hadoop基本组件原理小总结
Hadoop基础知识小总结
这是本人(学生党)在学习hadoop半个学期后根据教科书后习题做的一个小总结,如有发现错误还请各位海涵并指出,我会及时改过来的,谢谢!
目录
Hadoop基础知识小总结... 1
第一章... 2
1、简述hadoop平台的发展过程... 2
2、简述Hasoop名称和及技术来源。... 3
3、简述Hadoop的体系架构。... 3
4、简述MapReduce的体系架构。... 3
5、简述HDFS和MapReduce在Hadoop中的角色。... 4
第二章... 5
1、简述VMware是什么。... 5
第三章... 5
1、简述HDFS的体系结构。... 5
2、描述HDFS读数据的操作过程。... 6
3、简述HDFS写流程。... 7
4、理解RPC通讯机制。... 8
第四章... 11
1、简述MapReduce的进程。... 11
2、简述Hadoop的数据类型优势。... 13
3、理解hadoop序列化和Java序列化对比。... 14
4、列举MapReduce常用接口类。... 14
第五章... 15
1、简述YARN架构的进程。... 15
2、理解YARN和MapReduce的对比。... 16
第八章... 17
1、简述Hbase数据库。... 17
2、简述Hbase的架构角色。... 18
3、理解Hbase过滤器的作用。... 18
第一章
1、简述hadoop平台的发展过程
Hadoop的出现来源于Google的两款产品:GFS和Mapreduce。2006年3月份,Map/Reduce和Nutch Disrtributed File System,DNFS)分别被纳入Hadoop项目中,Hadoop主要由HDFS,MapReduce和Hbase组成。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。Hadoop来源于于Apach Nutch(一个开源的网络搜索引擎),是Apach Lucene(文本搜索引擎库)的一部分。Hadoop的名字不是英文的缩写,他是一个虚构的名字,来自于创始人Doug Cutting孩子的一个大象玩具的名字。
Nutch项目开始于2002年,一个可工作的抓取工具和搜索系统很快浮出水面。但是此时他们意识到,他们的架构无法扩展到数十亿网页的网络。在2003年Google发表的一篇描述分布式文件系统(Google file system 简称GFS)的论文给了他们启发和帮助。论文中称Google正在使用这个系统。可以解决他们在网络抓取过程中产生大量数据文件的存储需求,因此产生了Nutch中的分布式文件系统(NDFS)。在2004年,Google发表了论文,向全世界介绍了MapReduce,MapReduce是一种用于数据处理的编程模型。而Hadoop的另外一个核心模块MapReduce就是这篇论文的一个具体实现。
Nutch中的NDFS和MapReduce实现的应用远不止搜索领域。在2006年2月,他们从Nutch中转移出来一个Lucene一个独立的子项目,称为Hadoop。大约在同一时间,Dong Cutting加入雅虎。雅虎提供了一个专门的团队和资源将Hadoop发展成为一个可在网络上运行的系统。2008年2月雅虎宣布其搜索引擎产品可部署在一个1万个内核的Hadoop集群上。在2008年4月,Hadoop打破世界纪录,称为最快排序1T数据的系统(不到三分钟),击败了前一年的297秒冠军。同年11月Google在报告中称他的MapReduce在执行1T数据排序只用了68秒。在2009年5月,报告称雅虎的团队使用Hadoop对1T数据进行排序只用了62秒。
2、简述Hasoop名称和及技术来源。
名称:Hadoop 是由道格.卡丁虚构出来的一个名字。
技术来源:hadoop来源于Google的三篇论文:GFS、MapReduce、BigTable。最初搭建的hadoop系统就是从这三篇论文出发的。
3、简述Hadoop的体系架构。
Hadoop是实现了分布式并行处理任务的系统框架,其核心组成是HDFS和MapReduce两个子系统,能够自动完成大任务计算和大数据储存的分割工作。Hadoop有众多子集。例如:Common、Yarn、Avro、Chukwa、Hive、Hbase、Zookeeper等。这些生态工具对Hadoop起到了良好的补充作用。
