TensorFLow手写字识别深度学习网络分析详解
Tensorflow和MNIST简介
TensorFlow 是一个采用数据流图,用于数值计算的开源软件库。它是一个不严格的“神经网络”库,可以利用它提供的模块搭建大多数类型的神经网络。它可以基于CPU或GPU运行,可以自动使用GPU,无需编写分配程序。主要支持Python编写,但是官方说也有C++使用界面。
MNIST是一个巨大的手写数字数据集,被广泛应用于机器学习识别领域。MNIST有60000张训练集数据和10000张测试集数据,每一个训练元素都是28*28像素的手写数字图片。作为一个常见的数据集,MNIST经常被用来测试神经网络,也是比较基本的应用。
CNN算法
识别算法主要使用的是卷积神经网络算法(CNN)。
主要结构为:输入-卷积层-池化层-卷积层-池化层-全连接层-输出
卷积
卷积其实可以看做是提取特征的过程。如果不使用卷积的话,整个网络的输入量就是整张图片,处理就很困难。 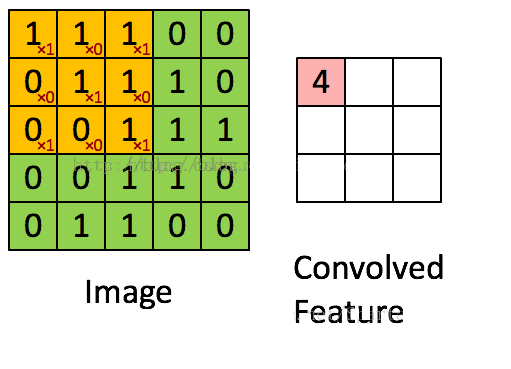
假设图中绿色5*5矩阵为原图片,黄色的3*3矩阵就是我们的过滤器,即卷积核。就是将原来的图片进行特征值的过滤。将黄色矩阵和绿色矩阵被覆盖的部分进行卷积计算,即每个元素相乘求和,便可得到这一部分的特征值,即图中的卷积特征。
然后,向右滑动黄色的矩阵,便可继续求下一部分的卷积特征值。而滑动的距离就是步长。
池化
池化是用来把卷积结果进行压缩,进一步减少全连接时的连接数。细化卷积结果特征。 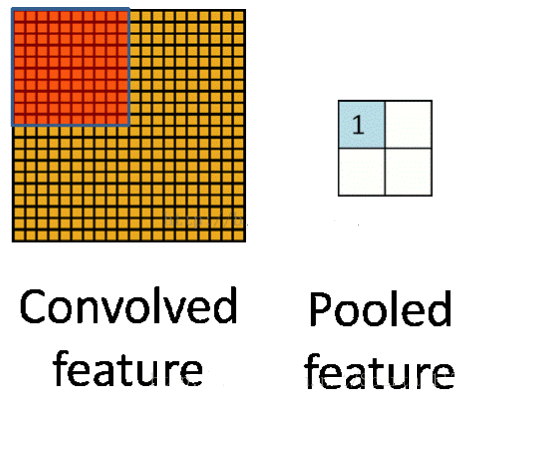
池化有两种:
一种是最大池化,在选中区域中找最大的值作为抽样后的值;
一种是平均值池化,把选中的区域中的平均值作为抽样后的值。
到此,Tensorflow的入门级的基本知识介绍完了。下面,将结合一个MNIST的手写识别的例子,从代码上简单分析一下,下面是源代码:
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 import tensorflow as tf
5
6 #加载测试数据的读写工具包,加载测试手写数据,目录MNIST_data是用来存放下载网络上的训练和测试数据的。
7 #这里,参考我前面的博文,由于网络原因,测试数据,我单独下载后,放在当前目录的MNIST_data目录了。
8 import tensorflow.examples.tutorials.mnist.input_data as input_data
9 mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
10
11 #创建一个交互式的Session。
12 sess = tf.InteractiveSession()
13
14 #创建两个占位符,数据类型是float。x占位符的形状是[None,784],即用来存放图像数据的变量,图像有多少张
15 #是不关注的。但是图像的数据维度有784围。怎么来的,因为MNIST处理的图片都是28*28的大小,将一个二维图像
16 #展平后,放入一个长度为784的数组中。
17 #y_占位符的形状类似x,只是维度只有10,因为输出结果是0-9的数字,所以只有10种结构。
18 x = tf.placeholder("float", shape=[None, 784])
19 y_ = tf.placeholder("float", shape=[None, 10])
20
21 #通过函数的形式定义权重变量。变量的初始值,来自于截取正态分布中的数据。
22 def weight_variable(shape):
23 initial = tf.truncated_normal(shape, stddev=0.1)
24 return tf.Variable(initial)
25
26 #通过函数的形式定义偏置量变量,偏置的初始值都是0.1,形状由shape定义。
27 def bias_variable(shape):
