java集合源码详解
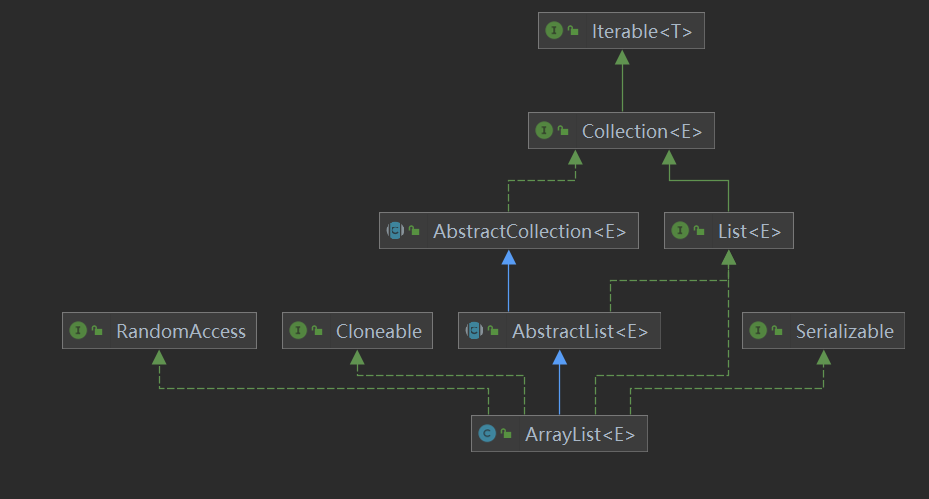
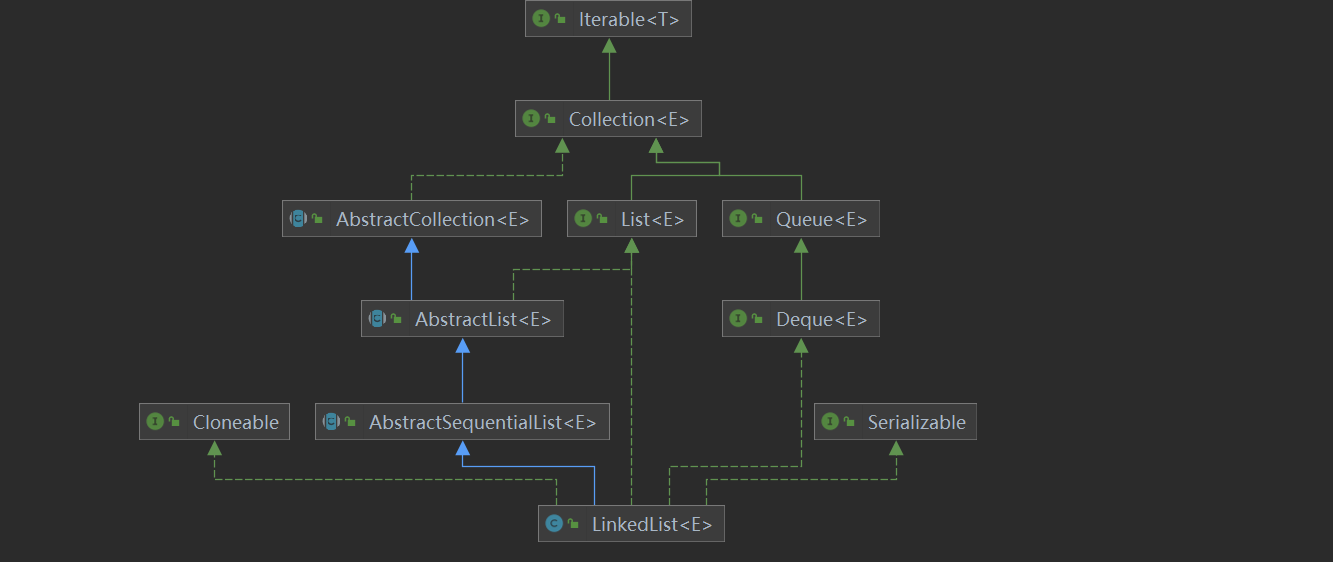
一 Collection接口
1.List
1.1ArrayList
特点
1.底层实现基于动态数组,数组特点根据下表查找元素速度所以查找速度较快.继承自接口 Collection ->List->ArrayList
2.扩充机制 初始化时数组是空数组,调用add()第一次存放元素时长度默认为10,满了扩容机制 原来数组 + 原来数组的一半 使用数组copy()方法
2.1 构造一个初始容量为空列表。(不给指定大小时为空)