HDFS系统是Hadoop的储存系统,能够实现创建文件、删除文件、移动文件等功能,操作的数据主要是要处理的原始数据以及计算过程中的中间数据,实现高吞吐量的数据读写。MapReduce系统是一个分布式计算框架,主要任务就是利用廉价的计算机对海量的数据进行分解处理。
4、简述MapReduce的体系架构。
-分布式编程架构
-以数据为中心,更看重吞吐率
-分而治之(把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后整合各个节点的中间结果得到最终的输出)
-Map把一个任务分解成多个子任务
-Reduce将分解后的多任务分别处理,并将结果汇总为最终的结果
应用举例:清点图书馆藏书、统计单词的出现次数、混合辣椒酱的制作等等。
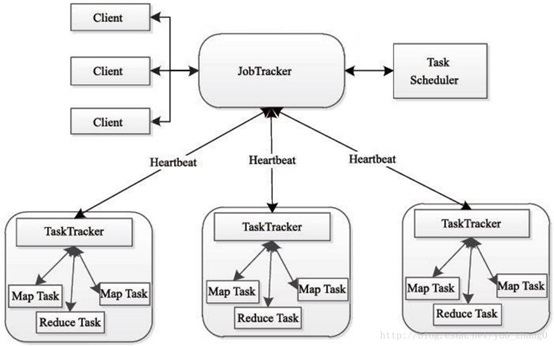
MapReduce架构图解
5、简述HDFS和MapReduce在Hadoop中的角色。
HDFS和MapReduce是hadoop中的核心组成系统,能够自动完成大任务的计算和大数据储存的分割工作。
HDFS系统是hadoop系统的储存系统,MapReduce系统是一个分布式计算框架,主任务是能够利用廉价的计算机对海量的数据进行分解处理,很大的一个优点是计算向数据靠近,这样就降低了数据传输的成本。
HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了了任务的分发、跟踪、执行等操作,收集结果,二者相互作用,完成了Hadoop的分布式集群任务。
第二章
1、简述VMware是什么。
VMware是一个“虚拟pc”软件,它使你可以在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。与“多启动”系统相比,VMWare采用了完全不同的概念。多启动系统在一个时刻只能运行一个系统,在系统切换时需要重新启动机器。
2、简述VMware和Linux系统两者的关系。
在VMware中Linux都是基于主机虚构出来的。Linux上所有的资源都是可以有VMware分配的。可以说VMware中的Linux,就是以VMware为前提条件的。
第三章
1、简述HDFS的体系结构。
HDFS集群有两类节点并以管理者——工作模式运行,即一个管理者管理多个工作者。NameNode管理文件系统的命名空间。他是维护着文件系统树和及其中的所有文件和目录。这些信息以两个文件保存次磁盘中:命名空间镜像文件和编辑日志文件。NameNode同时也记录着每个文件中各个数据块在节点上的信息,但是她不是永久保存块的信息,这些此信息会在系统启动时由数据节点重建。
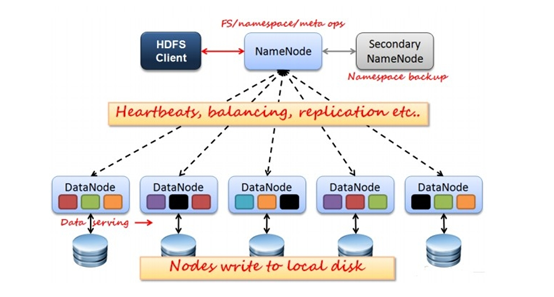
HDFS体系结构
2、描述HDFS读数据的操作过程。
(1)client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
(2)就近挑选一台datanode服务器,请求建立输入流 。
(3)DataNode向输入流中中写数据,以packet为单位来校验。
(4)关闭输入流。
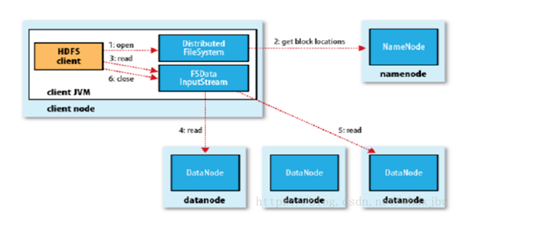
HDFS读流程
3、简述HDFS写流程。
(1)客户端向NameNode发出写文件请求。
(2)检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)
(3)client端按128MB的块切分文件。
(4)client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
(注:并不是写好一个块或一整个文件后才向后分发)
(5)每个DataNode写完一个块后,会返回确认信息。
(注:并不是每写完一个packet后就返回确认信息,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生)
(6)写完数据,关闭输输出流。
(7)发送完成信号给NameNode。
