MySQL中字符串查询效率大比拼
背景
最近有个同事对字符串加索引,加完后,发现多了个奇奇怪怪的数字
执行的SQL如下:
alter table string_index_test add index `idx_name` (`name`) USING BTREE;
这个奇怪数字就是191,它很是疑惑,也没指定索引的长度
通过查看MySQL官方文档
InnoDB has a maximum index length of 767 bytes for tables that use COMPACT or REDUNDANT row format, so for utf8mb3 or utf8mb4 columns, you can index a maximum of 255 or 191 characters, respectively. If you currently have utf8mb3 columns with indexes longer than 191 characters, you must index a smaller number of characters.
In an InnoDB table that uses COMPACT or REDUNDANT row format, these column and index definitions are legal:
col1 VARCHAR(500) CHARACTER SET utf8, INDEX (col1(255))
To use utf8mb4 instead, the index must be smaller:
col1 VARCHAR(500) CHARACTER SET utf8mb4, INDEX (col1(191))
大概意思就是InnoDB最大索引长度为 767 字节数,用的编码是utf8mb4,则可以存储191个字符(767/4 约等于 191),编码字段长度超出最大索引长度后MySQL 默认在普通索引追加了191
思考
1、MySQL中如何提高字符串查询效率?
对字符串加索引?
一般情况下,是不建议在字符串加索引,占空间
如果一定要加,建议可以指定长度,前提是字符串前面部分区分度好的话,此时这类索引就叫前缀索引
2、前缀索引有什么问题?
区分度不好的话,很容易发生碰撞,进而引发一系列问题
我们再通过执行计划来分析一波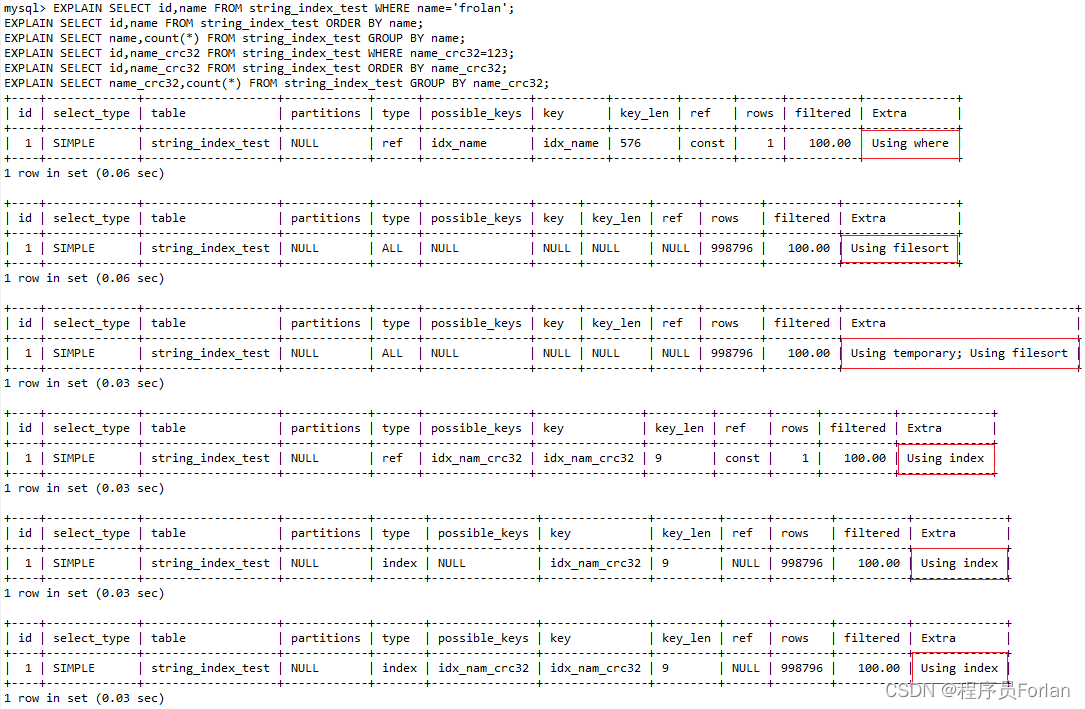
上面分别演示了前缀索引和普通索引在只有where条件、order by和group by不同执行情况,可以看到Extra的说明,前缀索引只有where条件,无法使用覆盖索引,order by会使用filesort,group by会使用temporary和filesort
总的来说,前缀索引无法使用覆盖索引,进而导致order by和group by要使用文件排序,甚至临时表前缀索引有这么些问题,不指定长度?怎么处理?