2.2使用add()方法,将指定的元素追加到列表的末尾。集合的长度 size ++ 先使用后自增1

2.3 将数组长度设置为10
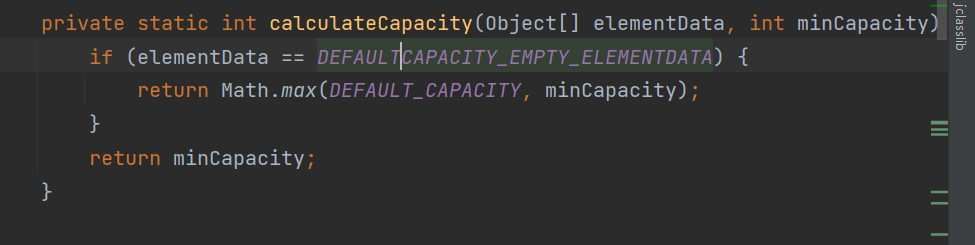
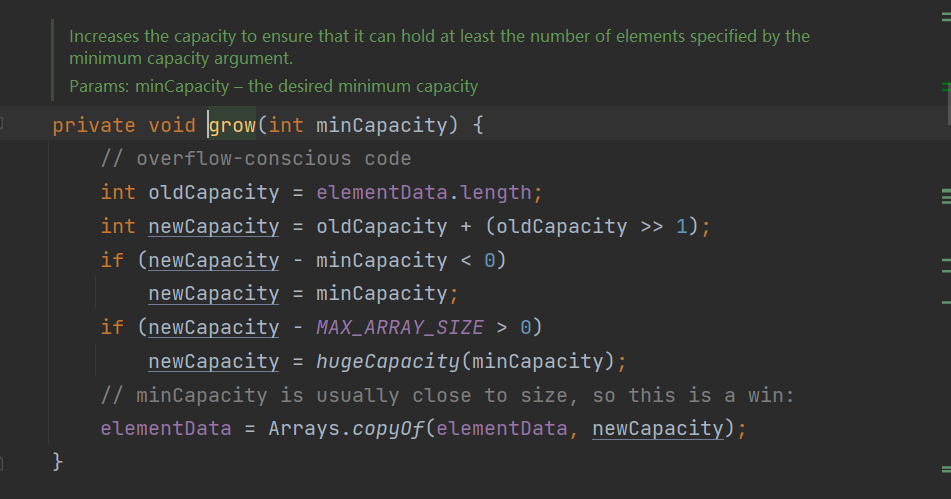
2.4判断长度是否大于当前数组 调用grow()方法扩容

2.5 newCapacity = oldCapacity + (oldCapacity >> 1); oldCapacity >> 1其实就是oldCapacity 除以2,返回一个copyOf的数组
3.线程不安全 ,效率高
1.2vector
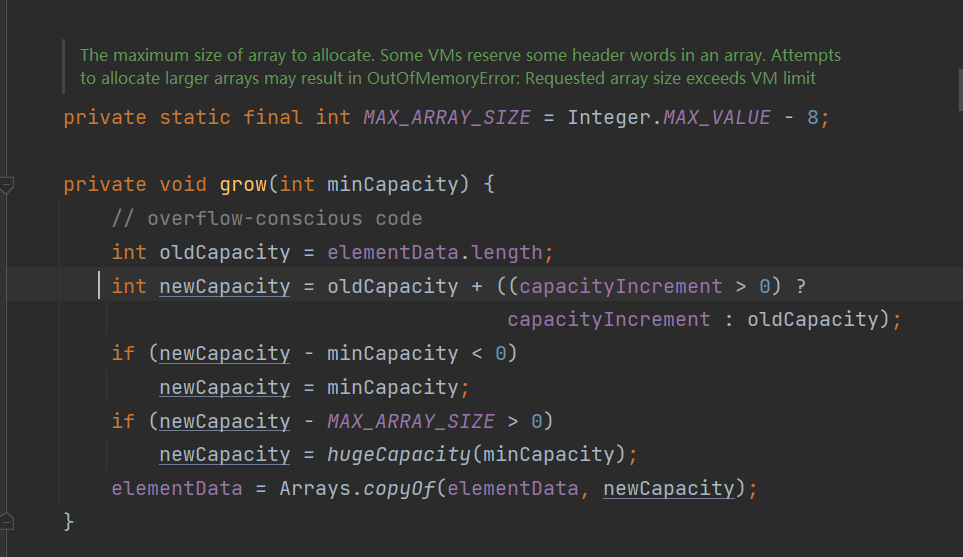
1.采用动态数组,初始化时默认长度10

2.由于是默认初始化 没有给定capacityIncrement 所以为 0 所以新数组长度为 oldCapacity + oldCapacity 也就是增长为原来2倍,如果给定增长值capacityIncrement
后,扩充为:原来大小+增量也就是newCapacity= oldCapacity + capacityIncrement
1.3LinkedList
1.适合插入,删除操作,性能高
2.有序的元素,元素可以重复
3.原理
3.1插入时只需让88元素记住前后俩元素, 删除88元素只需让88前面元素(6)记住该元素后面(35)元素 时间复杂度 O(1)< O(logn)< O(n)< O(n^2)

