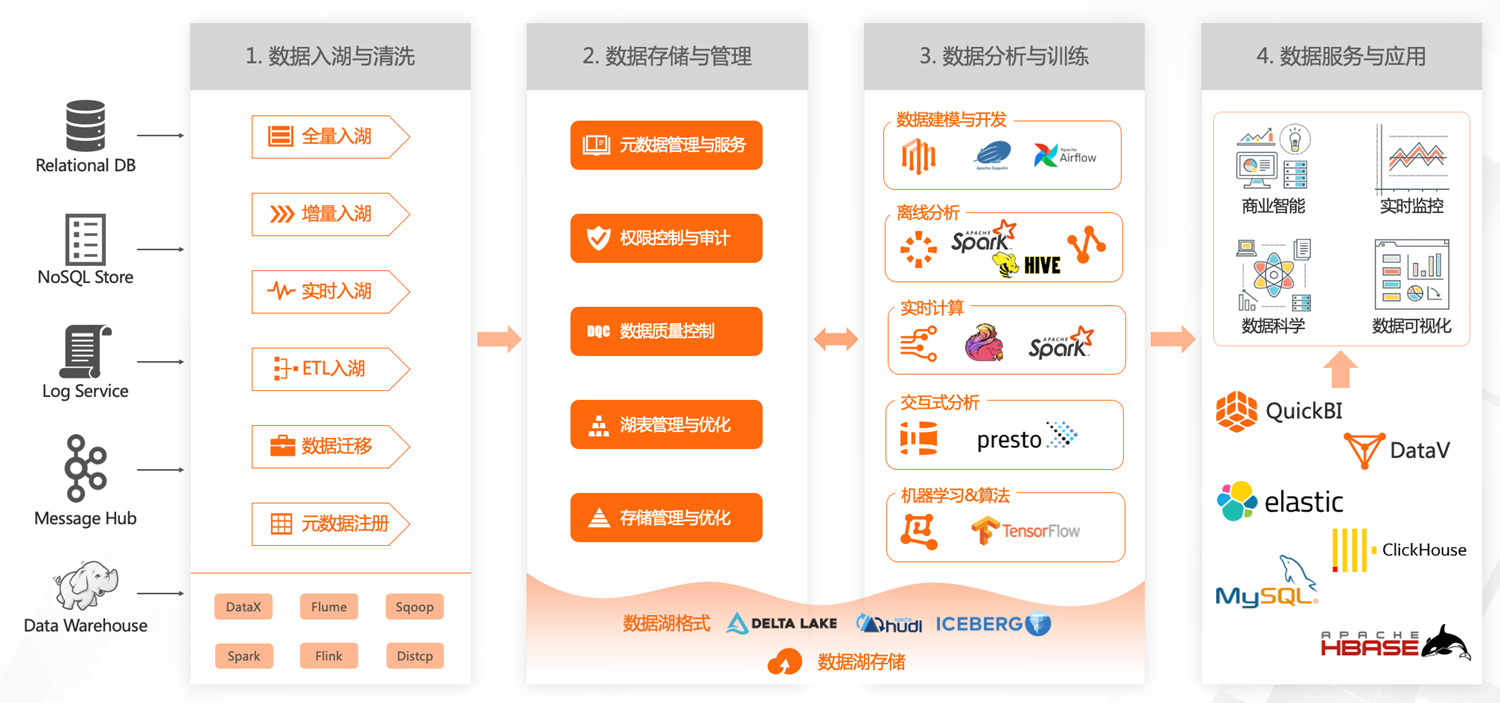
- 数据入湖与清洗
来自各个数据源的数据,以全量、增量、实时、ETL、数据迁移、元数据注册等方式入湖并清洗
- 数据存储与管理
- 元数据管理与服务
- 权限控制与审计
- 数据质量控制
- 湖表管理与优化
- 存储管理与优化
- 数据分析与训练
覆盖数据建模与开发、离线分析、实时计算、交互式分析、机器学习和算法等场景
- 数据服务与应用
- 将训练分析后的数据同步到需求对应产品进行深度分析或进一步处理
- 直接对接商业智能、实时监控、数据科学、数据可视化等数据应用
阿里云 Lakehouse 架构
- 数据层(数据湖核心能力)
- 计算层(弹性计算引擎)
- 平台层(数据开发与治理)

DLF 统一元数据服务与治理
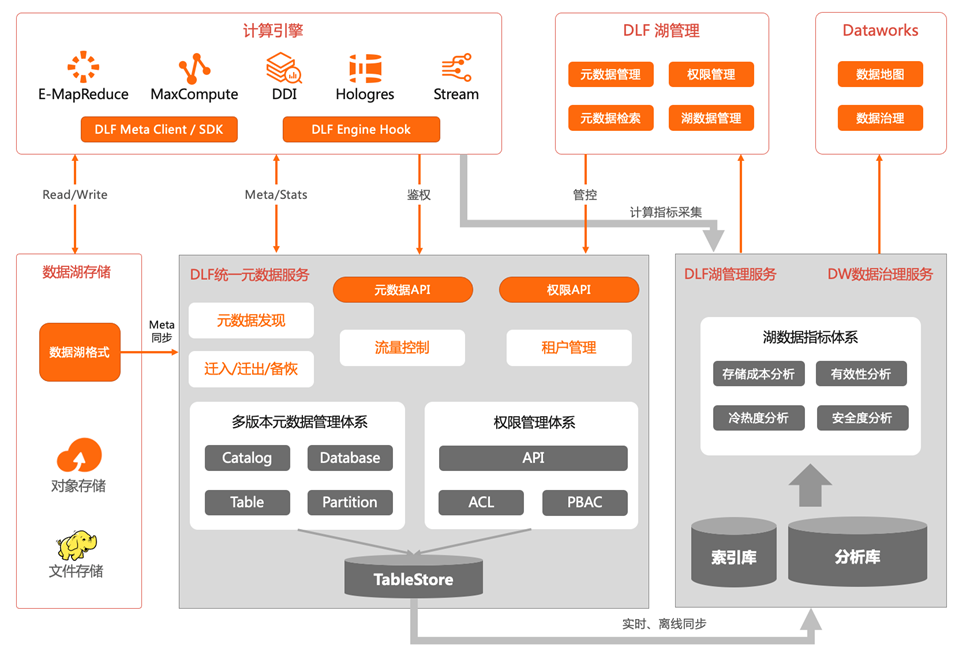
- 统一元数据与统一权限
- 完全兼容 HMS 协议,支持多引擎访问
- 多引擎统一权限控制
- 利用云上 KV 存储提供高扩展性、高性能服务
- 支持 Delta lake/Hudi/Iceberg 元数据同步,统一视图
- 以 Delta lake 支持多引擎访问为例
- 多形态Spark:DLF 数据探索、Databrick Spark、Maxcompute Serverles Spark
- 实时计算:Flink(对接中)
- EMR 交互式分析:Trino、Impala
- EMR Hive :阿里云贡献给社区的Delta Connector,完全开源
- 湖元数据治理
- 基于历史数据的元数据分析和管理
- 成本分析与优化、冷热分析与性能优化
CDC 入湖产品化

- 多种数据源0代码构建数据流
- 模板+配置 => Spark任务