分析
准备了单表100W的数据进行测试
使用性能压力测试工具mysqlslap
性能测试脚本
mysqlslap -uroot -p --concurrency=100,200 --iterations=1 --number-of-queries=1 --create-schema=test --query=C:\xxx\query.sql
–concurrency=100,200 测试并发的线程数/客户端数,第一次100,第二次200
–iterations=1 指定测试重复次数1次
–number-of-queries=1 指定每个线程执行的 SQL 语句数量上限(不精确)
–create-schema=test 指定查询的数据库test
1、不加索引
查询的SQL:SELECT SQL_NO_CACHE * FROM string_index_test WHERE name=‘forlan’;
Benchmark
Average number of seconds to run all queries: 8.328 seconds
Minimum number of seconds to run all queries: 8.328 seconds
Maximum number of seconds to run all queries: 8.328 seconds
Number of clients running queries: 100
Average number of queries per client: 0
Benchmark
Average number of seconds to run all queries: 18.078 seconds
Minimum number of seconds to run all queries: 18.078 seconds
Maximum number of seconds to run all queries: 18.078 seconds
Number of clients running queries: 200
Average number of queries per client: 0
2、加字符串索引
alter table string_index_test add index idx_name (name) USING BTREE;
查询的SQL:SELECT SQL_NO_CACHE * FROM string_index_test WHERE name=‘forlan’;
Benchmark
Average number of seconds to run all queries: 0.250 seconds
Minimum number of seconds to run all queries: 0.250 seconds
Maximum number of seconds to run all queries: 0.250 seconds
Number of clients running queries: 100
Average number of queries per client: 0
Benchmark
Average number of seconds to run all queries: 1.438 seconds
Minimum number of seconds to run all queries: 1.438 seconds
Maximum number of seconds to run all queries: 1.438 seconds
Number of clients running queries: 200
Average number of queries per client: 0
3、使用CRC32创建索引
CRC全称为Cyclic Redundancy Check,又叫循环冗余校验。
CRC32是CRC算法的一种,返回值的范围0~2^32-1,使用bigint存储
加一个name_crc32列,创建这个列的所有,索引空间小很多,利用整型加速查询
加索引:alter table string_index_test add index idx_nam_crc32 (name_crc32) USING BTREE;
查询的SQL:SELECT SQL_NO_CACHE * FROM string_index_test WHERE name_crc32=CRC32(‘forlan’) and name=‘forlan’;因为CRC32存在发生碰撞,所以加上name条件,才能筛选出正确的数据
Benchmark
Average number of seconds to run all queries: 0.266 seconds
Minimum number of seconds to run all queries: 0.266 seconds
Maximum number of seconds to run all queries: 0.266 seconds
Number of clients running queries: 100
Average number of queries per client: 0
Benchmark
Average number of seconds to run all queries: 0.390 seconds
Minimum number of seconds to run all queries: 0.390 seconds
Maximum number of seconds to run all queries: 0.390 seconds
Number of clients running queries: 200
Average number of queries per client: 0
总结
- 通过对字符串加索引,可以提高查询效率,但需要注意指定长度,无法使用覆盖索引
- 通过使用CRC32,需要额外存一个字段,将字符串转为整数存储,节省空间,效率提升并不是很大,但存在碰撞问题,可以加多字符串筛选条件
- -对于CRC32存在碰撞问题,可以使用CRC64减少碰撞,但需要安装 common_schema database函数库
MySQL中字符串查询效率大比拼的更多相关文章
- MySQL 中联合查询效率分析
目前我有两个表,一个keywords和一个news表.keyword存放关键词是从news中提取,通newsid进行关联,两表关系如图: keywords中存有20万条数据,news中有2万条数据,现 ...
- mysql 中合并查询结果union用法 or、in与union all 的查询效率
mysql 中合并查询结果union用法 or.in与union all 的查询效率 (2016-05-09 11:18:23) 转载▼ 标签: mysql union or in 分类: mysql ...
- 【面经】面试官:如何以最高的效率从MySQL中随机查询一条记录?
写在前面 MySQL数据库在互联网行业使用的比较多,有些小伙伴可能会认为MySQL数据库比较小,存储不了很多的数据.其实,这些小伙伴是真的不了解MySQL.MySQL的小不是说使用MySQL存储的数据 ...