3.2对于某一元素,如何找到它的下一个元素的存放位置呢?对每个数据元素ai,除了存储其本身的信息之外,
还需存储一个指示其直接后继存放位置的指针。在每个结点中再设一个指向前驱的指针域

prior 前面节点指针域 next后一个节点指针域


(图片来源<<数据结构 java语言描述>>)
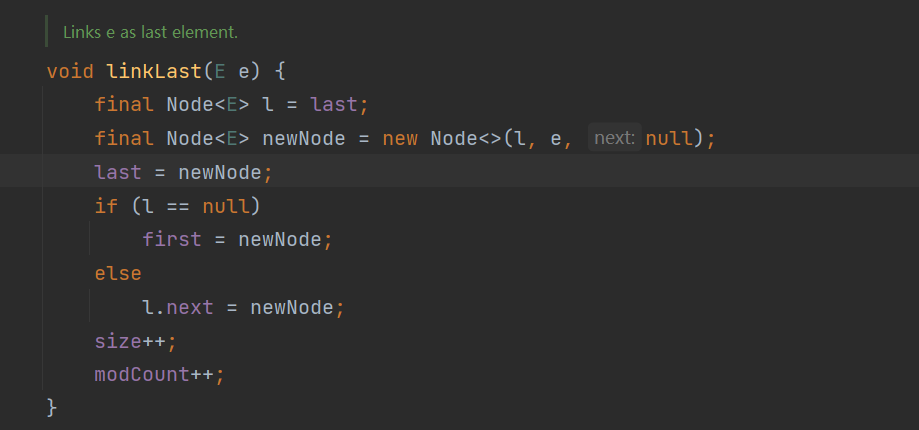
3.3 add() 时在尾部追加元素 ...等等
2 set接口
2.1HashSet
1.元素输出时不允许元素重复,允许元素为null (因为string 重写了hashCode,equals方法所以可以去重)
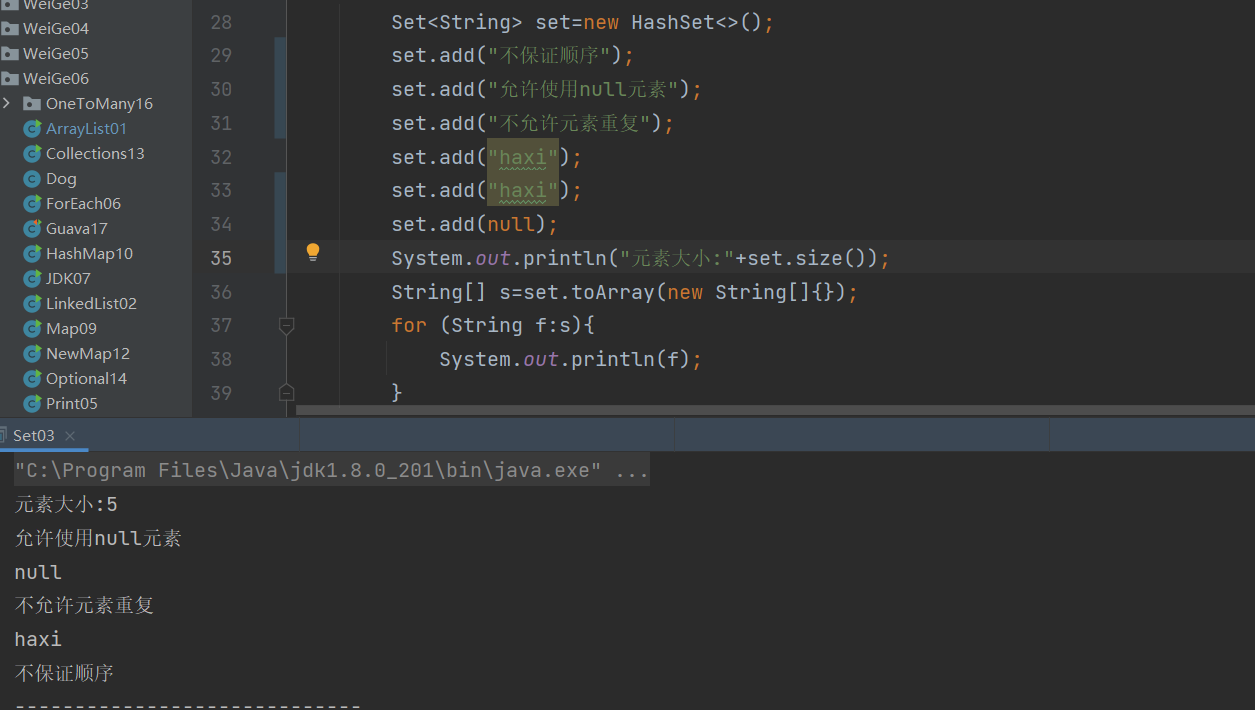
2.无序的
3.实现源码
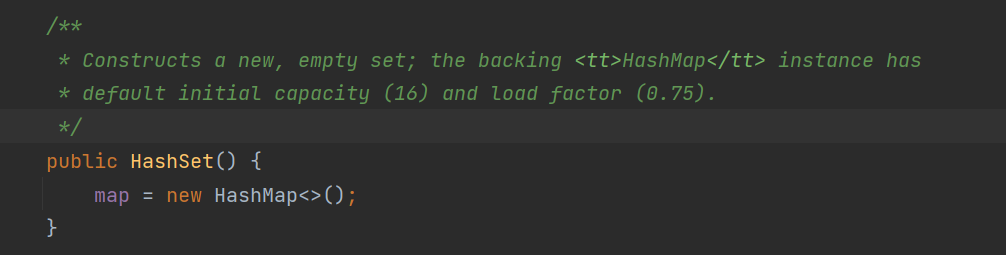
3.1 使用默认无参初始化时 其实使用的是HashMap实现的
构造一个新的空集;支持的stt>HashMaps/tt>实例具有默认的初始容量(16)和负载因子(0.75)。
3.2 向HashSet添加元素时 使用HashMap的put()方法,把值作为HashMap的key (key肯定不可以重复的,唯一的)