28 initial = tf.constant(0.1, shape=shape)
29 return tf.Variable(initial)
30
31 #定义卷积函数,其中x是输入,W是权重,也可以理解成卷积核,strides表示步长,或者说是滑动速率,包含长宽方向
32 #的步长。padding表示补齐数据。 目前有两种补齐方式,一种是SAME,表示补齐操作后(在原始图像周围补充0),实
33 #际卷积中,参与计算的原始图像数据都会参与。一种是VALID,补齐操作后,进行卷积过程中,原始图片中右边或者底部
34 #的像素数据可能出现丢弃的情况。
35 def conv2d(x, W):
36 return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
37
38 #这步定义函数进行池化操作,在卷积运算中,是一种数据下采样的操作,降低数据量,聚类数据的有效手段。常见的
39 #池化操作包含最大值池化和均值池化。这里的2*2池化,就是每4个值中取一个,池化操作的数据区域边缘不重叠。
40 #函数原型:def max_pool(value, ksize, strides, padding, data_format="NHWC", name=None)。对ksize和strides
41 #定义的理解要基于data_format进行。默认NHWC,表示4维数据,[batch,height,width,channels]. 下面函数中的ksize,
42 #strides中,每次处理都是一张图片,对应的处理数据是一个通道(例如,只是黑白图片)。长宽都是2,表明是2*2的
43 #池化区域,也反应出下采样的速度。
44 def max_pool_2x2(x):
45 return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
46
47 #定义第一层卷积核。shape在这里,对应卷积核filter。
48 #其中filter的结构为:[filter_height, filter_width, in_channels, out_channels]。这里,卷积核的高和宽都是5,
49 #输入通道1,输出通道数为32,也就是说,有32个卷积核参与卷积。
50 W_conv1 = weight_variable([5, 5, 1, 32])
51 #偏置量定义,偏置的维度是32.
52 b_conv1 = bias_variable([32])
53
54 #将输入tensor进行形状调整,调整成为一个28*28的图片,因为输入的时候x是一个[None,784],有与reshape的输入项shape
55 #是[-1,28,28,1],后续三个维度数据28,28,1相乘后得到784,所以,-1值在reshape函数中的特殊含义就可以映射程None。即
56 #输入图片的数量batch。
57 x_image = tf.reshape(x, [-1,28,28,1])
58
59 #将2维卷积的值加上一个偏置后的tensor,进行relu操作,一种激活函数,关于激活函数,有很多内容需要研究,在此不表。
60 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
61 #对激活函数返回结果进行下采样池化操作。
62 h_pool1 = max_pool_2x2(h_conv1)
63
64 #第二层卷积,卷积核大小5*5,输入通道有32个,输出通道有64个,从输出通道数看,第二层的卷积单元有64个。
65 W_conv2 = weight_variable([5, 5, 32, 64])
66 b_conv2 = bias_variable([64])
67
68 #类似第一层卷积操作的激活和池化
69 h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
70 h_pool2 = max_pool_2x2(h_conv2)
71
72 #图片尺寸减小到7x7,加入一个有1024个神经元的全连接层,用于处理整个图片。把池化层输出的张量reshape成一些
