elasticsearch初步使用学习
通过使用elasticsearch,我们可以加快搜索时间(直接使用SQL的模糊查询搜索耗时会比较久,而且elasticsearch的响应耗时与数据量关系不大)
es主要用于存储,计算,搜索数据
依次部署elasticsearch,kibana
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
参数说明9200为访问端口,9300为集群端口
- 第一个环境表示es的最大最小内存,不能低于512
- 第二个环境表示当前是单节点模式
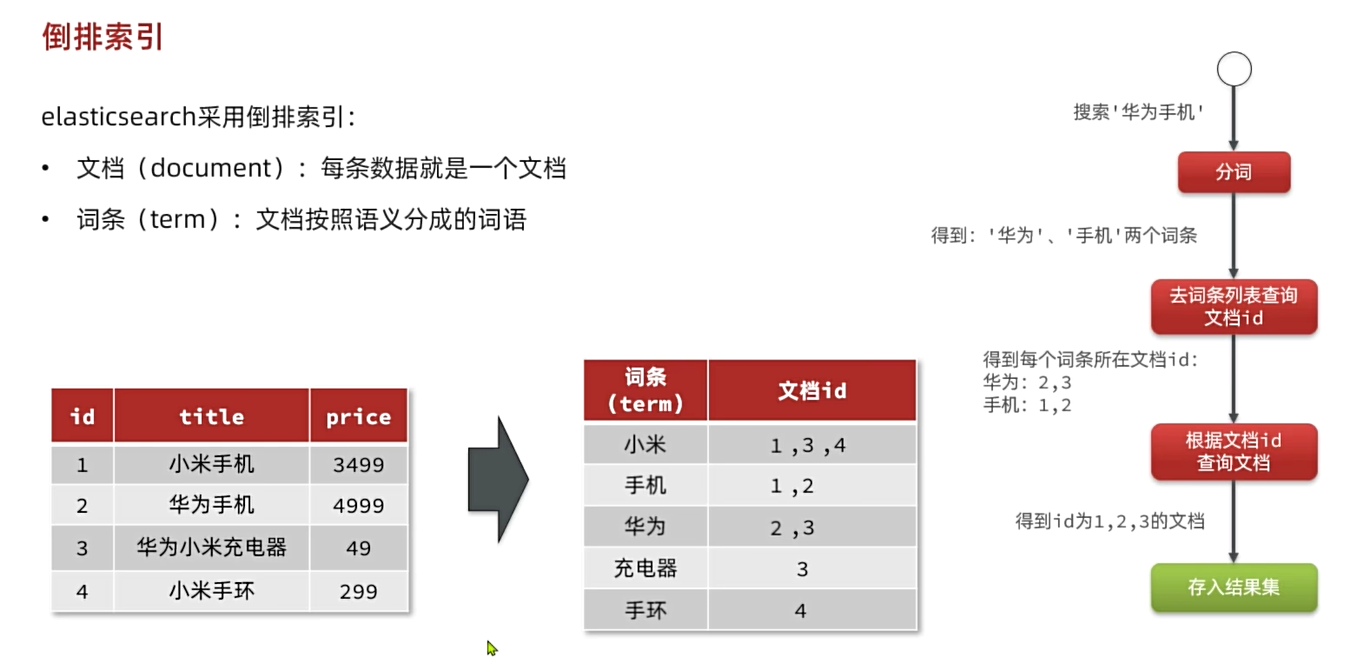
倒排索引:
文档document:每一条数据就是一个文档
词条term:文档按语义分成的词语
索引index:相同类的文档集中在一起
对文档内容分词,对词条建立索引,并记录词条所在文档的id
查询的时候根据词条查询文档id,再根据文档id查询文档
mySQL es
table index
row document
column field
schema mapping mapping是索引中文档的约束
SQL DSL DSL是es提供的json风格请求语句,实现CRUD
IK分词器:
smart智能切分,粗粒度
max_word最细切分,细粒度
POST /_analyze
{
"analyzer": "ik_max_word",// "ik_smart"
"text": "天津市长江大桥"
}
如何拓展IK分词器的词典
修改IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>
在config中新建一个ext.dic
市长
江大桥
mapping映射属性:
type:字段数据类型,
常见数据类型:
- 字符串text(这个是可以分词的)keyword(这个是精确值,不可进行分词)
- 数值:long,double,integer,float,byte,short
- 布尔boolean
- 日期date
- 对象object
index:是否创建索引,默认是true
analyzer:使用那种分词器(一般只有text需要指定这个)
properties:(该字段的子字段,一般是给object用的)
索引库操作:对应SQL中的table操作
# 创建索引库样例
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName":{
"type":"keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}
# 查询样例
GET /heima
# 删除样例
DELETE /heima
# 修改样例
PUT /heima/_mapping
{
"properties":{
"age":{
"type": "byte"
}
}
}
文档操作:对应SQL中对column的操作
# 文档操作:新增
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
} # 文档操作:查询
GET /heima/_doc/1 # 文档操作:删除
DELETE /heima/_doc/1 # 文档操作:修改 1.全量修改(先删除旧文档,再新增新文档)