(注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性。

HDFS写过程
▲基于2、3的总结。
实例参考的博客链接:https://www.cnblogs.com/forfuture1978/archive/2010/11/10/1874222.html
4、理解RPC通讯机制。
(1)Remote Procedure Call(简称RPC):远程过程调用协议。
(2)概括的说,RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
(3)工作原理图:

参考博客地址:https://blog.csdn.net/u010010428/article/details/51345693
RPC简单框架简单理解博客地址:http://www.cnblogs.com/ChrisMurphy/p/6550184.html
根据HDFS的储存原理来看,简单分为如下:
client: 用户提出读/写数据的需求
namenode:协调与把控
datanodes:数据存储,数量常常较多。
SecondaryNameNode有两个作用,一是镜像备份,二是日志与镜像的定期合并。两个过程同时进行,称为checkpoint. 镜像备份的作用:备份fsimage(fsimage是元数据发送检查点时写入文件);日志与镜像的定期合并的作用:将Namenode中edits日志和fsimage合并,防止(如果Namenode节点故障,namenode下次启动的时候,会把fsimage加载到内存中,应用edit log,edit log往往很大,导致操作往往很耗时。
SecondaryNameNode参考博客地址:https://www.xuebuyuan.com/3196294.html
第四章
1、简述MapReduce的进程。
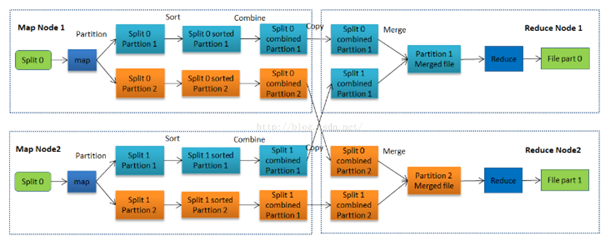
MapReduce工作流程图
主要步骤:
MapReduce主要步骤叙述:
Map阶段:
每个 Mapper任务是一个Java进程,它会读取HDFS中的文件,解析成很多的键值对
经过我们覆盖的map方法处理后,转换为很多的键值对再输出。 Mapper接收< ckey, value
形式的数据并处理成<
key, value>形式的数据,具体的处理过程用户可以定义
Step 1:把输入文件按照一定的标准分片( InputSplit),每个输入片的大小是固
定的。默认情况下,输入片( nputSplit的大小与数据块( Block)的大小是相同的。如果数据
块( Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB,那么小
的文件是一个输入片,大文件会分为两个数据块64MB和8MB,一共产生三个输入片。每
一个输入片由一个
Mapper进程处理。这里的三个输入片,会有三个 Mapper进程处理。
Step 2:用对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把
每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的
文本内容。
Step 3:调用Mapr类中的mp方法。第二阶段中解析出来的每一个键值对,
调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map
方法会输出零个或者多个键值对。
Step 4:按照一定的规则对第三阶段输出的键值对进行分区。比较是基于键进
行的。默认是只有一个区。分区的数量就是 Reducer任务运行的数量。默认只有一个 Reducer任务。
Step 5:对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相
同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。
那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没
有,直接输出到本地的 Linux文件中。
Step 6:是对数据进行归约处理,也就是 reduce处理。键相等的键值对会调用