73 #向量,乘上权重矩阵,加上偏置,然后对其使用ReLU激活操作。
74 W_fc1 = weight_variable([7 * 7 * 64, 1024])
75 b_fc1 = bias_variable([1024])
76
77 #将第二层池化后的数据进行变形
78 h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
79 #进行矩阵乘,加偏置后进行relu激活
80 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
81
82 keep_prob = tf.placeholder("float")
83 #对第二层卷积经过relu后的结果,基于tensor值keep_prob进行保留或者丢弃相关维度上的数据。这个是为了防止过拟合,快速收敛。
84 h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
85
86 W_fc2 = weight_variable([1024, 10])
87 b_fc2 = bias_variable([10])
88
89 #最后,添加一个softmax层,就像前面的单层softmax regression一样。softmax是一个多选择分类函数,其作用和sigmoid这个2值
90 #分类作用地位一样,在我们这个例子里面,softmax输出是10个。
91 y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
92
93 #实际值y_与预测值y_conv的自然对数求乘积,在对应的维度上上求和,该值作为梯度下降法的输入
94 cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
95
96 #下面基于步长1e-4来求梯度,梯度下降方法为AdamOptimizer。
97 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
98
99 #首先分别在训练值y_conv以及实际标签值y_的第一个轴向取最大值,比较是否相等
100 correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
101
102 #对correct_prediction值进行浮点化转换,然后求均值,得到精度。
103 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
104
105 #先通过tf执行全局变量的初始化,然后启用session运行图。
106 sess.run(tf.global_variables_initializer())
107 for i in range(20000):
108 #从mnist的train数据集中取出50批数据,返回的batch其实是一个列表,元素0表示图像数据,元素1表示标签值
109 batch = mnist.train.next_batch(50)
110 if i%100 == 0:
111 #计算精度,通过所取的batch中的图像数据以及标签值还有dropout参数,带入到accuracy定义时所涉及到的相关变量中,进行
112 #session的运算,得到一个输出,也就是通过已知的训练图片数据和标签值进行似然估计,然后基于梯度下降,进行权值训练。
113 train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0})
114 print "step %d, training accuracy %g"%(i, train_accuracy)
115 #此步主要是用来训练W和bias用的。基于似然估计函数进行梯度下降,收敛后,就等于W和bias都训练好了。
116 train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