所以详细实现源码下面介绍HashMap时再说
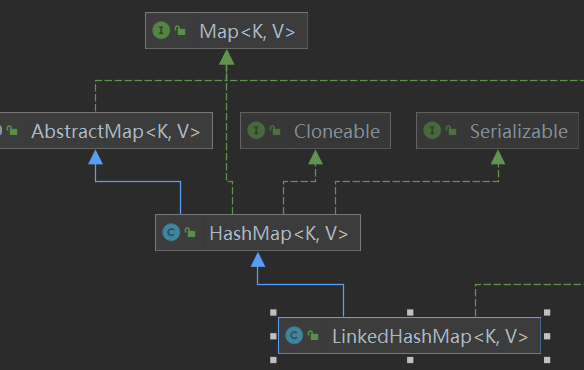
4. HashSet的子类LinkedHashSet 底层使用双向链表
4.特点 4.1.按照添加顺序输出 ; 元素不重复
4.2使用无参构造的初始化容量(16)和负载因子(0.75)构造一个新的空链接哈希集。
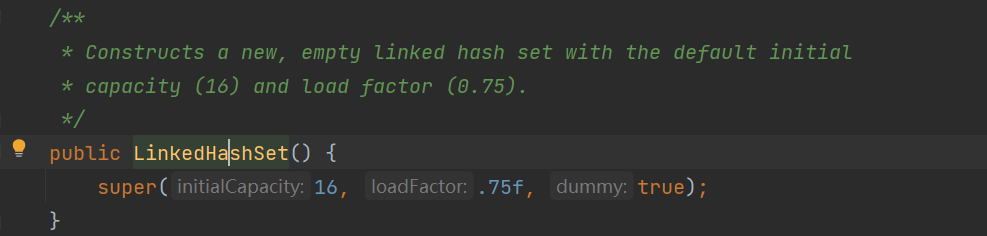
4.3调用父类HashSet 构造 初始化的对象是LinkedHashMap() 关系又跑到map上去了

4.4LinkedHashMap()调用他爹(HashMap)的构造
4.5 调用LinkedHashMap() 构造时 设置了hash顺序
accessOrder //这个链接哈希映射的迭代方法:true表示访问顺序,false表示插入顺序。