PUT /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "子龙",
"lastName": "赵"
}
} # 文档操作:修改 2.局部修改
POST /heima/_update/1
{
"doc": {
"info": "黑马程序员的Java讲师"
}
}
批处理文档:注意这里不能格式化,必须写在一行上,不然就会报错而且操作失败
# 文档批处理 新增
POST /_bulk
{"index":{"_index":"heima","_id":"3"}}
{"info":"黑马程序员C++讲师","email":"ww@itcast.cn","name":{"firstName":"五","lastName":"王"}}
{"index":{"_index":"heima","_id":"4"}}
{"info":"黑马程序员前端讲师","email":"zhangsan@itcast.cn","name":{"firstName":"三","lastName":"张"}} # 文档批处理 删除
POST /_bulk
{"delete":{"_index":"heima","_id":"3"}}
{"delete":{"_index":"heima","_id":"4"}} # 文档批处理 更新
POST /_bulk
{"update":{"_index":"heima","_id":"3"}}
{"doc":{"info":"黑马程序员C艹讲师"}}
{"update":{"_index":"heima","_id":"4"}}
{"doc":{"info":"黑马程序员非后端讲师"}}
elasticsearch初步使用学习的更多相关文章
- Elasticsearch初步使用(安装、Head配置、分词器配置)
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 1.ElasticSearch简单说明 a.ElasticSearch是一个基于Lu ...
- SimMechanics/Second Generation倒立摆模型建立及初步仿真学习
笔者最近捣鼓Simulink,发现MATLAB的仿真模块真的十分强大,以前只是在命令窗口敲点代码,直到不小心敲入simulink,就一发不可收拾.话说simulink的模块化建模确实方便,只要拖拽框框 ...
- ElasticSearch权威指南学习(索引管理)
创建索引 当我们需要确保索引被创建在适当数量的分片上,在索引数据之前设置好分析器和类型映射. 手动创建索引,在请求中加入所有设置和类型映射,如下所示: PUT /my_index { "se ...
- 搜索引擎Elasticsearch REST API学习
Elasticsearch为开发者提供了一套基于Http协议的Restful接口,只需要构造rest请求并解析请求返回的json即可实现访问Elasticsearch服务器.Elasticsearch ...
- ElasticSearch基础入门学习笔记
前言 本笔记的内容主要是在从0开始学习ElasticSearch中,按照官方文档以及自己的一些测试的过程. 安装 由于是初学者,按照官方文档安装即可.前面ELK入门使用主要就是讲述了安装过程,这里不再 ...