117
118 #对测试图片和测试标签值以及给定的keep_prob进行feed操作,进行计算求出识别率。就相当于前面训练好的W和bias作为已知参数。
119 print "test accuracy %g"%accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
对于CNN领域的卷积,不是连续信号的时域积分思路。而是输入图像X与卷积核W进行内积。卷积的过程,其实是一种特征提取的过程!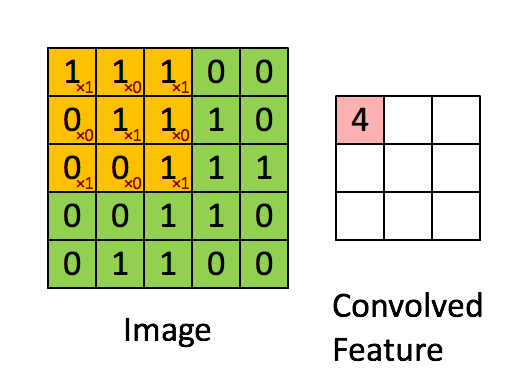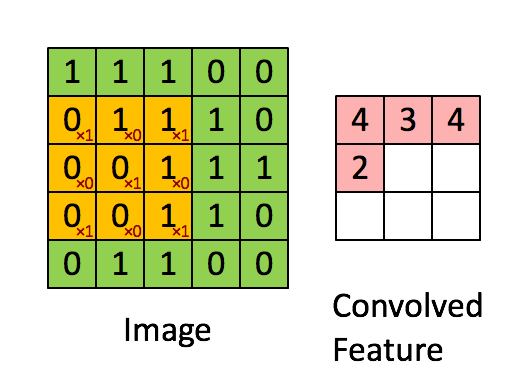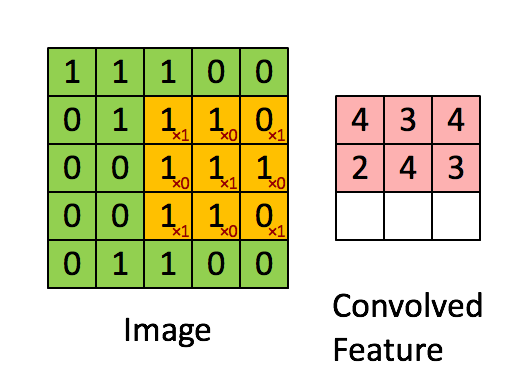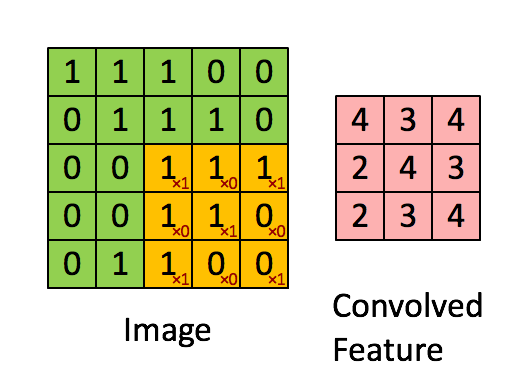
下面引用一下牛人的分析
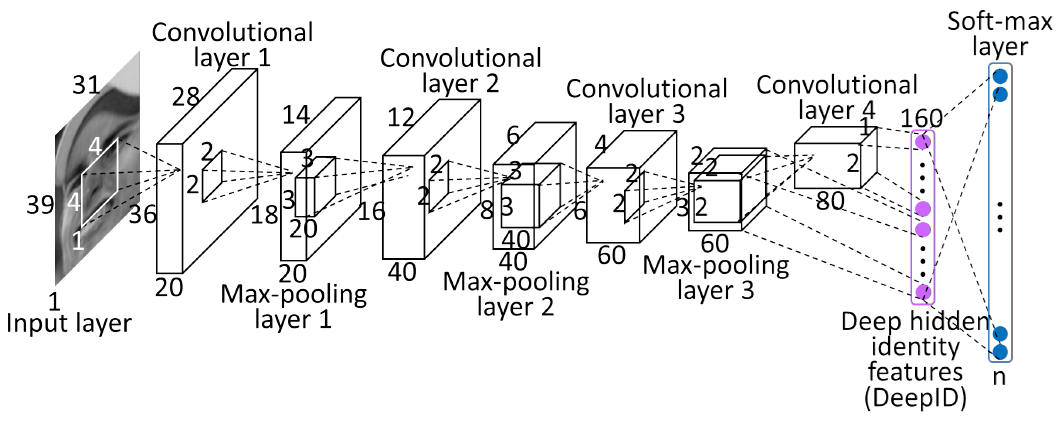
简单解释如下:
1.input layer:输入层是一个31*39的灰度图片,通道数是1,也可以理解输入图片的depth是1,很多论文或者技术文档中,输入通道数(in_channels)或者图片厚度(depth)都有用到。
2.convolutional layer 1: 第一层卷积层,卷积核大小为4*4,输出结果厚度depth为20,表示有20个4*4的卷积核与输入图片进行特征提取。卷基层神经元的大小为36*28,这个神经元大小是这么算出来的:(39 - 4 + 1)*(31 - 4 +1).
3.Max-pooling layer 1:第一层池化层,池化单元大小为2*2,池化不会改变输入数据的厚度,所以输出还是20,池化将神经元的大小降为一半,18*14.
4.convolutional layer 2:第二层卷积层,卷积核大小为3*3,输出结果厚度depth为40,表示有40个3*3的卷积核与前一级的输出进行了特征提取。卷积层神经元的大小为16*12,这个神经元大小是这么算出来的:(18 - 3 + 1)*(14 - 3 +1)。
5.Max-pooling layer 2:第二层池化层,池化单元大小为2*2,池化不会改变输入数据的厚度,所以输出还是40,池化将神经元的大小降为一半,8*6.
6.convolutional layer 3:第三层卷积层,卷积核大小为3*3,输出结果厚度depth为60,表示有60个3*3的卷积核与前一级的输出进行了特征提取。卷积层神经元的大小为6*4,这个神经元大小是这么算出来的:(8 - 3 + 1)*(6 - 3 +1)。
7.Max-pooling layer 3:第三层池化层,池化单元大小为2*2,池化不会改变输入数据的厚度,所以输出还是60,池化将神经元的大小降为一半,3*2.
8.convolutional layer 4:第四层卷积层,卷积核大小为2*2,输出结果厚度depth为80,表示有80个2*2的卷积核与前一级的输出进行了特征提取。卷积层神经元的大小为2*1,这个神经元大小是这么算出来的:(3 - 2 + 1)*(2 - 2 +1)。
9.接下来,对第四层输出结果,经过一次展平操作,80*(2*1)即得到160个输出特征。
10.经过softmax分类,即可得到最终输出预测结果。
TensorFLow手写字识别深度学习网络分析详解的更多相关文章
- mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)
前言 今天记录一下深度学习的另外一个入门项目——<mnist数据集手写数字识别>,这是一个入门必备的学习案例,主要使用了tensorflow下的keras网络结构的Sequential模型 ...
- 用TensorFlow教你手写字识别
博主原文链接:用TensorFlow教你做手写字识别(准确率94.09%) 如需转载,请备注出处及链接,谢谢. 2012 年,Alex Krizhevsky, Geoff Hinton, and Il ...