- 入湖工厂,自动生成Spark SQL / Dataframe Code
- 多种数据源 CDC 入湖,自动同步元数据
以 Hudi 为例
- Mysql、Kafka、Log Service、 TableStore 等实时写入 Hudi 数据湖
- 结合 Flink CDC,支持全托管和半托管Flink实时写入 Hudi 数据湖并同步元数据到 DLF,供其他引擎进一步分析。
- Hudi社区贡献
- 阿里云贡献 Spark SQL 和 Flink SQL 读写 Hudi
- 实现 MERGER INTO 等 CDC 常用算子
数据湖治理
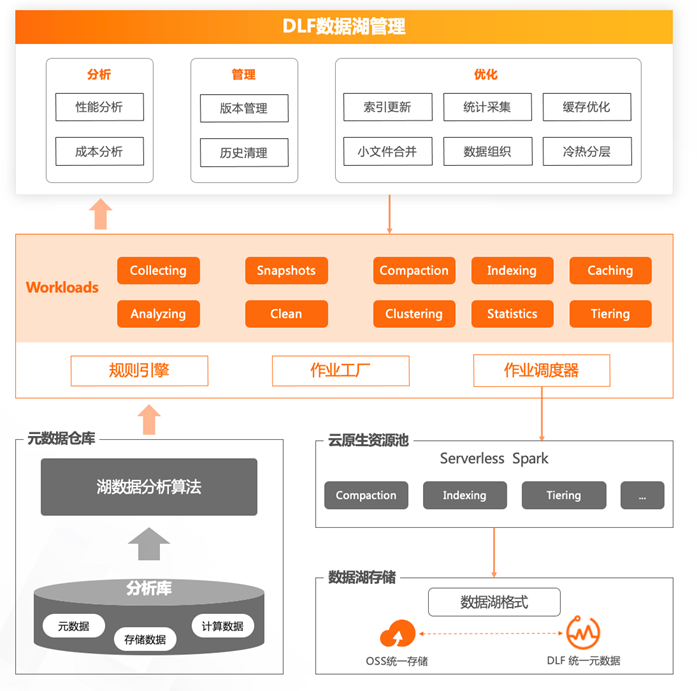
- 基于平台提供自动化的治理服务
以 Iceberg 为例
- Compact / Merge / Optmize
- Expire-snapshot / Vacuum
- Caching(基于JindoFS)
- 自动数据冷热分析及分层归档
- Serverless Spark提供低成本托管资源池务
案例分享及未来展望
案例分享1:全托管数据湖方案
大数据平台架构:
在上云之前,客户的大数据部署在 IDC 机房,基于 CDH 自建的 Hadoop 集群。因为自建 IDC 机房安全性和稳定性没有保障,容灾能力差。客户决定将大数据平台迁移上云。
案例详细介绍:百草味基于“ EMR+Databricks+DLF ”构建云上数据湖的最佳实践-阿里云开发者社区
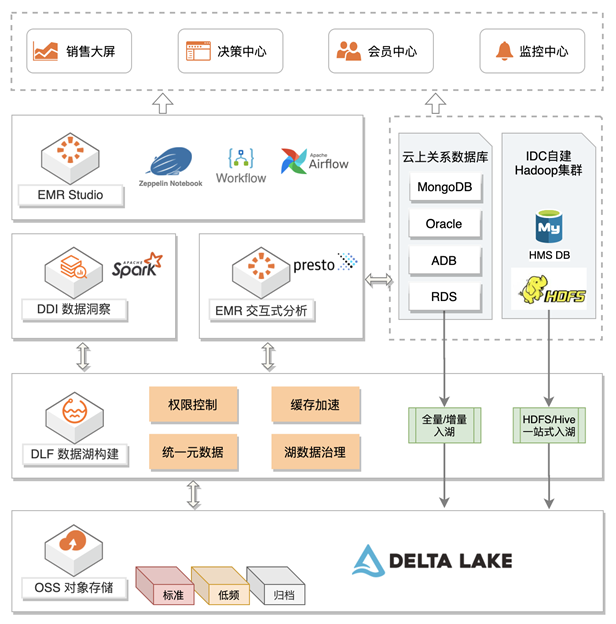
全托管数据湖方案:
以 RDS 关系型数据库为例
数据可以通过 Spark 进行 ETL 后入湖,或者通过在 DLF 上托管的 CDC 增量入湖/ Batch 全量入湖导入到对象存储 OSS中,在统一的元数据管理之下:
- 基于 Spark Streaming 做实时分析,进行实时报表/监控的展现
- 通过阿里云上 Databricks 数据洞察进行 ETL 任务,进行数据建模和进一步处理
- 拉起 EMR Presto 集群,以满足交互式分析场景
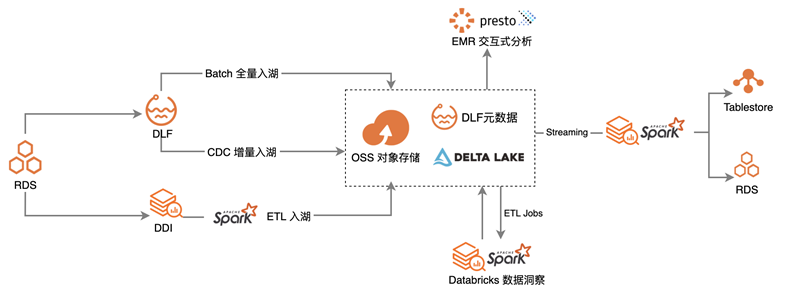
- 批流一体,链路简单清晰
- Delta lake + Spark 实现实时计算和离线分析
- 全托管服务,免运维
- OSS存储托管
- DLF元数据和入湖任务托管
- DDI Spark引擎托管
- 数据开放
- 快速接入Presto做交互式分析
在这套方案中,除了半托管的 EMR Presto,其余组件都是全托管的。无论是底层存储,还是元数据或者 Spark 引擎的管理,无需用户自行管理,也不需要进行组件的维护和升级。提升使用体验的同时,大大降低了运维成本。
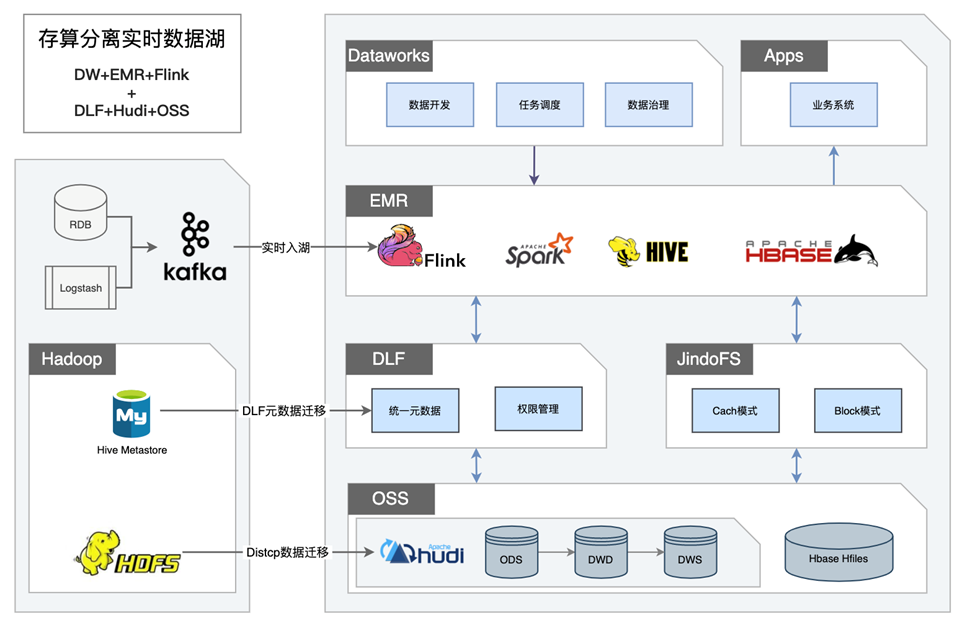
案例分享2:存算分离实时数据湖
这是一个存算分离的实时数据湖案例。用户本来使用的是存算一体架构,Hive 元数据信息存储在 Hive MetaStore,数据存储在 HDFS 中,经常会出现坏盘的情况,给运维带来麻烦的同时增加了成本。另一方面 Hive Metastore 在数据量到达一定程度后,比如 Partition 分区数到了10万级别后,性能上会受到很大挑战。所以用户决定进行存算一体到存算分离架构的迁移。
- 存算一体—> 存算分离
- HDfs运维困难 -> OSS免运维
- HDFS云盘成本高 -> OSS成本低
- HMS扩展性差 -> DLF元数据扩展性高