2.2TreeSet
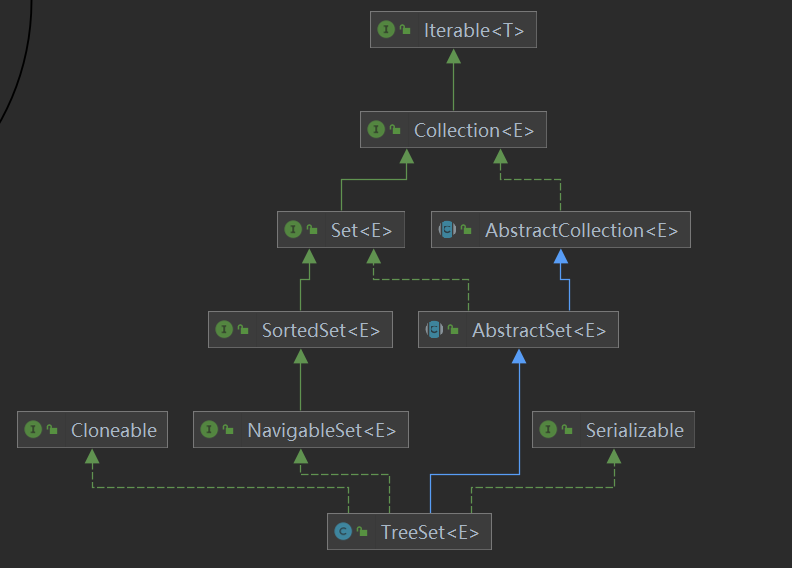
1.可以排序(元素按照自然排序进行排列 根据KEY值排序)且不允许元素重复
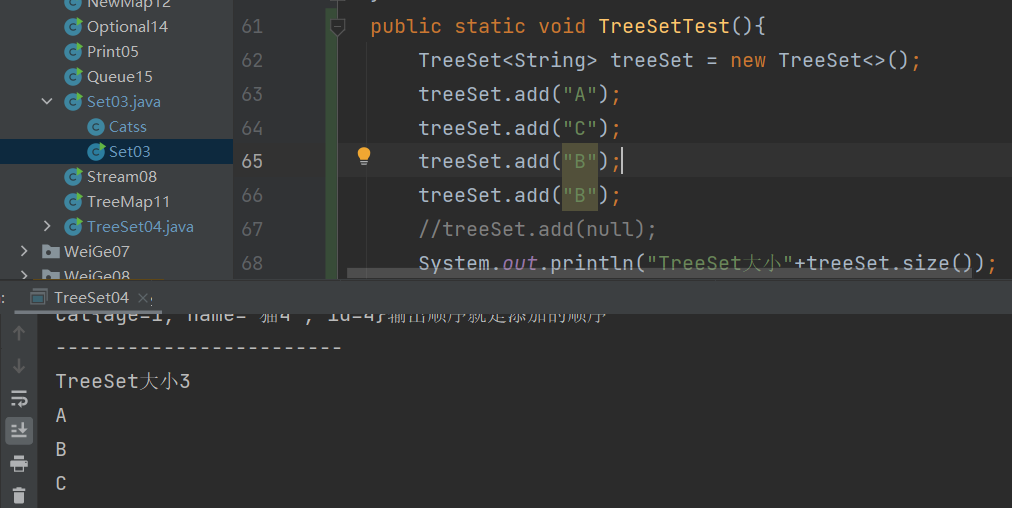
为什么会自动排序呢?
1.1 默认无参构造时 初始化的是一个TreeMap对象

2.2 调用add()方法时调用的是Map接口提供的put()方法 而treeMap 实现了map接口的put(); 所以底层存储就是treeMap 红黑树
方法 源码如下


public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
2.不允许元素为null

3.排序想按照对象的某个值排序,某个类实现接口 Comparator 重写 compare()方法
private static void treeSet(){ //TreeSet
Catss cat1=new Catss(2,"猫1",1);
Catss cat2=new Catss(1,"猫2",2);
Catss cat3=new Catss(3,"猫3",3);
Catss cat4=new Catss(1,"猫4",4);
Catss cat5=new Catss(1,"猫4",4);
//TreeSet存储数据要使用比较器
TreeSet<Catss> t=new TreeSet<>(new CatComparator());
t.add(cat1);
t.add(cat2);
t.add(cat3);
t.add(cat4);
t.add(cat5);
for (Object f:t){
System.out.println(f+"输出顺序是按照年龄排序递增(年龄有一样的将会覆盖一个,只输出一个)");//输出顺序是按照年龄排序递增(年龄有一样的将会覆盖一个,只输出一个)
}
}
class CatComparator implements Comparator<Catss> {
@Override
public int compare(Catss o1, Catss o2) {
return o1.getAge()-o2.getAge();//根据年龄排序
}
}
二 Map接口
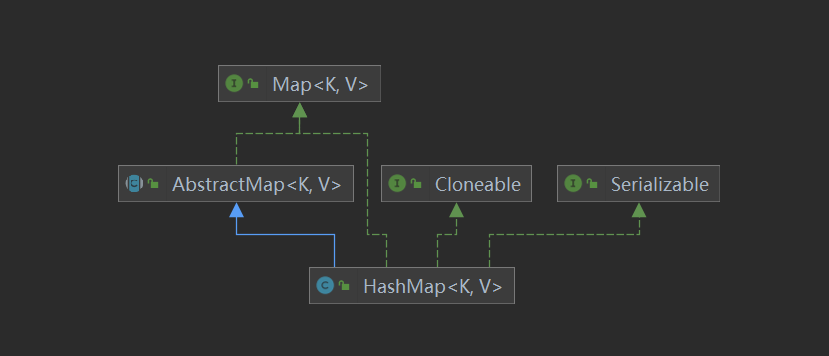
2.1 HashMap
特点:
1.无序的键值对存储一组对象
2.key必须保证唯一,Value可以重复
3.key 和value可以为null
4.线程不安全
5.默认加载因子0.75,默认数组大小16 6.实现基于哈希表 (数组+链表/红黑树)
源码:1.加载因子0.75f