- Reading | 《TensorFlow:实战Google深度学习框架》
目录 三.TensorFlow入门 1. TensorFlow计算模型--计算图 I. 计算图的概念 II. 计算图的使用 2.TensorFlow数据类型--张量 I. 张量的概念 II. 张量的使 ...
- 【书评】【不推荐】《TensorFlow:实战Google深度学习框架》(第2版)
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 这本书我老老实实从头到尾看了一遍(实际上是看到第9章,刚看完,后面的实在看不下去了,但还是会坚持看的),所有的代码 ...
- 基于Ubuntu+Python+Tensorflow+Jupyter notebook搭建深度学习环境
基于Ubuntu+Python+Tensorflow+Jupyter notebook搭建深度学习环境 前言一.环境准备环境介绍软件下载VMware下安装UbuntuUbuntu下Anaconda的安 ...
- knn算法手写字识别案例
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os from sklearn.neighb ...
- 2. 知识图谱-命名实体识别(NER)详解
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识 ...
- iPhone应用开发 UITableView学习点滴详解
iPhone应用开发 UITableView学习点滴详解是本文要介绍的内容,内容不多,主要是以代码实现UITableView的学习点滴,我们来看内容. -.建立 UITableView DataTab ...
- Eclipse IDE for C/C++ Developers和MinGW安装配置C/C++开发学习环境详解
Eclipse IDE for C/C++ Developers和MinGW安装配置C/C++开发学习环境详解 操作系统:Windows 7 JDK版本:1.6.0_33 Eclipse版本:Juno ...
- tensorflow卷积神经网络与手写字识别
1.知识点 """ 基础知识: 1.神经网络(neural networks)的基本组成包括输入层.隐藏层.输出层.而卷积神经网络的特点在于隐藏层分为卷积层和池化层(po ...
随机推荐
- 野火 STM32MP157 开发板 UBOOT 编译烧写
一.环境 编译环境:Ubuntu 版本:20.4.1 交叉编译工具:arm-none-eabi-gcc 版本:10.3.1 开发板:STM32MP157 pro 烧写软件:STM32CubeProgr ...
- C++多态与虚拟:C++编译器对函数名的改编(Name Mangling)
如果函数名称都相同(也就是被overloaded),编译器在面对你的函数唤起动作时,究竟是如何确定调用哪个函数实体呢?事实上,编译器把所有同名的overloaded functions视为不同的函数, ...
- M9K内存使用教程
M9K内存使用教程 M9K内存是Altera内嵌的高密度存储阵列.现代的FPGA基本都包含类似的不同大小的内存. M9K的每个块有8192位(包含校验位实际是9216位).配置灵活.详细了解M9K可参 ...
- CCE云原生混部场景下的测试案例
本文分享自华为云社区<CCE云原生混部场景下在线任务抢占.压制离线任务CPU资源.保障在线任务服务质量效果测试>,作者:可以交个朋友. 背景 企业的 IT 环境通常运行两大类进程,一类是在 ...
- Goland 的配置
目录 下载安装 设置好go的系统环境变量 设置 GOROOT 设置 GOPATH 设置 MODULES 设置 工作面板里的字体缩放大小快捷键 安装主题包 安装中文中包 Redis Mannager 读 ...
- Golang 开发常用代码片段
Struct to JsonString type BaseRequest struct { httpMethod string domain string path string params ma ...
- HDU 多校 2023 Round #6 题解
HDU 多校 2023 Round #6 题解 \(\text{By DaiRuiChen007}\) A. Count Problem Link 题目大意 求有多少个长度为 \(n\),字符集大小为 ...
- C 语言编程 — 异常处理
目录 文章目录 目录 前文列表 异常处理 perror() 和 strerror() 输出异常信息 程序退出状态 前文列表 <程序编译流程与 GCC 编译器> <C 语言编程 - 基 ...
- 【漏洞复现】用友NC uapjs RCE漏洞(CNVD-C-2023-76801)
产品介绍 用友NC是一款企业级ERP软件.作为一种信息化管理工具,用友NC提供了一系列业务管理模块,包括财务会计.采购管理.销售管理.物料管理.生产计划和人力资源管理等,帮助企业实现数字化转型和高效管 ...
- 任务Task系列之使用CancellationToken取消Task
本文参考书籍<CLR via C#> Task的取消采用一种形如令牌(Token)的方式.首先先构建一个CancellationTokenSource实例,然后任务中执行的方法必须能接受一 ...