- Flink实时入湖,Spark/Hive分析
- Flink -> Hudi高效实时写入能力
- DLF元数据天然打通Spark/Hive
- Hbase服务和数据分离
Lakehouse 未来展望
- 湖格式能力会不断增强,接近数仓/数据库的能力
- 多表事务(AWS Governed Table)
- Optimize 功能越来越丰富(Caching,Clustering,Z-Ording。。。)
- 三种湖格式能力不断追平
- 湖格式与存储/计算集成度越来越高,以获得更高的性能
- 存储层会出现面向湖格式的定制 API
- 为计算层提供更多面向性能优化的方案(二级索引,Column statistics)
- 湖管理平台能力越来越丰富和智能化
- 统一元数据服务成为标配,Meta 托管化、服务化(Hudi Timeline Server)
- 治理和优化成为平台基础能力,并对用户不可见
综上,无论是从 Lakehouse 的特性来看,或是从各个厂商在 Lakehouse、在湖格式上的探索及建设来看,Lakehouse 很可能成为新一代大数据架构。
原文链接
本文为阿里云原创内容,未经允许不得转载。
Lakehouse 架构解析与云上实践的更多相关文章
- ShardingSphere 云上实践:开箱即用的 ShardingSphere-Proxy 集群
本次 Apache ShardingSphere 5.1.2 版本更新为大家带来了三大全新功能,其中之一即为使用 ShardingSphere-Proxy chart 在云环境中快速部署一套 Shar ...
- Storm实战:在云上搭建大规模实时数据流处理系统(Storm+Kafka)