2.实现map接口的put()方法 hashMap重写put
2.1为了一次存取便能得到所查记录,在记录的存储位置和它的关键字之间建立一个确定的对应关系H,
以H(key)作为关键字为key的记录在表中的位置,称这个对应关系H为哈希(Hash)函数。按这个思想建立的表为哈希表。
2.2解决Hash冲突
根据设定的哈希函数H(key)和所选中的处理冲突的方法,将一组关键字映射到一个有限的、
地址连续的地址集(区间)上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得
的查找表称之为“哈希表”,这一映射过程也称为“散列”,所以哈希表也称散列表。--<<数据结构 java语言描述>>
2.3子类LinkHashMap,按照添加顺序输出特点参考上面LinkedHashSet
put()方法的大致流程如下:
首先,将插入的键值对通过hash算法计算出对应的桶位置。
检查该桶位置上是否已经存在元素。如果该桶位置上没有元素,则直接将键值对插入到该位置上。
如果该桶位置上已经存在元素,则需要进行链表或红黑树的操作。
如果该位置上的元素个数小于8个,则将该元素添加到链表中。
如果该位置上的元素个数已经达到8个,则将链表转换为红黑树。如果该位置上的元素已经是红黑树,则直接将该键值对插入到红黑树中。
在插入键值对后,如果HashMap的大小超过了负载因子(load factor)*当前数组长度,则需要进行扩容操作。
在扩容时,会创建一个新的数组,并将原来数组中的元素重新分配到新的数组中。
扩容后,新的数组的大小为原来数组的两倍,并将阈值(threshold)也扩大为原来的两倍。
最后,将键值对插入到桶位置中,并返回null或原来桶位置上的值。
public V put(K key, V value) {
// 计算键的hash值
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// 获取当前HashMap的table数组,如果为null,则进行初始化
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算key在数组中的下标i
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果当前位置为空,则直接创建新节点
tab[i] = newNode(hash, key, value, null);
else {
// 如果当前位置不为空,判断当前节点是否为要添加的key
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
// 如果是树节点,则进行红黑树添加操作
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 如果当前位置是链表,则遍历链表,查找key是否已存在
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 如果链表中没有找到key,则创建新节点添加到链表尾部
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 如果链表长度已达到阈值,则进行链表转换为红黑树的操作
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果e不为null,则说明key已存在,将其旧值替换为新值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 在LinkedHashMap中使用,记录节点访问顺序
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 如果HashMap中键值对数量已达到阈值,则进行扩容
if (++size > threshold)
resize();
// 在LinkedHashMap中使用,记录节点插入顺序
afterNodeInsertion(evict);
return null;
}
2.2Hashtable
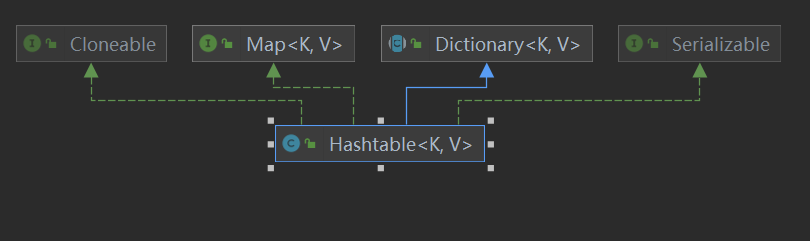
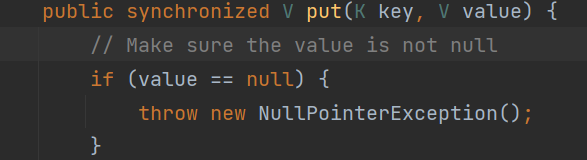
特点 1.线程安全调用put()时synchronized修饰

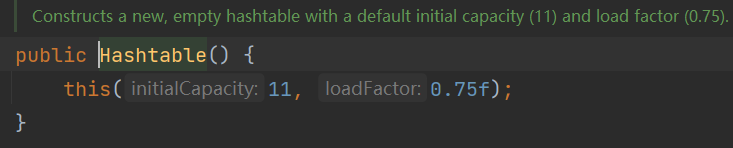
2.默认构造大小11扩充因子0.75
3.无序的,K和V 都不能为null ,允许元素重复