- Python 0(安装及初步使用+学习资源推荐)
不足之处,还请见谅,请指出不足.本人发布过的文章,会不断更改,力求减少错误信息. Python安装请借鉴网址https://www.runoob.com/python/python-install.h ...
- Elasticsearch的配置学习笔记
文/朱季谦 Elasticsearch是一个基于Lucene的搜索服务器.它提供一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,Elasticsearch是用Java语言开发的. ...
- Elasticsearch基础知识学习
概要 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Ap ...
- 初步了解学习flask轻量级框架,
关于flask我有话说 flask作为一个轻量级框架,它里面有好多扩展包需要下载,比较麻烦,而且有的时候flask需要在虚拟环境下运行,但是他的优点还是有滴 ,只要是用过Django的人,都会觉得fl ...
- ElasticSearch权威指南学习(分布式搜索)
查询阶段 在初始化查询阶段(query phase),查询被向索引中的每个分片副本(原本或副本)广播. 每个分片在本地执行搜索并且建立了匹配document的优先队列(priority queue). ...
随机推荐
- 记一次 .NET某质量检测中心系统 崩溃分析
一:背景 1. 讲故事 这些天有点意思,遇到的几个程序故障都是和Windows操作系统或者第三方组件有关系,真的有点无语,今天就带给大家一例 IIS 相关的与大家分享,这是一家国企的.NET程序,出现 ...
- 算法学习笔记(10): BSGS算法及其扩展算法
BSGS算法及其扩展算法 BSGS算法 所谓 Baby Step, Giant Step 算法,也就是暴力算法的优化 用于求出已知 \(a, b, p\), 且 \(p\) 为质数 时 \(a^x \ ...
- 程序员面试金典-面试题 16.20. T9键盘
题目: 在老式手机上,用户通过数字键盘输入,手机将提供与这些数字相匹配的单词列表.每个数字映射到0至4个字母.给定一个数字序列,实现一个算法来返回匹配单词的列表.你会得到一张含有有效单词的列表.映射如 ...
- kettle从入门到精通 第六十课 ETL之kettle for循环处理每条数据,so easy!
1.kettle原生是支持for循环处理的,无需通过javascript脚本或者java脚本开发for循环控制.当然如果想通过脚本挑战下也是可以的. 本节课主要讲解如何通过kettle中的job来实现 ...
- kettle从入门到精通 第二十七课 邮件发送
1.我们平常在做数据同步的时候,担心转换或者job没有正常运行,需要加上监控机制,这个时候就会用到邮件功能. 下图是一个简单的测试邮件发送功能的转换.在kettle.properties文件中设置邮件 ...
- 安装sql 2012 时遇到“需要更新的以前的 Visual Studio 2010 实例。”规则失败。
"需要更新的以前的 Visual Studio 2010 实例."规则失败.此计算机安装了需要 Service Pack 1 更新的 Visual Studio 2010,必须安装 ...
- 算法金 | 一文彻底理解机器学习 ROC-AUC 指标
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 在机器学习和数据科学的江湖中,评估模型的好坏是非常关键的一环.而 ROC(Rece ...
- 状态模式(Sate Pattern)
一.模式动机 状态模式(State Pattern)是一种较为复杂的行为型模式.它用于解决系统中复杂对象的状态转换以及不同状态下行为的封装问题.当系统中某个对象存在多个状态,这些状态之间可以进行转换, ...
- Jenkins构建UI自动化项目,指定本地执行,没弹起浏览显示
1. 原因分析 为什么执行web没有弹出浏览器,Jenkins日志显示正在执行中 jenkins是用windows installer 安装成 windows的服务了,那么启动windows后jenk ...
- 15分钟面试被5连CALL,你扛得住么?
最近一个朋友跳槽找工作,跟V 哥说被15分钟内一个问题5连 CALL,还好是自己比较熟悉的技术点,面试官最后跟他说,面了几十个人,你是第一个回答比较满意的,我好奇都是什么问题,原来是关于锁的问题连环问 ...