- mysql in 子查询 效率慢 优化(转)
mysql in 子查询 效率慢 优化(转) 现在的CMS系统.博客系统.BBS等都喜欢使用标签tag作交叉链接,因此我也尝鲜用了下.但用了后发现我想查询某个tag的文章列表时速度很慢,达到5秒之久! ...
- mysql中模糊查询的四种用法介绍
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
- MySQL中字符串与数字比较的坑
公司项目代码中,某枚举字段数据库表中类型是char(1),在代码中,误以为是TINYINT,所以用数字筛选,后来发现结果不对.发现了一个现象,用数字0筛选会把所有的记录给筛选出来. 经过排查发现是在M ...
- <经验杂谈>Mysql中字符串处理的几种处理方法concat、concat_ws、group_concat
Mysql中字符串处理的几种处理方法concat.concat_ws.group_concat以下详情: MySQL中concat函数使用方法:CONCAT(str1,str2,-) 返回结果为连接参 ...
- Mysql中字符串正确的连接方法
虽然SQL server和My sql的语句基本都一致,但是仍然存在一些小区别.就如字符串的连接来说,SQL server中的字符串连接是使用“+”来连接,不带引号sql server是做加法运算.而 ...
- Mysql中分页查询两个方法比较
mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下 1 2 3 SELECT COUNT(*) FROM foo WHERE b = 1; SELECT a FROM ...
- 下面介绍mysql中模糊查询的四种用法:
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
随机推荐
- Oracle数据库 insert 插入数据 显示问号乱码的解决办法
一.问题描述 插入的中文数据 显示成问号(乱码),其他语言如老挝文.柬文等都一样. 二.解决方案 plsql插入oracle数据乱码问题处理起来其实很简单,因为乱码问题一般都是由于编码不一致导致的,我 ...
- 一文了解清楚kafka消息丢失问题和解决方案
前言 今天分享一下kafka的消息丢失问题,kafka的消息丢失是一个很值得关注的问题,根据消息的重要性,消息丢失的严重性也会进行放大,如何从最大程度上保证消息不丢失,要从生产者,消费者,broker ...
- Java面试——Netty
一.BIO.NIO 和 AIO [1]阻塞 IO(Blocking I/O):同步阻塞I/O模式,当一条线程执行 read() 或者 write() 方法时,这条线程会一直阻塞直到读取一些数据或者写出 ...
- Spring AOP面向切面编程案例 (注解驱动开发)
AOP(动态代理):指在程序运行期间动态的将某段代码切入到指定方法指定位置进行运行的编程方式:[1]导入 aop 模块:Spring AOP:(spring-aspects):[2]定义一个业务逻辑类 ...
- Quicker快速开发,简单的网页数据爬取(示例,获取天眼查指定公司基础工商数据)
前言 有某个线上项目,没有接入工商接口,每次录入公司的时候,都要去天眼查.企查查或者其他公开数据平台,然后手动录入,一两个还好说,数量多了的重复操作就很烦,而且,部分数据是包含超链接,一不注意就点进去 ...
- 实现一个CRDT工具库——VClock 时钟向量类
这段代码实现了一个VClock类,它是基于GCounter实现的.VClock是一种向量时钟,它可以用于在分布式系统中对事件发生的顺序进行排序.VClock的实现方式是将每个节点的计数器值存储在一个字 ...
- [Java]变量及其初始化 与 类对象的初始化
1 变量 1.1 变量的[定义] 1.2 变量的[作用域] 1.3 变量的[初始值] 1.4 补充:缓存变量 1.5 变量的[分类]与[未初始化情况] 2 类对象 2.1 类对象的初始化/构造过程 1 ...
- Django笔记二十一之使用原生SQL查询数据库
本文首发于公众号:Hunter后端 原文链接:Django笔记二十一之使用原生SQL查询数据库 Django 提供了两种方式来执行原生 SQL 代码. 一种是使用 raw() 函数,一种是 使用 co ...
- Java的初始化块
三种初始化数据域的方法: 在构造器中设置值 在声明中赋值 初始化块(initialization block) 初始化块 在一个类的声明中,可以包含多个代码块.只要构造类的对象,这些块就会被执行. c ...
- Python 变量作用域和列表
变量作用域 变量由作用范围限制 分类:按照作用域分类 全局(global):在函数外部定义 局部(local):在函数内部定义 变量的作用范围: 全局变量:在整个全局范围有效 全局碧昂量在局部可以使用 ...