2.3TreeMap
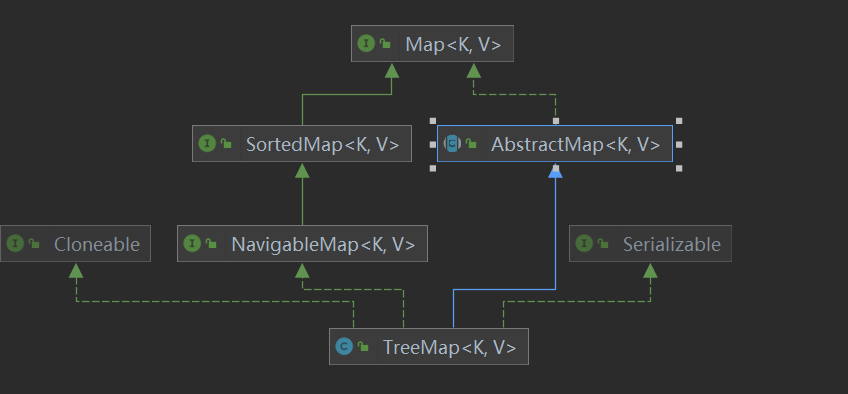
特点:1.可以排序(自然排序123),元素可以重复,K值不能重复
public static void treeMapTest(){
TreeMap<String, String> treeMap = new TreeMap<>();
treeMap.put("1","A");
treeMap.put("4","A");
treeMap.put("2","B");
treeMap.put("3","C");
treeMap.forEach((k,v)->System.out.println("K值:"+k+"----->value值:"+v));
}
//K值:1----->value值:A
//K值:2----->value值:B
//K值:3----->value值:C
//K值:4----->value值:A
2.排序想按照对象的某个值排序,某个类实现接口 Comparator 重写 compare()方法; 上面TreeSet 一样
补充
1.负载因子0.75
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。HashSet和HashMap、Hashtable的构造器允许指定一个负载极限,HashSet和HashMap、Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询);较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销。程序员可以根据实际情况来调整HashSet和HashMap的“负载极限”值。如果开始就知道HashSet和HashMap、Hashtable会保存很多记录,则可以在创建时就使用较大的初始化容量,如果初始化容量始终大于HashSet和HashMap、Hashtable所包含的最大记录数除以负载极限,就不会发生rehashing。使用足够大的初始化容量创建HashSet和HashMap、Hashtable时,可以更高效地增加记录,但将初始化容量设置太高可能会浪费空间,因此通常不要将初始化容量设置得太高 --<<java疯狂讲义>>
2.map集合的遍历
public class Map09 {
public static void main(String[] args){
hashMap();
}
private static void hashMap(){
Map<Integer,String> map=new HashMap<>();//Map<key,value>
map.put(1,"key必须保证唯一");
map.put(2,"无序的");
map.put(3,"put方法");
map.put(null,null);
System.out.println(map.size());
System.out.println("得到key=2的值:"+map.get(2));
//第一种遍历 lambda表达式遍历forEach();非常简便
System.out.println("---------lambda表达式遍历forEach()-----------------------");
map.forEach((i, s) -> System.out.println("key="+i+" value:"+s));
//第二种遍历 entrySet()方法
System.out.println("---------entrySet()方法使用foreach遍历-----------------------");
Set<Map.Entry<Integer,String>> entry=map.entrySet();
for (Map.Entry e:entry){
System.out.println(e.getKey()+"->"+e.getValue());
}
System.out.println("---------entrySet()方法使用Iterator遍历-----------------------");
Set entries = map.entrySet();
Iterator iterator = entries.iterator();
while(iterator.hasNext()){
Map.Entry entrys = (Map.Entry) iterator.next();
Object key = entrys.getKey();
String value = map.get(key);
System.out.println(key+" "+value+"-----");
}
System.out.println("----------keySet()方法---------------------");
//第三种 遍历键 keySet()方法
Set<Integer> key=map.keySet();
for (Integer i:key){
String va=map.get(i);
System.out.println(i+"->"+va);
}
//第四种遍历值map.values()
System.out.println("----------values()方法---------------------");
Collection<String> vs=map.values();
for (String str:vs){
System.out.println(str);
}
}
}
java集合源码详解的更多相关文章
- Java HashMap源码详解
Java数据结构-HashMap 目录 Java数据结构-HashMap 1. HashMap 1.1 HashMap介绍 1.1.1 HashMap介绍 1.1.2 HashMap继承图 1.2 H ...
