MR 原理
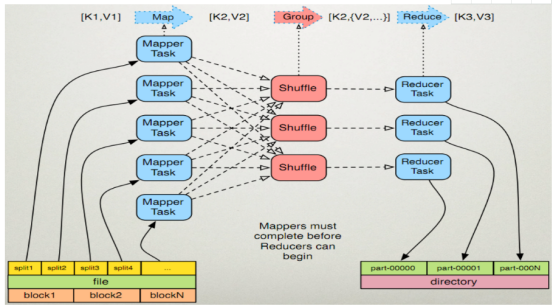
MapReduce的执行步骤:
1、Map任务处理
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。 <0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。 <hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。详见《Partitioner》
1.4 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后:<hello,1> <hello,1> <me,1> <you,1> 分组后:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可选)对分组后的数据进行归约。详见《Combiner》
Combiner编程(1.5可选步骤,视情况而定!)
每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。
combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。 如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
注意:Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。
2、Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。
/////////////////////////////////////////////////////////////////////////////

Map端:
1、在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。(注意:map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。)
2、写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。(注意:在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!)
3、最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
Reduce端:
1、Copy阶段:Reducer通过Http方式得到输出文件的分区。
reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给 JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
2、Merge阶段:如果形成多个磁盘文件会进行合并
从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
3、Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。(注意:当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。)
/////////////////////////////////////////////////////////////////////////////
2.2 对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑, <hello,2> <me,1> <you,1>
处理后,产生新的<k,v>输出。
2.3 对reduce输出的<k,v>写到HDFS中。
///////////////////////追加////////
partition过程
1,计算(key,value)所属与的分区。
当map输出的时候,写入缓存之前,会调用partition函数,计算出数据所属的分区,并且把这个元数据存储起来。
2,把属与同一分区的数据合并在一起。
当数据达到溢出的条件时(即达到溢出比例,启动线程准备写入文件前),读取缓存中的数据和分区元数据,然后把属与同一分区的数据合并到一起。
(三)自定义partition函数
public static class Partition extends Partitioner<intwritable, intwritable=""> {
@Override
public int getPartition(IntWritable key, IntWritable value,int numPartitions) {
int Maxnumber = 65223;
int bound = Maxnumber / numPartitions + 1;
int keynumber = key.get();
for (int i = 0; i < numPartitions; i++) {
//分区算法
if (keynumber < bound * i && keynumber >= bound * (i - 1)) {
return i - 1;
}
}
return 0;
}
}
调用
job.setPartitionerClass(Partition.class);
MR 原理的更多相关文章
- mr原理简单分析
背景 又是一个周末一天一天的过的好快,今天的任务干啥呢,索引总结一些mr吧,因为前两天有面试问过我?我当时也是简单说了一下,毕竟现在写mr程序的应该很少很少了,废话不说了,结合官网和自己理解写起. 官 ...
- MR原理
三.MapReduce运行原理 1.Map过程简述: 1)读取数据文件内容,对每一行内容解析成<k1,v1>键值对,每个键值对调用一次map函数 2)编写映射函数处理逻辑,将输入的< ...
- [Hadoop]浅谈MapReduce原理及执行流程
MapReduce MapReduce原理非常重要,hive与spark都是基于MR原理 MapReduce采用多进程,方便对每个任务资源控制和调配,但是进程消耗更多的启动时间,因此MR时效性不高.适 ...
- HadoopMR-Spark-HBase-Hive
 YARN资源调度: 三种 FIFO 大任务独占 一堆小任务独占 capacity 弹性分配 :计算任务较少时候可以利用全部的计算资源,当队列的任务多的时候会按照比例进行资源平衡. 容量保证:保证队 ...
- 2_分布式计算框架MapReduce
一.mr介绍 1.MapReduce设计理念是移动计算而不是移动数据,就是把分析计算的程序,分别拷贝一份到不同的机器上,而不是移动数据. 2.计算框架有很多,不是谁替换谁的问题,是谁更适合的问题.mr ...
- Hadoop基本知识,(以及MR编程原理)
hadoop核心是:MapReduce和HDFS (对应着job执行(程序)和文件存储系统(数据的输入和输出)) CRC32作数据交验:在文件Block写入的时候除了写入数据还会写入交验信息,在读取 ...
- Hive mapreduce SQL实现原理——SQL最终分解为MR任务,而group by在MR里和单词统计MR没有区别了
转自:http://blog.csdn.net/sn_zzy/article/details/43446027 SQL转化为MapReduce的过程 了解了MapReduce实现SQL基本操作之后,我 ...
- 【Hadoop】YARN 原理、MR本地&YARN运行模式
1.基本概念 2.YARN.MR交互流程 3.源码解读
- 【系统篇】从int 3探索Windows应用程序调试原理
探索调试器下断点的原理 在Windows上做开发的程序猿们都知道,x86架构处理器有一条特殊的指令——int 3,也就是机器码0xCC,用于调试所用,当程序执行到int 3的时候会中断到调试器,如果程 ...
随机推荐
- CyberArk
CyberArk PIM 套件由5个部分组成: · CyberArk EPV (Enterprise Password Vault)– 企业密码保险库 基于CyberArk 专利的Vault技术,为企 ...
- 使用自己的Python函数处理Protobuf中的字符串编码
我目前所在的项目是一个老项目,里面的字符串编码有点乱,数据库中有些是GB2312,有些是UTF8:代码中有些是GBK,有些是UTF8,代码中转来转去,经常是不太清楚当前这个字符串是什么编码,由于是老项 ...
- Shell中整数自增的几种方式
Shell中整数自增的几种方式 2016年08月27日 19:07:40 杰瑞26 阅读数:2816 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.n ...
- MapReduce分区数据倾斜
什么是数据倾斜? 数据不可避免的出现离群值,并导致数据倾斜,数据倾斜会显著的拖慢MR的执行速度 常见数据倾斜有以下几类 1.数据频率倾斜 某一个区域的数据量要远远大于其他区域 2.数据大小倾斜 ...
- 基于Netty的RPC架构学习笔记(七):netty学习之心跳
文章目录 idleStateHandler netty3
- sudo apt-get update:Could not get lock /var/lib/apt/lists/lock解决办法
原文: http://blog.chinaunix.net/uid-26932153-id-3193335.html 今天更新时候出现了点小问题,一开始更新到一半,我嫌速度慢,就取消掉了. 更新了so ...
- 『BASH』——Hadex's brief analysis of "Lookahead and Lookbehind Zero-Length Assertions"
/*为节省时间,本文以汉文撰写*/ -前言- 深入学习正则表达式,可以很好的提高思维逻辑的缜密性:又因正则应用于几乎所有高级编程语言,其重要性不言而喻,是江湖人士必备的内功心法. 正则表达式概要(ob ...
- 剑指offer——13矩阵中的路径
题目描述 请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径.路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向左,向右,向上,向下移动一个格子.如果一条路径经过了矩阵中 ...
- Firefox Developer Edition 是专为开发者设计
Firefox Developer Edition 当前是基于 Firefox 35.0a2,这款全新的浏览器包括内建调试功能,集成类似于Firefox火狐工具适配器的专用工具,并在浏览器当中内建We ...
- Crane /// 向量旋转+线段树
题目大意: 给定n条首尾相接的线段的长度 第一条从0,0开始,所有线段垂直与x轴向上延伸 给定c次操作 每次操作给定 s,a 使得 由第s条线段的角度 逆时针旋转a后 达到第s+1条线段的角度 每次操 ...