次 reduce方法。经过这一阶段,数据量会减少。归约后的数据输出到本地的 Linux文件中。
本阶段默认是没有的,需要用户自己增加这一阶段的代码。
参考地址:书本第四章
博客地址; https://blog.csdn.net/yuzhuzhong/article/details/51476353
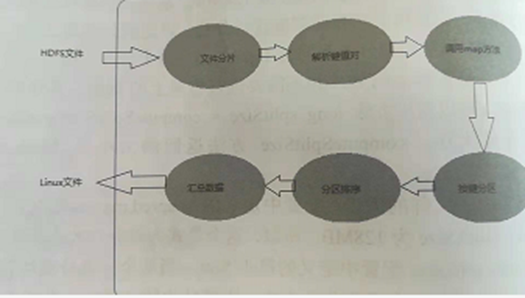
执行过程
Reduce阶段;
Reduce任务接收Maper任务的输出,规约处理后写入到HDFS中。

Reduce进程
Step 1:Reducer任务会主动从 Mapper任务复制其输出的键值对。 Mapper任
务可能会有很多,因此 Reducer会复制多个 Mapper的输出。
Step 2:把复制到 Reducer的本地数据,全部进行合并,即把分散的数据合并
成一个大的数据。再对合并后的数据排序。
Step 3:对排序后的键值对调用 reduce方法,键相等的键值对调用一次 reduce
方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文
件中。
2、简述Hadoop的数据类型优势。
(1)Text:使用UTF8格式存储的文本
(2)NullWritable:当<key, value>中的key或value为空时使用
3、理解hadoop序列化和Java序列化对比。
Java的序列化机制是不停的创建对象,但是在Hadoop序列化机制中,用户可以复用对象,这样就减少了Java对象的分配和回收,提高了利用率。
序列化:是指把结构化对象转化为字节流,便于在网上传输或写到磁盘上进行永久保存。
反序列化:是序列化的反过程。就是把字节流转换为结构对象。
Hadoop系列化有如下特点;
(1)紧凑:高效使用储存空间
(2)快速:读写数据的额外开销少
(3)可扩展性:可透明的读取老格式的数据
(4)互操作:支持多种语言的交互
序列化的作用:
(1)序列化在分布式环境的两大作用:进程间通讯,永久储存。
(2)Hadoop节点间通讯
4、列举MapReduce常用接口类。
MapReduce输入的处理类
(1)
FileInputFormat
(2)
InputSplit
MapReduce输出的处理类。
(1)TextOutputFormat
(2)SequenceFileOutputFormat
(3)SequenceFileAsOutputFormat
(4)MapFileOutputFormat
(5)MultipleOutputFormat
第五章
1、简述YARN架构的进程。
YARN框架主要是由Client、ResourceManager、NodeManager等进程。
主要工作流程步骤:
(1)
Client向ResourceManager提交任务。
(2)
ResourceManager分配创建Container任务并告知NodeManager启动进程MAAppMaster。
(3)
NodeManager接收指定任务并开辟空间启动MAAppMaster
(4)
NodeManager完成任务之后会及时汇报给ResourceManager
(5)
MRAPPMaster和ResourceManager交互,获取运行任务所需的资源。
(6)
MPAPPMaster获取资源后和NodeManager惊醒通讯,启动MapTask或ReduceTask
(7)
任务运行正常,定时向MRAPPMaster回报工作情况。

YARN计算过程图
2、理解YARN和MapReduce的对比。
(1) YARN大大减少了Job
Tracker的资源消耗,并且让监测每个Job子任务状态的程序分布式化了。
(2) YARN中Application Master是一个可变更部分,用户可以对不同编程模型编写自己的AppMst,让更多类型的编程模型能跑在Hadoop集群中。
(3)老的框架中,Job Tracker一个很大的负担就是监控Job下任务的运行状况,现在由Application Master去做,而Resource Manager是监测Application Master的运行状况,如果出问题,会将其在其他机器上重启。