- 数据结构与算法系列2 线性表 使用java实现动态数组+ArrayList源码详解
数据结构与算法系列2 线性表 使用java实现动态数组+ArrayList源码详解 对数组有不了解的可以先看看我的另一篇文章,那篇文章对数组有很多详细的解析,而本篇文章则着重讲动态数组,另一篇文章链接 ...
- Java源码详解系列(十)--全面分析mybatis的使用、源码和代码生成器(总计5篇博客)
简介 Mybatis 是一个持久层框架,它对 JDBC 进行了高级封装,使我们的代码中不会出现任何的 JDBC 代码,另外,它还通过 xml 或注解的方式将 sql 从 DAO/Repository ...
- 【Java集合】LinkedList详解前篇
[Java集合]LinkedList详解前篇 一.背景 最近在看一本<Redis深度历险>的书籍,书中第二节讲了Redis的5种数据结构,其中看到redis的list结构时,作者提到red ...
- Activiti架构分析及源码详解
目录 Activiti架构分析及源码详解 引言 一.Activiti设计解析-架构&领域模型 1.1 架构 1.2 领域模型 二.Activiti设计解析-PVM执行树 2.1 核心理念 2. ...
- 源码详解系列(七) ------ 全面讲解logback的使用和源码
什么是logback logback 用于日志记录,可以将日志输出到控制台.文件.数据库和邮件等,相比其它所有的日志系统,logback 更快并且更小,包含了许多独特并且有用的特性. logback ...
- 源码详解系列(八) ------ 全面讲解HikariCP的使用和源码
简介 HikariCP 是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,和 dr ...
- Mybatis源码详解系列(四)--你不知道的Mybatis用法和细节
简介 这是 Mybatis 系列博客的第四篇,我本来打算详细讲解 mybatis 的配置.映射器.动态 sql 等,但Mybatis官方中文文档对这部分内容的介绍已经足够详细了,有需要的可以直接参考. ...
- Shiro 登录认证源码详解
Shiro 登录认证源码详解 Apache Shiro 是一个强大且灵活的 Java 开源安全框架,拥有登录认证.授权管理.企业级会话管理和加密等功能,相比 Spring Security 来说要更加 ...
- 源码详解系列(六) ------ 全面讲解druid的使用和源码
简介 druid是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,druid还扩展 ...
随机推荐
- 【Azure 云服务】云服务(经典)迁移到云服务(外延支持)的八个问题
问题一:云服务( 经典)迁移到外延支持云服务是否需要停机? 通过平台的迁移工具(即验证.准备.提交)进行迁移没有停机时间.但是如果需要准备满足迁移条件,如删除对等互联,使用其他vnet资源则需要额外的 ...
- 【Azure 应用服务】App Service"访问控制/流量监控"四问
问题描述 一问:App Service有那些访问限制的方式 二问:访问限制中,是否可以通过域名来进行限制,而不只是IP地址 三问:App Service如何查看到访问者(客户端)的IP地址,访问时间 ...
- MySQL---面经
如果想要对 MySQL 的索引树有更深入的了解,掘金的小册子:<MySQL 是怎样运行的> MySQL 是怎样运行的 以下是常见面试题 MySQL日志 MySQL日志系统 redo_log ...
- spirmmvc框架整合手抄版示例,供基础搭建代码对照
注明所有文档和图片完整对照,辟免笔记出错,不能复习 package com.ithm.config; import com.alibaba.druid.pool.DruidDataSource; ...
- 基于RocketMQ实现分布式事务
背景 在一个微服务架构的项目中,一个业务操作可能涉及到多个服务,这些服务往往是独立部署,构成一个个独立的系统.这种分布式的系统架构往往面临着分布式事务的问题.为了保证系统数据的一致性,我们需要确保这些 ...
- 摆脱鼠标系列 vscode 向右拆分编辑器 ctrl + 右箭头
摆脱鼠标系列 vscode 向右拆分编辑器 ctrl + 右箭头 为什么 今天看见一个两栏工作的,左侧放的是目录大纲,右侧是代码内容 用快捷键 ctrl + 右箭头 快速扩展一个,关闭可以ctrl + ...
- manjaro系统的xfce桌面环境的的壁纸存放位置
/usr/share/backgrounds/xfce 添加新照片的命令是: sudo mv 目录/* /usr/share/backgrounds/xfce
- stm32L4xx串口日志配置解析
前言: st这两年推出了一款超低功耗的芯片,stm32l4xx系列,该系列芯片有着功耗低,尺寸小等特点,非常适合应用在可穿戴式设备. 团队在这一领域深耕,所以不可避免的要用到这款芯片,这里就针对该芯片 ...
- c 语言默认什么编码
C语言是没有编码的.它的编码就是平台的默认编码.比方说在windows 上汉字编码用gb2312 或者 说cp936(GBK一般的windows默认代码页,windows分为不同的代码页,可以查看一下 ...
- Android 自定义View模板代码记录
原文地址:Android 自定义View模板代码记录 - Stars-One的杂货小窝 每次写自定义View,需要重写3个构造方法,如果使用Android Studio直接创建,会导致View代码过多 ...