在大数据时代,数据规模变得越来越大.由于数据的增长速度和非结构化的特性,常用的软硬件工具已无法在用户可容忍的时间内对数据进行采集.管理和处理.本文主要介绍如何在阿里云上使用Kafka和Storm搭建大 ...
- 传统业务上云:跨AZ容灾架构解析
本文由 网易云发布. 数字化转型浪潮之下,采用云计算服务提升业务敏捷性.降低运维成本,成为了传统企业的优选方案.网易云资深解决方案架构师张亮通过某物流企业客户的实际案例,分享了传统业务系统在云上的架 ...
- 一面数据: Hadoop 迁移云上架构设计与实践
背景 一面数据创立于 2014 年,是一家领先的数据智能解决方案提供商,通过解读来自电商平台和社交媒体渠道的海量数据,提供实时.全面的数据洞察.长期服务全球快消巨头(宝洁.联合利华.玛氏等),获得行业 ...
- 阿里云基于OSS的云上统一数据保护方案2.0技术解析
近年来,随着越来越多的企业从传统经济向数字经济转型,云已经渐渐成为数据经济IT新常态.核心业务系统上云,云上的业务创新,这些都产生了大量的业务数据,这些数据也成为了企业最重要的资产.资源. 阿里云基于 ...
- 基于消息队列 RocketMQ 的大型分布式应用上云最佳实践
作者|绍舒 审核&校对:岁月.佳佳 编辑&排版:雯燕 前言 消息队列是分布式互联网架构的重要基础设施,在以下场景都有着重要的应用: 应用解耦 削峰填谷 异步通知 分布式事务 大数据处理 ...
- Atitit 文件上传 架构设计 实现机制 解决方案 实践java php c#.net js javascript c++ python
Atitit 文件上传 架构设计 实现机制 解决方案 实践java php c#.net js javascript c++ python 1. 上传的几点要求2 1.1. 本地预览2 1.2 ...