参考博客地址:https://blog.csdn.net/post_yuan/article/details/54631446
第八章
1、简述Hbase数据库。
(1)Hbase是一个可分布、可扩展的大数据存储的 Hadoop数据库。适用于随机、实时
读写大数据操作时使用。它的目标就是拥有一张大表,支持亿行亿列。 Hbase目标主要依
靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力
(2)Hbase是一个分布式的、面向列的开源数据库源于Goge的一篇论文《 bigtable
个结构化数据的分布式存储系统》
Hbase是 Google Bigtable的开源实现,它利用 Hadoop
HDFS作为其文件存储系统,利用 Hadoop MapReduce来处理 HBase中的海量数据,利用
keeper作为协同服务。
(3) Hbase- Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式
存储系统,利用 HBase技术可在廉价 PC Server上搭建起大规模结构化存储集群。 Hbase利
用 Hadoop HDFS作为其文件存储系统,利用 Hadoop MapReduce.处理 Hbase中的海量数
,利用 Zookeeper作为协调工具
(4)Hbase表数据可以储存在本地,也可以储存在HDFS上。
网上其他详细参考博客:https://www.cnblogs.com/raphael5200/p/5229164.html
2、简述Hbase的架构角色。
(1)Client
包含访问 Hbase的接口, Client维护着一些 cache来加快对 Hbase的访问,比如 Region
的位置信息
(2)Zookeeper
保证任何时候,集群中只有一个 running master
●存储所有 Region的寻址入口。
●实时监控 Region Server的状态,将
Region Server的上线和下线信息,实时通知给
Master
●存储 Hbase的 schema,包括有哪些
table,每个tabe有哪些 column family
(3)Master可以启动多个HMaster
通过 Zookeeper的 Master Election机制保证总有一个 Master运行。
●为 Region Server分配 Region。
●负责 Region Server的负载均衡。
●发现失效的 Region Server并重新分配其上的 Region
(4)Region Server
维护 Master分配给它的 Region,处理对这些 Region的o请求。负责切分在运行过
程中变得过大的 Regione。
3、理解Hbase过滤器的作用。
Hbase筛选数据提供了一起租过滤器,通过这个过滤器可以在Hbase中的数据的多个维度上进行对数据筛选的操作,也就是说过滤器最终能够筛选的数据能够细化到具体的一个单元格上。通常来说,通过行、键、值来筛选数据的场景应用的比较多。
有实例参考的博客地址:https://www.cnblogs.com/similarface/p/5805973.html
hadoop基本组件原理小总结的更多相关文章
- Hadoop以及组件介绍
一.背景介绍 在接触过大数据相关项目的时候常常都会听到Hadoop这个东西,简单来说,他是一个用分布式计算来处理大数据的开源软件,下面包含了许多的组件和子项目,这篇文章将会介绍Hadoop的原理以及一 ...
- Ubuntu13.04 Eclipse下编译安装Hadoop插件及使用小例
Ubuntu13.04 Eclipse下编译安装Hadoop插件及使用小例 一.在Eclipse下编译安装Hadoop插件 Hadoop的Eclipse插件现在已经没有二进制版直接提供,只能自己编译. ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- 23、自动装配-Aware注入Spring底层组件&原理
23.自动装配-Aware注入Spring底层组件&原理 Aware 接口,提供了类似回调函数的功能 自定义组件想要使用Spring 容器底层的一些组件(Application Context ...
- 大数据组件原理总结-Hadoop、Hbase、Kafka、Zookeeper、Spark
Hadoop原理 分为HDFS与Yarn两个部分.HDFS有Namenode和Datanode两个部分.每个节点占用一个电脑.Datanode定时向Namenode发送心跳包,心跳包中包含Datano ...
- 【大数据技术】Hadoop三大组件架构原理(HDFS-YARN-MapReduce)
目前,Hadoop还只是数据仓库产品的一个补充,和数据仓库一起构建混搭架构为上层应用联合提供服务. Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起. ...
- 远程调试hadoop各组件
远程调试对应用程序开发十分有用.例如,为不能托管开发平台的低端机器开发程序,或在专用的机器上(比如服务不能中断的 Web 服务器)调试程序.其他情况包括:运行在内存小或 CUP 性能低的设备上的 Ja ...
- Hadoop中RPC协议小例子报错java.lang.reflect.UndeclaredThrowableException解决方法
最近在学习传智播客吴超老师的Hadoop视频,里面他在讲解RPC通信原理的过程中给了一个RPC的小例子,但是自己编写的过程中遇到一个小错误,整理如下: log4j:WARN No appenders ...
- Salesforce学习之路-developer篇(五)Aura组件原理及常用属性
很喜欢曾经看到的一句话:以输出倒逼输入.以输出的形式强制自己学习,确实是高效的学习方式,真的很棒.以下仅为个人学习理解,如有错误,欢迎指出,共同学习. 1. 什么是Lightning Componen ...
随机推荐
- width、height为auto或者100%的区别
一.规则 1. 某div不设置宽度,那么width默认为auto. 2. 某子元素div的width为100%(或者设置为等于父元素宽度的具体值,比如父元素width为100px,子元素width也设 ...
- C语言基础五 数组
数组跟变量的区别? 数组是可以在内存中连续存储多个元素的结构,所有元素必须属于相同类型. 格式:元素类型 数组名[元素个数]: 数组的特点: 只能存放单一元素的数据,里面存放的数据成为元素. 数组的声 ...
- CSS中的vertical-align属性
1,vertical-align属性的作用? 设置元素垂直对齐的方式: 2,该属性使用过程的注意点: 与text-align属性不同,text-align属性是设置给需要对齐元素的父元素的, 而ver ...
- 转载【React Native代码】手写验证码倒计时组件
实例代码: import React, { Component , PropTypes} from 'react'; import { AppRegistry, StyleSheet, Text, V ...
- 如何利用Azure DevOps快速实现自动化构建、测试、打包及部署
前两天有朋友问我,微软的Azure好用吗,适不适合国人的使用习惯,我就跟他讲了下,Azue很好用,这也是为什么微软云营收一直涨涨涨的原因,基本可以再1个小时内实现自动化构建.打包以及部署到Azure服 ...
- itest(爱测试) 4.5.0 发布,开源BUG 跟踪管理 & 敏捷测试管理软件
itest 简介 test 开源敏捷测试管理,testOps 践行者.可按测试包分配测试用例执行,也可建测试迭代(含任务,测试包,BUG)来组织测试工作,也有测试环境管理,还有很常用的测试度量:对于发 ...
- udp socket 10054
udp socket 10054 在接收端没有启动的情况下 1.直接ReceiveFrom没问题. 2.如果先SendTo再ReceiveFrom,SendTo可以正常过,但是RecieveFrom会 ...
- Java线程池中线程的生命周期
设:我们有一个coreSize=10,maxSize=20,keepAliveTime=60s,queue=40 1.池初始化时里面没有任何线程. 2.当有一个任务提交到池就创建第一个线程. 3.若继 ...
- JS淘宝浏览商品
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- sqlserver 批量修改数据库表主键名称为PK_表名
1.我们在创建sqlserver得数据表的主键的时候,有时会出现,后面加一串随机字符串的情况,如图所示: 2.如果你有强迫症的话,可以使用以下sql脚本进行修改,将主键的名称修改为PK_表名. --将 ...