- 在阿里云上搭建nginx + ThinkPHP 的实践
作为一个程序猿,理应用linux系统来作为平时的工作机环境,哎,之前倒是用过一段时间的linux,可惜后来换了本本,后来竟然没有保持,嗷嗷后悔中... 废话不多说,大家用windows的理由都一样,但 ...
- 特斯拉Tesla Model 3整体架构解析(上)
特斯拉Tesla Model 3整体架构解析(上) 一辆特斯拉 Model 3型车在硬件改造后解体 Sensors for ADAS applications 特斯拉 Model 3型设计的传感器组件 ...
- 峰值利用率80%+,视频云离线转码自研上云TKE实践
作者 刘兆瑞,腾讯云高级研发工程师,负责腾讯明眸极速高清,画质重生等产品.专注于codec优化,画质增强等技术. 背景和问题 随着流量资费的降低和带宽的增加,视频成为人们获取信息越来越重要的方式,随之 ...
随机推荐
- 智慧公安!3DCAT实时云渲染助力某公安机关打造数字孪生可视化系统
近年来,随着大数据.数字孪生.云计算.人工智能等技术的飞速发展,数字化浪潮席卷全国各地公安系统.2022年全国公安工作会议中也提到,数字化改革是推动公安工作创新发展的大引擎.培育战斗力生成新的增长点. ...
- 【实时渲染】3DCAT实时渲染云助力游戏上云!
随着社会的发展技术的提升,云计算技术得到越来越多人的重视.同时随着5G的落地,游戏产业也迎来了新的革命.一些游戏厂商为了寻求新的发展机会,推出基于云计算的游戏"云游戏",将游戏平台 ...
- Android端Charles抓包
目录介绍 01.下载安装 02.抓包代理设置 03.抓包Https操作 04.抓包原理介绍 05.抓包数据介绍 06.常见问题总结 07.Android拦截抓包 01.下载安装 下载地址(下载对应的平 ...
- AntSK 0.2.3 版本更新:轻松集成 AI 本地离线模型
大家好,今天和大家分享 AntSK 知识库/智能体项目的最新进展. AntSK 是一个基于 .Net 8.Blazor 及 SemanticKernel 开发的 AI 项目,旨在为开发者提供一个强大的 ...
- rnacos版本更新为 v0.1.5
rnacos是一个用 rust重新实现的nacos. rnacos比java实现的nacos更轻量.快速.稳定:合适在开发.测试.受资限服务等环境平替nacos服务使用. rnacos v0.1.5 ...
- AABO:自适应Anchor设置优化,性能榨取的最后一步 | ECCV 2020 Spotlight
论文提出超参数优化方法AABO,该方法核心基于贝叶斯优化和Sub-Sample方法,能够自适应的搜索最优的anchor设置.从实验结果来看,AABO能够仅通过anchor设置优化,为SOTA目标检测方 ...
- KingbaseES 扩展插件src_restrict 介绍
插件简介 src_restrict是KingbaseES的一个扩展插件,主要用于支持来源限制功能,该功能通过黑白名单来实现.插件src_restrict默认已经加载. 查看插件是否加载 show sh ...
- python爬虫爬取科技报告数据,共计40余万条(来自国家科技报告服务系统)
按学科分类[中图分类] 共计三十余万条科技报告数据 爬取的网址:https://www.nstrs.cn/kjbg/navigation !!! 如果要完整地跑起来代码,需要先看一下我的这篇博客,完成 ...
- kafka主题、消费者、生产者命令行操作
十二.Kafka (1)Topic 1)查看当前服务器中的所有topic bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list 2) ...
- ssh登录太慢了,每次都要20s
背景 大家工作时,少不了ssh登录各个服务器,我这边手里也有很多服务器,有一些登录很快就进去了,有些要卡半天才能进去.之前以为是公司网络问题,每次也就忍了,这次突然不想忍了,决定定位一下. 我这边的服 ...